 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPETrack: Unidirectional Position Estimation for Tracking Occluded Deformable Linear Objects
Dec 10, 2025Real-time state tracking of Deformable Linear Objects (DLOs) is critical for enabling robotic manipulation of DLOs in industrial assembly, medical procedures, and daily-life applications. However, the high-dimensional configuration space, nonlinear dynamics, and frequent partial occlusions present fundamental barriers to robust real-time DLO tracking. To address these limitations, this study introduces UPETrack, a geometry-driven framework based on Unidirectional Position Estimation (UPE), which facilitates tracking without the requirement for physical modeling, virtual simulation, or visual markers. The framework operates in two phases: (1) visible segment tracking is based on a Gaussian Mixture Model (GMM) fitted via the Expectation Maximization (EM) algorithm, and (2) occlusion region prediction employing UPE algorithm we proposed. UPE leverages the geometric continuity inherent in DLO shapes and their temporal evolution patterns to derive a closed-form positional estimator through three principal mechanisms: (i) local linear combination displacement term, (ii) proximal linear constraint term, and (iii) historical curvature term. This analytical formulation allows efficient and stable estimation of occluded nodes through explicit linear combinations of geometric components, eliminating the need for additional iterative optimization. Experimental results demonstrate that UPETrack surpasses two state-of-the-art tracking algorithms, including TrackDLO and CDCPD2, in both positioning accuracy and computational efficiency.
MinerU2.5: A Decoupled Vision-Language Model for Efficient High-Resolution Document Parsing
Sep 26, 2025We introduce MinerU2.5, a 1.2B-parameter document parsing vision-language model that achieves state-of-the-art recognition accuracy while maintaining exceptional computational efficiency. Our approach employs a coarse-to-fine, two-stage parsing strategy that decouples global layout analysis from local content recognition. In the first stage, the model performs efficient layout analysis on downsampled images to identify structural elements, circumventing the computational overhead of processing high-resolution inputs. In the second stage, guided by the global layout, it performs targeted content recognition on native-resolution crops extracted from the original image, preserving fine-grained details in dense text, complex formulas, and tables. To support this strategy, we developed a comprehensive data engine that generates diverse, large-scale training corpora for both pretraining and fine-tuning. Ultimately, MinerU2.5 demonstrates strong document parsing ability, achieving state-of-the-art performance on multiple benchmarks, surpassing both general-purpose and domain-specific models across various recognition tasks, while maintaining significantly lower computational overhead.
Estimated Informed Anytime Search for Sampling-Based Planning via Adaptive Sampler
Aug 29, 2025Path planning in robotics often involves solving continuously valued, high-dimensional problems. Popular informed approaches include graph-based searches, such as A*, and sampling-based methods, such as Informed RRT*, which utilize informed set and anytime strategies to expedite path optimization incrementally. Informed sampling-based planners define informed sets as subsets of the problem domain based on the current best solution cost. However, when no solution is found, these planners re-sample and explore the entire configuration space, which is time-consuming and computationally expensive. This article introduces Multi-Informed Trees (MIT*), a novel planner that constructs estimated informed sets based on prior admissible solution costs before finding the initial solution, thereby accelerating the initial convergence rate. Moreover, MIT* employs an adaptive sampler that dynamically adjusts the sampling strategy based on the exploration process. Furthermore, MIT* utilizes length-related adaptive sparse collision checks to guide lazy reverse search. These features enhance path cost efficiency and computation times while ensuring high success rates in confined scenarios. Through a series of simulations and real-world experiments, it is confirmed that MIT* outperforms existing single-query, sampling-based planners for problems in R^4 to R^16 and has been successfully applied to real-world robot manipulation tasks. A video showcasing our experimental results is available at: https://youtu.be/30RsBIdexTU
APT*: Asymptotically Optimal Motion Planning via Adaptively Prolated Elliptical R-Nearest Neighbors
Aug 27, 2025



Optimal path planning aims to determine a sequence of states from a start to a goal while accounting for planning objectives. Popular methods often integrate fixed batch sizes and neglect information on obstacles, which is not problem-specific. This study introduces Adaptively Prolated Trees (APT*), a novel sampling-based motion planner that extends based on Force Direction Informed Trees (FDIT*), integrating adaptive batch-sizing and elliptical $r$-nearest neighbor modules to dynamically modulate the path searching process based on environmental feedback. APT* adjusts batch sizes based on the hypervolume of the informed sets and considers vertices as electric charges that obey Coulomb's law to define virtual forces via neighbor samples, thereby refining the prolate nearest neighbor selection. These modules employ non-linear prolate methods to adaptively adjust the electric charges of vertices for force definition, thereby improving the convergence rate with lower solution costs. Comparative analyses show that APT* outperforms existing single-query sampling-based planners in dimensions from $\mathbb{R}^4$ to $\mathbb{R}^{16}$, and it was further validated through a real-world robot manipulation task. A video showcasing our experimental results is available at: https://youtu.be/gCcUr8LiEw4
Elliptical K-Nearest Neighbors -- Path Optimization via Coulomb's Law and Invalid Vertices in C-space Obstacles
Aug 27, 2025Path planning has long been an important and active research area in robotics. To address challenges in high-dimensional motion planning, this study introduces the Force Direction Informed Trees (FDIT*), a sampling-based planner designed to enhance speed and cost-effectiveness in pathfinding. FDIT* builds upon the state-of-the-art informed sampling planner, the Effort Informed Trees (EIT*), by capitalizing on often-overlooked information in invalid vertices. It incorporates principles of physical force, particularly Coulomb's law. This approach proposes the elliptical $k$-nearest neighbors search method, enabling fast convergence navigation and avoiding high solution cost or infeasible paths by exploring more problem-specific search-worthy areas. It demonstrates benefits in search efficiency and cost reduction, particularly in confined, high-dimensional environments. It can be viewed as an extension of nearest neighbors search techniques. Fusing invalid vertex data with physical dynamics facilitates force-direction-based search regions, resulting in an improved convergence rate to the optimum. FDIT* outperforms existing single-query, sampling-based planners on the tested problems in R^4 to R^16 and has been demonstrated on a real-world mobile manipulation task.
Tree-Based Grafting Approach for Bidirectional Motion Planning with Local Subsets Optimization
Aug 27, 2025Bidirectional motion planning often reduces planning time compared to its unidirectional counterparts. It requires connecting the forward and reverse search trees to form a continuous path. However, this process could fail and restart the asymmetric bidirectional search due to the limitations of lazy-reverse search. To address this challenge, we propose Greedy GuILD Grafting Trees (G3T*), a novel path planner that grafts invalid edge connections at both ends to re-establish tree-based connectivity, enabling rapid path convergence. G3T* employs a greedy approach using the minimum Lebesgue measure of guided incremental local densification (GuILD) subsets to optimize paths efficiently. Furthermore, G3T* dynamically adjusts the sampling distribution between the informed set and GuILD subsets based on historical and current cost improvements, ensuring asymptotic optimality. These features enhance the forward search's growth towards the reverse tree, achieving faster convergence and lower solution costs. Benchmark experiments across dimensions from R^2 to R^8 and real-world robotic evaluations demonstrate G3T*'s superior performance compared to existing single-query sampling-based planners. A video showcasing our experimental results is available at: https://youtu.be/3mfCRL5SQIU
Direction Informed Trees (DIT*): Optimal Path Planning via Direction Filter and Direction Cost Heuristic
Aug 26, 2025Optimal path planning requires finding a series of feasible states from the starting point to the goal to optimize objectives. Popular path planning algorithms, such as Effort Informed Trees (EIT*), employ effort heuristics to guide the search. Effective heuristics are accurate and computationally efficient, but achieving both can be challenging due to their conflicting nature. This paper proposes Direction Informed Trees (DIT*), a sampling-based planner that focuses on optimizing the search direction for each edge, resulting in goal bias during exploration. We define edges as generalized vectors and integrate similarity indexes to establish a directional filter that selects the nearest neighbors and estimates direction costs. The estimated direction cost heuristics are utilized in edge evaluation. This strategy allows the exploration to share directional information efficiently. DIT* convergence faster than existing single-query, sampling-based planners on tested problems in R^4 to R^16 and has been demonstrated in real-world environments with various planning tasks. A video showcasing our experimental results is available at: https://youtu.be/2SX6QT2NOek
ST-Raptor: LLM-Powered Semi-Structured Table Question Answering
Aug 25, 2025



Semi-structured tables, widely used in real-world applications (e.g., financial reports, medical records, transactional orders), often involve flexible and complex layouts (e.g., hierarchical headers and merged cells). These tables generally rely on human analysts to interpret table layouts and answer relevant natural language questions, which is costly and inefficient. To automate the procedure, existing methods face significant challenges. First, methods like NL2SQL require converting semi-structured tables into structured ones, which often causes substantial information loss. Second, methods like NL2Code and multi-modal LLM QA struggle to understand the complex layouts of semi-structured tables and cannot accurately answer corresponding questions. To this end, we propose ST-Raptor, a tree-based framework for semi-structured table question answering using large language models. First, we introduce the Hierarchical Orthogonal Tree (HO-Tree), a structural model that captures complex semi-structured table layouts, along with an effective algorithm for constructing the tree. Second, we define a set of basic tree operations to guide LLMs in executing common QA tasks. Given a user question, ST-Raptor decomposes it into simpler sub-questions, generates corresponding tree operation pipelines, and conducts operation-table alignment for accurate pipeline execution. Third, we incorporate a two-stage verification mechanism: forward validation checks the correctness of execution steps, while backward validation evaluates answer reliability by reconstructing queries from predicted answers. To benchmark the performance, we present SSTQA, a dataset of 764 questions over 102 real-world semi-structured tables. Experiments show that ST-Raptor outperforms nine baselines by up to 20% in answer accuracy. The code is available at https://github.com/weAIDB/ST-Raptor.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025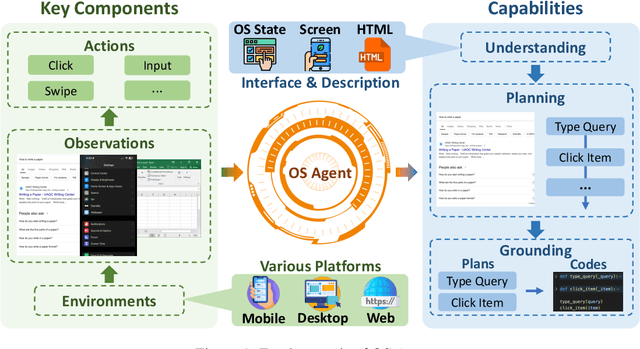
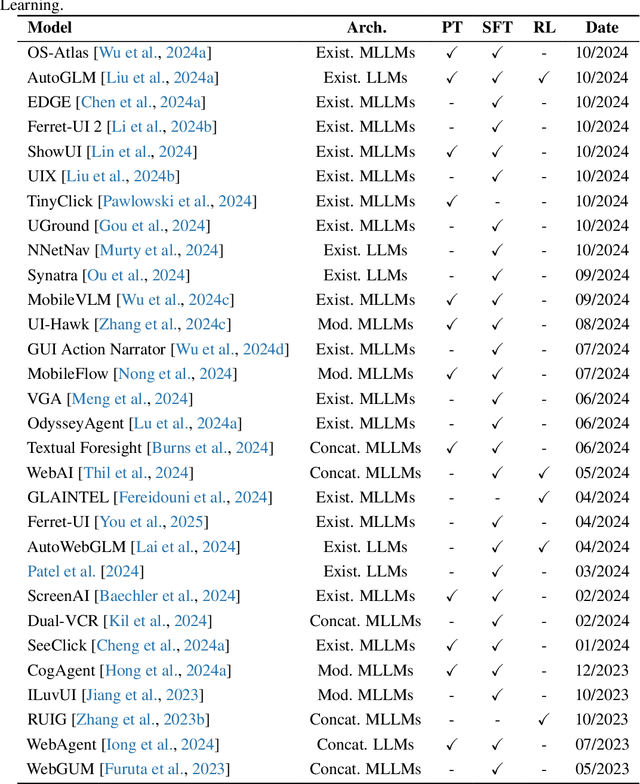
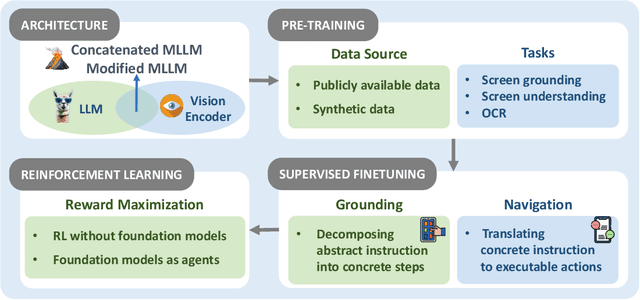
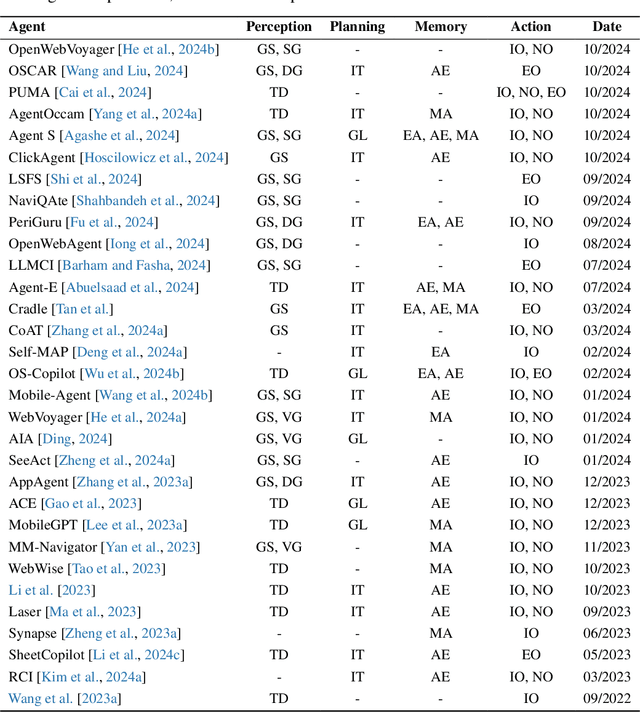
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
EC-Diff: Fast and High-Quality Edge-Cloud Collaborative Inference for Diffusion Models
Jul 16, 2025Diffusion Models have shown remarkable proficiency in image and video synthesis. As model size and latency increase limit user experience, hybrid edge-cloud collaborative framework was recently proposed to realize fast inference and high-quality generation, where the cloud model initiates high-quality semantic planning and the edge model expedites later-stage refinement. However, excessive cloud denoising prolongs inference time, while insufficient steps cause semantic ambiguity, leading to inconsistency in edge model output. To address these challenges, we propose EC-Diff that accelerates cloud inference through gradient-based noise estimation while identifying the optimal point for cloud-edge handoff to maintain generation quality. Specifically, we design a K-step noise approximation strategy to reduce cloud inference frequency by using noise gradients between steps and applying cloud inference periodically to adjust errors. Then we design a two-stage greedy search algorithm to efficiently find the optimal parameters for noise approximation and edge model switching. Extensive experiments demonstrate that our method significantly enhances generation quality compared to edge inference, while achieving up to an average $2\times$ speedup in inference compared to cloud inference. Video samples and source code are available at https://ec-diff.github.io/.