 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMD-Hummingbird: Towards an Efficient Text-to-Video Model
Mar 25, 2025Text-to-Video (T2V) generation has attracted significant attention for its ability to synthesize realistic videos from textual descriptions. However, existing models struggle to balance computational efficiency and high visual quality, particularly on resource-limited devices, e.g.,iGPUs and mobile phones. Most prior work prioritizes visual fidelity while overlooking the need for smaller, more efficient models suitable for real-world deployment. To address this challenge, we propose a lightweight T2V framework, termed Hummingbird, which prunes existing models and enhances visual quality through visual feedback learning. Our approach reduces the size of the U-Net from 1.4 billion to 0.7 billion parameters, significantly improving efficiency while preserving high-quality video generation. Additionally, we introduce a novel data processing pipeline that leverages Large Language Models (LLMs) and Video Quality Assessment (VQA) models to enhance the quality of both text prompts and video data. To support user-driven training and style customization, we publicly release the full training code, including data processing and model training. Extensive experiments show that our method achieves a 31X speedup compared to state-of-the-art models such as VideoCrafter2, while also attaining the highest overall score on VBench. Moreover, our method supports the generation of videos with up to 26 frames, addressing the limitations of existing U-Net-based methods in long video generation. Notably, the entire training process requires only four GPUs, yet delivers performance competitive with existing leading methods. Hummingbird presents a practical and efficient solution for T2V generation, combining high performance, scalability, and flexibility for real-world applications.
LLM-driven Effective Knowledge Tracing by Integrating Dual-channel Difficulty
Feb 27, 2025Knowledge Tracing (KT) is a fundamental technology in intelligent tutoring systems used to simulate changes in students' knowledge state during learning, track personalized knowledge mastery, and predict performance. However, current KT models face three major challenges: (1) When encountering new questions, models face cold-start problems due to sparse interaction records, making precise modeling difficult; (2) Traditional models only use historical interaction records for student personalization modeling, unable to accurately track individual mastery levels, resulting in unclear personalized modeling; (3) The decision-making process is opaque to educators, making it challenging for them to understand model judgments. To address these challenges, we propose a novel Dual-channel Difficulty-aware Knowledge Tracing (DDKT) framework that utilizes Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) for subjective difficulty assessment, while integrating difficulty bias-aware algorithms and student mastery algorithms for precise difficulty measurement. Our framework introduces three key innovations: (1) Difficulty Balance Perception Sequence (DBPS) - students' subjective perceptions combined with objective difficulty, measuring gaps between LLM-assessed difficulty, mathematical-statistical difficulty, and students' subjective perceived difficulty through attention mechanisms; (2) Difficulty Mastery Ratio (DMR) - precise modeling of student mastery levels through different difficulty zones; (3) Knowledge State Update Mechanism - implementing personalized knowledge acquisition through gated networks and updating student knowledge state. Experimental results on two real datasets show our method consistently outperforms nine baseline models, improving AUC metrics by 2% to 10% while effectively addressing cold-start problems and enhancing model interpretability.
Megrez-Omni Technical Report
Feb 19, 2025
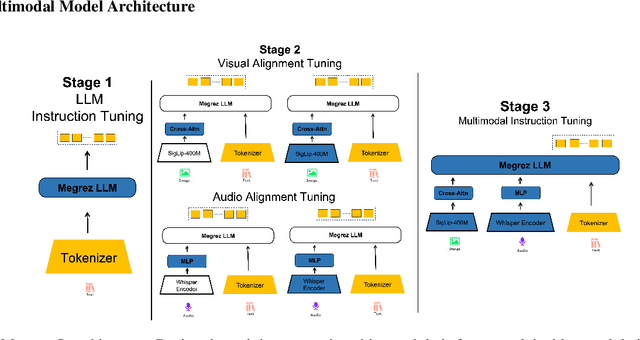


In this work, we present the Megrez models, comprising a language model (Megrez-3B-Instruct) and a multimodal model (Megrez-3B-Omni). These models are designed to deliver fast inference, compactness, and robust edge-side intelligence through a software-hardware co-design approach. Megrez-3B-Instruct offers several advantages, including high accuracy, high speed, ease of use, and a wide range of applications. Building on Megrez-3B-Instruct, Megrez-3B-Omni is an on-device multimodal understanding LLM that supports image, text, and audio analysis. It achieves state-of-the-art accuracy across all three modalities and demonstrates strong versatility and robustness, setting a new benchmark for multimodal AI models.
Edit as You See: Image-guided Video Editing via Masked Motion Modeling
Jan 08, 2025Recent advancements in diffusion models have significantly facilitated text-guided video editing. However, there is a relative scarcity of research on image-guided video editing, a method that empowers users to edit videos by merely indicating a target object in the initial frame and providing an RGB image as reference, without relying on the text prompts. In this paper, we propose a novel Image-guided Video Editing Diffusion model, termed IVEDiff for the image-guided video editing. IVEDiff is built on top of image editing models, and is equipped with learnable motion modules to maintain the temporal consistency of edited video. Inspired by self-supervised learning concepts, we introduce a masked motion modeling fine-tuning strategy that empowers the motion module's capabilities for capturing inter-frame motion dynamics, while preserving the capabilities for intra-frame semantic correlations modeling of the base image editing model. Moreover, an optical-flow-guided motion reference network is proposed to ensure the accurate propagation of information between edited video frames, alleviating the misleading effects of invalid information. We also construct a benchmark to facilitate further research. The comprehensive experiments demonstrate that our method is able to generate temporally smooth edited videos while robustly dealing with various editing objects with high quality.
ReNeg: Learning Negative Embedding with Reward Guidance
Dec 27, 2024In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal. In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings. We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities. For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideoCrafter2, resulting in consistent performance improvements across the board.
Vision-Based Deep Reinforcement Learning of UAV Autonomous Navigation Using Privileged Information
Dec 09, 2024The capability of UAVs for efficient autonomous navigation and obstacle avoidance in complex and unknown environments is critical for applications in agricultural irrigation, disaster relief and logistics. In this paper, we propose the DPRL (Distributed Privileged Reinforcement Learning) navigation algorithm, an end-to-end policy designed to address the challenge of high-speed autonomous UAV navigation under partially observable environmental conditions. Our approach combines deep reinforcement learning with privileged learning to overcome the impact of observation data corruption caused by partial observability. We leverage an asymmetric Actor-Critic architecture to provide the agent with privileged information during training, which enhances the model's perceptual capabilities. Additionally, we present a multi-agent exploration strategy across diverse environments to accelerate experience collection, which in turn expedites model convergence. We conducted extensive simulations across various scenarios, benchmarking our DPRL algorithm against the state-of-the-art navigation algorithms. The results consistently demonstrate the superior performance of our algorithm in terms of flight efficiency, robustness and overall success rate.
HateDebias: On the Diversity and Variability of Hate Speech Debiasing
Jun 07, 2024



Hate speech on social media is ubiquitous but urgently controlled. Without detecting and mitigating the biases brought by hate speech, different types of ethical problems. While a number of datasets have been proposed to address the problem of hate speech detection, these datasets seldom consider the diversity and variability of bias, making it far from real-world scenarios. To fill this gap, we propose a benchmark, named HateDebias, to analyze the model ability of hate speech detection under continuous, changing environments. Specifically, to meet the diversity of biases, we collect existing hate speech detection datasets with different types of biases. To further meet the variability (i.e., the changing of bias attributes in datasets), we reorganize datasets to follow the continuous learning setting. We evaluate the detection accuracy of models trained on the datasets with a single type of bias with the performance on the HateDebias, where a significant performance drop is observed. To provide a potential direction for debiasing, we further propose a debiasing framework based on continuous learning and bias information regularization, as well as the memory replay strategies to ensure the debiasing ability of the model. Experiment results on the proposed benchmark show that the aforementioned method can improve several baselines with a distinguished margin, highlighting its effectiveness in real-world applications.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning
Feb 24, 2024Food classification is the foundation for developing food vision tasks and plays a key role in the burgeoning field of computational nutrition. Due to the complexity of food requiring fine-grained classification, recent academic research mainly modifies Convolutional Neural Networks (CNNs) and/or Vision Transformers (ViTs) to perform food category classification. However, to learn fine-grained features, the CNN backbone needs additional structural design, whereas ViT, containing the self-attention module, has increased computational complexity. In recent months, a new Sequence State Space (S4) model, through a Selection mechanism and computation with a Scan (S6), colloquially termed Mamba, has demonstrated superior performance and computation efficiency compared to the Transformer architecture. The VMamba model, which incorporates the Mamba mechanism into image tasks (such as classification), currently establishes the state-of-the-art (SOTA) on the ImageNet dataset. In this research, we introduce an academically underestimated food dataset CNFOOD-241, and pioneer the integration of a residual learning framework within the VMamba model to concurrently harness both global and local state features inherent in the original VMamba architectural design. The research results show that VMamba surpasses current SOTA models in fine-grained and food classification. The proposed Res-VMamba further improves the classification accuracy to 79.54\% without pretrained weight. Our findings elucidate that our proposed methodology establishes a new benchmark for SOTA performance in food recognition on the CNFOOD-241 dataset. The code can be obtained on GitHub: https://github.com/ChiShengChen/ResVMamba.
LV-Eval: A Balanced Long-Context Benchmark with 5 Length Levels Up to 256K
Feb 06, 2024
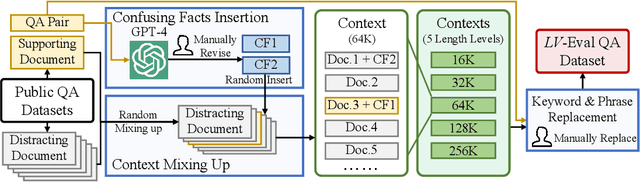

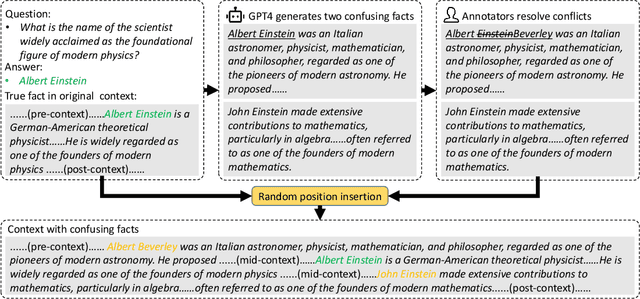
State-of-the-art large language models (LLMs) are now claiming remarkable supported context lengths of 256k or even more. In contrast, the average context lengths of mainstream benchmarks are insufficient (5k-21k), and they suffer from potential knowledge leakage and inaccurate metrics, resulting in biased evaluation. This paper introduces LV-Eval, a challenging long-context benchmark with five length levels (16k, 32k, 64k, 128k, and 256k) reaching up to 256k words. LV-Eval features two main tasks, single-hop QA and multi-hop QA, comprising 11 bilingual datasets. The design of LV-Eval has incorporated three key techniques, namely confusing facts insertion, keyword and phrase replacement, and keyword-recall-based metric design. The advantages of LV-Eval include controllable evaluation across different context lengths, challenging test instances with confusing facts, mitigated knowledge leakage, and more objective evaluations. We evaluate 10 LLMs on LV-Eval and conduct ablation studies on the techniques used in LV-Eval construction. The results reveal that: (i) Commercial LLMs generally outperform open-source LLMs when evaluated within length levels shorter than their claimed context length. However, their overall performance is surpassed by open-source LLMs with longer context lengths. (ii) Extremely long-context LLMs, such as Yi-6B-200k, exhibit a relatively gentle degradation of performance, but their absolute performances may not necessarily be higher than those of LLMs with shorter context lengths. (iii) LLMs' performances can significantly degrade in the presence of confusing information, especially in the pressure test of "needle in a haystack". (iv) Issues related to knowledge leakage and inaccurate metrics introduce bias in evaluation, and these concerns are alleviated in LV-Eval. All datasets and evaluation codes are released at: https://github.com/infinigence/LVEval.