 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt Takes Two: Masked Appearance-Motion Modeling for Self-supervised Video Transformer Pre-training
Oct 11, 2022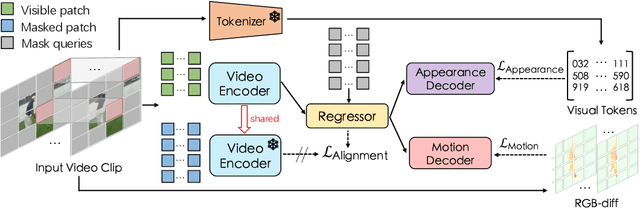

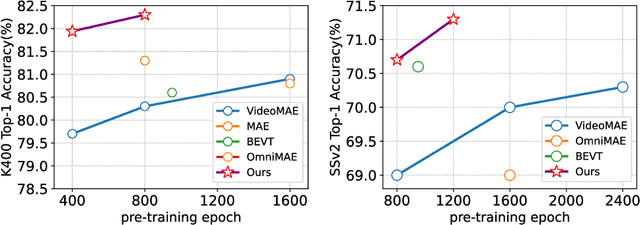
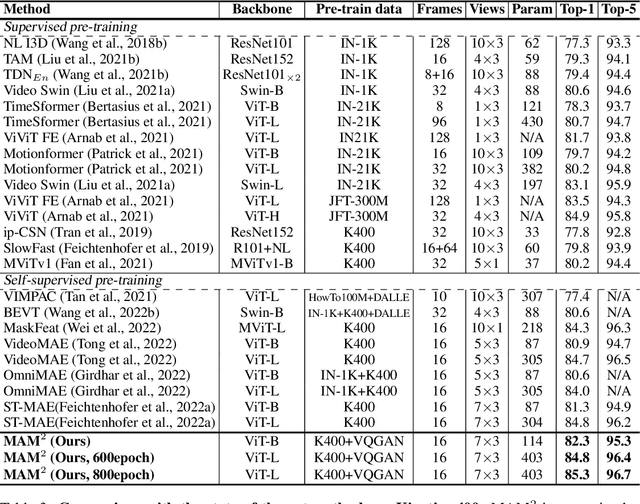
Self-supervised video transformer pre-training has recently benefited from the mask-and-predict pipeline. They have demonstrated outstanding effectiveness on downstream video tasks and superior data efficiency on small datasets. However, temporal relation is not fully exploited by these methods. In this work, we explicitly investigate motion cues in videos as extra prediction target and propose our Masked Appearance-Motion Modeling (MAM2) framework. Specifically, we design an encoder-regressor-decoder pipeline for this task. The regressor separates feature encoding and pretext tasks completion, such that the feature extraction process is completed adequately by the encoder. In order to guide the encoder to fully excavate spatial-temporal features, two separate decoders are used for two pretext tasks of disentangled appearance and motion prediction. We explore various motion prediction targets and figure out RGB-difference is simple yet effective. As for appearance prediction, VQGAN codes are leveraged as prediction target. With our pre-training pipeline, convergence can be remarkably speed up, e.g., we only require half of epochs than state-of-the-art VideoMAE (400 v.s. 800) to achieve the competitive performance. Extensive experimental results prove that our method learns generalized video representations. Notably, our MAM2 with ViT-B achieves 82.3% on Kinects-400, 71.3% on Something-Something V2, 91.5% on UCF101, and 62.5% on HMDB51.
Effective Invertible Arbitrary Image Rescaling
Sep 26, 2022
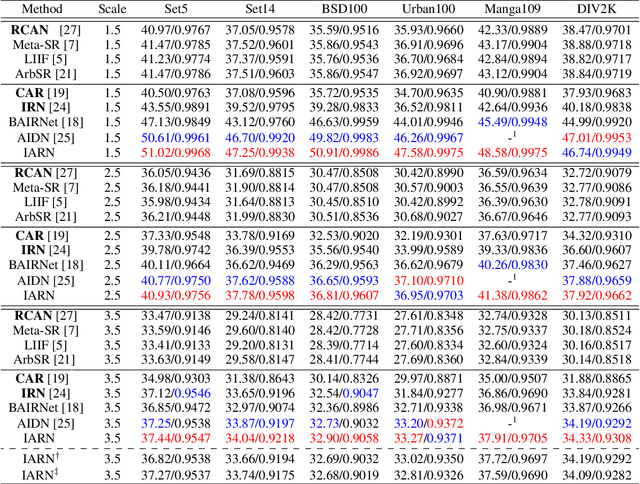
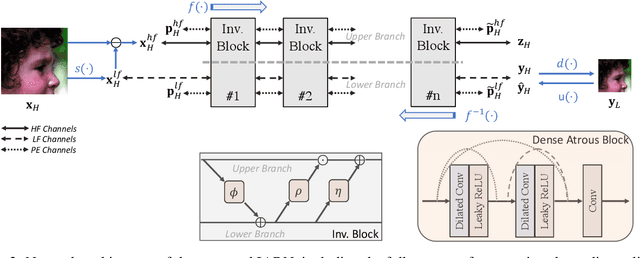
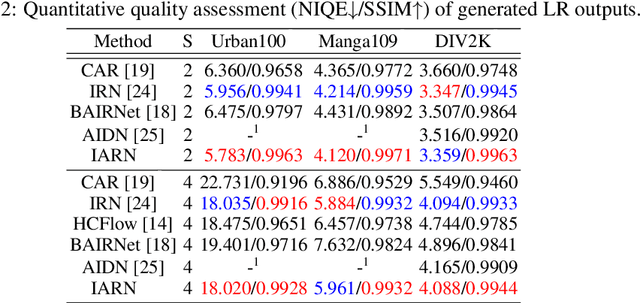
Great successes have been achieved using deep learning techniques for image super-resolution (SR) with fixed scales. To increase its real world applicability, numerous models have also been proposed to restore SR images with arbitrary scale factors, including asymmetric ones where images are resized to different scales along horizontal and vertical directions. Though most models are only optimized for the unidirectional upscaling task while assuming a predefined downscaling kernel for low-resolution (LR) inputs, recent models based on Invertible Neural Networks (INN) are able to increase upscaling accuracy significantly by optimizing the downscaling and upscaling cycle jointly. However, limited by the INN architecture, it is constrained to fixed integer scale factors and requires one model for each scale. Without increasing model complexity, a simple and effective invertible arbitrary rescaling network (IARN) is proposed to achieve arbitrary image rescaling by training only one model in this work. Using innovative components like position-aware scale encoding and preemptive channel splitting, the network is optimized to convert the non-invertible rescaling cycle to an effectively invertible process. It is shown to achieve a state-of-the-art (SOTA) performance in bidirectional arbitrary rescaling without compromising perceptual quality in LR outputs. It is also demonstrated to perform well on tests with asymmetric scales using the same network architecture.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022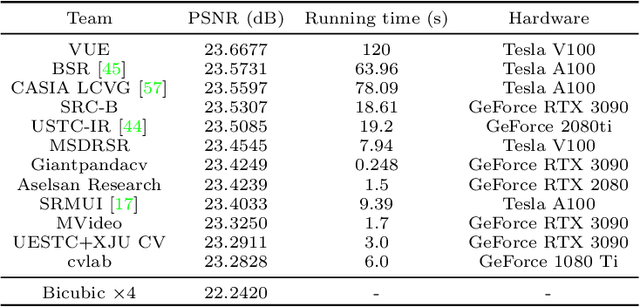
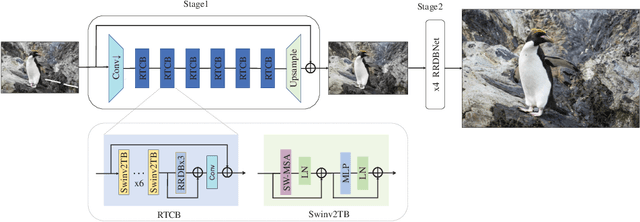

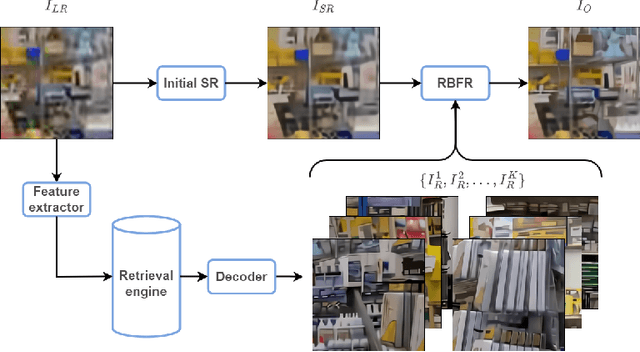
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
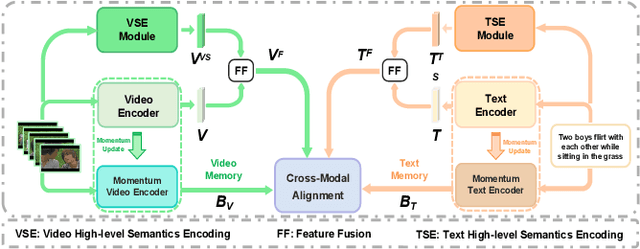
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022
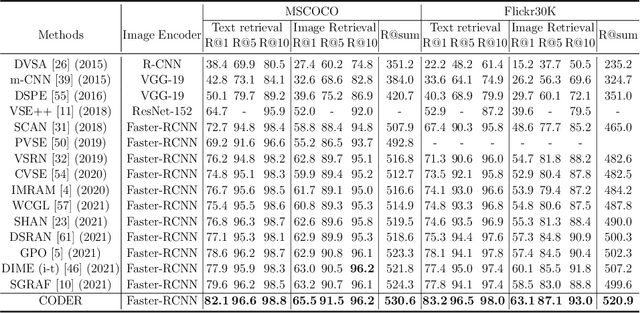
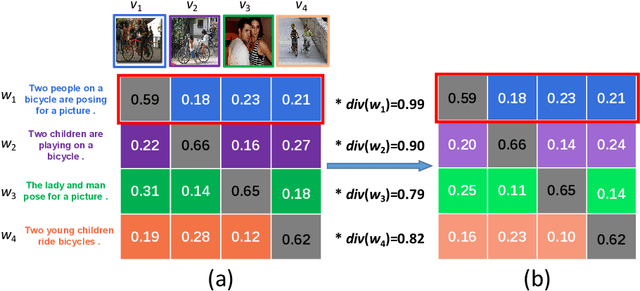
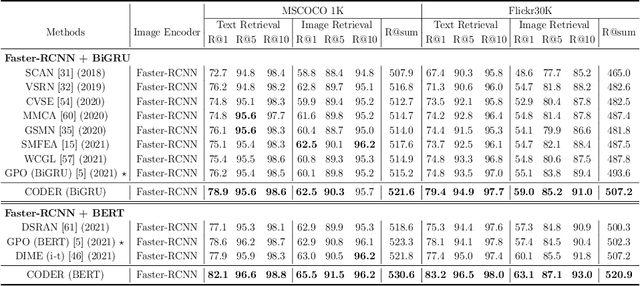
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.
Boosting Video-Text Retrieval with Explicit High-Level Semantics
Aug 09, 2022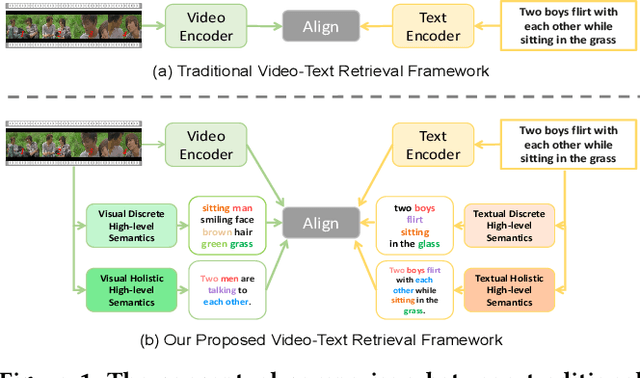
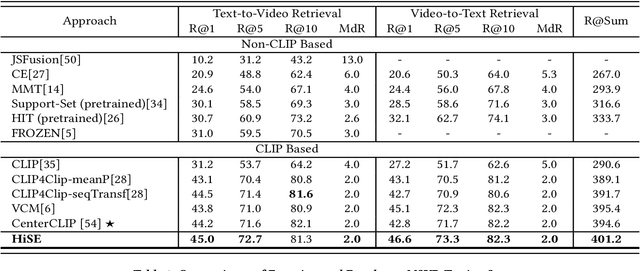
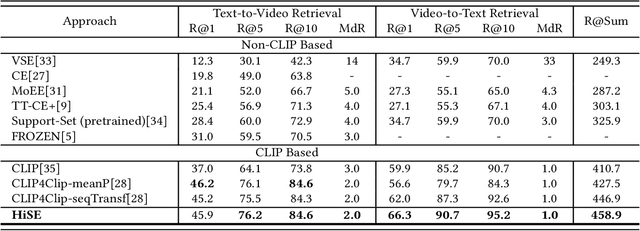
Video-text retrieval (VTR) is an attractive yet challenging task for multi-modal understanding, which aims to search for relevant video (text) given a query (video). Existing methods typically employ completely heterogeneous visual-textual information to align video and text, whilst lacking the awareness of homogeneous high-level semantic information residing in both modalities. To fill this gap, in this work, we propose a novel visual-linguistic aligning model named HiSE for VTR, which improves the cross-modal representation by incorporating explicit high-level semantics. First, we explore the hierarchical property of explicit high-level semantics, and further decompose it into two levels, i.e. discrete semantics and holistic semantics. Specifically, for visual branch, we exploit an off-the-shelf semantic entity predictor to generate discrete high-level semantics. In parallel, a trained video captioning model is employed to output holistic high-level semantics. As for the textual modality, we parse the text into three parts including occurrence, action and entity. In particular, the occurrence corresponds to the holistic high-level semantics, meanwhile both action and entity represent the discrete ones. Then, different graph reasoning techniques are utilized to promote the interaction between holistic and discrete high-level semantics. Extensive experiments demonstrate that, with the aid of explicit high-level semantics, our method achieves the superior performance over state-of-the-art methods on three benchmark datasets, including MSR-VTT, MSVD and DiDeMo.
NSNet: Non-saliency Suppression Sampler for Efficient Video Recognition
Jul 21, 2022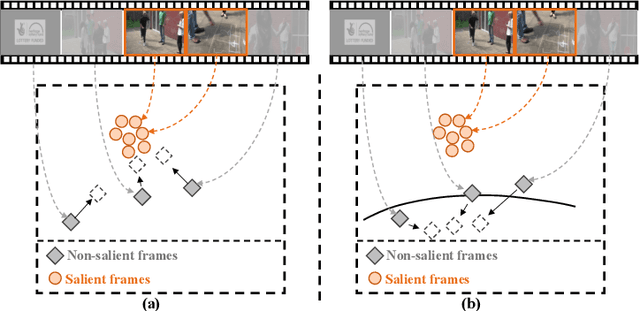
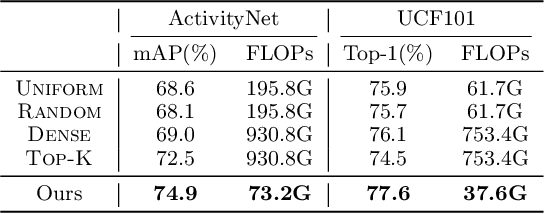

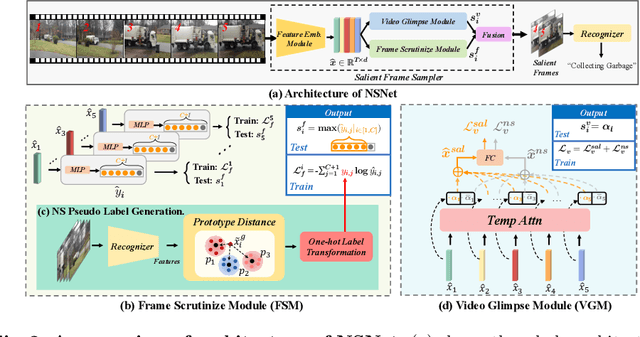
It is challenging for artificial intelligence systems to achieve accurate video recognition under the scenario of low computation costs. Adaptive inference based efficient video recognition methods typically preview videos and focus on salient parts to reduce computation costs. Most existing works focus on complex networks learning with video classification based objectives. Taking all frames as positive samples, few of them pay attention to the discrimination between positive samples (salient frames) and negative samples (non-salient frames) in supervisions. To fill this gap, in this paper, we propose a novel Non-saliency Suppression Network (NSNet), which effectively suppresses the responses of non-salient frames. Specifically, on the frame level, effective pseudo labels that can distinguish between salient and non-salient frames are generated to guide the frame saliency learning. On the video level, a temporal attention module is learned under dual video-level supervisions on both the salient and the non-salient representations. Saliency measurements from both two levels are combined for exploitation of multi-granularity complementary information. Extensive experiments conducted on four well-known benchmarks verify our NSNet not only achieves the state-of-the-art accuracy-efficiency trade-off but also present a significantly faster (2.4~4.3x) practical inference speed than state-of-the-art methods. Our project page is at https://lawrencexia2008.github.io/projects/nsnet .
Neural Color Operators for Sequential Image Retouching
Jul 17, 2022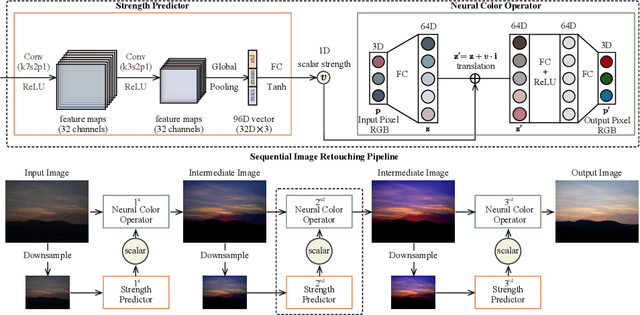
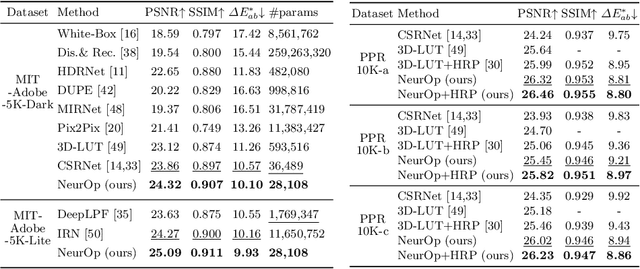


We propose a novel image retouching method by modeling the retouching process as performing a sequence of newly introduced trainable neural color operators. The neural color operator mimics the behavior of traditional color operators and learns pixelwise color transformation while its strength is controlled by a scalar. To reflect the homomorphism property of color operators, we employ equivariant mapping and adopt an encoder-decoder structure which maps the non-linear color transformation to a much simpler transformation (i.e., translation) in a high dimensional space. The scalar strength of each neural color operator is predicted using CNN based strength predictors by analyzing global image statistics. Overall, our method is rather lightweight and offers flexible controls. Experiments and user studies on public datasets show that our method consistently achieves the best results compared with SOTA methods in both quantitative measures and visual qualities. The code and data will be made publicly available.
DALG: Deep Attentive Local and Global Modeling for Image Retrieval
Jul 01, 2022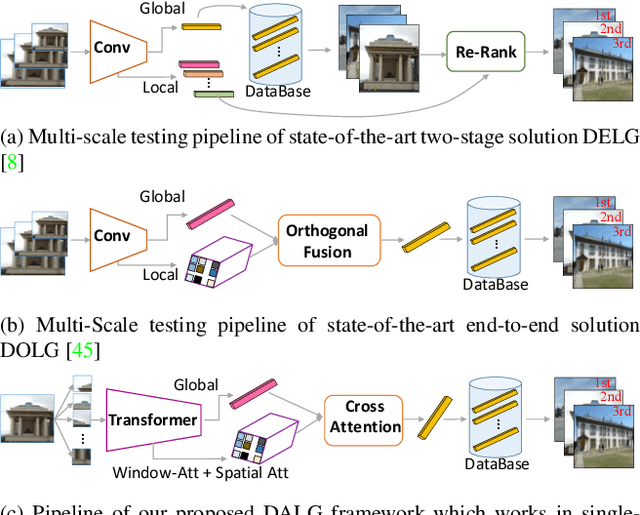
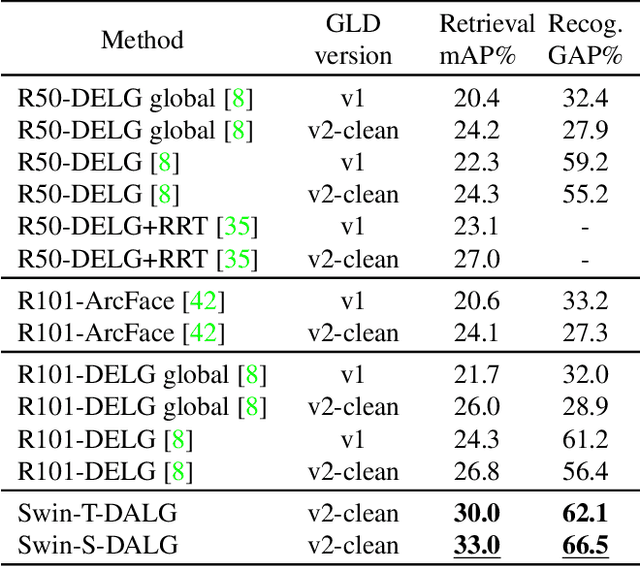
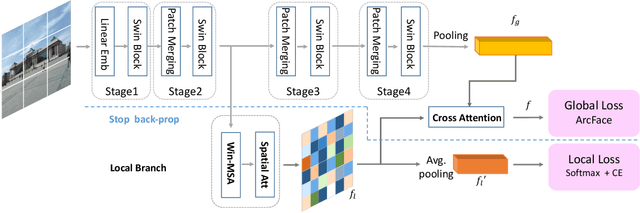
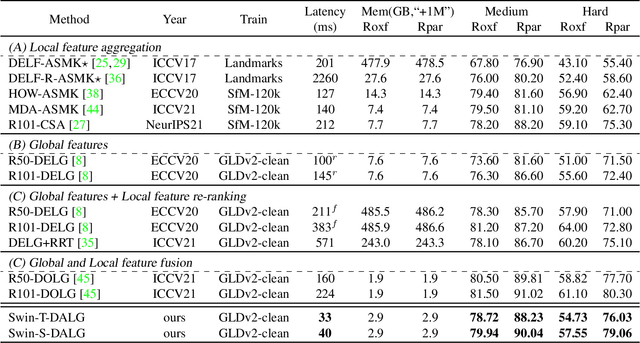
Deeply learned representations have achieved superior image retrieval performance in a retrieve-then-rerank manner. Recent state-of-the-art single stage model, which heuristically fuses local and global features, achieves promising trade-off between efficiency and effectiveness. However, we notice that efficiency of existing solutions is still restricted because of their multi-scale inference paradigm. In this paper, we follow the single stage art and obtain further complexity-effectiveness balance by successfully getting rid of multi-scale testing. To achieve this goal, we abandon the widely-used convolution network giving its limitation in exploring diverse visual patterns, and resort to fully attention based framework for robust representation learning motivated by the success of Transformer. Besides applying Transformer for global feature extraction, we devise a local branch composed of window-based multi-head attention and spatial attention to fully exploit local image patterns. Furthermore, we propose to combine the hierarchical local and global features via a cross-attention module, instead of using heuristically fusion as previous art does. With our Deep Attentive Local and Global modeling framework (DALG), extensive experimental results show that efficiency can be significantly improved while maintaining competitive results with the state of the arts.
Towards Bidirectional Arbitrary Image Rescaling: Joint Optimization and Cycle Idempotence
Mar 08, 2022
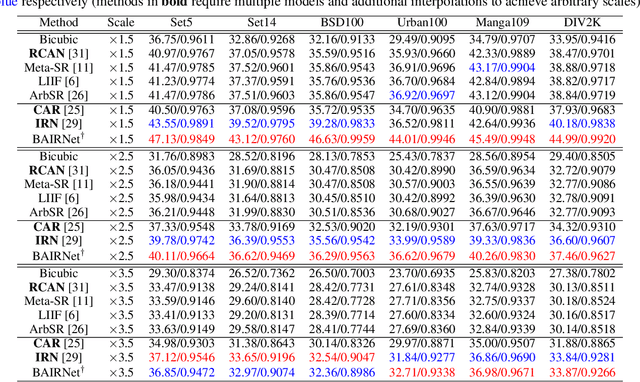
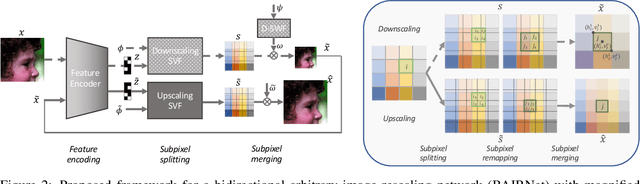

Deep learning based single image super-resolution models have been widely studied and superb results are achieved in upscaling low-resolution images with fixed scale factor and downscaling degradation kernel. To improve real world applicability of such models, there are growing interests to develop models optimized for arbitrary upscaling factors. Our proposed method is the first to treat arbitrary rescaling, both upscaling and downscaling, as one unified process. Using joint optimization of both directions, the proposed model is able to learn upscaling and downscaling simultaneously and achieve bidirectional arbitrary image rescaling. It improves the performance of current arbitrary upscaling models by a large margin while at the same time learns to maintain visual perception quality in downscaled images. The proposed model is further shown to be robust in cycle idempotence test, free of severe degradations in reconstruction accuracy when the downscaling-to-upscaling cycle is applied repetitively. This robustness is beneficial for image rescaling in the wild when this cycle could be applied to one image for multiple times. It also performs well on tests with arbitrary large scales and asymmetric scales, even when the model is not trained with such tasks. Extensive experiments are conducted to demonstrate the superior performance of our model.
Adversarial Dual-Student with Differentiable Spatial Warping for Semi-Supervised Semantic Segmentation
Mar 05, 2022
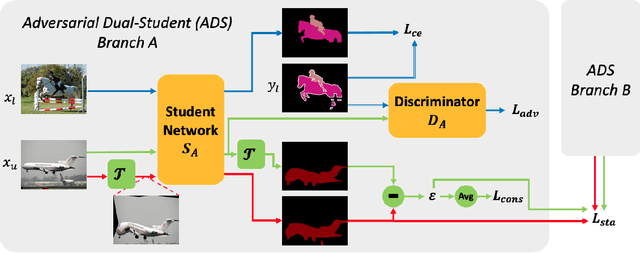
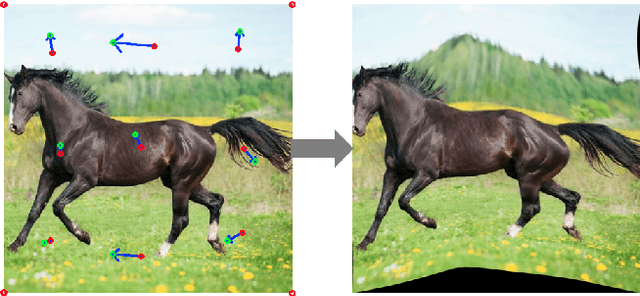

A common challenge posed to robust semantic segmentation is the expensive data annotation cost. Existing semi-supervised solutions show great potential toward solving this problem. Their key idea is constructing consistency regularization with unsupervised data augmentation from unlabeled data for model training. The perturbations for unlabeled data enable the consistency training loss, which benefits semi-supervised semantic segmentation. However, these perturbations destroy image context and introduce unnatural boundaries, which is harmful for semantic segmentation. Besides, the widely adopted semi-supervised learning framework, i.e. mean-teacher, suffers performance limitation since the student model finally converges to the teacher model. In this paper, first of all, we propose a context friendly differentiable geometric warping to conduct unsupervised data augmentation; secondly, a novel adversarial dual-student framework is proposed to improve the Mean-Teacher from the following two aspects: (1) dual student models are learnt independently except for a stabilization constraint to encourage exploiting model diversities; (2) adversarial training scheme is applied to both students and the discriminators are resorted to distinguish reliable pseudo-label of unlabeled data for self-training. Effectiveness is validated via extensive experiments on PASCAL VOC2012 and Citescapes. Our solution significantly improves the performance and state-of-the-art results are achieved on both datasets. Remarkably, compared with fully supervision, our solution achieves comparable mIoU of 73.4% using only 12.5% annotated data on PASCAL VOC2012.