 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToKen: Task Decomposition and Knowledge Infusion for Few-Shot Hate Speech Detection
May 25, 2022
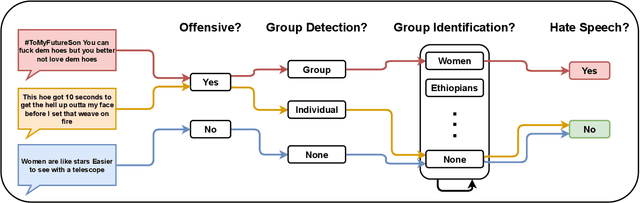

Hate speech detection is complex; it relies on commonsense reasoning, knowledge of stereotypes, and an understanding of social nuance that differs from one culture to the next. It is also difficult to collect a large-scale hate speech annotated dataset. In this work, we frame this problem as a few-shot learning task, and show significant gains with decomposing the task into its "constituent" parts. In addition, we see that infusing knowledge from reasoning datasets (e.g. Atomic2020) improves the performance even further. Moreover, we observe that the trained models generalize to out-of-distribution datasets, showing the superiority of task decomposition and knowledge infusion compared to previously used methods. Concretely, our method outperforms the baseline by 17.83% absolute gain in the 16-shot case.
Spurious Correlations in Reference-Free Evaluation of Text Generation
Apr 21, 2022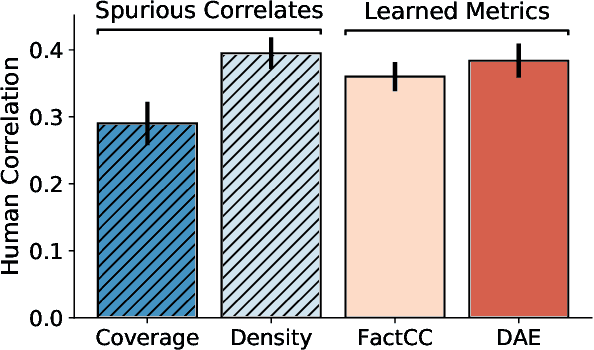

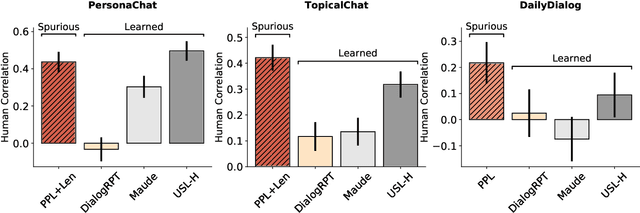
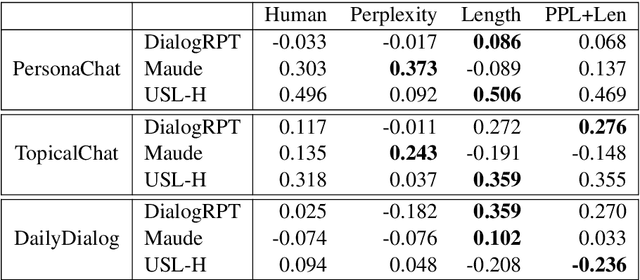
Model-based, reference-free evaluation metrics have been proposed as a fast and cost-effective approach to evaluate Natural Language Generation (NLG) systems. Despite promising recent results, we find evidence that reference-free evaluation metrics of summarization and dialog generation may be relying on spurious correlations with measures such as word overlap, perplexity, and length. We further observe that for text summarization, these metrics have high error rates when ranking current state-of-the-art abstractive summarization systems. We demonstrate that these errors can be mitigated by explicitly designing evaluation metrics to avoid spurious features in reference-free evaluation.
Faithful or Extractive? On Mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization
Aug 31, 2021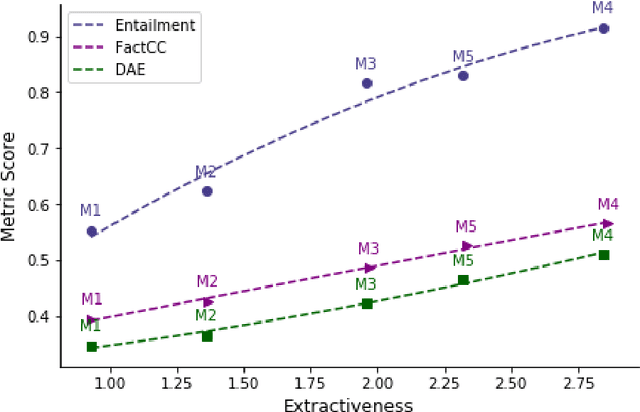

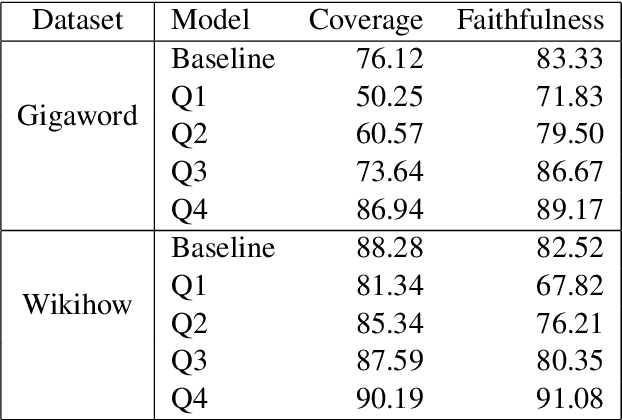
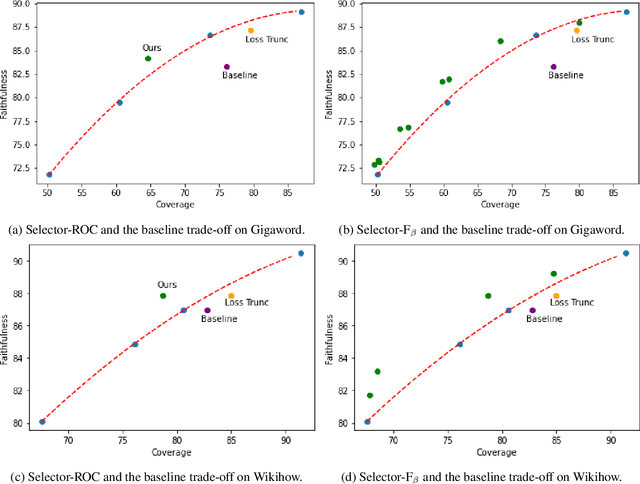
Despite recent progress in abstractive summarization, systems still suffer from faithfulness errors. While prior work has proposed models that improve faithfulness, it is unclear whether the improvement comes from an increased level of extractiveness of the model outputs as one naive way to improve faithfulness is to make summarization models more extractive. In this work, we present a framework for evaluating the effective faithfulness of summarization systems, by generating a faithfulnessabstractiveness trade-off curve that serves as a control at different operating points on the abstractiveness spectrum. We then show that the Maximum Likelihood Estimation (MLE) baseline as well as a recently proposed method for improving faithfulness, are both worse than the control at the same level of abstractiveness. Finally, we learn a selector to identify the most faithful and abstractive summary for a given document, and show that this system can attain higher faithfulness scores in human evaluations while being more abstractive than the baseline system on two datasets. Moreover, we show that our system is able to achieve a better faithfulness-abstractiveness trade-off than the control at the same level of abstractiveness.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Segmenting Subtitles for Correcting ASR Segmentation Errors
Apr 16, 2021
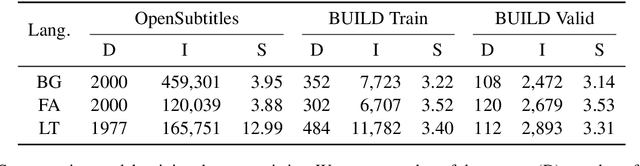

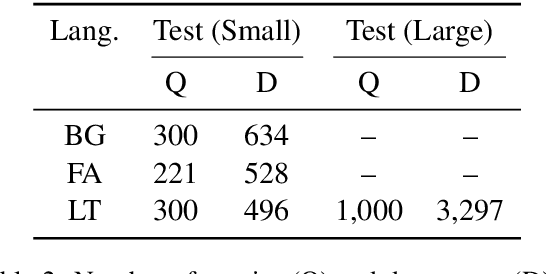
Typical ASR systems segment the input audio into utterances using purely acoustic information, which may not resemble the sentence-like units that are expected by conventional machine translation (MT) systems for Spoken Language Translation. In this work, we propose a model for correcting the acoustic segmentation of ASR models for low-resource languages to improve performance on downstream tasks. We propose the use of subtitles as a proxy dataset for correcting ASR acoustic segmentation, creating synthetic acoustic utterances by modeling common error modes. We train a neural tagging model for correcting ASR acoustic segmentation and show that it improves downstream performance on MT and audio-document cross-language information retrieval (CLIR).
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
To BERT or Not to BERT: Comparing Task-specific and Task-agnostic Semi-Supervised Approaches for Sequence Tagging
Oct 27, 2020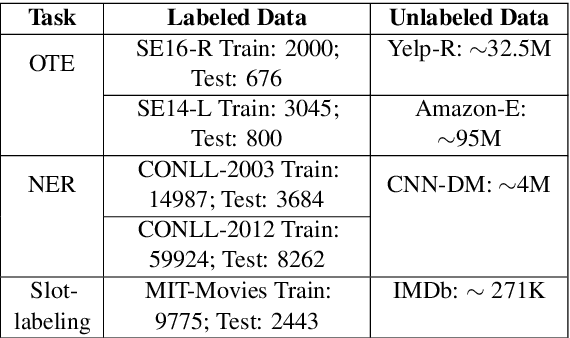
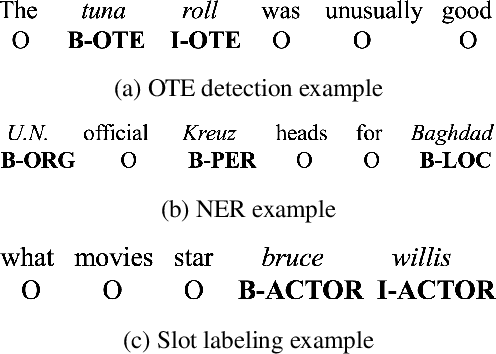
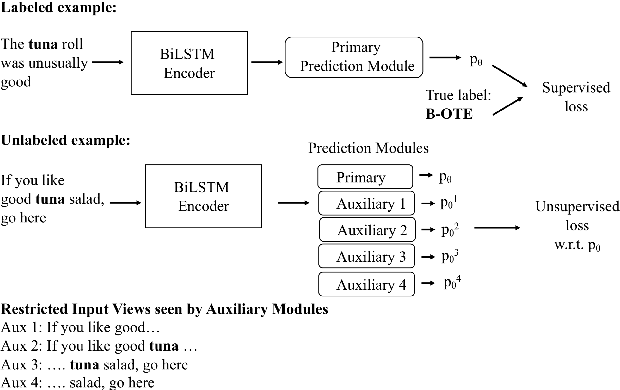
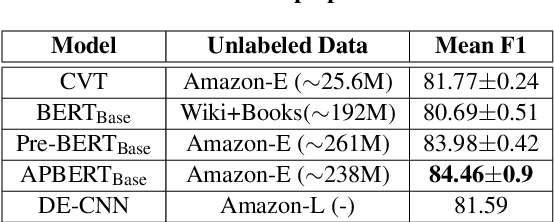
Leveraging large amounts of unlabeled data using Transformer-like architectures, like BERT, has gained popularity in recent times owing to their effectiveness in learning general representations that can then be further fine-tuned for downstream tasks to much success. However, training these models can be costly both from an economic and environmental standpoint. In this work, we investigate how to effectively use unlabeled data: by exploring the task-specific semi-supervised approach, Cross-View Training (CVT) and comparing it with task-agnostic BERT in multiple settings that include domain and task relevant English data. CVT uses a much lighter model architecture and we show that it achieves similar performance to BERT on a set of sequence tagging tasks, with lesser financial and environmental impact.
Incorporating Terminology Constraints in Automatic Post-Editing
Oct 19, 2020
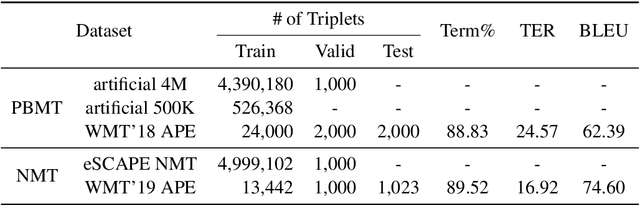
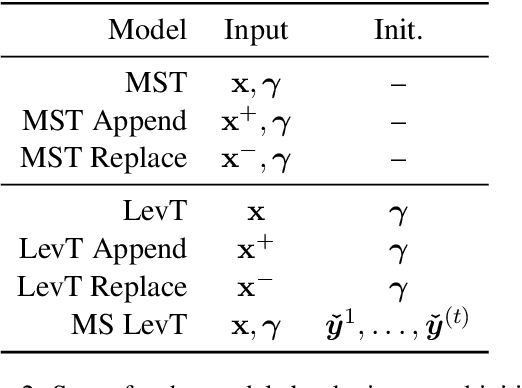
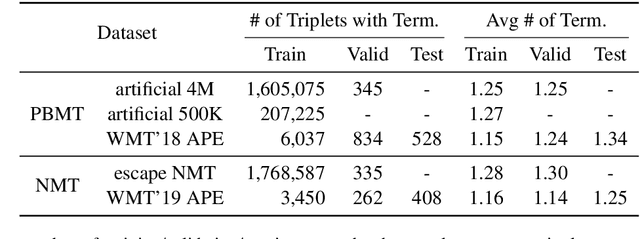
Users of machine translation (MT) may want to ensure the use of specific lexical terminologies. While there exist techniques for incorporating terminology constraints during inference for MT, current APE approaches cannot ensure that they will appear in the final translation. In this paper, we present both autoregressive and non-autoregressive models for lexically constrained APE, demonstrating that our approach enables preservation of 95% of the terminologies and also improves translation quality on English-German benchmarks. Even when applied to lexically constrained MT output, our approach is able to improve preservation of the terminologies. However, we show that our models do not learn to copy constraints systematically and suggest a simple data augmentation technique that leads to improved performance and robustness.
WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization
Oct 07, 2020


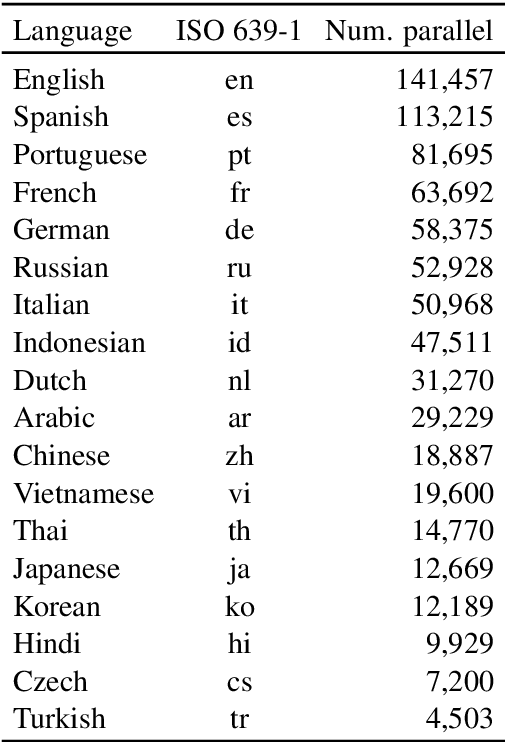
We introduce WikiLingua, a large-scale, multilingual dataset for the evaluation of crosslingual abstractive summarization systems. We extract article and summary pairs in 18 languages from WikiHow, a high quality, collaborative resource of how-to guides on a diverse set of topics written by human authors. We create gold-standard article-summary alignments across languages by aligning the images that are used to describe each how-to step in an article. As a set of baselines for further studies, we evaluate the performance of existing cross-lingual abstractive summarization methods on our dataset. We further propose a method for direct crosslingual summarization (i.e., without requiring translation at inference time) by leveraging synthetic data and Neural Machine Translation as a pre-training step. Our method significantly outperforms the baseline approaches, while being more cost efficient during inference.
Exploring Content Selection in Summarization of Novel Chapters
May 07, 2020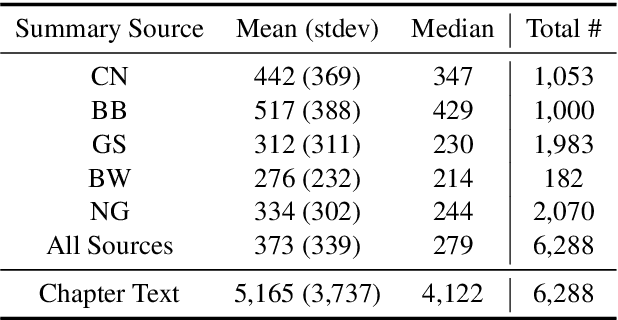
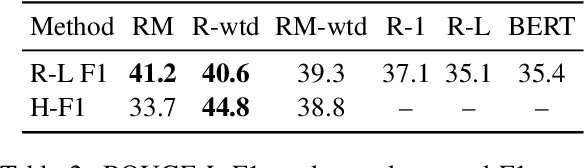
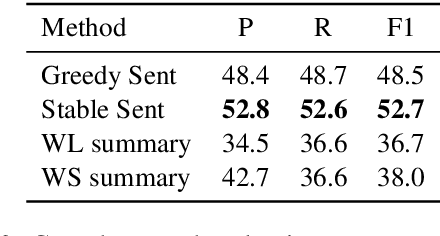

We present a new summarization task, generating summaries of novel chapters using summary/chapter pairs from online study guides. This is a harder task than the news summarization task, given the chapter length as well as the extreme paraphrasing and generalization found in the summaries. We focus on extractive summarization, which requires the creation of a gold-standard set of extractive summaries. We present a new metric for aligning reference summary sentences with chapter sentences to create gold extracts and also experiment with different alignment methods. Our experiments demonstrate significant improvement over prior alignment approaches for our task as shown through automatic metrics and a crowd-sourced pyramid analysis.