 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Semantics for Few Shot Named Entity Recognition
Mar 16, 2022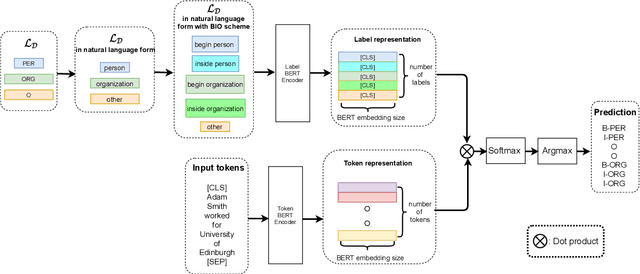
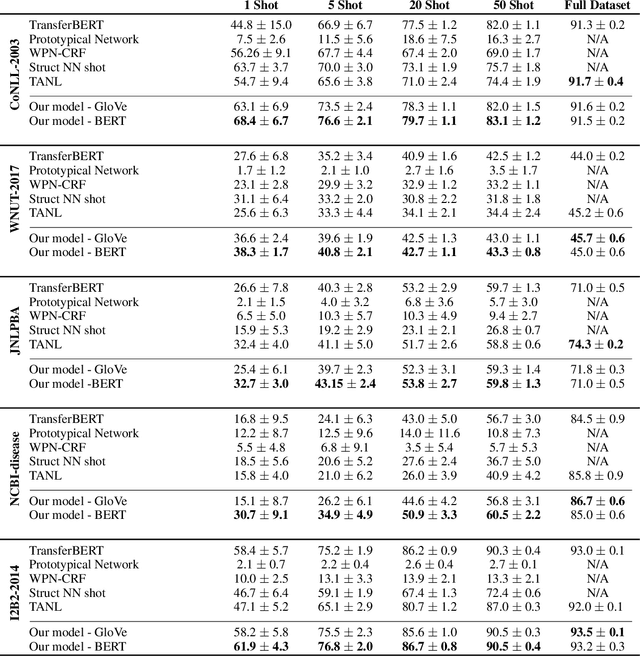
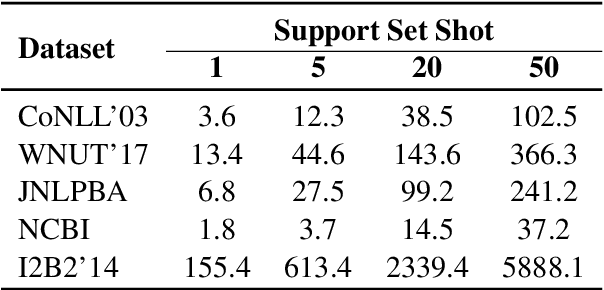
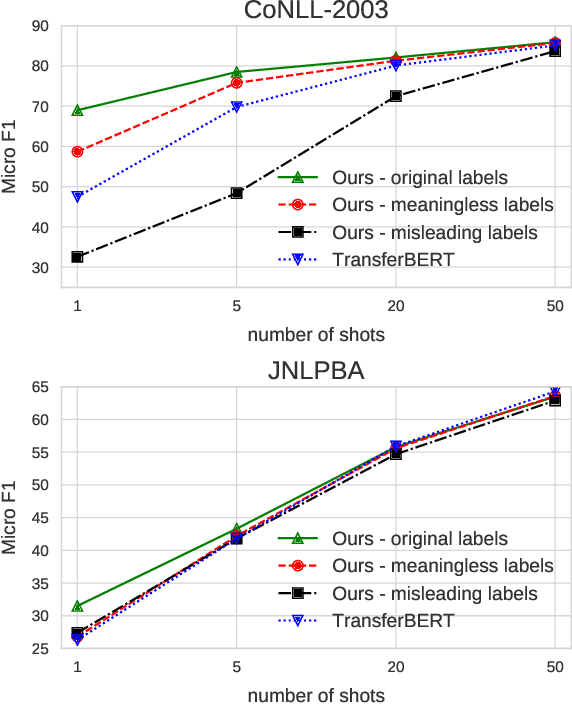
We study the problem of few shot learning for named entity recognition. Specifically, we leverage the semantic information in the names of the labels as a way of giving the model additional signal and enriched priors. We propose a neural architecture that consists of two BERT encoders, one to encode the document and its tokens and another one to encode each of the labels in natural language format. Our model learns to match the representations of named entities computed by the first encoder with label representations computed by the second encoder. The label semantics signal is shown to support improved state-of-the-art results in multiple few shot NER benchmarks and on-par performance in standard benchmarks. Our model is especially effective in low resource settings.
Multi-Task Learning and Adapted Knowledge Models for Emotion-Cause Extraction
Jun 17, 2021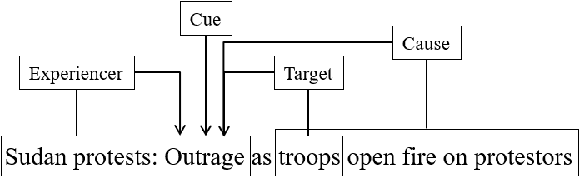
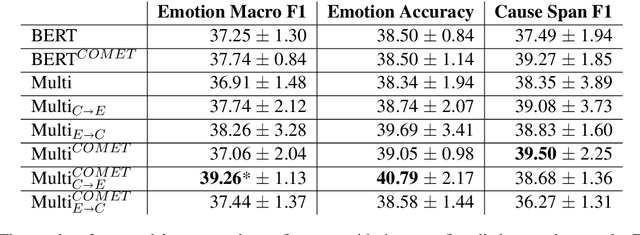
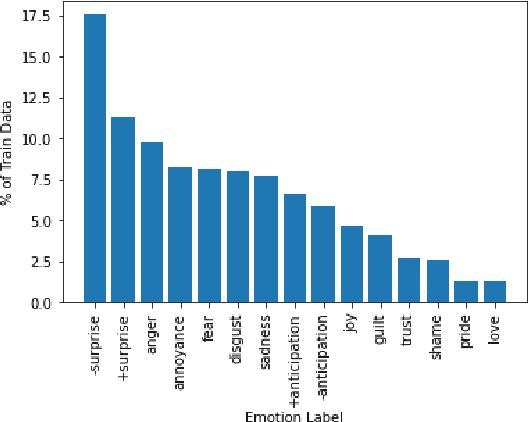

Detecting what emotions are expressed in text is a well-studied problem in natural language processing. However, research on finer grained emotion analysis such as what causes an emotion is still in its infancy. We present solutions that tackle both emotion recognition and emotion cause detection in a joint fashion. Considering that common-sense knowledge plays an important role in understanding implicitly expressed emotions and the reasons for those emotions, we propose novel methods that combine common-sense knowledge via adapted knowledge models with multi-task learning to perform joint emotion classification and emotion cause tagging. We show performance improvement on both tasks when including common-sense reasoning and a multitask framework. We provide a thorough analysis to gain insights into model performance.
To BERT or Not to BERT: Comparing Task-specific and Task-agnostic Semi-Supervised Approaches for Sequence Tagging
Oct 27, 2020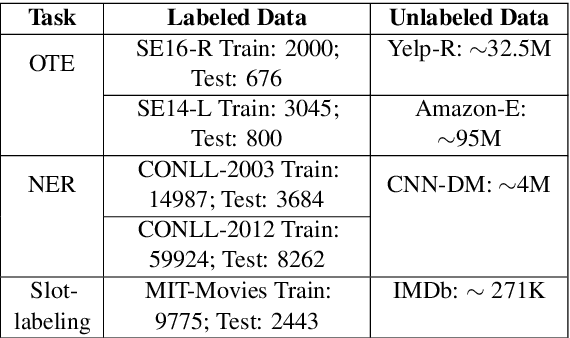
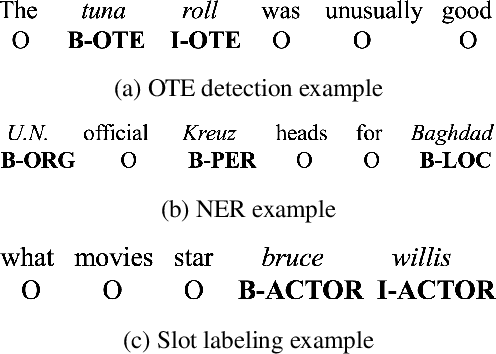
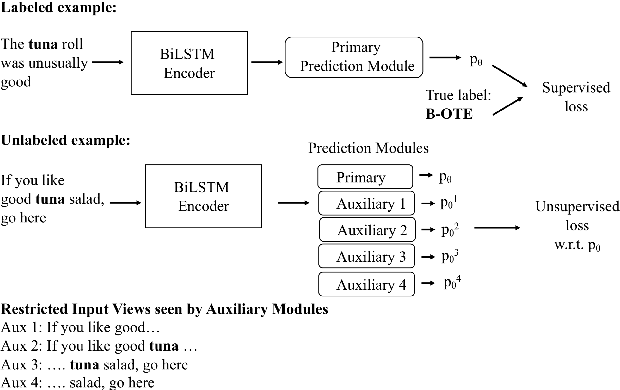
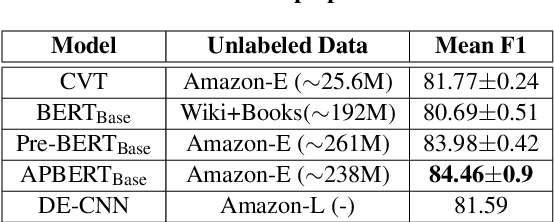
Leveraging large amounts of unlabeled data using Transformer-like architectures, like BERT, has gained popularity in recent times owing to their effectiveness in learning general representations that can then be further fine-tuned for downstream tasks to much success. However, training these models can be costly both from an economic and environmental standpoint. In this work, we investigate how to effectively use unlabeled data: by exploring the task-specific semi-supervised approach, Cross-View Training (CVT) and comparing it with task-agnostic BERT in multiple settings that include domain and task relevant English data. CVT uses a much lighter model architecture and we show that it achieves similar performance to BERT on a set of sequence tagging tasks, with lesser financial and environmental impact.
Resource-Enhanced Neural Model for Event Argument Extraction
Oct 06, 2020
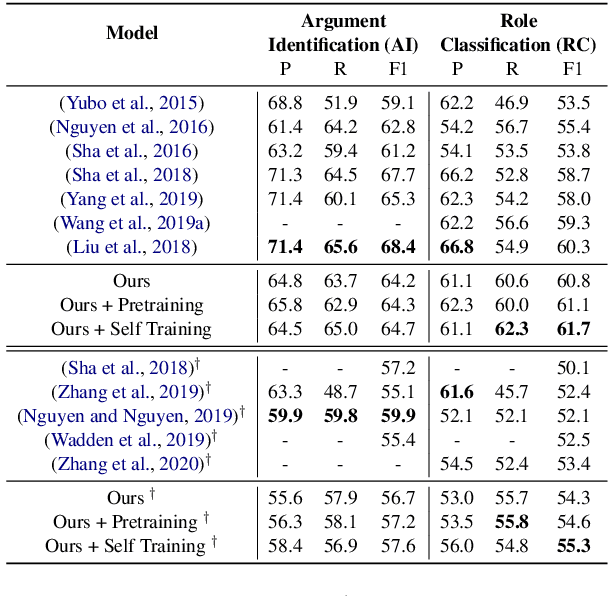
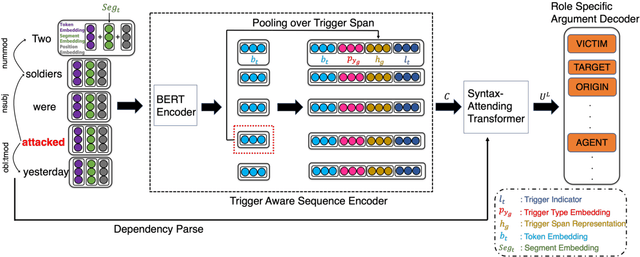
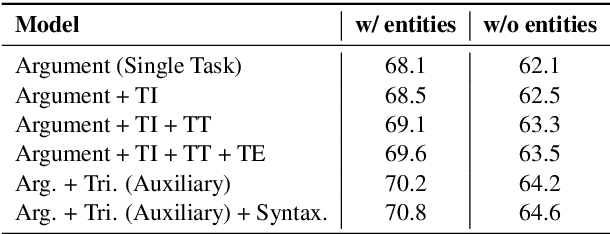
Event argument extraction (EAE) aims to identify the arguments of an event and classify the roles that those arguments play. Despite great efforts made in prior work, there remain many challenges: (1) Data scarcity. (2) Capturing the long-range dependency, specifically, the connection between an event trigger and a distant event argument. (3) Integrating event trigger information into candidate argument representation. For (1), we explore using unlabeled data in different ways. For (2), we propose to use a syntax-attending Transformer that can utilize dependency parses to guide the attention mechanism. For (3), we propose a trigger-aware sequence encoder with several types of trigger-dependent sequence representations. We also support argument extraction either from text annotated with gold entities or from plain text. Experiments on the English ACE2005 benchmark show that our approach achieves a new state-of-the-art.
Exploring Content Selection in Summarization of Novel Chapters
May 07, 2020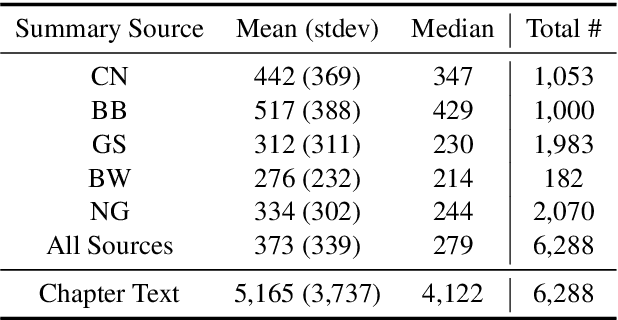
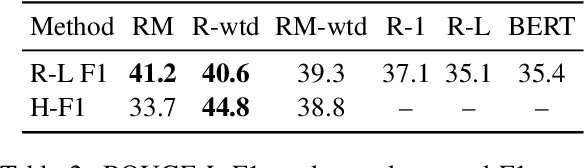
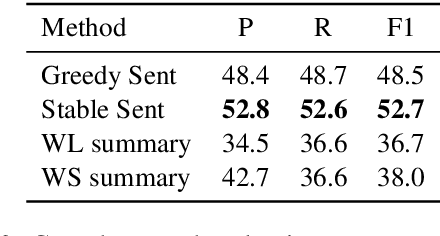

We present a new summarization task, generating summaries of novel chapters using summary/chapter pairs from online study guides. This is a harder task than the news summarization task, given the chapter length as well as the extreme paraphrasing and generalization found in the summaries. We focus on extractive summarization, which requires the creation of a gold-standard set of extractive summaries. We present a new metric for aligning reference summary sentences with chapter sentences to create gold extracts and also experiment with different alignment methods. Our experiments demonstrate significant improvement over prior alignment approaches for our task as shown through automatic metrics and a crowd-sourced pyramid analysis.
Words aren't enough, their order matters: On the Robustness of Grounding Visual Referring Expressions
May 04, 2020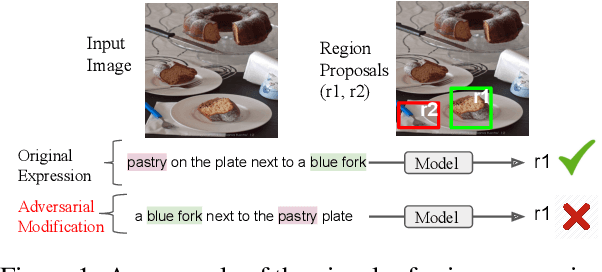

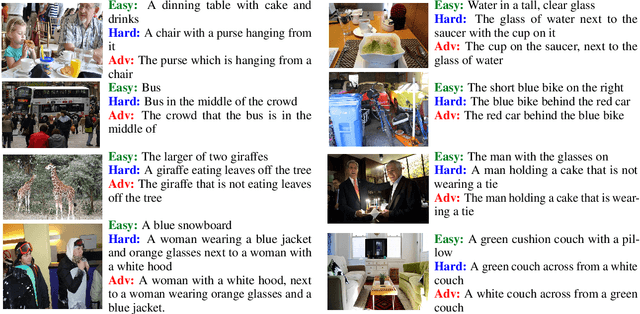
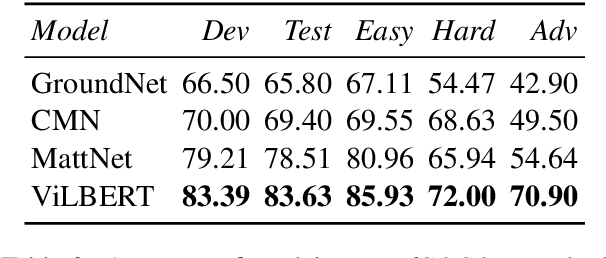
Visual referring expression recognition is a challenging task that requires natural language understanding in the context of an image. We critically examine RefCOCOg, a standard benchmark for this task, using a human study and show that 83.7% of test instances do not require reasoning on linguistic structure, i.e., words are enough to identify the target object, the word order doesn't matter. To measure the true progress of existing models, we split the test set into two sets, one which requires reasoning on linguistic structure and the other which doesn't. Additionally, we create an out-of-distribution dataset Ref-Adv by asking crowdworkers to perturb in-domain examples such that the target object changes. Using these datasets, we empirically show that existing methods fail to exploit linguistic structure and are 12% to 23% lower in performance than the established progress for this task. We also propose two methods, one based on contrastive learning and the other based on multi-task learning, to increase the robustness of ViLBERT, the current state-of-the-art model for this task. Our datasets are publicly available at https://github.com/aws/aws-refcocog-adv
Evaluating Robustness to Input Perturbations for Neural Machine Translation
May 01, 2020
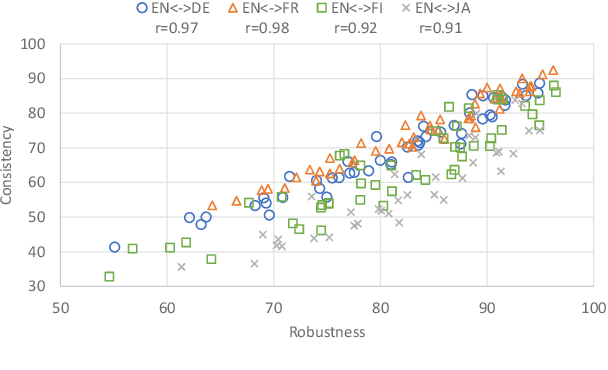
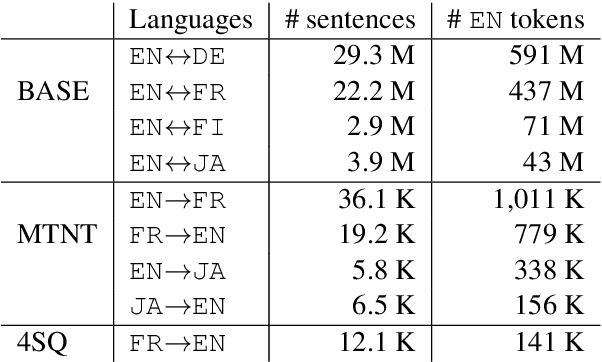
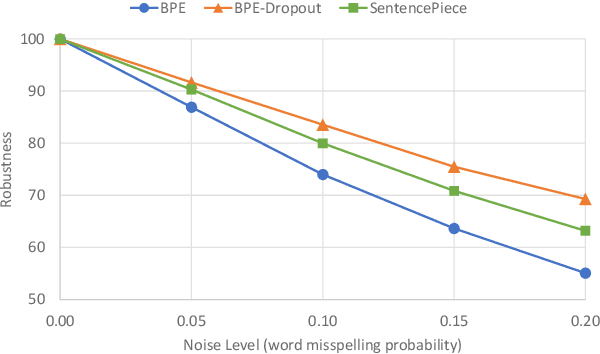
Neural Machine Translation (NMT) models are sensitive to small perturbations in the input. Robustness to such perturbations is typically measured using translation quality metrics such as BLEU on the noisy input. This paper proposes additional metrics which measure the relative degradation and changes in translation when small perturbations are added to the input. We focus on a class of models employing subword regularization to address robustness and perform extensive evaluations of these models using the robustness measures proposed. Results show that our proposed metrics reveal a clear trend of improved robustness to perturbations when subword regularization methods are used.
Joint translation and unit conversion for end-to-end localization
Apr 10, 2020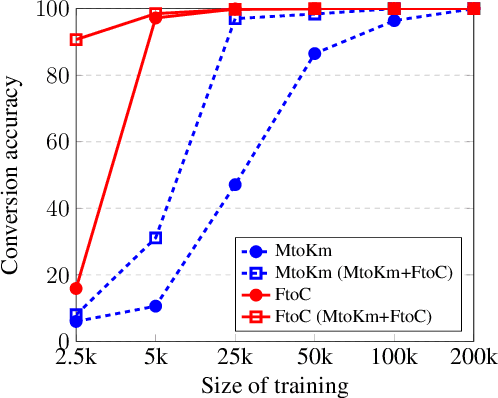

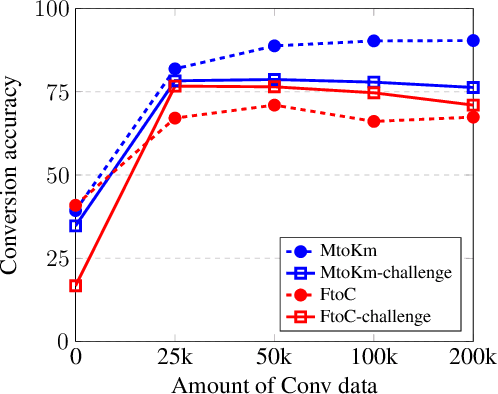
A variety of natural language tasks require processing of textual data which contains a mix of natural language and formal languages such as mathematical expressions. In this paper, we take unit conversions as an example and propose a data augmentation technique which leads to models learning both translation and conversion tasks as well as how to adequately switch between them for end-to-end localization.
Severing the Edge Between Before and After: Neural Architectures for Temporal Ordering of Events
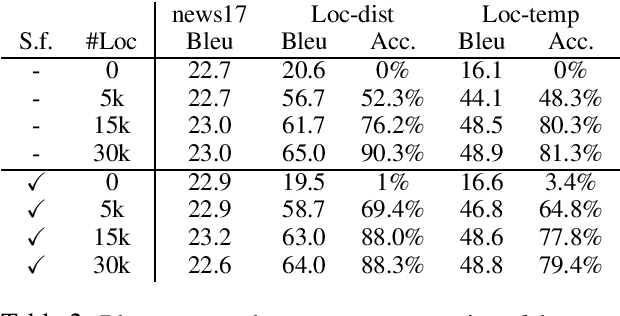
Apr 08, 2020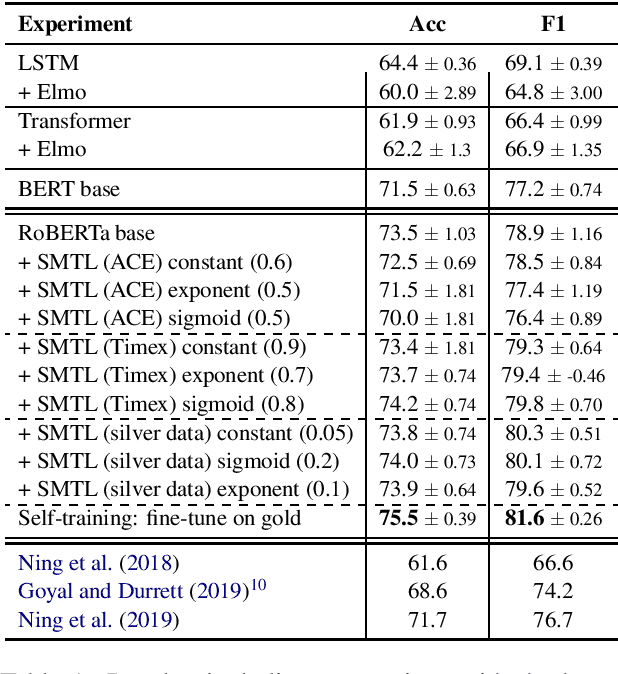
In this paper, we propose a neural architecture and a set of training methods for ordering events by predicting temporal relations. Our proposed models receive a pair of events within a span of text as input and they identify temporal relations (Before, After, Equal, Vague) between them. Given that a key challenge with this task is the scarcity of annotated data, our models rely on either pretrained representations (i.e. RoBERTa, BERT or ELMo), transfer and multi-task learning (by leveraging complementary datasets), and self-training techniques. Experiments on the MATRES dataset of English documents establish a new state-of-the-art on this task.
Robustness to Capitalization Errors in Named Entity Recognition
Nov 13, 2019
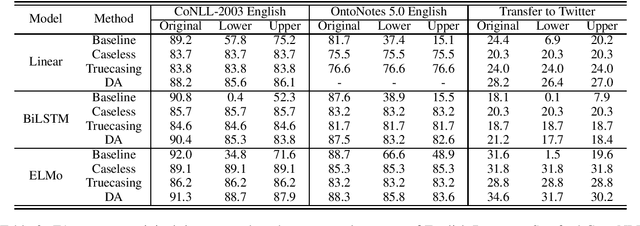
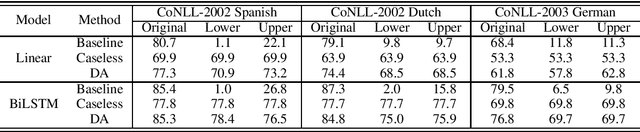
Robustness to capitalization errors is a highly desirable characteristic of named entity recognizers, yet we find standard models for the task are surprisingly brittle to such noise. Existing methods to improve robustness to the noise completely discard given orthographic information, mwhich significantly degrades their performance on well-formed text. We propose a simple alternative approach based on data augmentation, which allows the model to \emph{learn} to utilize or ignore orthographic information depending on its usefulness in the context. It achieves competitive robustness to capitalization errors while making negligible compromise to its performance on well-formed text and significantly improving generalization power on noisy user-generated text. Our experiments clearly and consistently validate our claim across different types of machine learning models, languages, and dataset sizes.
* Accepted to EMNLP 2019 Workshop : W-NUT 2019 5th Workshop on Noisy User Generated Text