 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaverse: Simulating Embodied Agents at One Million Experiences per Second
Jul 21, 2021
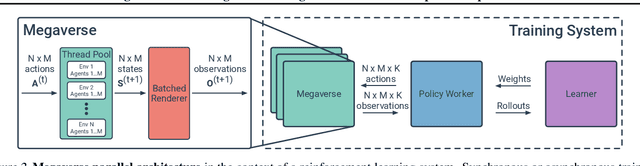
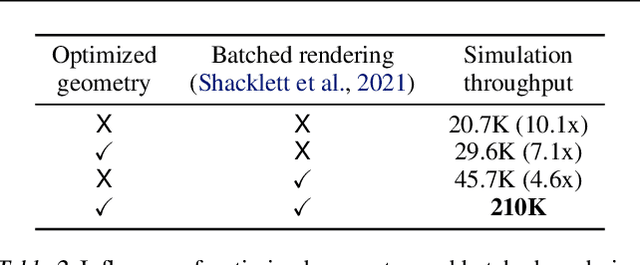
We present Megaverse, a new 3D simulation platform for reinforcement learning and embodied AI research. The efficient design of our engine enables physics-based simulation with high-dimensional egocentric observations at more than 1,000,000 actions per second on a single 8-GPU node. Megaverse is up to 70x faster than DeepMind Lab in fully-shaded 3D scenes with interactive objects. We achieve this high simulation performance by leveraging batched simulation, thereby taking full advantage of the massive parallelism of modern GPUs. We use Megaverse to build a new benchmark that consists of several single-agent and multi-agent tasks covering a variety of cognitive challenges. We evaluate model-free RL on this benchmark to provide baselines and facilitate future research. The source code is available at https://www.megaverse.info
Habitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


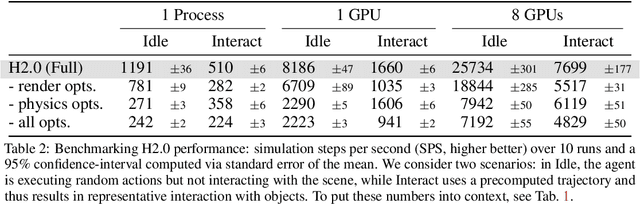
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.
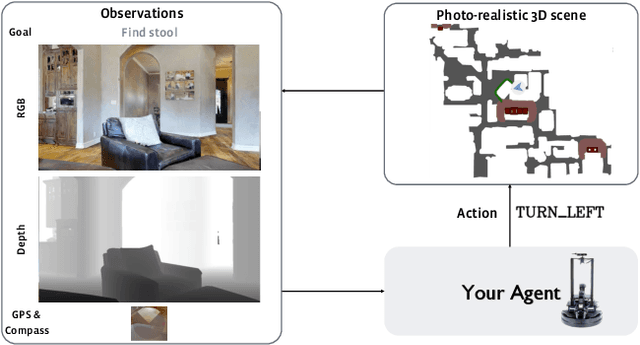
Auxiliary Tasks and Exploration Enable ObjectNav
Apr 08, 2021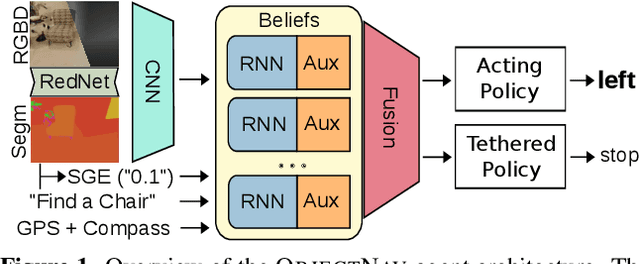
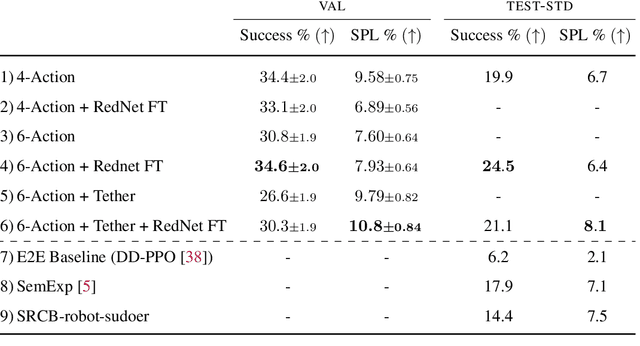
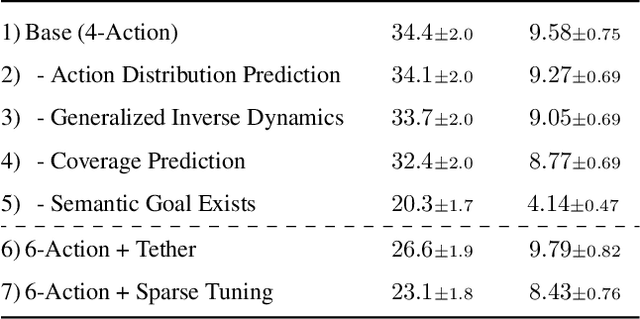
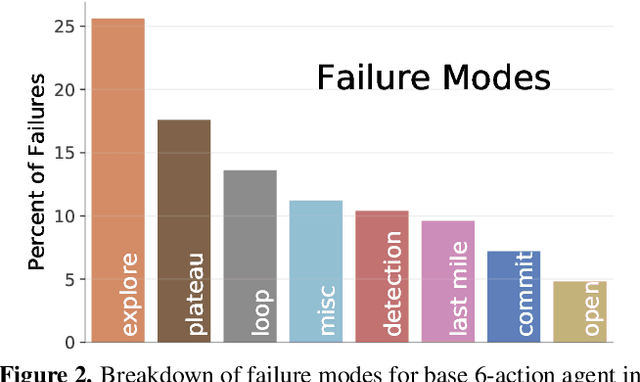
ObjectGoal Navigation (ObjectNav) is an embodied task wherein agents are to navigate to an object instance in an unseen environment. Prior works have shown that end-to-end ObjectNav agents that use vanilla visual and recurrent modules, e.g. a CNN+RNN, perform poorly due to overfitting and sample inefficiency. This has motivated current state-of-the-art methods to mix analytic and learned components and operate on explicit spatial maps of the environment. We instead re-enable a generic learned agent by adding auxiliary learning tasks and an exploration reward. Our agents achieve 24.5% success and 8.1% SPL, a 37% and 8% relative improvement over prior state-of-the-art, respectively, on the Habitat ObjectNav Challenge. From our analysis, we propose that agents will act to simplify their visual inputs so as to smooth their RNN dynamics, and that auxiliary tasks reduce overfitting by minimizing effective RNN dimensionality; i.e. a performant ObjectNav agent that must maintain coherent plans over long horizons does so by learning smooth, low-dimensional recurrent dynamics. Site: https://joel99.github.io/objectnav/
Large Batch Simulation for Deep Reinforcement Learning
Mar 12, 2021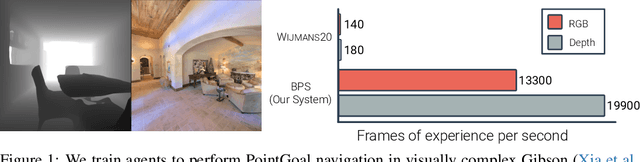
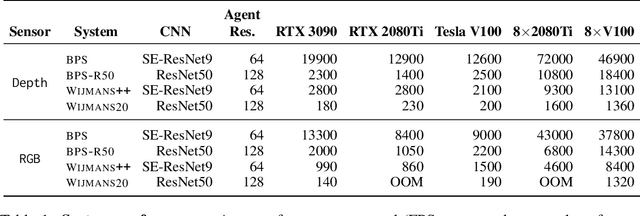
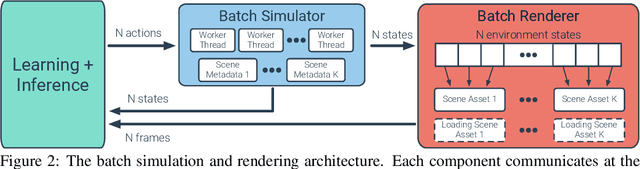
We accelerate deep reinforcement learning-based training in visually complex 3D environments by two orders of magnitude over prior work, realizing end-to-end training speeds of over 19,000 frames of experience per second on a single GPU and up to 72,000 frames per second on a single eight-GPU machine. The key idea of our approach is to design a 3D renderer and embodied navigation simulator around the principle of "batch simulation": accepting and executing large batches of requests simultaneously. Beyond exposing large amounts of work at once, batch simulation allows implementations to amortize in-memory storage of scene assets, rendering work, data loading, and synchronization costs across many simulation requests, dramatically improving the number of simulated agents per GPU and overall simulation throughput. To balance DNN inference and training costs with faster simulation, we also build a computationally efficient policy DNN that maintains high task performance, and modify training algorithms to maintain sample efficiency when training with large mini-batches. By combining batch simulation and DNN performance optimizations, we demonstrate that PointGoal navigation agents can be trained in complex 3D environments on a single GPU in 1.5 days to 97% of the accuracy of agents trained on a prior state-of-the-art system using a 64-GPU cluster over three days. We provide open-source reference implementations of our batch 3D renderer and simulator to facilitate incorporation of these ideas into RL systems.
How to Train PointGoal Navigation Agents on a Budget
Dec 11, 2020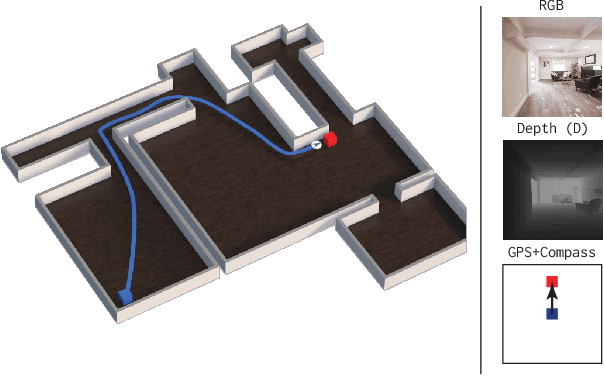
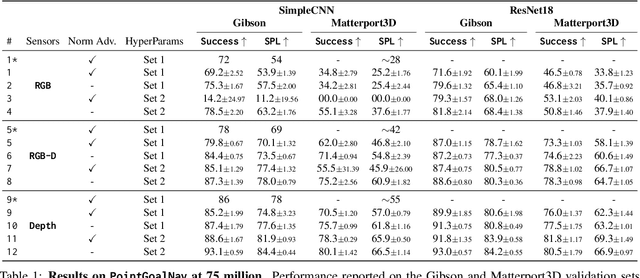
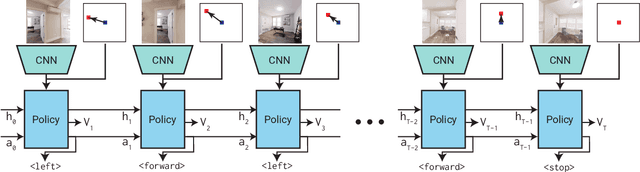
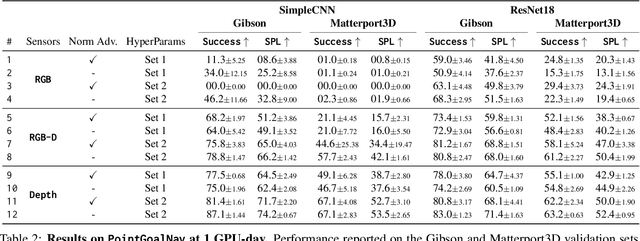
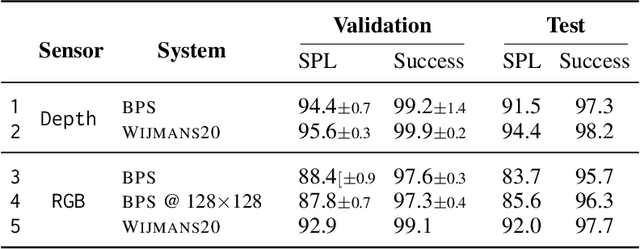
PointGoal navigation has seen significant recent interest and progress, spurred on by the Habitat platform and associated challenge. In this paper, we study PointGoal navigation under both a sample budget (75 million frames) and a compute budget (1 GPU for 1 day). We conduct an extensive set of experiments, cumulatively totaling over 50,000 GPU-hours, that let us identify and discuss a number of ostensibly minor but significant design choices -- the advantage estimation procedure (a key component in training), visual encoder architecture, and a seemingly minor hyper-parameter change. Overall, these design choices to lead considerable and consistent improvements over the baselines present in Savva et al. Under a sample budget, performance for RGB-D agents improves 8 SPL on Gibson (14% relative improvement) and 20 SPL on Matterport3D (38% relative improvement). Under a compute budget, performance for RGB-D agents improves by 19 SPL on Gibson (32% relative improvement) and 35 SPL on Matterport3D (220% relative improvement). We hope our findings and recommendations will make serve to make the community's experiments more efficient.
Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Jul 20, 2020
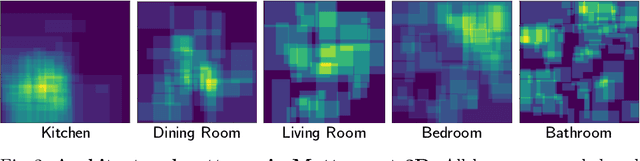
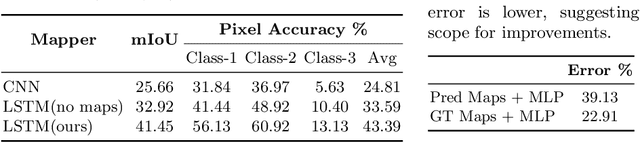
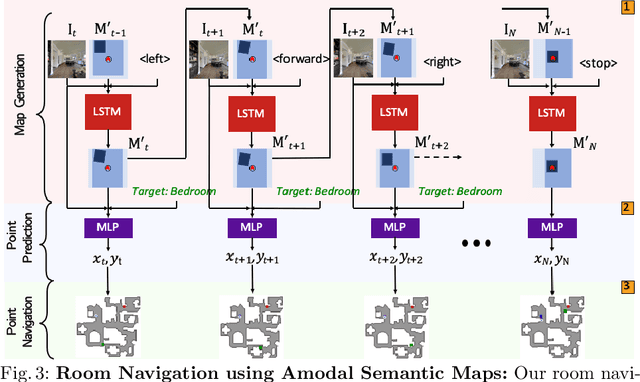
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent's field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further.
Auxiliary Tasks Speed Up Learning PointGoal Navigation
Jul 09, 2020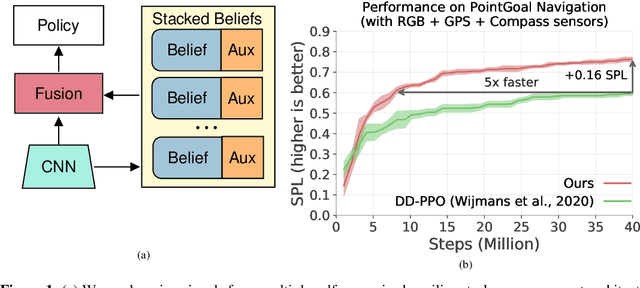

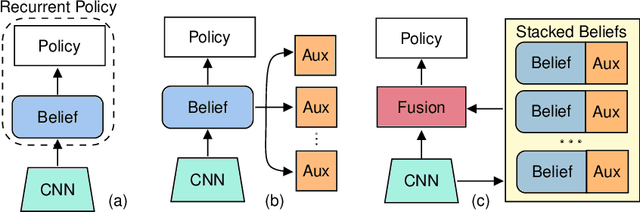
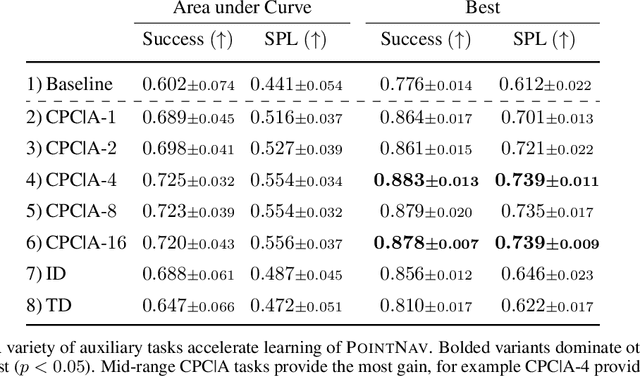
PointGoal Navigation is an embodied task that requires agents to navigate to a specified point in an unseen environment. Wijmans et al. showed that this task is solvable but their method is computationally prohibitive, requiring 2.5 billion frames and 180 GPU-days. In this work, we develop a method to significantly increase sample and time efficiency in learning PointNav using self-supervised auxiliary tasks (e.g. predicting the action taken between two egocentric observations, predicting the distance between two observations from a trajectory,etc.).We find that naively combining multiple auxiliary tasks improves sample efficiency,but only provides marginal gains beyond a point. To overcome this, we use attention to combine representations learnt from individual auxiliary tasks. Our best agent is 5x faster to reach the performance of the previous state-of-the-art, DD-PPO, at 40M frames, and improves on DD-PPO's performance at40M frames by 0.16 SPL. Our code is publicly available at https://github.com/joel99/habitat-pointnav-aux.
ObjectNav Revisited: On Evaluation of Embodied Agents Navigating to Objects
Jun 23, 2020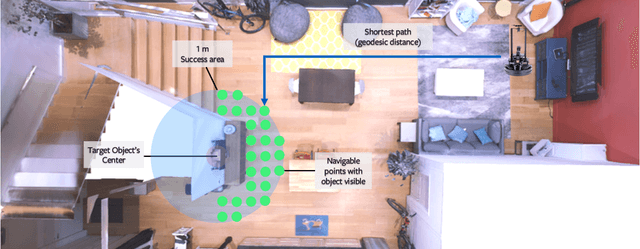

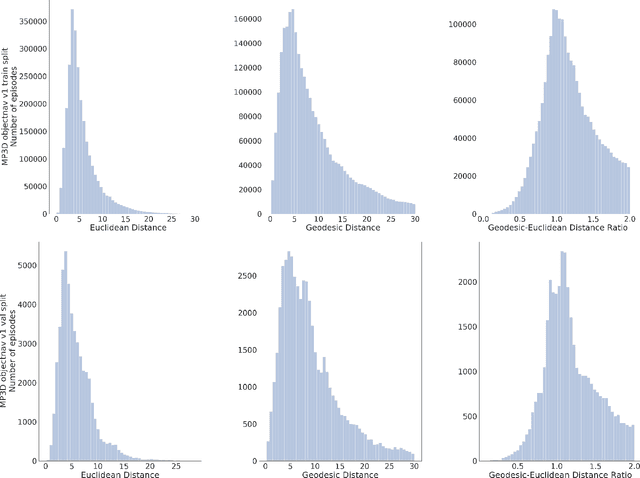
We revisit the problem of Object-Goal Navigation (ObjectNav). In its simplest form, ObjectNav is defined as the task of navigating to an object, specified by its label, in an unexplored environment. In particular, the agent is initialized at a random location and pose in an environment and asked to find an instance of an object category, e.g., find a chair, by navigating to it. As the community begins to show increased interest in semantic goal specification for navigation tasks, a number of different often-inconsistent interpretations of this task are emerging. This document summarizes the consensus recommendations of this working group on ObjectNav. In particular, we make recommendations on subtle but important details of evaluation criteria (for measuring success when navigating towards a target object), the agent's embodiment parameters, and the characteristics of the environments within which the task is carried out. Finally, we provide a detailed description of the instantiation of these recommendations in challenges organized at the Embodied AI workshop at CVPR 2020 \url{http://embodied-ai.org} .
Beyond the Nav-Graph: Vision-and-Language Navigation in Continuous Environments
Apr 06, 2020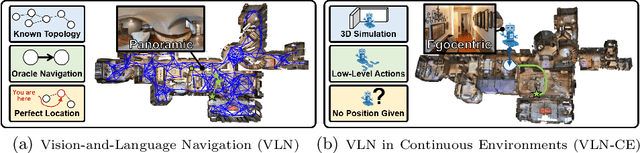


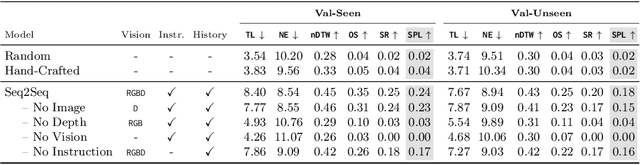
We develop a language-guided navigation task set in a continuous 3D environment where agents must execute low-level actions to follow natural language navigation directions. By being situated in continuous environments, this setting lifts a number of assumptions implicit in prior work that represents environments as a sparse graph of panoramas with edges corresponding to navigability. Specifically, our setting drops the presumptions of known environment topologies, short-range oracle navigation, and perfect agent localization. To contextualize this new task, we develop models that mirror many of the advances made in prior settings as well as single-modality baselines. While some of these techniques transfer, we find significantly lower absolute performance in the continuous setting -- suggesting that performance in prior `navigation-graph' settings may be inflated by the strong implicit assumptions.
Analyzing Visual Representations in Embodied Navigation Tasks
Mar 12, 2020
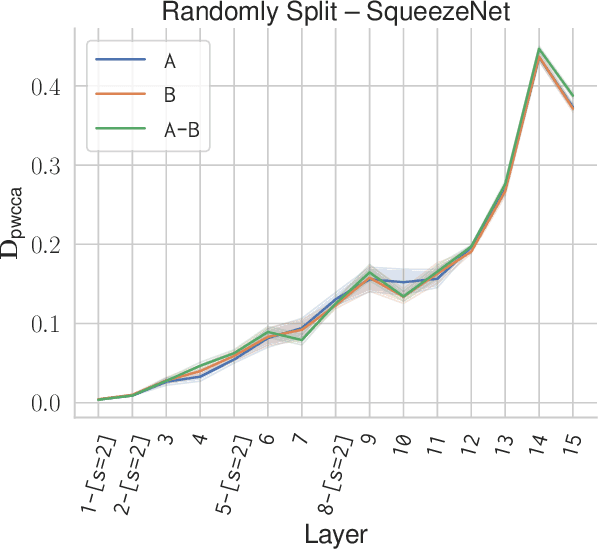
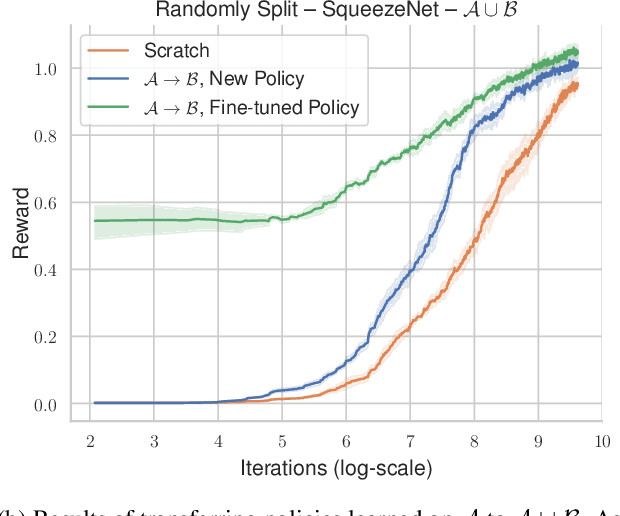
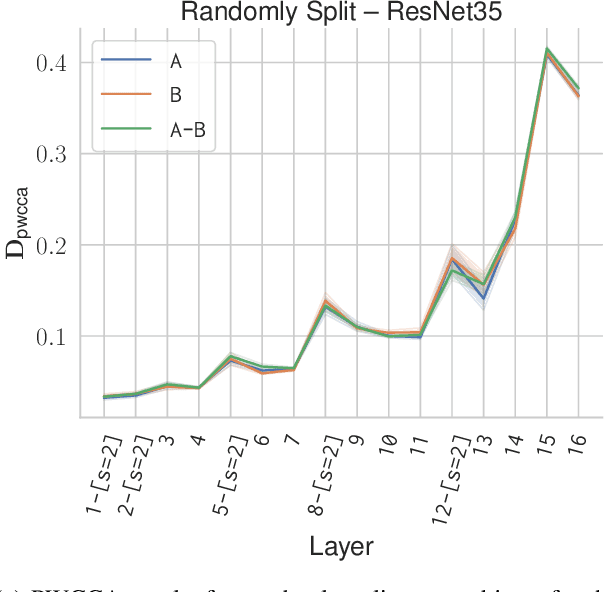
Recent advances in deep reinforcement learning require a large amount of training data and generally result in representations that are often over specialized to the target task. In this work, we present a methodology to study the underlying potential causes for this specialization. We use the recently proposed projection weighted Canonical Correlation Analysis (PWCCA) to measure the similarity of visual representations learned in the same environment by performing different tasks. We then leverage our proposed methodology to examine the task dependence of visual representations learned on related but distinct embodied navigation tasks. Surprisingly, we find that slight differences in task have no measurable effect on the visual representation for both SqueezeNet and ResNet architectures. We then empirically demonstrate that visual representations learned on one task can be effectively transferred to a different task.