 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathology-and-genomics Multimodal Transformer for Survival Outcome Prediction
Jul 22, 2023



Survival outcome assessment is challenging and inherently associated with multiple clinical factors (e.g., imaging and genomics biomarkers) in cancer. Enabling multimodal analytics promises to reveal novel predictive patterns of patient outcomes. In this study, we propose a multimodal transformer (PathOmics) integrating pathology and genomics insights into colon-related cancer survival prediction. We emphasize the unsupervised pretraining to capture the intrinsic interaction between tissue microenvironments in gigapixel whole slide images (WSIs) and a wide range of genomics data (e.g., mRNA-sequence, copy number variant, and methylation). After the multimodal knowledge aggregation in pretraining, our task-specific model finetuning could expand the scope of data utility applicable to both multi- and single-modal data (e.g., image- or genomics-only). We evaluate our approach on both TCGA colon and rectum cancer cohorts, showing that the proposed approach is competitive and outperforms state-of-the-art studies. Finally, our approach is desirable to utilize the limited number of finetuned samples towards data-efficient analytics for survival outcome prediction. The code is available at https://github.com/Cassie07/PathOmics.
Training Like a Medical Resident: Universal Medical Image Segmentation via Context Prior Learning
Jun 06, 2023



A major enduring focus of clinical workflows is disease analytics and diagnosis, leading to medical imaging datasets where the modalities and annotations are strongly tied to specific clinical objectives. To date, building task-specific segmentation models is intuitive yet a restrictive approach, lacking insights gained from widespread imaging cohorts. Inspired by the training of medical residents, we explore universal medical image segmentation, whose goal is to learn from diverse medical imaging sources covering a range of clinical targets, body regions, and image modalities. Following this paradigm, we propose Hermes, a context prior learning approach that addresses the challenges related to the heterogeneity on data, modality, and annotations in the proposed universal paradigm. In a collection of seven diverse datasets, we demonstrate the appealing merits of the universal paradigm over the traditional task-specific training paradigm. By leveraging the synergy among various tasks, Hermes shows superior performance and model scalability. Our in-depth investigation on two additional datasets reveals Hermes' strong capabilities for transfer learning, incremental learning, and generalization to different downstream tasks. The code is available: https://github.com/yhygao/universal-medical-image-segmentation.
A Critical Analysis of the Limitation of Deep Learning based 3D Dental Mesh Segmentation Methods in Segmenting Partial Scans
Apr 29, 2023Tooth segmentation from intraoral scans is a crucial part of digital dentistry. Many Deep Learning based tooth segmentation algorithms have been developed for this task. In most of the cases, high accuracy has been achieved, although, most of the available tooth segmentation techniques make an implicit restrictive assumption of full jaw model and they report accuracy based on full jaw models. Medically, however, in certain cases, full jaw tooth scan is not required or may not be available. Given this practical issue, it is important to understand the robustness of currently available widely used Deep Learning based tooth segmentation techniques. For this purpose, we applied available segmentation techniques on partial intraoral scans and we discovered that the available deep Learning techniques under-perform drastically. The analysis and comparison presented in this work would help us in understanding the severity of the problem and allow us to develop robust tooth segmentation technique without strong assumption of full jaw model.
Dealing With Heterogeneous 3D MR Knee Images: A Federated Few-Shot Learning Method With Dual Knowledge Distillation
Apr 18, 2023Federated Learning has gained popularity among medical institutions since it enables collaborative training between clients (e.g., hospitals) without aggregating data. However, due to the high cost associated with creating annotations, especially for large 3D image datasets, clinical institutions do not have enough supervised data for training locally. Thus, the performance of the collaborative model is subpar under limited supervision. On the other hand, large institutions have the resources to compile data repositories with high-resolution images and labels. Therefore, individual clients can utilize the knowledge acquired in the public data repositories to mitigate the shortage of private annotated images. In this paper, we propose a federated few-shot learning method with dual knowledge distillation. This method allows joint training with limited annotations across clients without jeopardizing privacy. The supervised learning of the proposed method extracts features from limited labeled data in each client, while the unsupervised data is used to distill both feature and response-based knowledge from a national data repository to further improve the accuracy of the collaborative model and reduce the communication cost. Extensive evaluations are conducted on 3D magnetic resonance knee images from a private clinical dataset. Our proposed method shows superior performance and less training time than other semi-supervised federated learning methods. Codes and additional visualization results are available at https://github.com/hexiaoxiao-cs/fedml-knee.
Revisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens
Mar 27, 2023



Contrastive learning-based vision-language pre-training approaches, such as CLIP, have demonstrated great success in many vision-language tasks. These methods achieve cross-modal alignment by encoding a matched image-text pair with similar feature embeddings, which are generated by aggregating information from visual patches and language tokens. However, direct aligning cross-modal information using such representations is challenging, as visual patches and text tokens differ in semantic levels and granularities. To alleviate this issue, we propose a Finite Discrete Tokens (FDT) based multimodal representation. FDT is a set of learnable tokens representing certain visual-semantic concepts. Both images and texts are embedded using shared FDT by first grounding multimodal inputs to FDT space and then aggregating the activated FDT representations. The matched visual and semantic concepts are enforced to be represented by the same set of discrete tokens by a sparse activation constraint. As a result, the granularity gap between the two modalities is reduced. Through both quantitative and qualitative analyses, we demonstrate that using FDT representations in CLIP-style models improves cross-modal alignment and performance in visual recognition and vision-language downstream tasks. Furthermore, we show that our method can learn more comprehensive representations, and the learned FDT capture meaningful cross-modal correspondence, ranging from objects to actions and attributes.
Steering Prototype with Prompt-tuning for Rehearsal-free Continual Learning
Mar 16, 2023



Prototype, as a representation of class embeddings, has been explored to reduce memory footprint or mitigate forgetting for continual learning scenarios. However, prototype-based methods still suffer from abrupt performance deterioration due to semantic drift and prototype interference. In this study, we propose Contrastive Prototypical Prompt (CPP) and show that task-specific prompt-tuning, when optimized over a contrastive learning objective, can effectively address both obstacles and significantly improve the potency of prototypes. Our experiments demonstrate that CPP excels in four challenging class-incremental learning benchmarks, resulting in 4% to 6% absolute improvements over state-of-the-art methods. Moreover, CPP does not require a rehearsal buffer and it largely bridges the performance gap between continual learning and offline joint-learning, showcasing a promising design scheme for continual learning systems under a Transformer architecture.
3D Tooth Mesh Segmentation with Simplified Mesh Cell Representation
Jan 25, 2023Manual tooth segmentation of 3D tooth meshes is tedious and there is variations among dentists. %Manual tooth annotation of 3D tooth meshes is a tedious task. Several deep learning based methods have been proposed to perform automatic tooth mesh segmentation. Many of the proposed tooth mesh segmentation algorithms summarize the mesh cell as - the cell center or barycenter, the normal at barycenter, the cell vertices and the normals at the cell vertices. Summarizing of the mesh cell/triangle in this manner imposes an implicit structural constraint and makes it difficult to work with multiple resolutions which is done in many point cloud based deep learning algorithms. We propose a novel segmentation method which utilizes only the barycenter and the normal at the barycenter information of the mesh cell and yet achieves competitive performance. We are the first to demonstrate that it is possible to relax the implicit structural constraint and yet achieve superior segmentation performance
CDDSA: Contrastive Domain Disentanglement and Style Augmentation for Generalizable Medical Image Segmentation
Nov 22, 2022



Generalization to previously unseen images with potential domain shifts and different styles is essential for clinically applicable medical image segmentation, and the ability to disentangle domain-specific and domain-invariant features is key for achieving Domain Generalization (DG). However, existing DG methods can hardly achieve effective disentanglement to get high generalizability. To deal with this problem, we propose an efficient Contrastive Domain Disentanglement and Style Augmentation (CDDSA) framework for generalizable medical image segmentation. First, a disentangle network is proposed to decompose an image into a domain-invariant anatomical representation and a domain-specific style code, where the former is sent to a segmentation model that is not affected by the domain shift, and the disentangle network is regularized by a decoder that combines the anatomical and style codes to reconstruct the input image. Second, to achieve better disentanglement, a contrastive loss is proposed to encourage the style codes from the same domain and different domains to be compact and divergent, respectively. Thirdly, to further improve generalizability, we propose a style augmentation method based on the disentanglement representation to synthesize images in various unseen styles with shared anatomical structures. Our method was validated on a public multi-site fundus image dataset for optic cup and disc segmentation and an in-house multi-site Nasopharyngeal Carcinoma Magnetic Resonance Image (NPC-MRI) dataset for nasopharynx Gross Tumor Volume (GTVnx) segmentation. Experimental results showed that the proposed CDDSA achieved remarkable generalizability across different domains, and it outperformed several state-of-the-art methods in domain-generalizable segmentation.
Visual Prompt Tuning for Test-time Domain Adaptation
Oct 10, 2022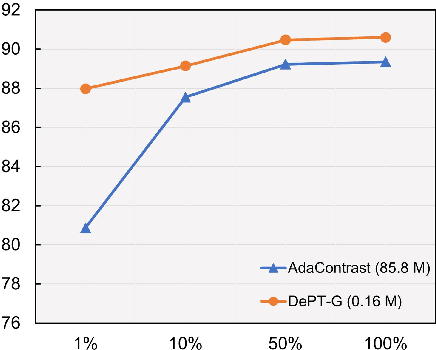
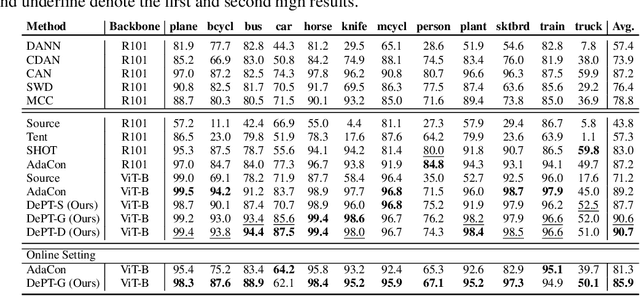
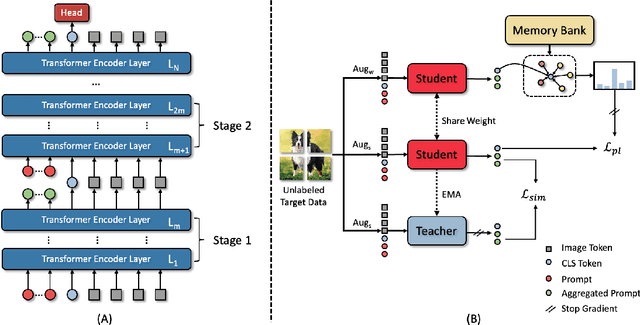
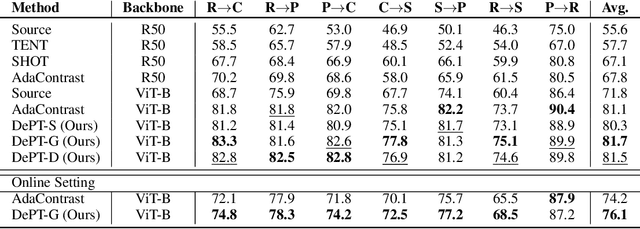
Models should have the ability to adapt to unseen data during test-time to avoid performance drop caused by inevitable distribution shifts in real-world deployment scenarios. In this work, we tackle the practical yet challenging test-time adaptation (TTA) problem, where a model adapts to the target domain without accessing the source data. We propose a simple recipe called data-efficient prompt tuning (DePT) with two key ingredients. First, DePT plugs visual prompts into the vision Transformer and only tunes these source-initialized prompts during adaptation. We find such parameter-efficient finetuning can efficiently adapt the model representation to the target domain without overfitting to the noise in the learning objective. Second, DePT bootstraps the source representation to the target domain by memory bank-based online pseudo labeling. A hierarchical self-supervised regularization specially designed for prompts is jointly optimized to alleviate error accumulation during self-training. With much fewer tunable parameters, DePT demonstrates not only state-of-the-art performance on major adaptation benchmarks, but also superior data efficiency, i.e., adaptation with only 1\% or 10\% data without much performance degradation compared to 100\% data. In addition, DePT is also versatile to be extended to online or multi-source TTA settings.
Hierarchically Self-Supervised Transformer for Human Skeleton Representation Learning
Jul 20, 2022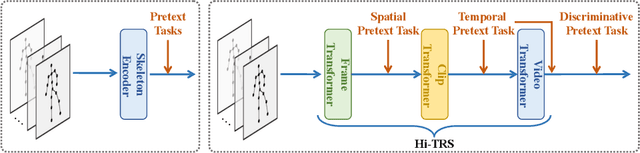
Despite the success of fully-supervised human skeleton sequence modeling, utilizing self-supervised pre-training for skeleton sequence representation learning has been an active field because acquiring task-specific skeleton annotations at large scales is difficult. Recent studies focus on learning video-level temporal and discriminative information using contrastive learning, but overlook the hierarchical spatial-temporal nature of human skeletons. Different from such superficial supervision at the video level, we propose a self-supervised hierarchical pre-training scheme incorporated into a hierarchical Transformer-based skeleton sequence encoder (Hi-TRS), to explicitly capture spatial, short-term, and long-term temporal dependencies at frame, clip, and video levels, respectively. To evaluate the proposed self-supervised pre-training scheme with Hi-TRS, we conduct extensive experiments covering three skeleton-based downstream tasks including action recognition, action detection, and motion prediction. Under both supervised and semi-supervised evaluation protocols, our method achieves the state-of-the-art performance. Additionally, we demonstrate that the prior knowledge learned by our model in the pre-training stage has strong transfer capability for different downstream tasks.