 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongEval at CLEF 2025: Longitudinal Evaluation of IR Model Performance
Mar 11, 2025
This paper presents the third edition of the LongEval Lab, part of the CLEF 2025 conference, which continues to explore the challenges of temporal persistence in Information Retrieval (IR). The lab features two tasks designed to provide researchers with test data that reflect the evolving nature of user queries and document relevance over time. By evaluating how model performance degrades as test data diverge temporally from training data, LongEval seeks to advance the understanding of temporal dynamics in IR systems. The 2025 edition aims to engage the IR and NLP communities in addressing the development of adaptive models that can maintain retrieval quality over time in the domains of web search and scientific retrieval.
IAI Group at CheckThat! 2024: Transformer Models and Data Augmentation for Checkworthy Claim Detection
Aug 02, 2024This paper describes IAI group's participation for automated check-worthiness estimation for claims, within the framework of the 2024 CheckThat! Lab "Task 1: Check-Worthiness Estimation". The task involves the automated detection of check-worthy claims in English, Dutch, and Arabic political debates and Twitter data. We utilized various pre-trained generative decoder and encoder transformer models, employing methods such as few-shot chain-of-thought reasoning, fine-tuning, data augmentation, and transfer learning from one language to another. Despite variable success in terms of performance, our models achieved notable placements on the organizer's leaderboard: ninth-best in English, third-best in Dutch, and the top placement in Arabic, utilizing multilingual datasets for enhancing the generalizability of check-worthiness detection. Despite a significant drop in performance on the unlabeled test dataset compared to the development test dataset, our findings contribute to the ongoing efforts in claim detection research, highlighting the challenges and potential of language-specific adaptations in claim verification systems.
PKG API: A Tool for Personal Knowledge Graph Management
Feb 12, 2024


Personal knowledge graphs (PKGs) offer individuals a way to store and consolidate their fragmented personal data in a central place, improving service personalization while maintaining full user control. Despite their potential, practical PKG implementations with user-friendly interfaces remain scarce. This work addresses this gap by proposing a complete solution to represent, manage, and interface with PKGs. Our approach includes (1) a user-facing PKG Client, enabling end-users to administer their personal data easily via natural language statements, and (2) a service-oriented PKG API. To tackle the complexity of representing these statements within a PKG, we present an RDF-based PKG vocabulary that supports this, along with properties for access rights and provenance.
LongEval-Retrieval: French-English Dynamic Test Collection for Continuous Web Search Evaluation
Mar 06, 2023



LongEval-Retrieval is a Web document retrieval benchmark that focuses on continuous retrieval evaluation. This test collection is intended to be used to study the temporal persistence of Information Retrieval systems and will be used as the test collection in the Longitudinal Evaluation of Model Performance Track (LongEval) at CLEF 2023. This benchmark simulates an evolving information system environment - such as the one a Web search engine operates in - where the document collection, the query distribution, and relevance all move continuously, while following the Cranfield paradigm for offline evaluation. To do that, we introduce the concept of a dynamic test collection that is composed of successive sub-collections each representing the state of an information system at a given time step. In LongEval-Retrieval, each sub-collection contains a set of queries, documents, and soft relevance assessments built from click models. The data comes from Qwant, a privacy-preserving Web search engine that primarily focuses on the French market. LongEval-Retrieval also provides a 'mirror' collection: it is initially constructed in the French language to benefit from the majority of Qwant's traffic, before being translated to English. This paper presents the creation process of LongEval-Retrieval and provides baseline runs and analysis.
Cross-language Information Retrieval
Nov 10, 2021Two key assumptions shape the usual view of ranked retrieval: (1) that the searcher can choose words for their query that might appear in the documents that they wish to see, and (2) that ranking retrieved documents will suffice because the searcher will be able to recognize those which they wished to find. When the documents to be searched are in a language not known by the searcher, neither assumption is true. In such cases, Cross-Language Information Retrieval (CLIR) is needed. This chapter reviews the state of the art for cross-language information retrieval and outlines some open research questions.
Cross-language Sentence Selection via Data Augmentation and Rationale Training
Jun 04, 2021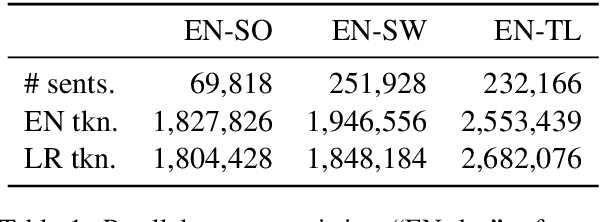
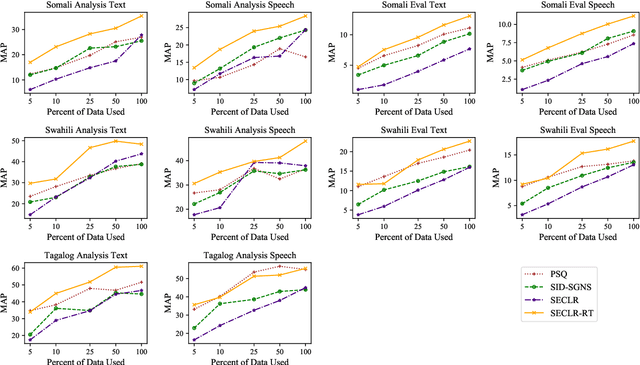
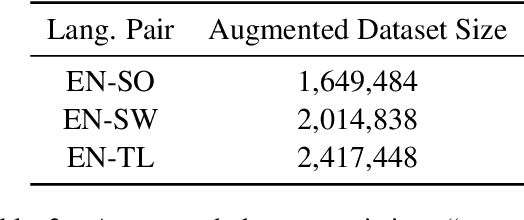
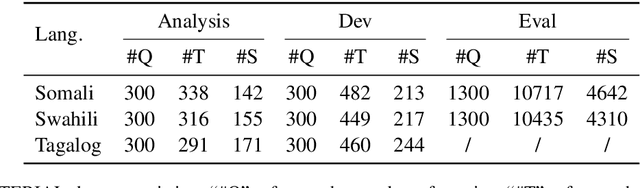
This paper proposes an approach to cross-language sentence selection in a low-resource setting. It uses data augmentation and negative sampling techniques on noisy parallel sentence data to directly learn a cross-lingual embedding-based query relevance model. Results show that this approach performs as well as or better than multiple state-of-the-art machine translation + monolingual retrieval systems trained on the same parallel data. Moreover, when a rationale training secondary objective is applied to encourage the model to match word alignment hints from a phrase-based statistical machine translation model, consistent improvements are seen across three language pairs (English-Somali, English-Swahili and English-Tagalog) over a variety of state-of-the-art baselines.
Segmenting Subtitles for Correcting ASR Segmentation Errors
Apr 16, 2021

Typical ASR systems segment the input audio into utterances using purely acoustic information, which may not resemble the sentence-like units that are expected by conventional machine translation (MT) systems for Spoken Language Translation. In this work, we propose a model for correcting the acoustic segmentation of ASR models for low-resource languages to improve performance on downstream tasks. We propose the use of subtitles as a proxy dataset for correcting ASR acoustic segmentation, creating synthetic acoustic utterances by modeling common error modes. We train a neural tagging model for correcting ASR acoustic segmentation and show that it improves downstream performance on MT and audio-document cross-language information retrieval (CLIR).