 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Intelligent Self-driving Truck System For Highway Transportation
Dec 31, 2021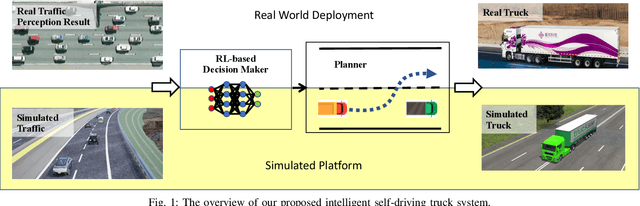
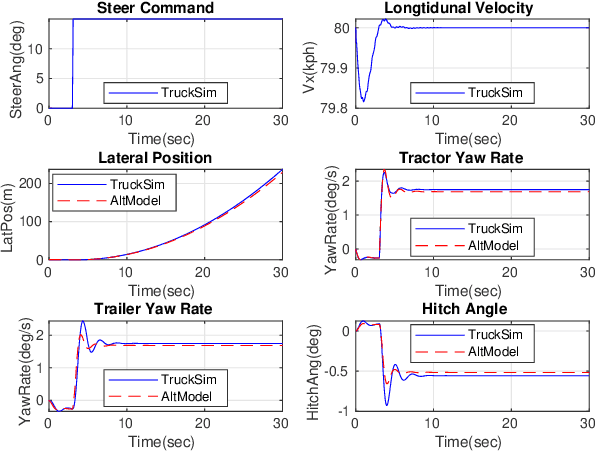
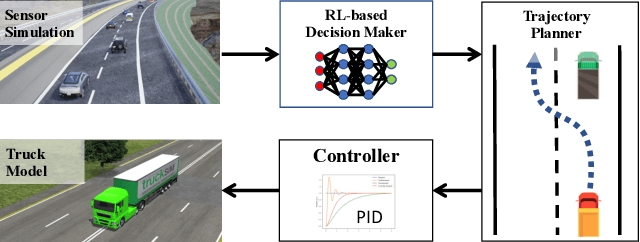
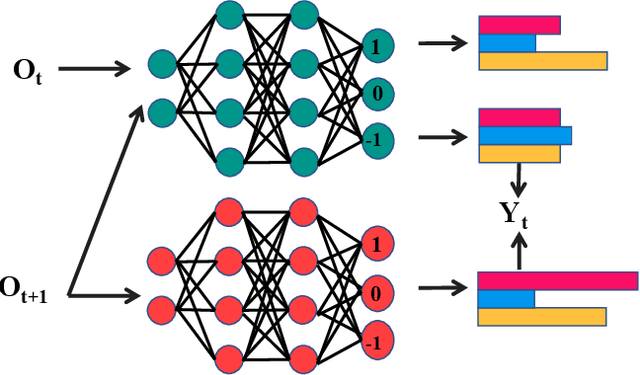
Recently, there have been many advances in autonomous driving society, attracting a lot of attention from academia and industry. However, existing works mainly focus on cars, extra development is still required for self-driving truck algorithms and models. In this paper, we introduce an intelligent self-driving truck system. Our presented system consists of three main components, 1) a realistic traffic simulation module for generating realistic traffic flow in testing scenarios, 2) a high-fidelity truck model which is designed and evaluated for mimicking real truck response in real-world deployment, 3) an intelligent planning module with learning-based decision making algorithm and multi-mode trajectory planner, taking into account the truck's constraints, road slope changes, and the surrounding traffic flow. We provide quantitative evaluations for each component individually to demonstrate the fidelity and performance of each part. We also deploy our proposed system on a real truck and conduct real world experiments which shows our system's capacity of mitigating sim-to-real gap. Our code is available at https://github.com/InceptioResearch/IITS
Dynamic Coherence-Based EM Ray Tracing Simulations in Vehicular Environments
Dec 14, 2021
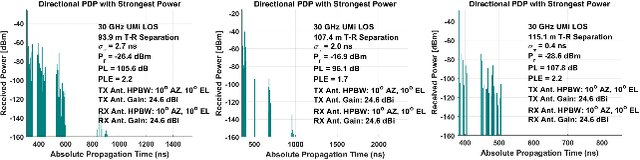
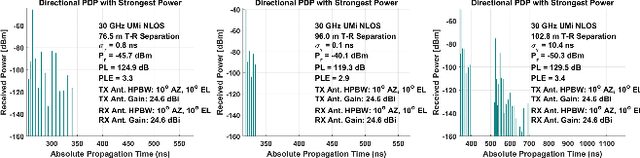
5G applications have become increasingly popular in recent years as the spread of 5G network deployment has grown. For vehicular networks, mmWave band signals have been well studied and used for communication and sensing. In this work, we propose a new dynamic ray tracing algorithm that exploits spatial and temporal coherence. We evaluate the performance by comparing the results on typical vehicular communication scenarios with NYUSIM, which builds on stochastic models, and Winprop, which utilizes the deterministic model for simulations with given environment information. We compare the performance of our algorithm on complex, urban models and observe the reduction in computation time by 60% compared to NYUSIM and 30% compared to Winprop, while maintaining similar prediction accuracy.
N-Cloth: Predicting 3D Cloth Deformation with Mesh-Based Networks
Dec 13, 2021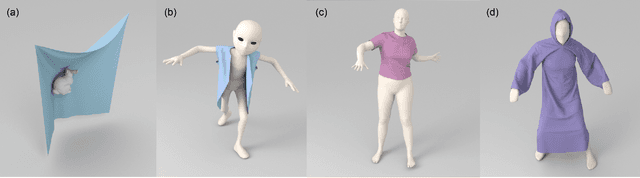
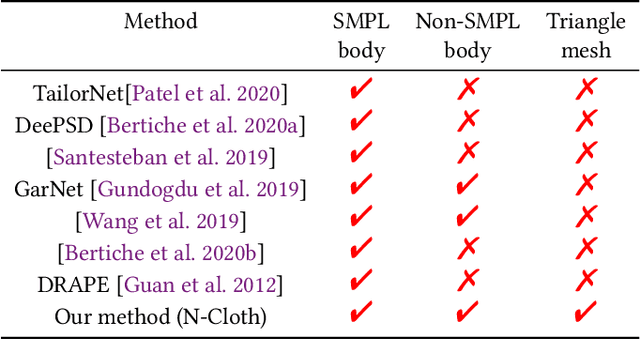
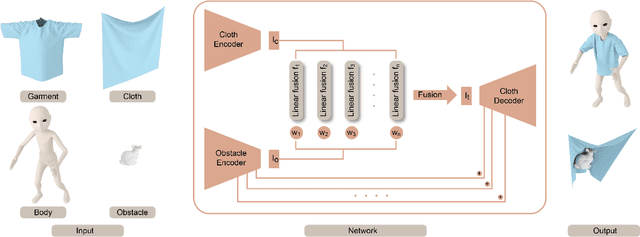

We present a novel mesh-based learning approach (N-Cloth) for plausible 3D cloth deformation prediction. Our approach is general and can handle cloth or obstacles represented by triangle meshes with arbitrary topology. We use graph convolution to transform the cloth and object meshes into a latent space to reduce the non-linearity in the mesh space. Our network can predict the target 3D cloth mesh deformation based on the state of the initial cloth mesh template and the target obstacle mesh. Our approach can handle complex cloth meshes with up to $100$K triangles and scenes with various objects corresponding to SMPL humans, Non-SMPL humans, or rigid bodies. In practice, our approach demonstrates good temporal coherence between successive input frames and can be used to generate plausible cloth simulation at $30-45$ fps on an NVIDIA GeForce RTX 3090 GPU. We highlight its benefits over prior learning-based methods and physically-based cloth simulators.
Using Graph-Theoretic Machine Learning to Predict Human Driver Behavior
Nov 04, 2021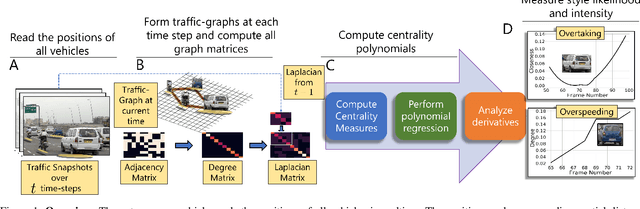
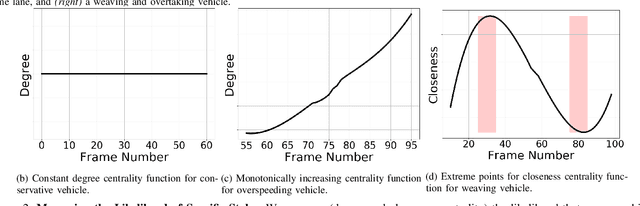
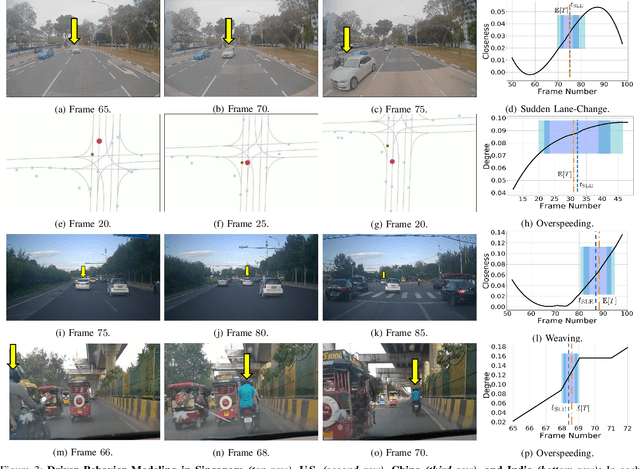

Studies have shown that autonomous vehicles (AVs) behave conservatively in a traffic environment composed of human drivers and do not adapt to local conditions and socio-cultural norms. It is known that socially aware AVs can be designed if there exists a mechanism to understand the behaviors of human drivers. We present an approach that leverages machine learning to predict, the behaviors of human drivers. This is similar to how humans implicitly interpret the behaviors of drivers on the road, by only observing the trajectories of their vehicles. We use graph-theoretic tools to extract driver behavior features from the trajectories and machine learning to obtain a computational mapping between the extracted trajectory of a vehicle in traffic and the driver behaviors. Compared to prior approaches in this domain, we prove that our method is robust, general, and extendable to broad-ranging applications such as autonomous navigation. We evaluate our approach on real-world traffic datasets captured in the U.S., India, China, and Singapore, as well as in simulation.
Active Learning of Neural Collision Handler for Complex 3D Mesh Deformations
Oct 08, 2021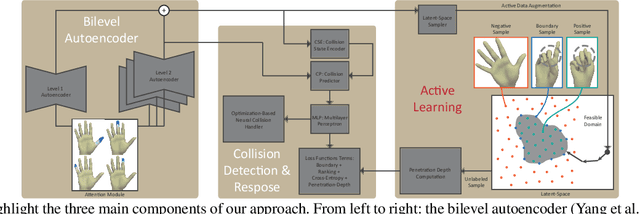
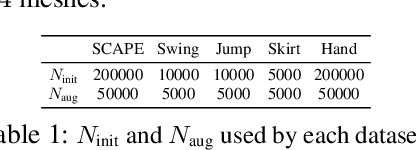
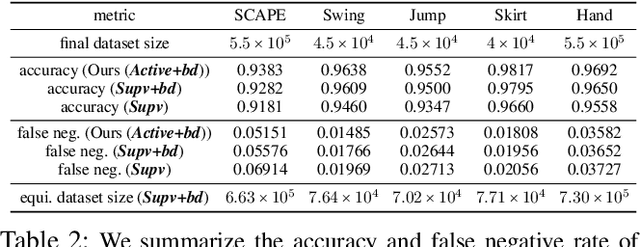
We present a robust learning algorithm to detect and handle collisions in 3D deforming meshes. Our collision detector is represented as a bilevel deep autoencoder with an attention mechanism that identifies colliding mesh sub-parts. We use a numerical optimization algorithm to resolve penetrations guided by the network. Our learned collision handler can resolve collisions for unseen, high-dimensional meshes with thousands of vertices. To obtain stable network performance in such large and unseen spaces, we progressively insert new collision data based on the errors in network inferences. We automatically label these data using an analytical collision detector and progressively fine-tune our detection networks. We evaluate our method for collision handling of complex, 3D meshes coming from several datasets with different shapes and topologies, including datasets corresponding to dressed and undressed human poses, cloth simulations, and human hand poses acquired using multiview capture systems. Our approach outperforms supervised learning methods and achieves $93.8-98.1\%$ accuracy compared to the groundtruth by analytic methods. Compared to prior learning methods, our approach results in a $5.16\%-25.50\%$ lower false negative rate in terms of collision checking and a $9.65\%-58.91\%$ higher success rate in collision handling.
FAST-RIR: Fast neural diffuse room impulse response generator
Oct 07, 2021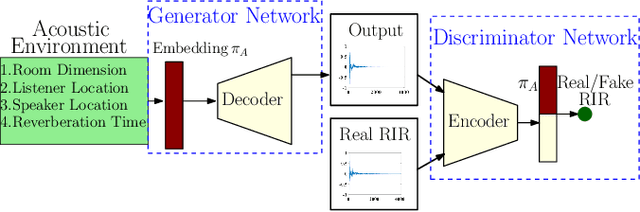
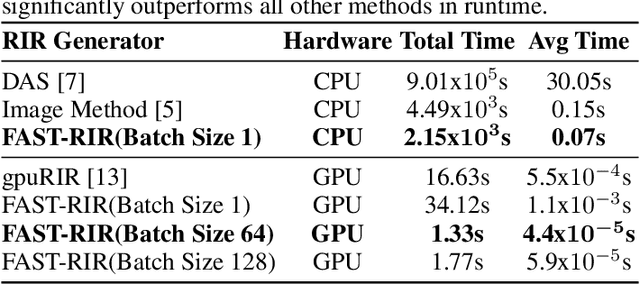

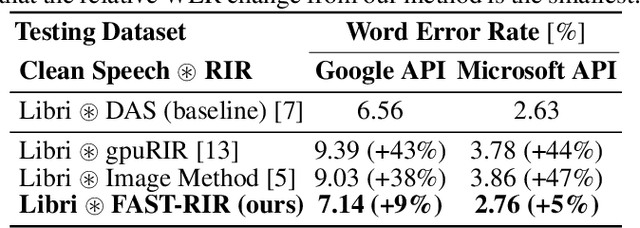
We present a neural-network-based fast diffuse room impulse response generator (FAST-RIR) for generating room impulse responses (RIRs) for a given acoustic environment. Our FAST-RIR takes rectangular room dimensions, listener and speaker positions, and reverberation time as inputs and generates specular and diffuse reflections for a given acoustic environment. Our FAST-RIR is capable of generating RIRs for a given input reverberation time with an average error of 0.02s. We evaluate our generated RIRs in automatic speech recognition (ASR) applications using Google Speech API, Microsoft Speech API, and Kaldi tools. We show that our proposed FAST-RIR with batch size 1 is 400 times faster than a state-of-the-art diffuse acoustic simulator (DAS) on a CPU and gives similar performance to DAS in ASR experiments. Our FAST-RIR is 12 times faster than an existing GPU-based RIR generator (gpuRIR). We show that our FAST-RIR outperforms gpuRIR by 2.5% in an AMI far-field ASR benchmark.
HighlightMe: Detecting Highlights from Human-Centric Videos
Oct 05, 2021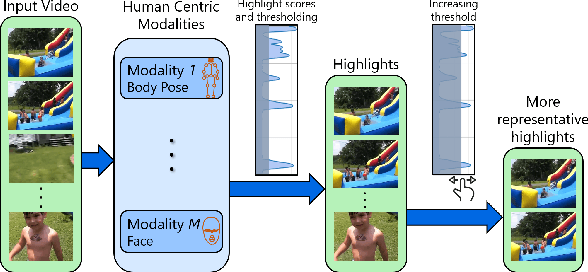
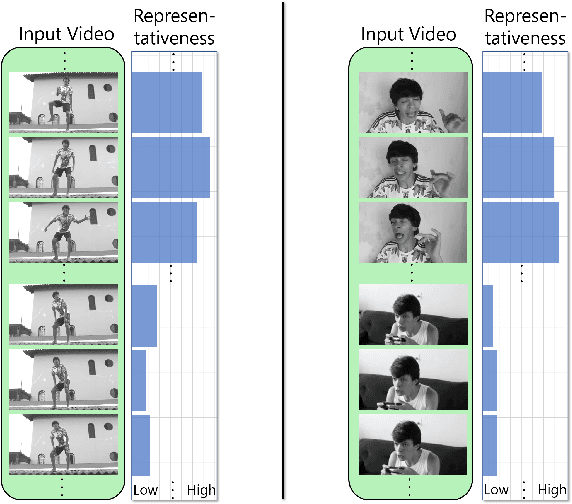

We present a domain- and user-preference-agnostic approach to detect highlightable excerpts from human-centric videos. Our method works on the graph-based representation of multiple observable human-centric modalities in the videos, such as poses and faces. We use an autoencoder network equipped with spatial-temporal graph convolutions to detect human activities and interactions based on these modalities. We train our network to map the activity- and interaction-based latent structural representations of the different modalities to per-frame highlight scores based on the representativeness of the frames. We use these scores to compute which frames to highlight and stitch contiguous frames to produce the excerpts. We train our network on the large-scale AVA-Kinetics action dataset and evaluate it on four benchmark video highlight datasets: DSH, TVSum, PHD2, and SumMe. We observe a 4-12% improvement in the mean average precision of matching the human-annotated highlights over state-of-the-art methods in these datasets, without requiring any user-provided preferences or dataset-specific fine-tuning.
METEOR: A Massive Dense & Heterogeneous Behavior Dataset for Autonomous Driving
Sep 30, 2021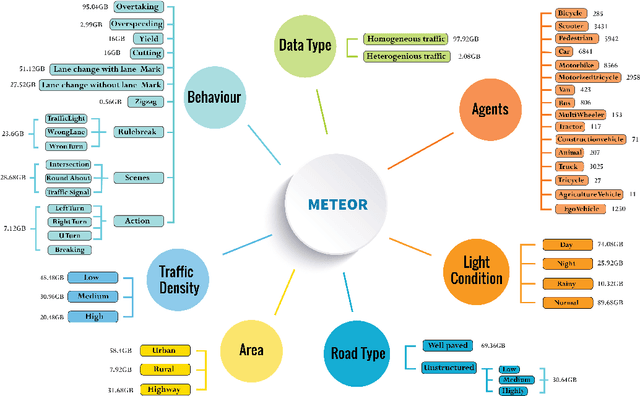

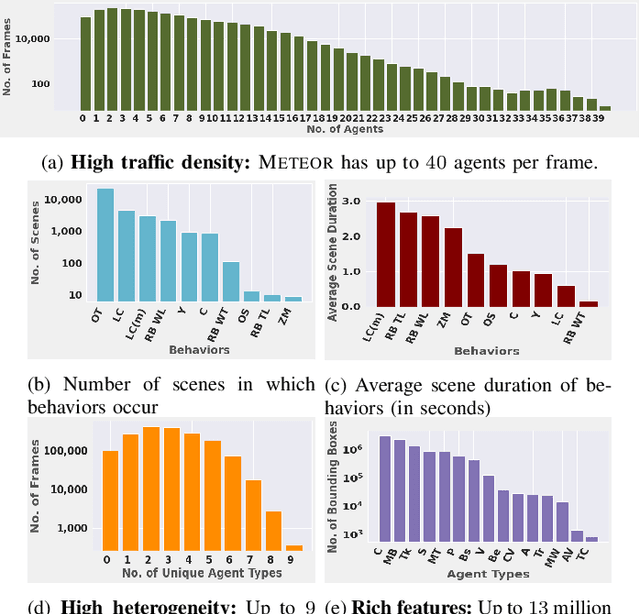
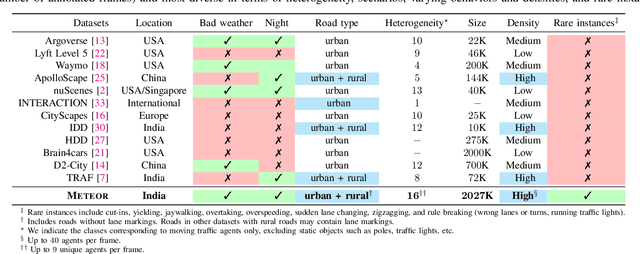
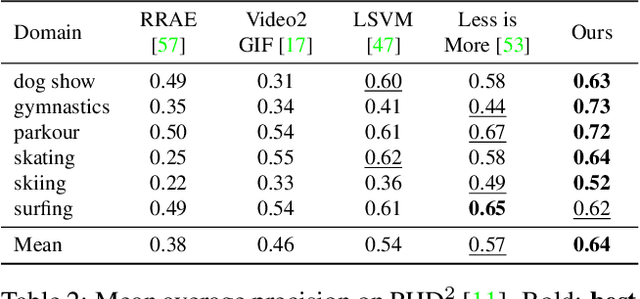
We present a new and complex traffic dataset, METEOR, which captures traffic patterns in unstructured scenarios in India. METEOR consists of more than 1000 one-minute video clips, over 2 million annotated frames with ego-vehicle trajectories, and more than 13 million bounding boxes for surrounding vehicles or traffic agents. METEOR is a unique dataset in terms of capturing the heterogeneity of microscopic and macroscopic traffic characteristics. Furthermore, we provide annotations for rare and interesting driving behaviors such as cut-ins, yielding, overtaking, overspeeding, zigzagging, sudden lane changing, running traffic signals, driving in the wrong lanes, taking wrong turns, lack of right-of-way rules at intersections, etc. We also present diverse traffic scenarios corresponding to rainy weather, nighttime driving, driving in rural areas with unmarked roads, and high-density traffic scenarios. We use our novel dataset to evaluate the performance of object detection and behavior prediction algorithms. We show that state-of-the-art object detectors fail in these challenging conditions and also propose a new benchmark test: action-behavior prediction with a baseline mAP score of 70.74.
TERP: Reliable Planning in Uneven Outdoor Environments using Deep Reinforcement Learning
Sep 23, 2021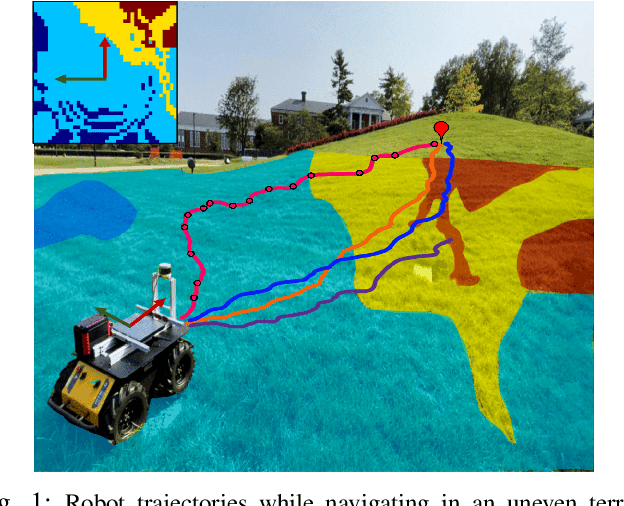
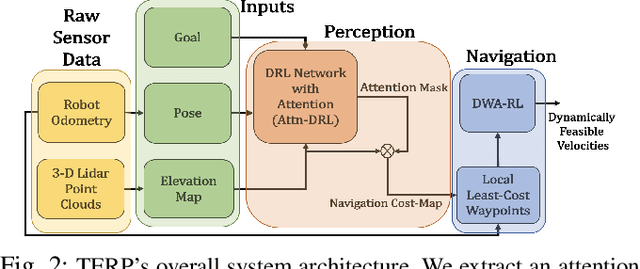
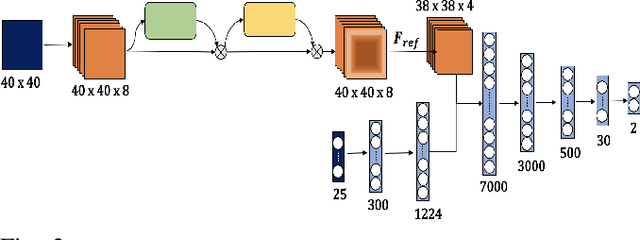
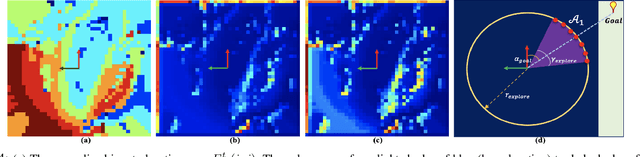
We present a novel method for reliable robot navigation in uneven outdoor terrains. Our approach employs a novel fully-trained Deep Reinforcement Learning (DRL) network that uses elevation maps of the environment, robot pose, and goal as inputs to compute an attention mask of the environment. The attention mask is used to identify reduced stability regions in the elevation map and is computed using channel and spatial attention modules and a novel reward function. We continuously compute and update a navigation cost-map that encodes the elevation information or the level-of-flatness of the terrain using the attention mask. We then generate locally least-cost waypoints on the cost-map and compute the final dynamically feasible trajectory using another DRL-based method. Our approach guarantees safe, locally least-cost paths and dynamically feasible robot velocities in uneven terrains. We observe an increase of 35.18% in terms of success rate and, a decrease of 26.14% in the cumulative elevation gradient of the robot's trajectory compared to prior navigation methods in high-elevation regions. We evaluate our method on a Husky robot in real-world uneven terrains (~ 4m of elevation gain) and demonstrate its benefits.
Joint Search of Optimal Topology and Trajectory for Planar Linkages
Sep 15, 2021

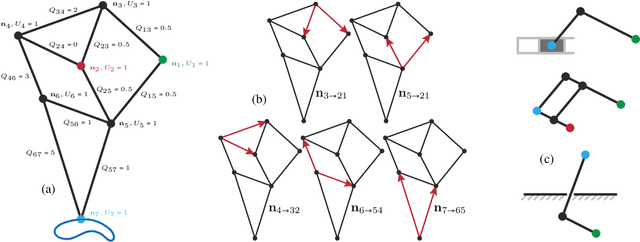
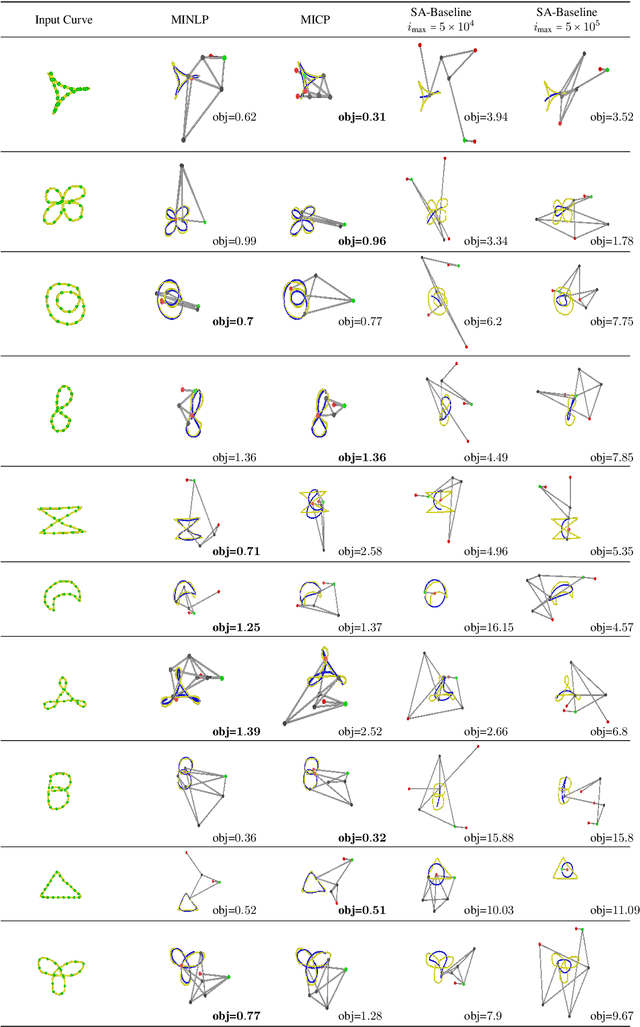
We present an algorithm to compute planar linkage topology and geometry, given a user-specified end-effector trajectory. Planar linkage structures convert rotational or prismatic motions of a single actuator into an arbitrarily complex periodic motion, \refined{which is an important component when building low-cost, modular robots, mechanical toys, and foldable structures in our daily lives (chairs, bikes, and shelves). The design of such structures require trial and error even for experienced engineers. Our research provides semi-automatic methods for exploring novel designs given high-level specifications and constraints.} We formulate this problem as a non-smooth numerical optimization with quadratic objective functions and non-convex quadratic constraints involving mixed-integer decision variables (MIQCQP). We propose and compare three approximate algorithms to solve this problem: mixed-integer conic-programming (MICP), mixed-integer nonlinear programming (MINLP), and simulated annealing (SA). We evaluated these algorithms searching for planar linkages involving $10-14$ rigid links. Our results show that the best performance can be achieved by combining MICP and MINLP, leading to a hybrid algorithm capable of finding the planar linkages within a couple of hours on a desktop machine, which significantly outperforms the SA baseline in terms of optimality. We highlight the effectiveness of our optimized planar linkages by using them as legs of a walking robot.