 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Graph Contrastive Learning
Jun 17, 2021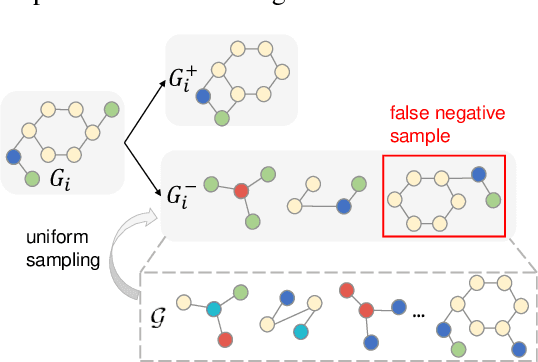
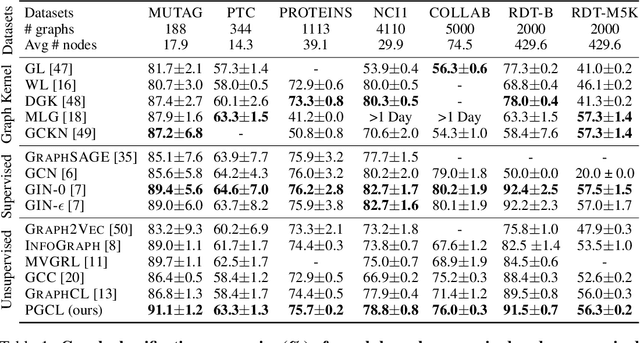
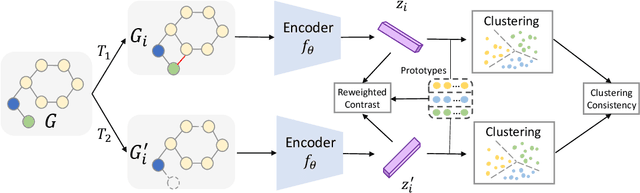
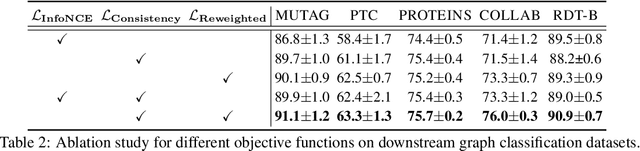
Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods.
Negational Symmetry of Quantum Neural Networks for Binary Pattern Classification
May 20, 2021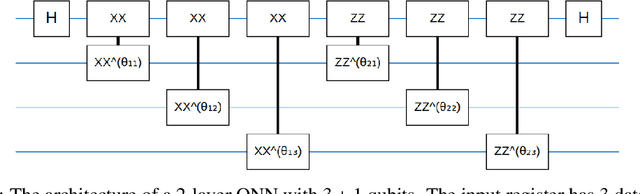
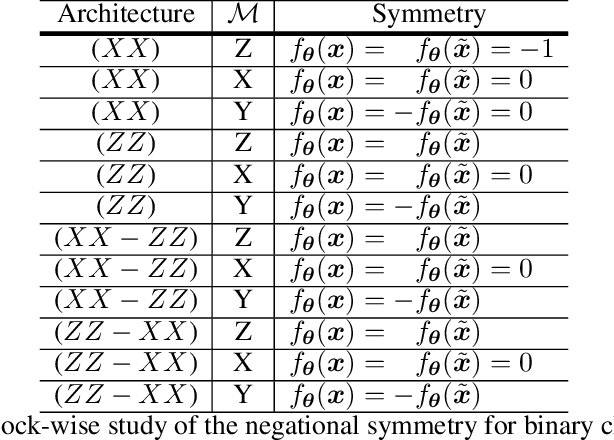
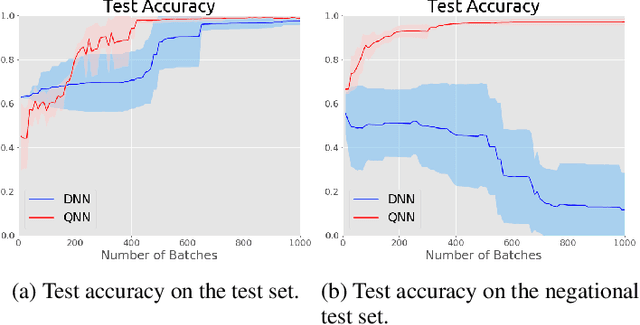
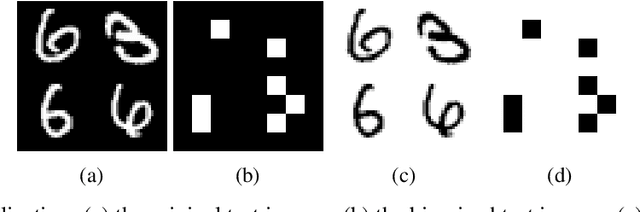
Entanglement is a physical phenomenon, which has fueled recent successes of quantum algorithms. Although quantum neural networks (QNNs) have shown promising results in solving simple machine learning tasks recently, for the time being, the effect of entanglement in QNNs and the behavior of QNNs in binary pattern classification are still underexplored. In this work, we provide some theoretical insight into the properties of QNNs by presenting and analyzing a new form of invariance embedded in QNNs for both quantum binary classification and quantum representation learning, which we term negational symmetry. Given a quantum binary signal and its negational counterpart where a bitwise NOT operation is applied to each quantum bit of the binary signal, a QNN outputs the same logits. That is to say, QNNs cannot differentiate a quantum binary signal and its negational counterpart in a binary classification task. We further empirically evaluate the negational symmetry of QNNs in binary pattern classification tasks using Google's quantum computing framework. The theoretical and experimental results suggest that negational symmetry is a fundamental property of QNNs, which is not shared by classical models. Our findings also imply that negational symmetry is a double-edged sword in practical quantum applications.
Active Learning to Classify Macromolecular Structures in situ for Less Supervision in Cryo-Electron Tomography
Feb 24, 2021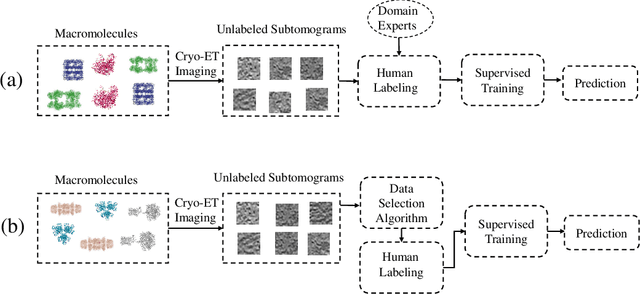
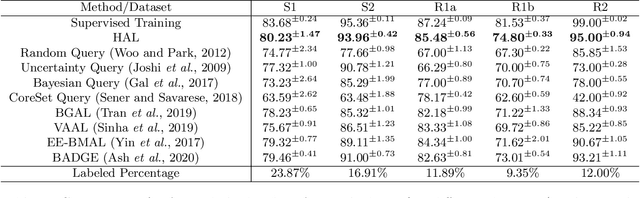
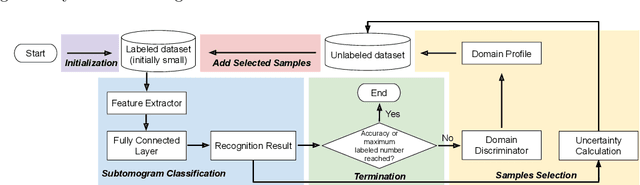

Motivation: Cryo-Electron Tomography (cryo-ET) is a 3D bioimaging tool that visualizes the structural and spatial organization of macromolecules at a near-native state in single cells, which has broad applications in life science. However, the systematic structural recognition and recovery of macromolecules captured by cryo-ET are difficult due to high structural complexity and imaging limits. Deep learning based subtomogram classification have played critical roles for such tasks. As supervised approaches, however, their performance relies on sufficient and laborious annotation on a large training dataset. Results: To alleviate this major labeling burden, we proposed a Hybrid Active Learning (HAL) framework for querying subtomograms for labelling from a large unlabeled subtomogram pool. Firstly, HAL adopts uncertainty sampling to select the subtomograms that have the most uncertain predictions. Moreover, to mitigate the sampling bias caused by such strategy, a discriminator is introduced to judge if a certain subtomogram is labeled or unlabeled and subsequently the model queries the subtomogram that have higher probabilities to be unlabeled. Additionally, HAL introduces a subset sampling strategy to improve the diversity of the query set, so that the information overlap is decreased between the queried batches and the algorithmic efficiency is improved. Our experiments on subtomogram classification tasks using both simulated and real data demonstrate that we can achieve comparable testing performance (on average only 3% accuracy drop) by using less than 30% of the labeled subtomograms, which shows a very promising result for subtomogram classification task with limited labeling resources.
On Data Efficiency of Meta-learning
Jan 30, 2021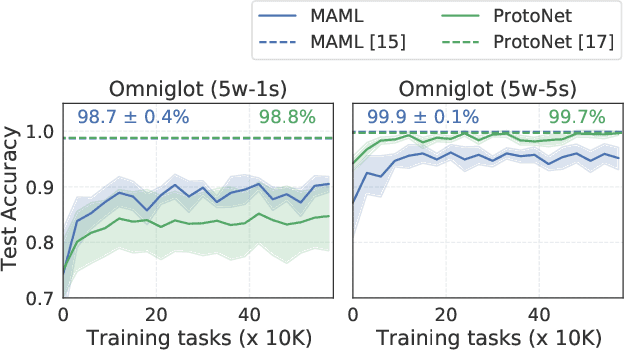
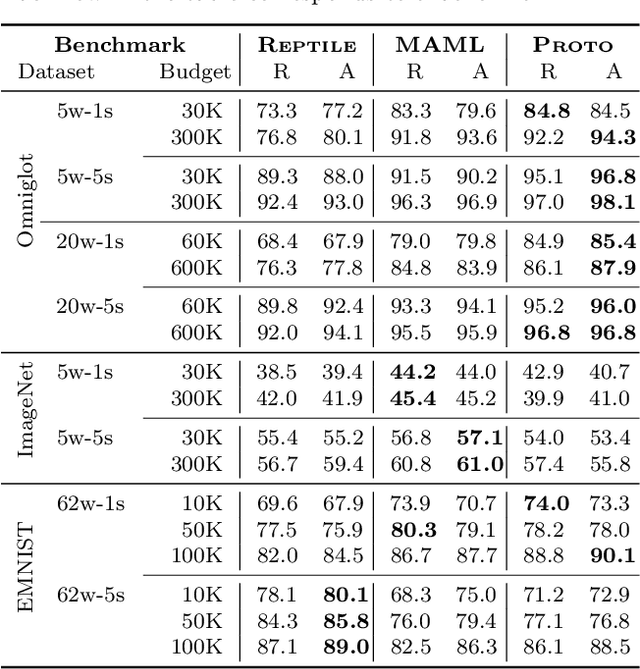

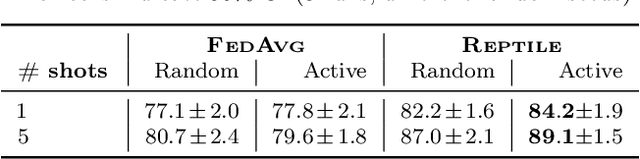
Meta-learning has enabled learning statistical models that can be quickly adapted to new prediction tasks. Motivated by use-cases in personalized federated learning, we study the often overlooked aspect of the modern meta-learning algorithms -- their data efficiency. To shed more light on which methods are more efficient, we use techniques from algorithmic stability to derive bounds on the transfer risk that have important practical implications, indicating how much supervision is needed and how it must be allocated for each method to attain the desired level of generalization. Further, we introduce a new simple framework for evaluating meta-learning methods under a limit on the available supervision, conduct an empirical study of MAML, Reptile, and Protonets, and demonstrate the differences in the behavior of these methods on few-shot and federated learning benchmarks. Finally, we propose active meta-learning, which incorporates active data selection into learning-to-learn, leading to better performance of all methods in the limited supervision regime.
Interactive Weak Supervision: Learning Useful Heuristics for Data Labeling
Dec 11, 2020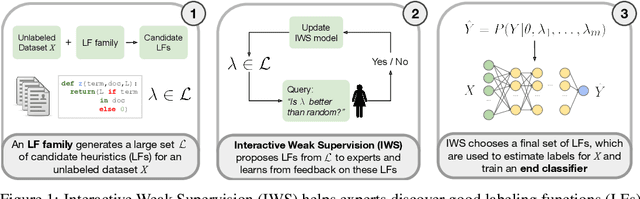
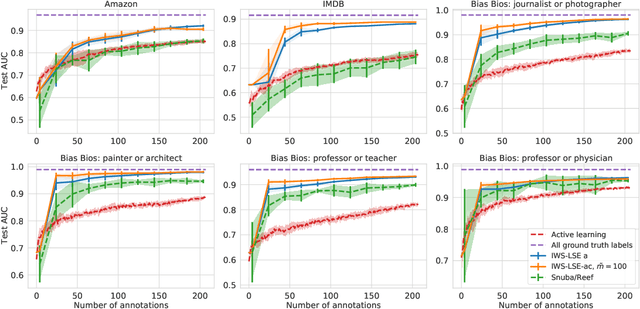
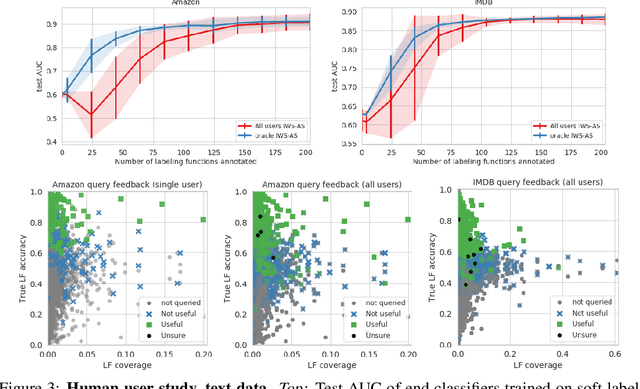
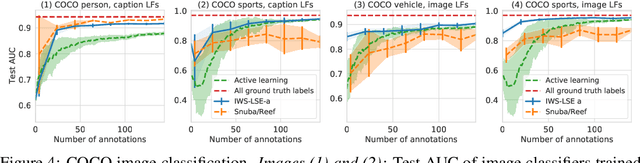
Obtaining large annotated datasets is critical for training successful machine learning models and it is often a bottleneck in practice. Weak supervision offers a promising alternative for producing labeled datasets without ground truth annotations by generating probabilistic labels using multiple noisy heuristics. This process can scale to large datasets and has demonstrated state of the art performance in diverse domains such as healthcare and e-commerce. One practical issue with learning from user-generated heuristics is that their creation requires creativity, foresight, and domain expertise from those who hand-craft them, a process which can be tedious and subjective. We develop the first framework for interactive weak supervision in which a method proposes heuristics and learns from user feedback given on each proposed heuristic. Our experiments demonstrate that only a small number of feedback iterations are needed to train models that achieve highly competitive test set performance without access to ground truth training labels. We conduct user studies, which show that users are able to effectively provide feedback on heuristics and that test set results track the performance of simulated oracles.
Federated Learning via Posterior Averaging: A New Perspective and Practical Algorithms
Oct 11, 2020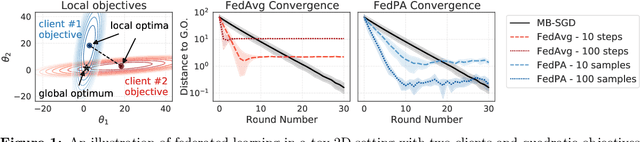

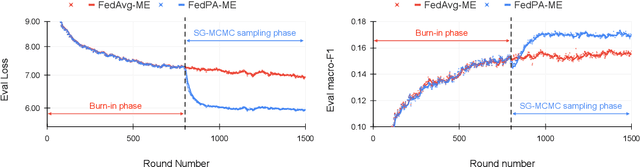
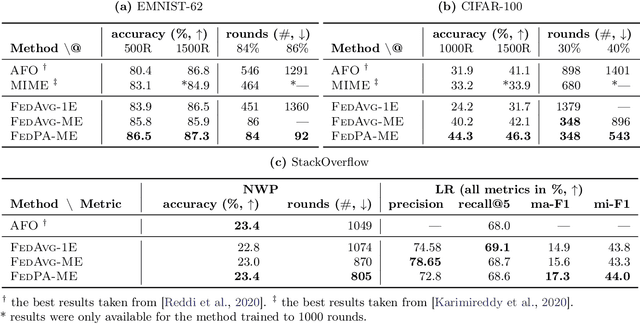
Federated learning is typically approached as an optimization problem, where the goal is to minimize a global loss function by distributing computation across client devices that possess local data and specify different parts of the global objective. We present an alternative perspective and formulate federated learning as a posterior inference problem, where the goal is to infer a global posterior distribution by having client devices each infer the posterior of their local data. While exact inference is often intractable, this perspective provides a principled way to search for global optima in federated settings. Further, starting with the analysis of federated quadratic objectives, we develop a computation- and communication-efficient approximate posterior inference algorithm -- federated posterior averaging (FedPA). Our algorithm uses MCMC for approximate inference of local posteriors on the clients and efficiently communicates their statistics to the server, where the latter uses them to refine a global estimate of the posterior mode. Finally, we show that FedPA generalizes federated averaging (FedAvg), can similarly benefit from adaptive optimizers, and yields state-of-the-art results on four realistic and challenging benchmarks, converging faster, to better optima.
Pathological Visual Question Answering
Oct 06, 2020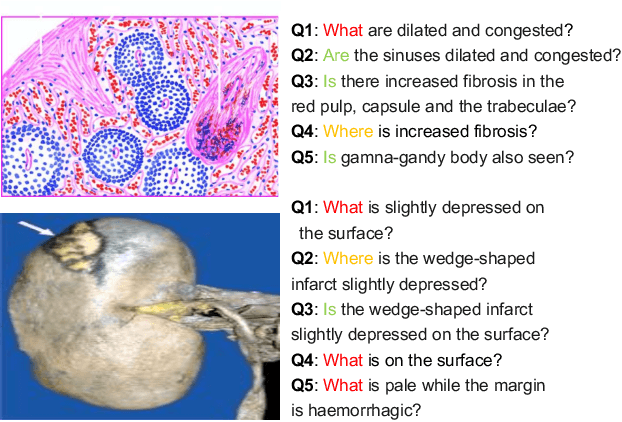
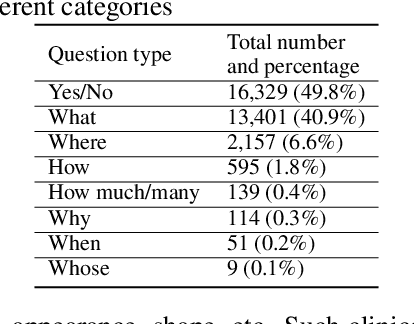
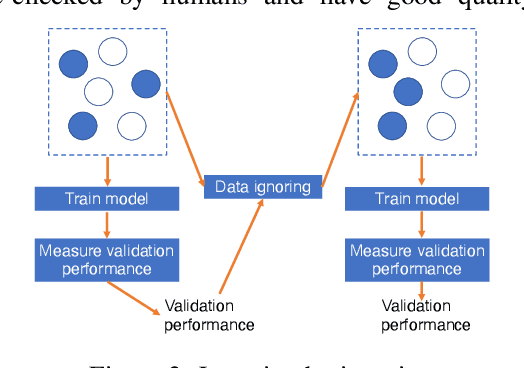
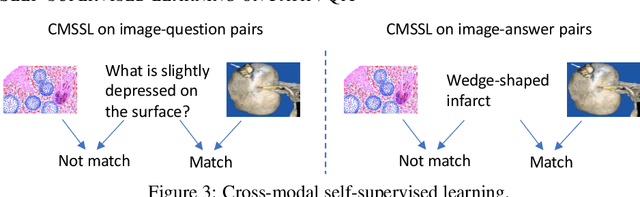
Is it possible to develop an "AI Pathologist" to pass the board-certified examination of the American Board of Pathology (ABP)? To build such a system, three challenges need to be addressed. First, we need to create a visual question answering (VQA) dataset where the AI agent is presented with a pathology image together with a question and is asked to give the correct answer. Due to privacy concerns, pathology images are usually not publicly available. Besides, only well-trained pathologists can understand pathology images, but they barely have time to help create datasets for AI research. The second challenge is: since it is difficult to hire highly experienced pathologists to create pathology visual questions and answers, the resulting pathology VQA dataset may contain errors. Training pathology VQA models using these noisy or even erroneous data will lead to problematic models that cannot generalize well on unseen images. The third challenge is: the medical concepts and knowledge covered in pathology question-answer (QA) pairs are very diverse while the number of QA pairs available for modeling training is limited. How to learn effective representations of diverse medical concepts based on limited data is technically demanding. In this paper, we aim to address these three challenges. To our best knowledge, our work represents the first one addressing the pathology VQA problem. To deal with the issue that a publicly available pathology VQA dataset is lacking, we create PathVQA dataset. To address the second challenge, we propose a learning-by-ignoring approach. To address the third challenge, we propose to use cross-modal self-supervised learning. We perform experiments on our created PathVQA dataset and the results demonstrate the effectiveness of our proposed learning-by-ignoring method and cross-modal self-supervised learning methods.
XRayGAN: Consistency-preserving Generation of X-ray Images from Radiology Reports
Jun 17, 2020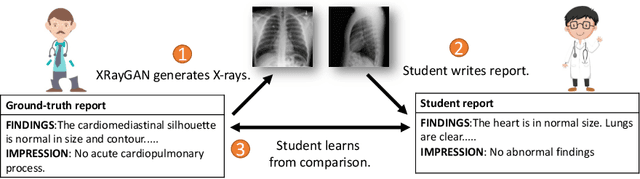
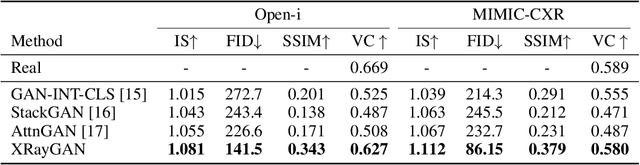
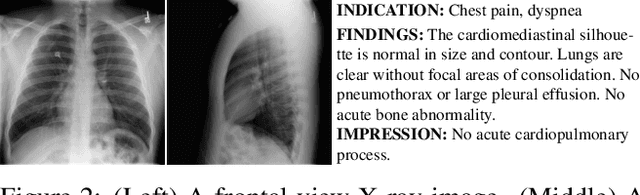
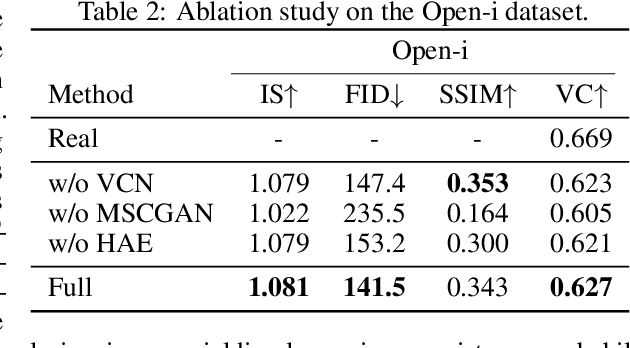
To effectively train medical students to become qualified radiologists, a large number of X-ray images collected from patients with diverse medical conditions are needed. However, due to data privacy concerns, such images are typically difficult to obtain. To address this problem, we develop methods to generate view-consistent, high-fidelity, and high-resolution X-ray images from radiology reports to facilitate radiology training of medical students. This task is presented with several challenges. First, from a single report, images with different views (e.g., frontal, lateral) need to be generated. How to ensure consistency of these images (i.e., make sure they are about the same patient)? Second, X-ray images are required to have high resolution. Otherwise, many details of diseases would be lost. How to generate high-resolutions images? Third, radiology reports are long and have complicated structure. How to effectively understand their semantics to generate high-fidelity images that accurately reflect the contents of the reports? To address these three challenges, we propose an XRayGAN composed of three modules: (1) a view consistency network that maximizes the consistency between generated frontal-view and lateral-view images; (2) a multi-scale conditional GAN that progressively generates a cascade of images with increasing resolution; (3) a hierarchical attentional encoder that learns the latent semantics of a radiology report by capturing its hierarchical linguistic structure and various levels of clinical importance of words and sentences. Experiments on two radiology datasets demonstrate the effectiveness of our methods. To our best knowledge, this work represents the first one generating consistent and high-resolution X-ray images from radiology reports. The code is available at https://github.com/UCSD-AI4H/XRayGAN.
On the Generation of Medical Dialogues for COVID-19
May 11, 2020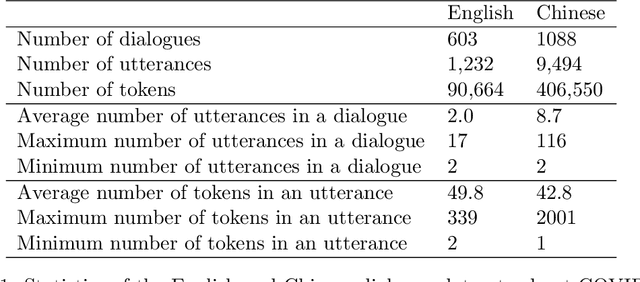

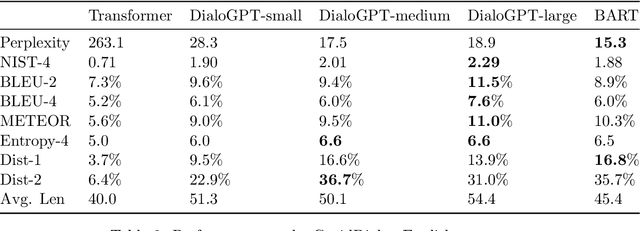

Under the pandemic of COVID-19, people experiencing COVID19-related symptoms or exposed to risk factors have a pressing need to consult doctors. Due to hospital closure, a lot of consulting services have been moved online. Because of the shortage of medical professionals, many people cannot receive online consultations timely. To address this problem, we aim to develop a medical dialogue system that can provide COVID19-related consultations. We collected two dialogue datasets -CovidDialog- (in English and Chinese respectively) containing conversations between doctors and patients about COVID-19. On these two datasets, we train several dialogue generation models based on Transformer, GPT, and BERT-GPT. Since the two COVID-19 dialogue datasets are small in size, which bears high risk of overfitting, we leverage transfer learning to mitigate data deficiency. Specifically, we take the pretrained models of Transformer, GPT, and BERT-GPT on dialog datasets and other large-scale texts, then finetune them on our CovidDialog datasets. Experiments demonstrate that these approaches are promising in generating meaningful medical dialogues about COVID-19. But more advanced approaches are needed to build a fully useful dialogue system that can offer accurate COVID-related consultations. The data and code are available at https://github.com/UCSD-AI4H/COVID-Dialogue
Show, Describe and Conclude: On Exploiting the Structure Information of Chest X-Ray Reports
Apr 26, 2020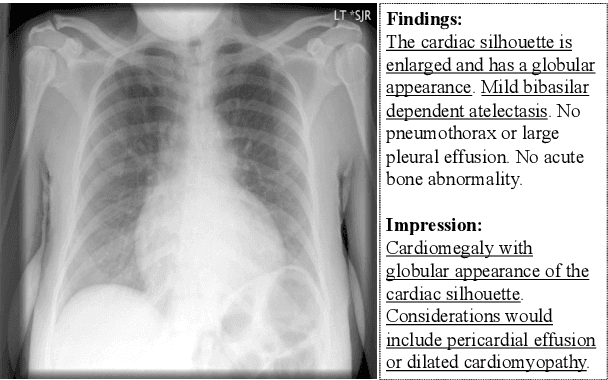
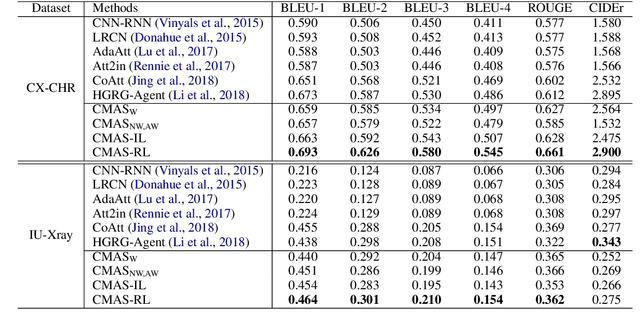
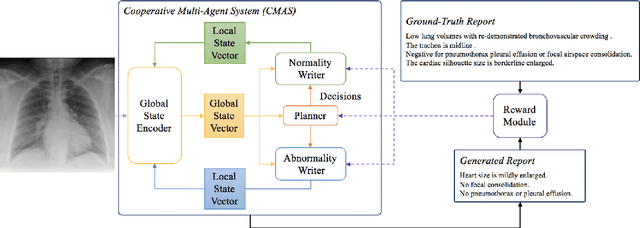
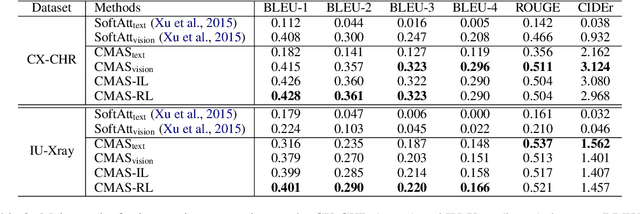
Chest X-Ray (CXR) images are commonly used for clinical screening and diagnosis. Automatically writing reports for these images can considerably lighten the workload of radiologists for summarizing descriptive findings and conclusive impressions. The complex structures between and within sections of the reports pose a great challenge to the automatic report generation. Specifically, the section Impression is a diagnostic summarization over the section Findings; and the appearance of normality dominates each section over that of abnormality. Existing studies rarely explore and consider this fundamental structure information. In this work, we propose a novel framework that exploits the structure information between and within report sections for generating CXR imaging reports. First, we propose a two-stage strategy that explicitly models the relationship between Findings and Impression. Second, we design a novel cooperative multi-agent system that implicitly captures the imbalanced distribution between abnormality and normality. Experiments on two CXR report datasets show that our method achieves state-of-the-art performance in terms of various evaluation metrics. Our results expose that the proposed approach is able to generate high-quality medical reports through integrating the structure information.