 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-Level Information Transmission Network for Predicting Phenotype from New Genotype: Application to Cancer Precision Medicine
Oct 09, 2020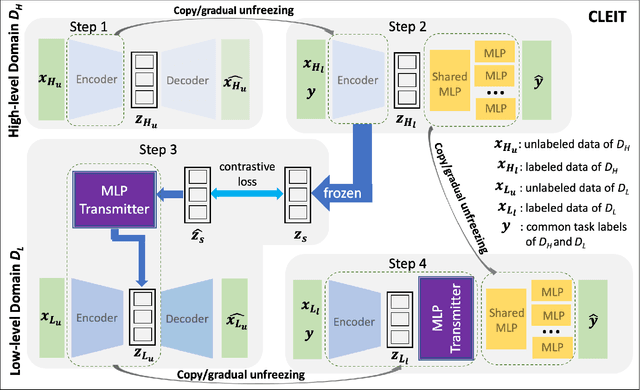
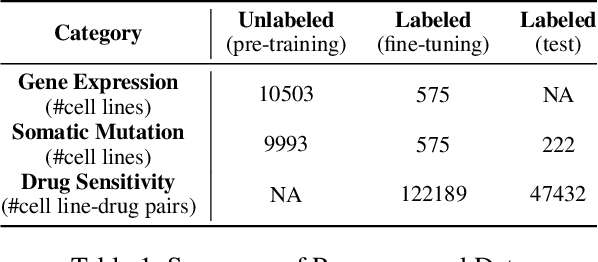
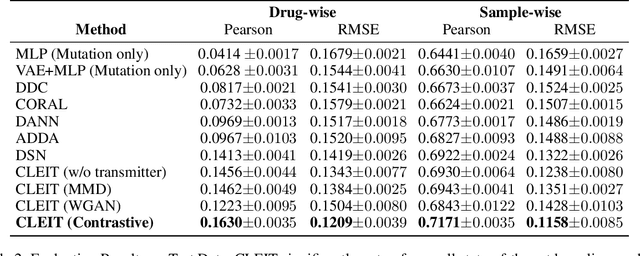
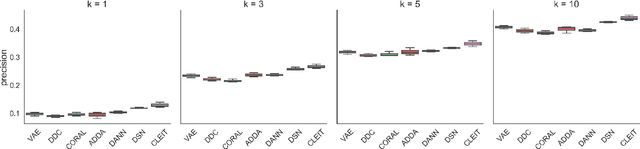
An unsolved fundamental problem in biology and ecology is to predict observable traits (phenotypes) from a new genetic constitution (genotype) of an organism under environmental perturbations (e.g., drug treatment). The emergence of multiple omics data provides new opportunities but imposes great challenges in the predictive modeling of genotype-phenotype associations. Firstly, the high-dimensionality of genomics data and the lack of labeled data often make the existing supervised learning techniques less successful. Secondly, it is a challenging task to integrate heterogeneous omics data from different resources. Finally, the information transmission from DNA to phenotype involves multiple intermediate levels of RNA, protein, metabolite, etc. The higher-level features (e.g., gene expression) usually have stronger discriminative power than the lower level features (e.g., somatic mutation). To address above issues, we proposed a novel Cross-LEvel Information Transmission network (CLEIT) framework. CLEIT aims to explicitly model the asymmetrical multi-level organization of the biological system. Inspired by domain adaptation, CLEIT first learns the latent representation of high-level domain then uses it as ground-truth embedding to improve the representation learning of the low-level domain in the form of contrastive loss. In addition, we adopt a pre-training-fine-tuning approach to leveraging the unlabeled heterogeneous omics data to improve the generalizability of CLEIT. We demonstrate the effectiveness and performance boost of CLEIT in predicting anti-cancer drug sensitivity from somatic mutations via the assistance of gene expressions when compared with state-of-the-art methods.
GraphNorm: A Principled Approach to Accelerating Graph Neural Network Training
Sep 07, 2020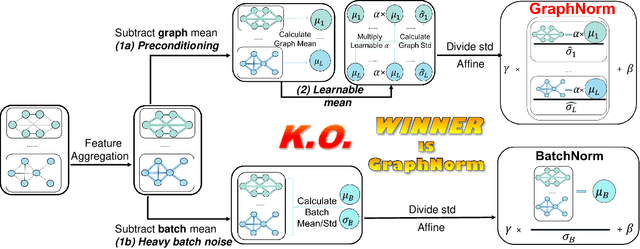
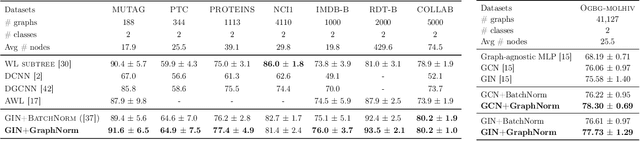
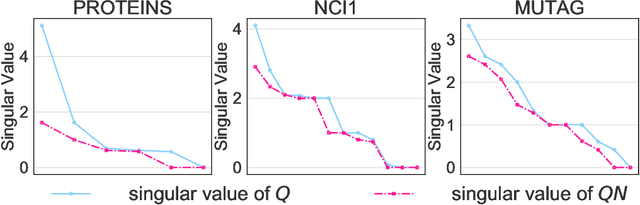
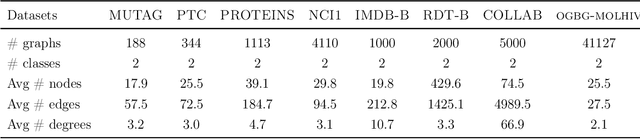
Normalization plays an important role in the optimization of deep neural networks. While there are standard normalization methods in computer vision and natural language processing, there is limited understanding of how to effectively normalize neural networks for graph representation learning. In this paper, we propose a principled normalization method, Graph Normalization (GraphNorm), where the key idea is to normalize the feature values across all nodes for each individual graph with a learnable shift. Theoretically, we show that GraphNorm serves as a preconditioner that smooths the distribution of the graph aggregation's spectrum, leading to faster optimization. Such an improvement cannot be well obtained if we use currently popular normalization methods, such as BatchNorm, which normalizes the nodes in a batch rather than in individual graphs, due to heavy batch noises. Moreover, we show that for some highly regular graphs, the mean of the feature values contains graph structural information, and directly subtracting the mean may lead to an expressiveness degradation. The learnable shift in GraphNorm enables the model to learn to avoid such degradation for those cases. Empirically, Graph neural networks (GNNs) with GraphNorm converge much faster compared to GNNs with other normalization methods, e.g., BatchNorm. GraphNorm also improves generalization of GNNs, achieving better performance on graph classification benchmarks.
Taking Notes on the Fly Helps BERT Pre-training
Aug 04, 2020
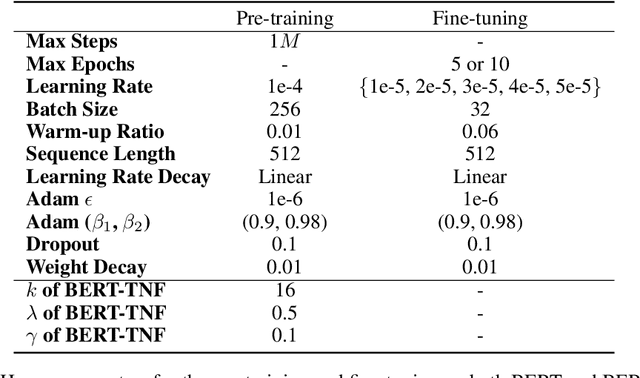
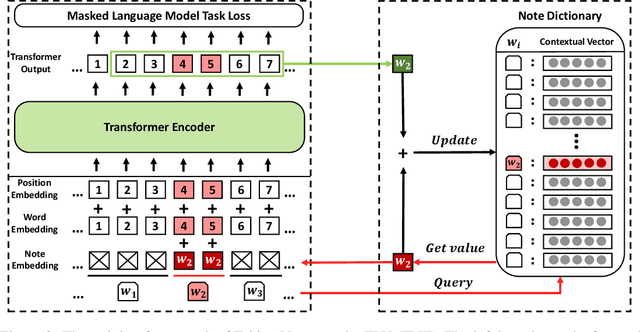

How to make unsupervised language pre-training more efficient and less resource-intensive is an important research direction in NLP. In this paper, we focus on improving the efficiency of language pre-training methods through providing better data utilization. It is well-known that in language data corpus, words follow a heavy-tail distribution. A large proportion of words appear only very few times and the embeddings of rare words are usually poorly optimized. We argue that such embeddings carry inadequate semantic signals. They could make the data utilization inefficient and slow down the pre-training of the entire model. To solve this problem, we propose Taking Notes on the Fly (TNF). TNF takes notes for rare words on the fly during pre-training to help the model understand them when they occur next time. Specifically, TNF maintains a note dictionary and saves a rare word's context information in it as notes when the rare word occurs in a sentence. When the same rare word occurs again in training, TNF employs the note information saved beforehand to enhance the semantics of the current sentence. By doing so, TNF provides a better data utilization since cross-sentence information is employed to cover the inadequate semantics caused by rare words in the sentences. Experimental results show that TNF significantly expedite the BERT pre-training and improve the model's performance on downstream tasks. TNF's training time is $60\%$ less than BERT when reaching the same performance. When trained with same number of iterations, TNF significantly outperforms BERT on most of downstream tasks and the average GLUE score.
Transferred Discrepancy: Quantifying the Difference Between Representations
Jul 24, 2020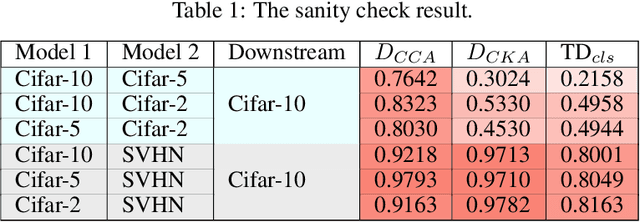
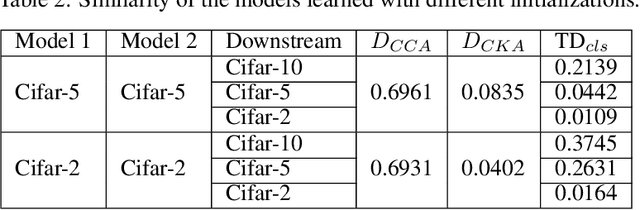
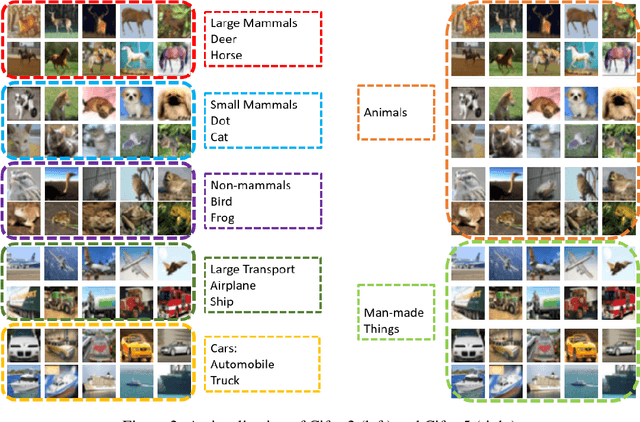
Understanding what information neural networks capture is an essential problem in deep learning, and studying whether different models capture similar features is an initial step to achieve this goal. Previous works sought to define metrics over the feature matrices to measure the difference between two models. However, different metrics sometimes lead to contradictory conclusions, and there has been no consensus on which metric is suitable to use in practice. In this work, we propose a novel metric that goes beyond previous approaches. Recall that one of the most practical scenarios of using the learned representations is to apply them to downstream tasks. We argue that we should design the metric based on a similar principle. For that, we introduce the transferred discrepancy (TD), a new metric that defines the difference between two representations based on their downstream-task performance. Through an asymptotic analysis, we show how TD correlates with downstream tasks and the necessity to define metrics in such a task-dependent fashion. In particular, we also show that under specific conditions, the TD metric is closely related to previous metrics. Our experiments show that TD can provide fine-grained information for varied downstream tasks, and for the models trained from different initializations, the learned features are not the same in terms of downstream-task predictions. We find that TD may also be used to evaluate the effectiveness of different training strategies. For example, we demonstrate that the models trained with proper data augmentations that improve the generalization capture more similar features in terms of TD, while those with data augmentations that hurt the generalization will not. This suggests a training strategy that leads to more robust representation also trains models that generalize better.
Rethinking Positional Encoding in Language Pre-training
Jul 09, 2020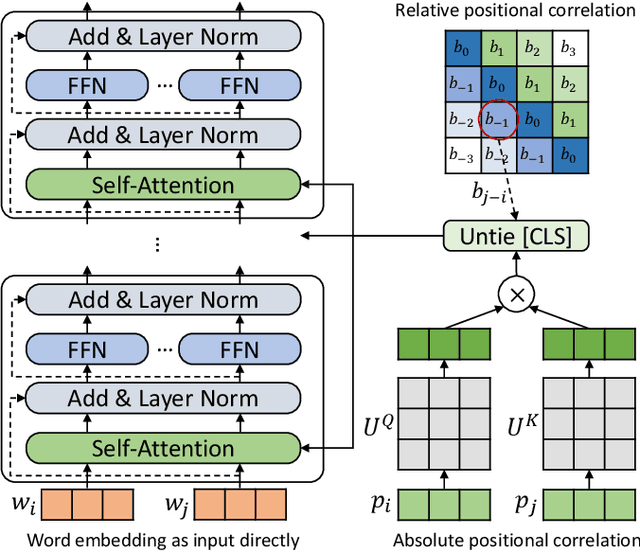
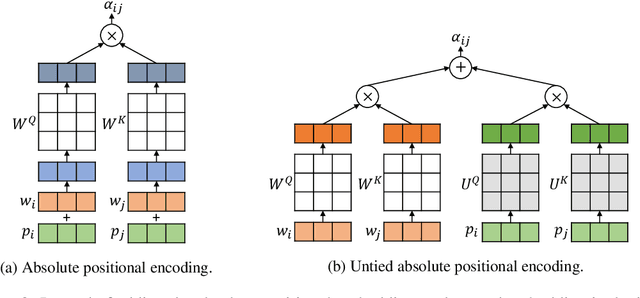
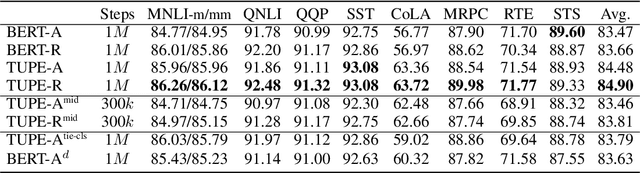
How to explicitly encode positional information into neural networks is important in learning the representation of natural languages, such as BERT. Based on the Transformer architecture, the positional information is simply encoded as embedding vectors, which are used in the input layer, or encoded as a bias term in the self-attention module. In this work, we investigate the problems in the previous formulations and propose a new positional encoding method for BERT called Transformer with Untied Positional Encoding (TUPE). Different from all other works, TUPE only uses the word embedding as input. In the self-attention module, the word contextual correlation and positional correlation are computed separately with different parameterizations and then added together. This design removes the addition over heterogeneous embeddings in the input, which may potentially bring randomness, and gives more expressiveness to characterize the relationship between words/positions by using different projection matrices. Furthermore, TUPE unties the [CLS] symbol from other positions to provide it with a more specific role to capture the global representation of the sentence. Extensive experiments and ablation studies on GLUE benchmark demonstrate the effectiveness and efficiency of the proposed method: TUPE outperforms several baselines on almost all tasks by a large margin. In particular, it can achieve a higher score than baselines while only using 30% pre-training computational costs. We release our code at https://github.com/guolinke/TUPE.
MC-BERT: Efficient Language Pre-Training via a Meta Controller
Jun 16, 2020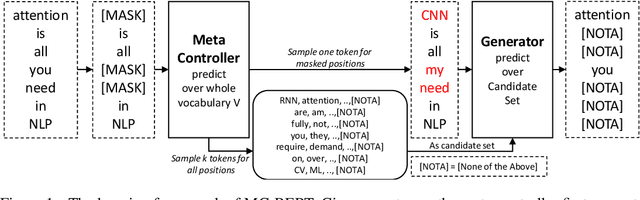

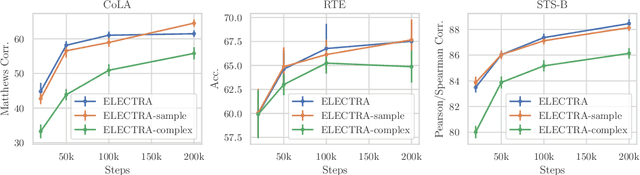

Pre-trained contextual representations (e.g., BERT) have become the foundation to achieve state-of-the-art results on many NLP tasks. However, large-scale pre-training is computationally expensive. ELECTRA, an early attempt to accelerate pre-training, trains a discriminative model that predicts whether each input token was replaced by a generator. Our studies reveal that ELECTRA's success is mainly due to its reduced complexity of the pre-training task: the binary classification (replaced token detection) is more efficient to learn than the generation task (masked language modeling). However, such a simplified task is less semantically informative. To achieve better efficiency and effectiveness, we propose a novel meta-learning framework, MC-BERT. The pre-training task is a multi-choice cloze test with a reject option, where a meta controller network provides training input and candidates. Results over GLUE natural language understanding benchmark demonstrate that our proposed method is both efficient and effective: it outperforms baselines on GLUE semantic tasks given the same computational budget.
Invertible Image Rescaling
May 12, 2020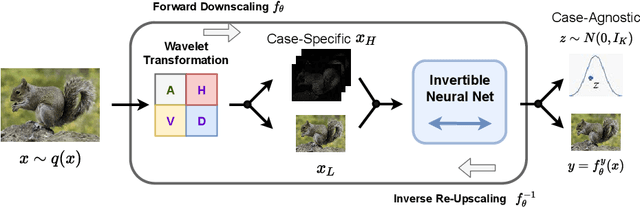
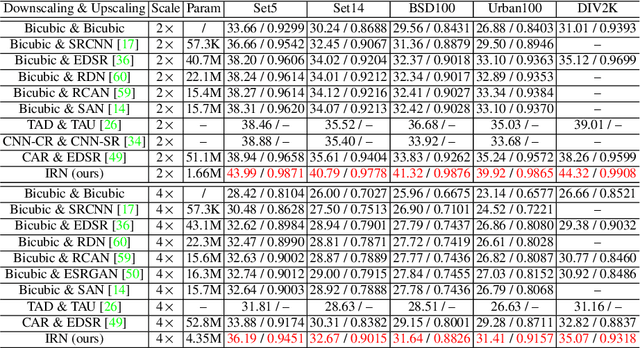
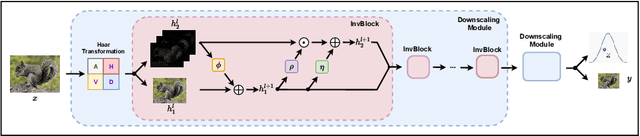
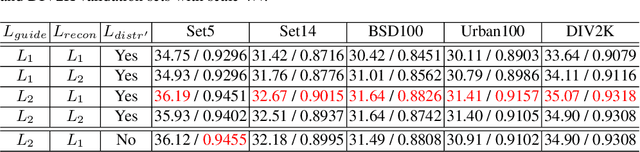
High-resolution digital images are usually downscaled to fit various display screens or save the cost of storage and bandwidth, meanwhile the post-upscaling is adpoted to recover the original resolutions or the details in the zoom-in images. However, typical image downscaling is a non-injective mapping due to the loss of high-frequency information, which leads to the ill-posed problem of the inverse upscaling procedure and poses great challenges for recovering details from the downscaled low-resolution images. Simply upscaling with image super-resolution methods results in unsatisfactory recovering performance. In this work, we propose to solve this problem by modeling the downscaling and upscaling processes from a new perspective, i.e. an invertible bijective transformation, which can largely mitigate the ill-posed nature of image upscaling. We develop an Invertible Rescaling Net (IRN) with deliberately designed framework and objectives to produce visually-pleasing low-resolution images and meanwhile capture the distribution of the lost information using a latent variable following a specified distribution in the downscaling process. In this way, upscaling is made tractable by inversely passing a randomly-drawn latent variable with the low-resolution image through the network. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of image upscaling reconstruction from downscaled images.
Incorporating BERT into Neural Machine Translation
Feb 17, 2020
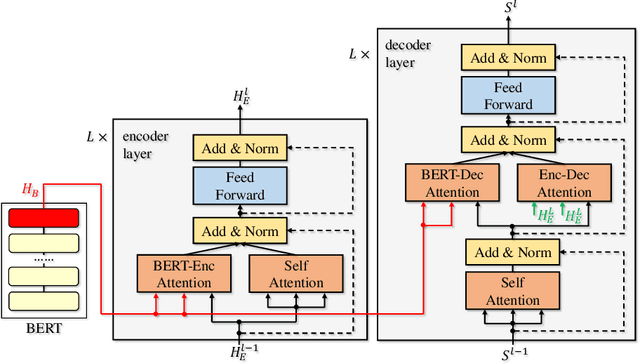
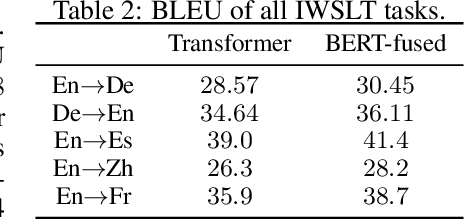
The recently proposed BERT has shown great power on a variety of natural language understanding tasks, such as text classification, reading comprehension, etc. However, how to effectively apply BERT to neural machine translation (NMT) lacks enough exploration. While BERT is more commonly used as fine-tuning instead of contextual embedding for downstream language understanding tasks, in NMT, our preliminary exploration of using BERT as contextual embedding is better than using for fine-tuning. This motivates us to think how to better leverage BERT for NMT along this direction. We propose a new algorithm named BERT-fused model, in which we first use BERT to extract representations for an input sequence, and then the representations are fused with each layer of the encoder and decoder of the NMT model through attention mechanisms. We conduct experiments on supervised (including sentence-level and document-level translations), semi-supervised and unsupervised machine translation, and achieve state-of-the-art results on seven benchmark datasets. Our code is available at \url{https://github.com/bert-nmt/bert-nmt}.
MACER: Attack-free and Scalable Robust Training via Maximizing Certified Radius
Feb 15, 2020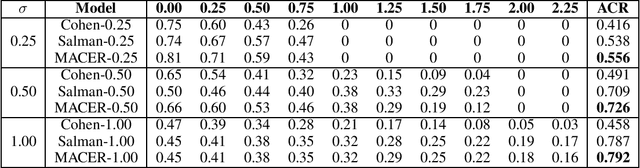
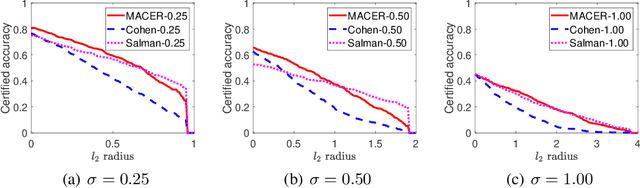
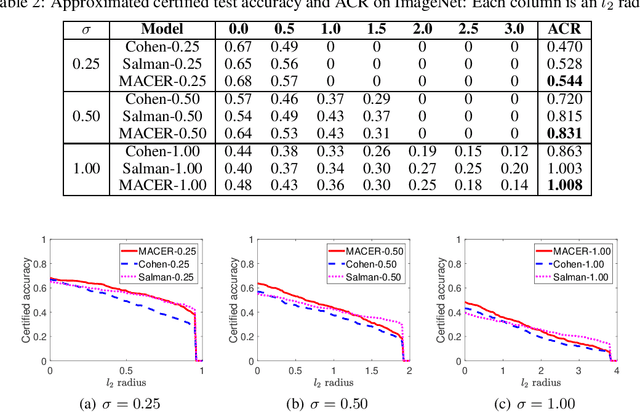
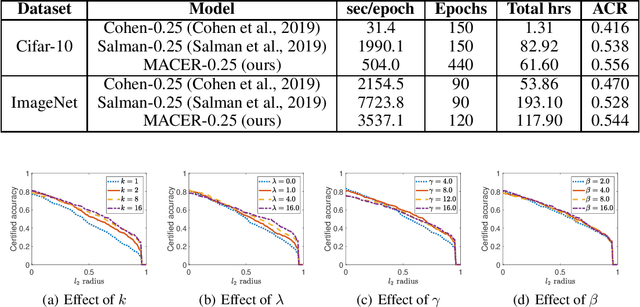
Adversarial training is one of the most popular ways to learn robust models but is usually attack-dependent and time costly. In this paper, we propose the MACER algorithm, which learns robust models without using adversarial training but performs better than all existing provable l2-defenses. Recent work shows that randomized smoothing can be used to provide a certified l2 radius to smoothed classifiers, and our algorithm trains provably robust smoothed classifiers via MAximizing the CErtified Radius (MACER). The attack-free characteristic makes MACER faster to train and easier to optimize. In our experiments, we show that our method can be applied to modern deep neural networks on a wide range of datasets, including Cifar-10, ImageNet, MNIST, and SVHN. For all tasks, MACER spends less training time than state-of-the-art adversarial training algorithms, and the learned models achieve larger average certified radius.
On Layer Normalization in the Transformer Architecture
Feb 12, 2020

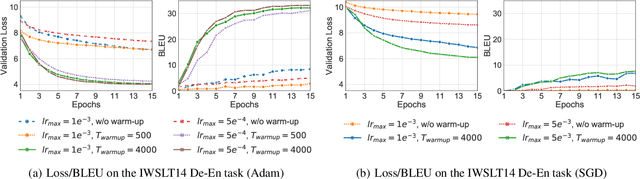

The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning on a wide range of applications.