 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoLatent: Video-Language Learning via Latent Self-Forcing
Jun 22, 2026Recent advancements in chain-of-thought (CoT) reasoning have shown promise in enhancing video understanding and reasoning capabilities of multimodal large language models (MLLMs). However, existing CoT-based MLLMs require labor-intensive CoT annotations and incur substantial training and inference overhead. While visual latent reasoning has emerged as a more efficient alternative, existing methods primarily focus on image tasks and heavily rely on additional supervision signals for visual latent generation (e.g., CoT traces, auxiliary images, or fine-grained annotations), limiting their scalability and transferability to video tasks. To bridge this gap, we introduce VideoLatent, a novel MLLM equipped with a latent injection module tailored for video understanding and reasoning. Specifically, VideoLatent learns to perform visual latent reasoning using a new latent self-forcing training paradigm, which comprises latent alignment and latent diversity objectives, and relies solely on standard video-question-answer triplets. Extensive experiments across 14 benchmarks demonstrate that our model consistently outperforms existing standard and latent MLLMs on general video understanding and complex video reasoning. Compared with Video-R1, our VideoLatent achieves superior computational efficiency, reducing training/inference overhead by $\sim$6$\times$/$\sim$68$\times$. Moreover, experiments demonstrate that our method has strong generalizability to different MLLM backbones and different model scales.
Rethinking Chain-of-Thought Reasoning for Videos
Dec 10, 2025Chain-of-thought (CoT) reasoning has been highly successful in solving complex tasks in natural language processing, and recent multimodal large language models (MLLMs) have extended this paradigm to video reasoning. However, these models typically build on lengthy reasoning chains and large numbers of input visual tokens. Motivated by empirical observations from our benchmark study, we hypothesize that concise reasoning combined with a reduced set of visual tokens can be sufficient for effective video reasoning. To evaluate this hypothesis, we design and validate an efficient post-training and inference framework that enhances a video MLLM's reasoning capability. Our framework enables models to operate on compressed visual tokens and generate brief reasoning traces prior to answering. The resulting models achieve substantially improved inference efficiency, deliver competitive performance across diverse benchmarks, and avoid reliance on manual CoT annotations or supervised fine-tuning. Collectively, our results suggest that long, human-like CoT reasoning may not be necessary for general video reasoning, and that concise reasoning can be both effective and efficient. Our code will be released at https://github.com/LaVi-Lab/Rethink_CoT_Video.
Enhancing Temporal Modeling of Video LLMs via Time Gating
Oct 08, 2024



Video Large Language Models (Video LLMs) have achieved impressive performance on video-and-language tasks, such as video question answering. However, most existing Video LLMs neglect temporal information in video data, leading to struggles with temporal-aware video understanding. To address this gap, we propose a Time Gating Video LLM (TG-Vid) designed to enhance temporal modeling through a novel Time Gating module (TG). The TG module employs a time gating mechanism on its sub-modules, comprising gating spatial attention, gating temporal attention, and gating MLP. This architecture enables our model to achieve a robust understanding of temporal information within videos. Extensive evaluation of temporal-sensitive video benchmarks (i.e., MVBench, TempCompass, and NExT-QA) demonstrates that our TG-Vid model significantly outperforms the existing Video LLMs. Further, comprehensive ablation studies validate that the performance gains are attributed to the designs of our TG module. Our code is available at https://github.com/LaVi-Lab/TG-Vid.
Beyond Embeddings: The Promise of Visual Table in Multi-Modal Models
Mar 27, 2024



Visual representation learning has been a cornerstone in computer vision, evolving from supervised learning with human-annotated labels to aligning image-text pairs from the Internet. Despite recent advancements in multi-modal large language models (MLLMs), the visual representations they rely on, such as CLIP embeddings, often lack access to external world knowledge critical for real-world visual reasoning. In this work, we propose Visual Table, a novel visual representation tailored for MLLMs. It provides hierarchical text descriptions of holistic visual scenes, consisting of a scene description and multiple object-centric descriptions that encompass categories, attributes, and knowledge at instance level. We further develop a scalable generator for visual table generation and train it on small-scale annotations from GPT4V. Extensive evaluations demonstrate that, with generated visual tables as additional visual representations, our model can consistently outperform the state-of-the-art (SOTA) MLLMs across diverse benchmarks. When visual tables serve as standalone visual representations, our model can closely match or even beat the SOTA MLLMs that are built on CLIP visual embeddings. Our code is available at https://github.com/LaVi-Lab/Visual-Table.
VL-PET: Vision-and-Language Parameter-Efficient Tuning via Granularity Control
Aug 18, 2023



As the model size of pre-trained language models (PLMs) grows rapidly, full fine-tuning becomes prohibitively expensive for model training and storage. In vision-and-language (VL), parameter-efficient tuning (PET) techniques are proposed to integrate modular modifications (e.g., Adapter and LoRA) into encoder-decoder PLMs. By tuning a small set of trainable parameters, these techniques perform on par with full fine-tuning. However, excessive modular modifications and neglecting the functionality gap between the encoders and decoders can lead to performance degradation, while existing PET techniques (e.g., VL-Adapter) overlook these critical issues. In this paper, we propose a Vision-and-Language Parameter-Efficient Tuning (VL-PET) framework to impose effective control over modular modifications via a novel granularity-controlled mechanism. Considering different granularity-controlled matrices generated by this mechanism, a variety of model-agnostic VL-PET modules can be instantiated from our framework for better efficiency and effectiveness trade-offs. We further propose lightweight PET module designs to enhance VL alignment and modeling for the encoders and maintain text generation for the decoders. Extensive experiments conducted on four image-text tasks and four video-text tasks demonstrate the efficiency, effectiveness and transferability of our VL-PET framework. In particular, our VL-PET-large with lightweight PET module designs significantly outperforms VL-Adapter by 2.92% (3.41%) and LoRA by 3.37% (7.03%) with BART-base (T5-base) on image-text tasks. Furthermore, we validate the enhanced effect of employing our VL-PET designs on existing PET techniques, enabling them to achieve significant performance improvements. Our code is available at https://github.com/HenryHZY/VL-PET.
CLEVA: Chinese Language Models EVAluation Platform
Aug 09, 2023



With the continuous emergence of Chinese Large Language Models (LLMs), how to evaluate a model's capabilities has become an increasingly significant issue. The absence of a comprehensive Chinese benchmark that thoroughly assesses a model's performance, the unstandardized and incomparable prompting procedure, and the prevalent risk of contamination pose major challenges in the current evaluation of Chinese LLMs. We present CLEVA, a user-friendly platform crafted to holistically evaluate Chinese LLMs. Our platform employs a standardized workflow to assess LLMs' performance across various dimensions, regularly updating a competitive leaderboard. To alleviate contamination, CLEVA curates a significant proportion of new data and develops a sampling strategy that guarantees a unique subset for each leaderboard round. Empowered by an easy-to-use interface that requires just a few mouse clicks and a model API, users can conduct a thorough evaluation with minimal coding. Large-scale experiments featuring 23 influential Chinese LLMs have validated CLEVA's efficacy.
Prototypical Graph Contrastive Learning
Jun 17, 2021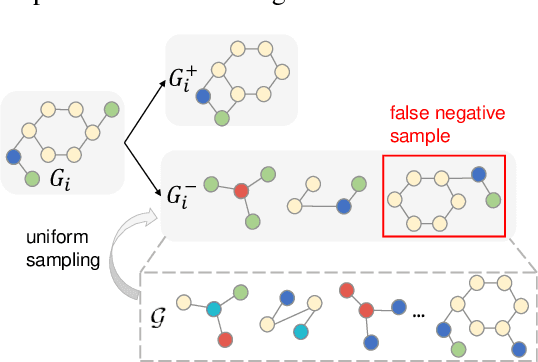
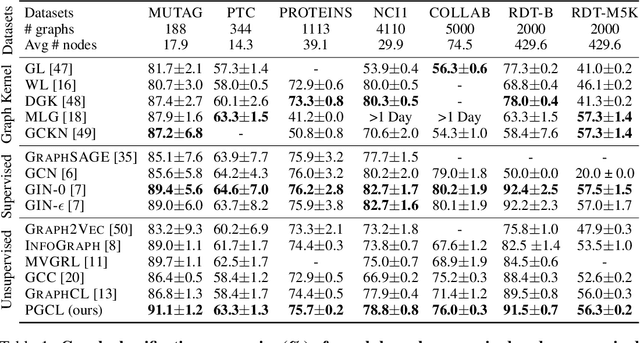
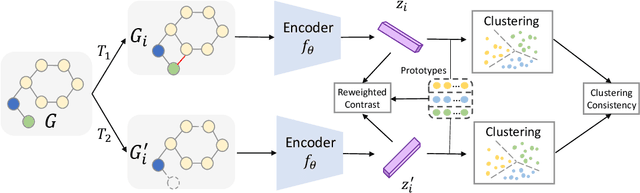
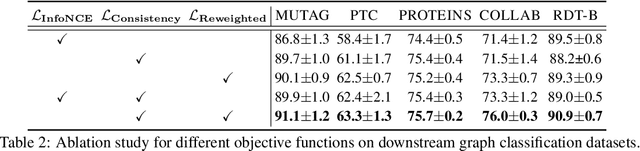
Graph-level representations are critical in various real-world applications, such as predicting the properties of molecules. But in practice, precise graph annotations are generally very expensive and time-consuming. To address this issue, graph contrastive learning constructs instance discrimination task which pulls together positive pairs (augmentation pairs of the same graph) and pushes away negative pairs (augmentation pairs of different graphs) for unsupervised representation learning. However, since for a query, its negatives are uniformly sampled from all graphs, existing methods suffer from the critical sampling bias issue, i.e., the negatives likely having the same semantic structure with the query, leading to performance degradation. To mitigate this sampling bias issue, in this paper, we propose a Prototypical Graph Contrastive Learning (PGCL) approach. Specifically, PGCL models the underlying semantic structure of the graph data via clustering semantically similar graphs into the same group, and simultaneously encourages the clustering consistency for different augmentations of the same graph. Then given a query, it performs negative sampling via drawing the graphs from those clusters that differ from the cluster of query, which ensures the semantic difference between query and its negative samples. Moreover, for a query, PGCL further reweights its negative samples based on the distance between their prototypes (cluster centroids) and the query prototype such that those negatives having moderate prototype distance enjoy relatively large weights. This reweighting strategy is proved to be more effective than uniform sampling. Experimental results on various graph benchmarks testify the advantages of our PGCL over state-of-the-art methods.
BCFNet: A Balanced Collaborative Filtering Network with Attention Mechanism
Mar 10, 2021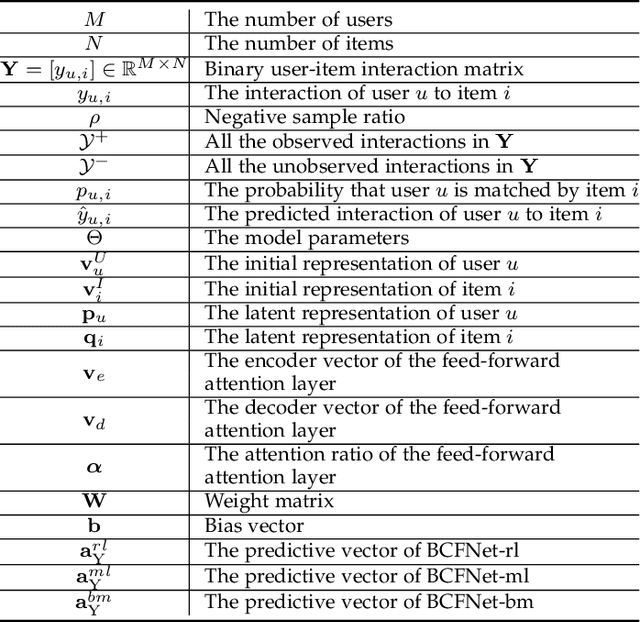
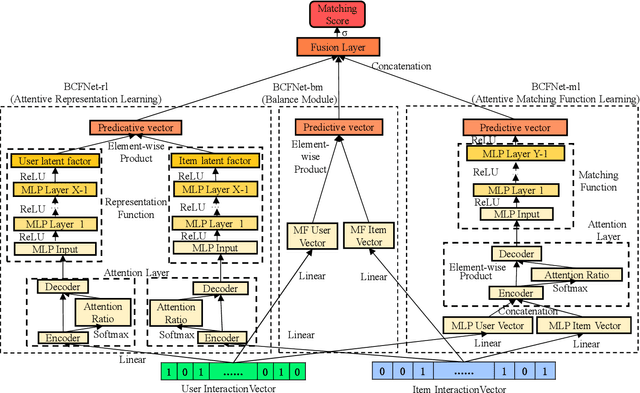
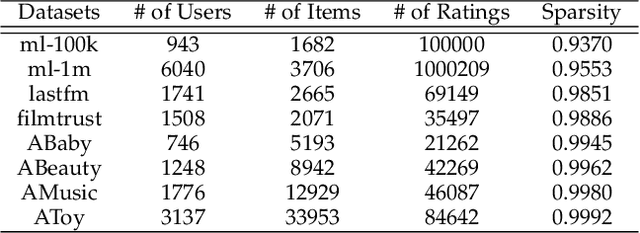
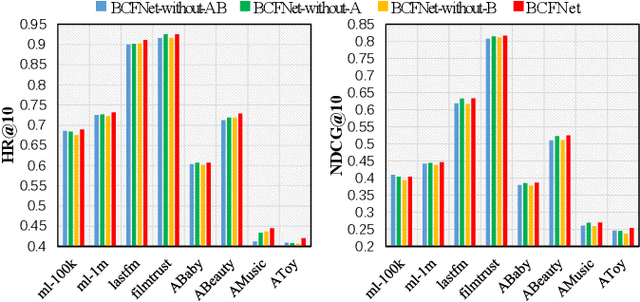
Collaborative Filtering (CF) based recommendation methods have been widely studied, which can be generally categorized into two types, i.e., representation learning-based CF methods and matching function learning-based CF methods. Representation learning tries to learn a common low dimensional space for the representations of users and items. In this case, a user and item match better if they have higher similarity in that common space. Matching function learning tries to directly learn the complex matching function that maps user-item pairs to matching scores. Although both methods are well developed, they suffer from two fundamental flaws, i.e., the representation learning resorts to applying a dot product which has limited expressiveness on the latent features of users and items, while the matching function learning has weakness in capturing low-rank relations. To overcome such flaws, we propose a novel recommendation model named Balanced Collaborative Filtering Network (BCFNet), which has the strengths of the two types of methods. In addition, an attention mechanism is designed to better capture the hidden information within implicit feedback and strengthen the learning ability of the neural network. Furthermore, a balance module is designed to alleviate the over-fitting issue in DNNs. Extensive experiments on eight real-world datasets demonstrate the effectiveness of the proposed model.