 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Dual-Line Decoder Network with Multi-Scale Convolutional Attention for Multi-organ Segmentation
Aug 23, 2025Proper segmentation of organs-at-risk is important for radiation therapy, surgical planning, and diagnostic decision-making in medical image analysis. While deep learning-based segmentation architectures have made significant progress, they often fail to balance segmentation accuracy with computational efficiency. Most of the current state-of-the-art methods either prioritize performance at the cost of high computational complexity or compromise accuracy for efficiency. This paper addresses this gap by introducing an efficient dual-line decoder segmentation network (EDLDNet). The proposed method features a noisy decoder, which learns to incorporate structured perturbation at training time for better model robustness, yet at inference time only the noise-free decoder is executed, leading to lower computational cost. Multi-Scale convolutional Attention Modules (MSCAMs), Attention Gates (AGs), and Up-Convolution Blocks (UCBs) are further utilized to optimize feature representation and boost segmentation performance. By leveraging multi-scale segmentation masks from both decoders, we also utilize a mutation-based loss function to enhance the model's generalization. Our approach outperforms SOTA segmentation architectures on four publicly available medical imaging datasets. EDLDNet achieves SOTA performance with an 84.00% Dice score on the Synapse dataset, surpassing baseline model like UNet by 13.89% in Dice score while significantly reducing Multiply-Accumulate Operations (MACs) by 89.7%. Compared to recent approaches like EMCAD, our EDLDNet not only achieves higher Dice score but also maintains comparable computational efficiency. The outstanding performance across diverse datasets establishes EDLDNet's strong generalization, computational efficiency, and robustness. The source code, pre-processed data, and pre-trained weights will be available at https://github.com/riadhassan/EDLDNet .
Fine-tuned Large Language Models (LLMs): Improved Prompt Injection Attacks Detection
Oct 28, 2024



Large language models (LLMs) are becoming a popular tool as they have significantly advanced in their capability to tackle a wide range of language-based tasks. However, LLMs applications are highly vulnerable to prompt injection attacks, which poses a critical problem. These attacks target LLMs applications through using carefully designed input prompts to divert the model from adhering to original instruction, thereby it could execute unintended actions. These manipulations pose serious security threats which potentially results in data leaks, biased outputs, or harmful responses. This project explores the security vulnerabilities in relation to prompt injection attacks. To detect whether a prompt is vulnerable or not, we follows two approaches: 1) a pre-trained LLM, and 2) a fine-tuned LLM. Then, we conduct a thorough analysis and comparison of the classification performance. Firstly, we use pre-trained XLM-RoBERTa model to detect prompt injections using test dataset without any fine-tuning and evaluate it by zero-shot classification. Then, this proposed work will apply supervised fine-tuning to this pre-trained LLM using a task-specific labeled dataset from deepset in huggingface, and this fine-tuned model achieves impressive results with 99.13\% accuracy, 100\% precision, 98.33\% recall and 99.15\% F1-score thorough rigorous experimentation and evaluation. We observe that our approach is highly efficient in detecting prompt injection attacks.
Embedding with Large Language Models for Classification of HIPAA Safeguard Compliance Rules
Oct 28, 2024



Although software developers of mHealth apps are responsible for protecting patient data and adhering to strict privacy and security requirements, many of them lack awareness of HIPAA regulations and struggle to distinguish between HIPAA rules categories. Therefore, providing guidance of HIPAA rules patterns classification is essential for developing secured applications for Google Play Store. In this work, we identified the limitations of traditional Word2Vec embeddings in processing code patterns. To address this, we adopt multilingual BERT (Bidirectional Encoder Representations from Transformers) which offers contextualized embeddings to the attributes of dataset to overcome the issues. Therefore, we applied this BERT to our dataset for embedding code patterns and then uses these embedded code to various machine learning approaches. Our results demonstrate that the models significantly enhances classification performance, with Logistic Regression achieving a remarkable accuracy of 99.95\%. Additionally, we obtained high accuracy from Support Vector Machine (99.79\%), Random Forest (99.73\%), and Naive Bayes (95.93\%), outperforming existing approaches. This work underscores the effectiveness and showcases its potential for secure application development.
Case Study-Based Approach of Quantum Machine Learning in Cybersecurity: Quantum Support Vector Machine for Malware Classification and Protection
Jun 01, 2023



Quantum machine learning (QML) is an emerging field of research that leverages quantum computing to improve the classical machine learning approach to solve complex real world problems. QML has the potential to address cybersecurity related challenges. Considering the novelty and complex architecture of QML, resources are not yet explicitly available that can pave cybersecurity learners to instill efficient knowledge of this emerging technology. In this research, we design and develop QML-based ten learning modules covering various cybersecurity topics by adopting student centering case-study based learning approach. We apply one subtopic of QML on a cybersecurity topic comprised of pre-lab, lab, and post-lab activities towards providing learners with hands-on QML experiences in solving real-world security problems. In order to engage and motivate students in a learning environment that encourages all students to learn, pre-lab offers a brief introduction to both the QML subtopic and cybersecurity problem. In this paper, we utilize quantum support vector machine (QSVM) for malware classification and protection where we use open source Pennylane QML framework on the drebin215 dataset. We demonstrate our QSVM model and achieve an accuracy of 95% in malware classification and protection. We will develop all the modules and introduce them to the cybersecurity community in the coming days.
Feature Engineering-Based Detection of Buffer Overflow Vulnerability in Source Code Using Neural Networks
Jun 01, 2023



One of the most significant challenges in the field of software code auditing is the presence of vulnerabilities in software source code. Every year, more and more software flaws are discovered, either internally in proprietary code or publicly disclosed. These flaws are highly likely to be exploited and can lead to system compromise, data leakage, or denial of service. To create a large-scale machine learning system for function level vulnerability identification, we utilized a sizable dataset of C and C++ open-source code containing millions of functions with potential buffer overflow exploits. We have developed an efficient and scalable vulnerability detection method based on neural network models that learn features extracted from the source codes. The source code is first converted into an intermediate representation to remove unnecessary components and shorten dependencies. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. We maintain the semantic and syntactic information using state of the art word embedding algorithms such as GloVe and fastText. The embedded vectors are subsequently fed into neural networks such as LSTM, BiLSTM, LSTM Autoencoder, word2vec, BERT, and GPT2 to classify the possible vulnerabilities. Furthermore, we have proposed a neural network model that can overcome issues associated with traditional neural networks. We have used evaluation metrics such as F1 score, precision, recall, accuracy, and total execution time to measure the performance. We have conducted a comparative analysis between results derived from features containing a minimal text representation and semantic and syntactic information.
A Novel IoT-based Framework for Non-Invasive Human Hygiene Monitoring using Machine Learning Techniques
Jul 07, 2022


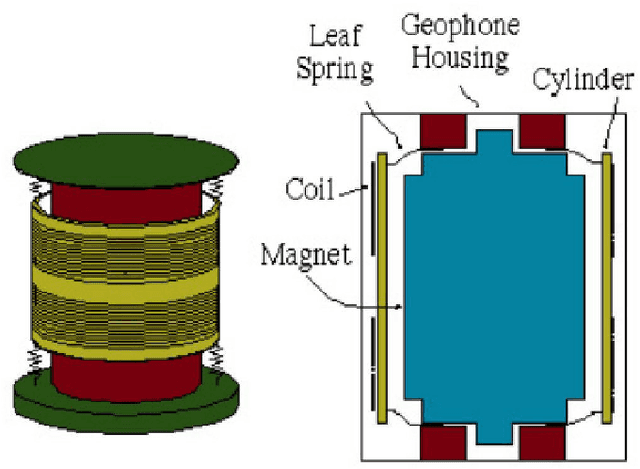
People's personal hygiene habits speak volumes about the condition of taking care of their bodies and health in daily lifestyle. Maintaining good hygiene practices not only reduces the chances of contracting a disease but could also reduce the risk of spreading illness within the community. Given the current pandemic, daily habits such as washing hands or taking regular showers have taken primary importance among people, especially for the elderly population living alone at home or in an assisted living facility. This paper presents a novel and non-invasive framework for monitoring human hygiene using vibration sensors where we adopt Machine Learning techniques. The approach is based on a combination of a geophone sensor, a digitizer, and a cost-efficient computer board in a practical enclosure. Monitoring daily hygiene routines may help healthcare professionals be proactive rather than reactive in identifying and controlling the spread of potential outbreaks within the community. The experimental result indicates that applying a Support Vector Machine (SVM) for binary classification exhibits a promising accuracy of ~95% in the classification of different hygiene habits. Furthermore, both tree-based classifier (Random Forrest and Decision Tree) outperforms other models by achieving the highest accuracy (100%), which means that classifying hygiene events using vibration and non-invasive sensors is possible for monitoring hygiene activity.
Causal Discovery on the Effect of Antipsychotic Drugs on Delirium Patients in the ICU using Large EHR Dataset
Apr 28, 2022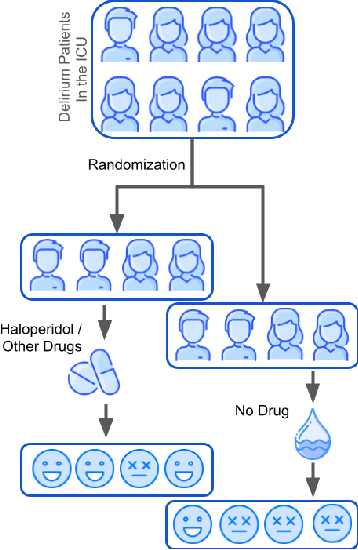
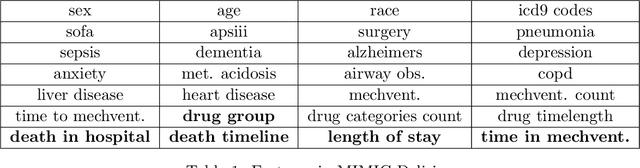

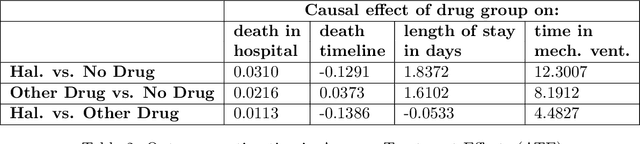
Delirium occurs in about 80% cases in the Intensive Care Unit (ICU) and is associated with a longer hospital stay, increased mortality and other related issues. Delirium does not have any biomarker-based diagnosis and is commonly treated with antipsychotic drugs (APD). However, multiple studies have shown controversy over the efficacy or safety of APD in treating delirium. Since randomized controlled trials (RCT) are costly and time-expensive, we aim to approach the research question of the efficacy of APD in the treatment of delirium using retrospective cohort analysis. We plan to use the Causal inference framework to look for the underlying causal structure model, leveraging the availability of large observational data on ICU patients. To explore safety outcomes associated with APD, we aim to build a causal model for delirium in the ICU using large observational data sets connecting various covariates correlated with delirium. We utilized the MIMIC III database, an extensive electronic health records (EHR) dataset with 53,423 distinct hospital admissions. Our null hypothesis is: there is no significant difference in outcomes for delirium patients under different drug-group in the ICU. Through our exploratory, machine learning based and causal analysis, we had findings such as: mean length-of-stay and max length-of-stay is higher for patients in Haloperidol drug group, and haloperidol group has a higher rate of death in a year compared to other two-groups. Our generated causal model explicitly shows the functional relationships between different covariates. For future work, we plan to do time-varying analysis on the dataset.
Pragmatic Clinical Trials in the Rubric of Structural Causal Models
Apr 28, 2022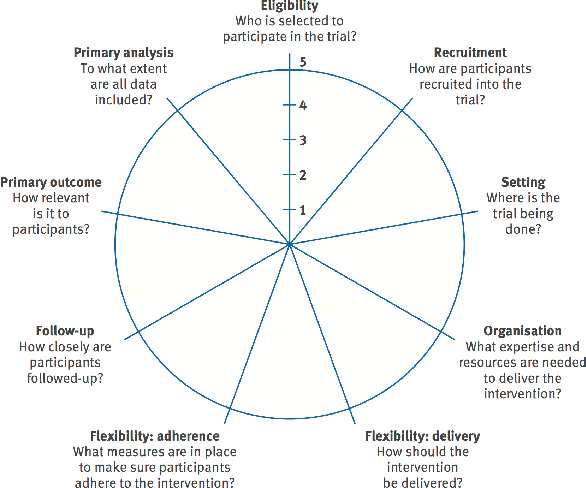
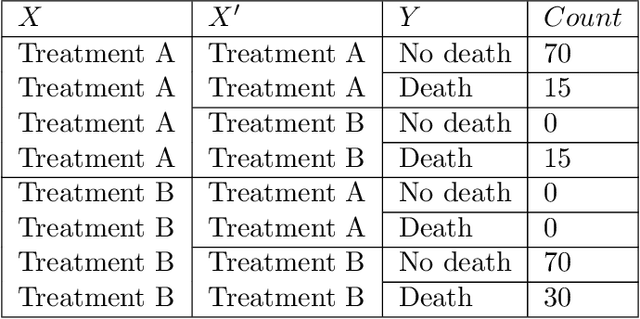
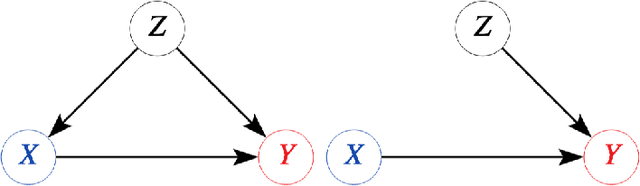
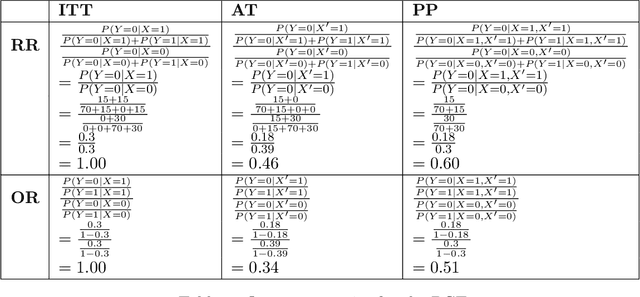
Explanatory studies, such as randomized controlled trials, are targeted to extract the true causal effect of interventions on outcomes and are by design adjusted for covariates through randomization. On the contrary, observational studies are a representation of events that occurred without intervention. Both can be illustrated using the Structural Causal Model (SCM), and do-calculus can be employed to estimate the causal effects. Pragmatic clinical trials (PCT) fall between these two ends of the trial design spectra and are thus hard to define. Due to its pragmatic nature, no standardized representation of PCT through SCM has been yet established. In this paper, we approach this problem by proposing a generalized representation of PCT under the rubric of structural causal models (SCM). We discuss different analysis techniques commonly employed in PCT using the proposed graphical model, such as intention-to-treat, as-treated, and per-protocol analysis. To show the application of our proposed approach, we leverage an experimental dataset from a pragmatic clinical trial. Our proposition of SCM through PCT creates a pathway to leveraging do-calculus and related mathematical operations on clinical datasets.
CKH: Causal Knowledge Hierarchy for Estimating Structural Causal Models from Data and Priors
Apr 28, 2022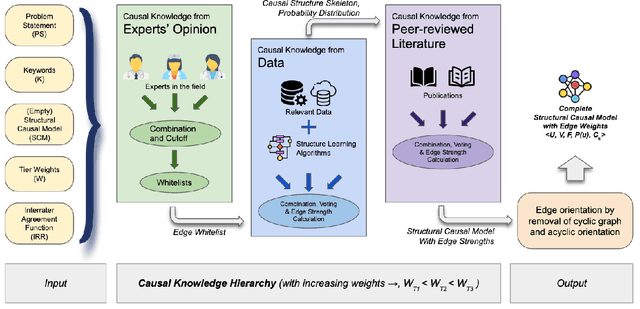
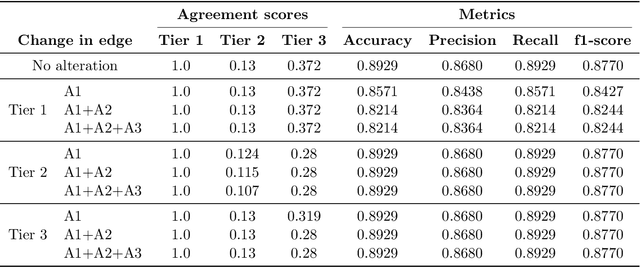
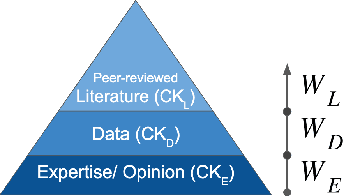

Structural causal models (SCMs) provide a principled approach to identifying causation from observational and experimental data in disciplines ranging from economics to medicine. SCMs, however, require domain knowledge, which is typically represented as graphical models. A key challenge in this context is the absence of a methodological framework for encoding priors (background knowledge) into causal models in a systematic manner. We propose an abstraction called causal knowledge hierarchy (CKH) for encoding priors into causal models. Our approach is based on the foundation of "levels of evidence" in medicine, with a focus on confidence in causal information. Using CKH, we present a methodological framework for encoding causal priors from various data sources and combining them to derive an SCM. We evaluate our approach on a simulated dataset and demonstrate overall performance compared to the ground truth causal model with sensitivity analysis.
A Causally Formulated Hazard Ratio Estimation through Backdoor Adjustment on Structural Causal Model
Jun 22, 2020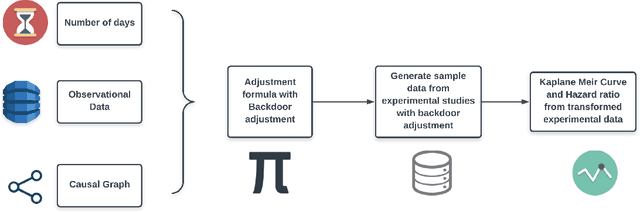

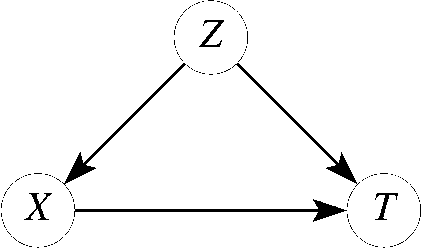

Identifying causal relationships for a treatment intervention is a fundamental problem in health sciences. Randomized controlled trials (RCTs) are considered the gold standard for identifying causal relationships. However, recent advancements in the theory of causal inference based on the foundations of structural causal models (SCMs) have allowed the identification of causal relationships from observational data, under certain assumptions. Survival analysis provides standard measures, such as the hazard ratio, to quantify the effects of an intervention. While hazard ratios are widely used in clinical and epidemiological studies for RCTs, a principled approach does not exist to compute hazard ratios for observational studies with SCMs. In this work, we review existing approaches to compute hazard ratios as well as their causal interpretation, if it exists. We also propose a novel approach to compute hazard ratios from observational studies using backdoor adjustment through SCMs and do-calculus. Finally, we evaluate the approach using experimental data for Ewing's sarcoma.