 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuaranteed Tensor Recovery Fused Low-rankness and Smoothness
Feb 04, 2023



The tensor data recovery task has thus attracted much research attention in recent years. Solving such an ill-posed problem generally requires to explore intrinsic prior structures underlying tensor data, and formulate them as certain forms of regularization terms for guiding a sound estimate of the restored tensor. Recent research have made significant progress by adopting two insightful tensor priors, i.e., global low-rankness (L) and local smoothness (S) across different tensor modes, which are always encoded as a sum of two separate regularization terms into the recovery models. However, unlike the primary theoretical developments on low-rank tensor recovery, these joint L+S models have no theoretical exact-recovery guarantees yet, making the methods lack reliability in real practice. To this crucial issue, in this work, we build a unique regularization term, which essentially encodes both L and S priors of a tensor simultaneously. Especially, by equipping this single regularizer into the recovery models, we can rigorously prove the exact recovery guarantees for two typical tensor recovery tasks, i.e., tensor completion (TC) and tensor robust principal component analysis (TRPCA). To the best of our knowledge, this should be the first exact-recovery results among all related L+S methods for tensor recovery. Significant recovery accuracy improvements over many other SOTA methods in several TC and TRPCA tasks with various kinds of visual tensor data are observed in extensive experiments. Typically, our method achieves a workable performance when the missing rate is extremely large, e.g., 99.5%, for the color image inpainting task, while all its peers totally fail in such challenging case.
Improve Noise Tolerance of Robust Loss via Noise-Awareness
Jan 18, 2023Robust loss minimization is an important strategy for handling robust learning issue on noisy labels. Current robust losses, however, inevitably involve hyperparameters to be tuned for different datasets with noisy labels, manually or heuristically through cross validation, which makes them fairly hard to be generally applied in practice. Existing robust loss methods usually assume that all training samples share common hyperparameters, which are independent of instances. This limits the ability of these methods on distinguishing individual noise properties of different samples, making them hardly adapt to different noise structures. To address above issues, we propose to assemble robust loss with instance-dependent hyperparameters to improve their noise-tolerance with theoretical guarantee. To achieve setting such instance-dependent hyperparameters for robust loss, we propose a meta-learning method capable of adaptively learning a hyperparameter prediction function, called Noise-Aware-Robust-Loss-Adjuster (NARL-Adjuster). Specifically, through mutual amelioration between hyperparameter prediction function and classifier parameters in our method, both of them can be simultaneously finely ameliorated and coordinated to attain solutions with good generalization capability. Four kinds of SOTA robust losses are attempted to be integrated with our algorithm, and experiments substantiate the general availability and effectiveness of the proposed method in both its noise tolerance and generalization performance. Meanwhile, the explicit parameterized structure makes the meta-learned prediction function capable of being readily transferrable and plug-and-play to unseen datasets with noisy labels. Specifically, we transfer our meta-learned NARL-Adjuster to unseen tasks, including several real noisy datasets, and achieve better performance compared with conventional hyperparameter tuning strategy.
Deep Diversity-Enhanced Feature Representation of Hyperspectral Images
Jan 15, 2023



In this paper, we study the problem of embedding the high-dimensional spatio-spectral information of hyperspectral (HS) images efficiently and effectively, oriented by feature diversity. To be specific, based on the theoretical formulation that feature diversity is correlated with the rank of the unfolded kernel matrix, we rectify 3D convolution by modifying its topology to boost the rank upper-bound, yielding a rank-enhanced spatial-spectral symmetrical convolution set (ReS$^3$-ConvSet), which is able to not only learn diverse and powerful feature representations but also save network parameters. In addition, we also propose a novel diversity-aware regularization (DA-Reg) term, which acts directly on the feature maps to maximize the independence among elements. To demonstrate the superiority of the proposed ReS$^3$-ConvSet and DA-Reg, we apply them to various HS image processing and analysis tasks, including denoising, spatial super-resolution, and classification. Extensive experiments demonstrate that the proposed approaches outperform state-of-the-art methods to a significant extent both quantitatively and qualitatively. The code is publicly available at \url{https://github.com/jinnh/ReSSS-ConvSet}.
NeuroExplainer: Fine-Grained Attention Decoding to Uncover Cortical Development Patterns of Preterm Infants
Jan 01, 2023Deploying reliable deep learning techniques in interdisciplinary applications needs learned models to output accurate and ({even more importantly}) explainable predictions. Existing approaches typically explicate network outputs in a post-hoc fashion, under an implicit assumption that faithful explanations come from accurate predictions/classifications. We have an opposite claim that explanations boost (or even determine) classification. That is, end-to-end learning of explanation factors to augment discriminative representation extraction could be a more intuitive strategy to inversely assure fine-grained explainability, e.g., in those neuroimaging and neuroscience studies with high-dimensional data containing noisy, redundant, and task-irrelevant information. In this paper, we propose such an explainable geometric deep network dubbed as NeuroExplainer, with applications to uncover altered infant cortical development patterns associated with preterm birth. Given fundamental cortical attributes as network input, our NeuroExplainer adopts a hierarchical attention-decoding framework to learn fine-grained attentions and respective discriminative representations to accurately recognize preterm infants from term-born infants at term-equivalent age. NeuroExplainer learns the hierarchical attention-decoding modules under subject-level weak supervision coupled with targeted regularizers deduced from domain knowledge regarding brain development. These prior-guided constraints implicitly maximizes the explainability metrics (i.e., fidelity, sparsity, and stability) in network training, driving the learned network to output detailed explanations and accurate classifications. Experimental results on the public dHCP benchmark suggest that NeuroExplainer led to quantitatively reliable explanation results that are qualitatively consistent with representative neuroimaging studies.
S2S-WTV: Seismic Data Noise Attenuation Using Weighted Total Variation Regularized Self-Supervised Learning
Dec 27, 2022



Seismic data often undergoes severe noise due to environmental factors, which seriously affects subsequent applications. Traditional hand-crafted denoisers such as filters and regularizations utilize interpretable domain knowledge to design generalizable denoising techniques, while their representation capacities may be inferior to deep learning denoisers, which can learn complex and representative denoising mappings from abundant training pairs. However, due to the scarcity of high-quality training pairs, deep learning denoisers may sustain some generalization issues over various scenarios. In this work, we propose a self-supervised method that combines the capacities of deep denoiser and the generalization abilities of hand-crafted regularization for seismic data random noise attenuation. Specifically, we leverage the Self2Self (S2S) learning framework with a trace-wise masking strategy for seismic data denoising by solely using the observed noisy data. Parallelly, we suggest the weighted total variation (WTV) to further capture the horizontal local smooth structure of seismic data. Our method, dubbed as S2S-WTV, enjoys both high representation abilities brought from the self-supervised deep network and good generalization abilities of the hand-crafted WTV regularizer and the self-supervised nature. Therefore, our method can more effectively and stably remove the random noise and preserve the details and edges of the clean signal. To tackle the S2S-WTV optimization model, we introduce an alternating direction multiplier method (ADMM)-based algorithm. Extensive experiments on synthetic and field noisy seismic data demonstrate the effectiveness of our method as compared with state-of-the-art traditional and deep learning-based seismic data denoising methods.
Orientation-Shared Convolution Representation for CT Metal Artifact Learning
Dec 26, 2022During X-ray computed tomography (CT) scanning, metallic implants carrying with patients often lead to adverse artifacts in the captured CT images and then impair the clinical treatment. Against this metal artifact reduction (MAR) task, the existing deep-learning-based methods have gained promising reconstruction performance. Nevertheless, there is still some room for further improvement of MAR performance and generalization ability, since some important prior knowledge underlying this specific task has not been fully exploited. Hereby, in this paper, we carefully analyze the characteristics of metal artifacts and propose an orientation-shared convolution representation strategy to adapt the physical prior structures of artifacts, i.e., rotationally symmetrical streaking patterns. The proposed method rationally adopts Fourier-series-expansion-based filter parametrization in artifact modeling, which can better separate artifacts from anatomical tissues and boost the model generalizability. Comprehensive experiments executed on synthesized and clinical datasets show the superiority of our method in detail preservation beyond the current representative MAR methods. Code will be available at \url{https://github.com/hongwang01/OSCNet}
Low-Rank Tensor Function Representation for Multi-Dimensional Data Recovery
Dec 01, 2022



Since higher-order tensors are naturally suitable for representing multi-dimensional data in real-world, e.g., color images and videos, low-rank tensor representation has become one of the emerging areas in machine learning and computer vision. However, classical low-rank tensor representations can only represent data on finite meshgrid due to their intrinsical discrete nature, which hinders their potential applicability in many scenarios beyond meshgrid. To break this barrier, we propose a low-rank tensor function representation (LRTFR), which can continuously represent data beyond meshgrid with infinite resolution. Specifically, the suggested tensor function, which maps an arbitrary coordinate to the corresponding value, can continuously represent data in an infinite real space. Parallel to discrete tensors, we develop two fundamental concepts for tensor functions, i.e., the tensor function rank and low-rank tensor function factorization. We theoretically justify that both low-rank and smooth regularizations are harmoniously unified in the LRTFR, which leads to high effectiveness and efficiency for data continuous representation. Extensive multi-dimensional data recovery applications arising from image processing (image inpainting and denoising), machine learning (hyperparameter optimization), and computer graphics (point cloud upsampling) substantiate the superiority and versatility of our method as compared with state-of-the-art methods. Especially, the experiments beyond the original meshgrid resolution (hyperparameter optimization) or even beyond meshgrid (point cloud upsampling) validate the favorable performances of our method for continuous representation.
Fast Noise Removal in Hyperspectral Images via Representative Coefficient Total Variation
Nov 03, 2022Mining structural priors in data is a widely recognized technique for hyperspectral image (HSI) denoising tasks, whose typical ways include model-based methods and data-based methods. The model-based methods have good generalization ability, while the runtime cannot meet the fast processing requirements of the practical situations due to the large size of an HSI data $ \mathbf{X} \in \mathbb{R}^{MN\times B}$. For the data-based methods, they perform very fast on new test data once they have been trained. However, their generalization ability is always insufficient. In this paper, we propose a fast model-based HSI denoising approach. Specifically, we propose a novel regularizer named Representative Coefficient Total Variation (RCTV) to simultaneously characterize the low rank and local smooth properties. The RCTV regularizer is proposed based on the observation that the representative coefficient matrix $\mathbf{U}\in\mathbb{R}^{MN\times R} (R\ll B)$ obtained by orthogonally transforming the original HSI $\mathbf{X}$ can inherit the strong local-smooth prior of $\mathbf{X}$. Since $R/B$ is very small, the HSI denoising model based on the RCTV regularizer has lower time complexity. Additionally, we find that the representative coefficient matrix $\mathbf{U}$ is robust to noise, and thus the RCTV regularizer can somewhat promote the robustness of the HSI denoising model. Extensive experiments on mixed noise removal demonstrate the superiority of the proposed method both in denoising performance and denoising speed compared with other state-of-the-art methods. Remarkably, the denoising speed of our proposed method outperforms all the model-based techniques and is comparable with the deep learning-based approaches.
Deep Fourier Up-Sampling
Oct 11, 2022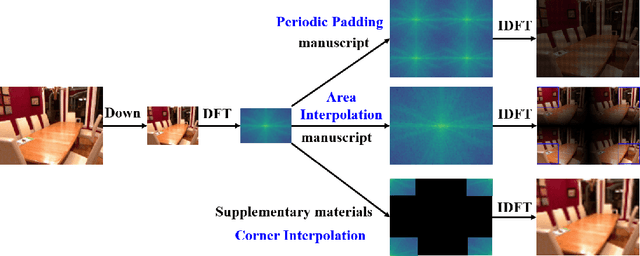
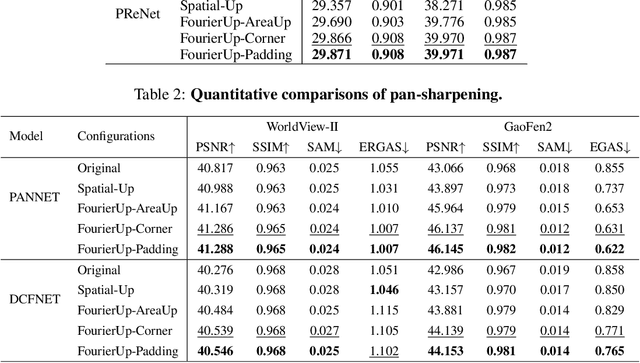
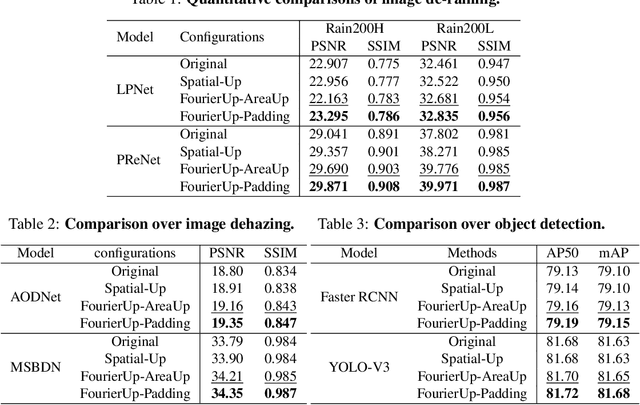
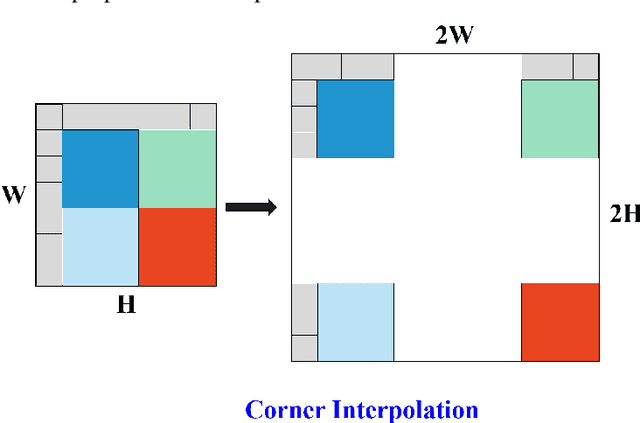
Existing convolutional neural networks widely adopt spatial down-/up-sampling for multi-scale modeling. However, spatial up-sampling operators (\emph{e.g.}, interpolation, transposed convolution, and un-pooling) heavily depend on local pixel attention, incapably exploring the global dependency. In contrast, the Fourier domain obeys the nature of global modeling according to the spectral convolution theorem. Unlike the spatial domain that performs up-sampling with the property of local similarity, up-sampling in the Fourier domain is more challenging as it does not follow such a local property. In this study, we propose a theoretically sound Deep Fourier Up-Sampling (FourierUp) to solve these issues. We revisit the relationships between spatial and Fourier domains and reveal the transform rules on the features of different resolutions in the Fourier domain, which provide key insights for FourierUp's designs. FourierUp as a generic operator consists of three key components: 2D discrete Fourier transform, Fourier dimension increase rules, and 2D inverse Fourier transform, which can be directly integrated with existing networks. Extensive experiments across multiple computer vision tasks, including object detection, image segmentation, image de-raining, image dehazing, and guided image super-resolution, demonstrate the consistent performance gains obtained by introducing our FourierUp.
A Learnable Optimization and Regularization Approach to Massive MIMO CSI Feedback
Sep 30, 2022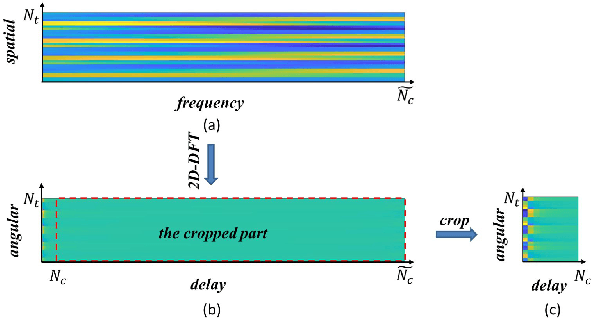
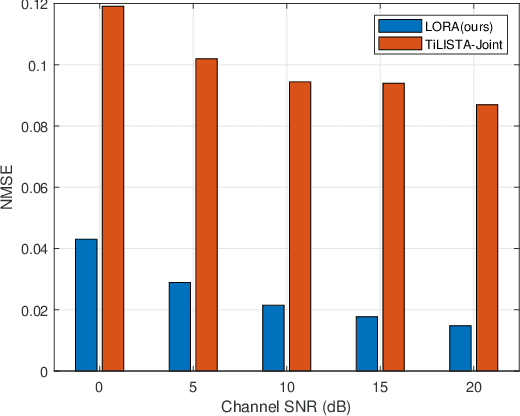
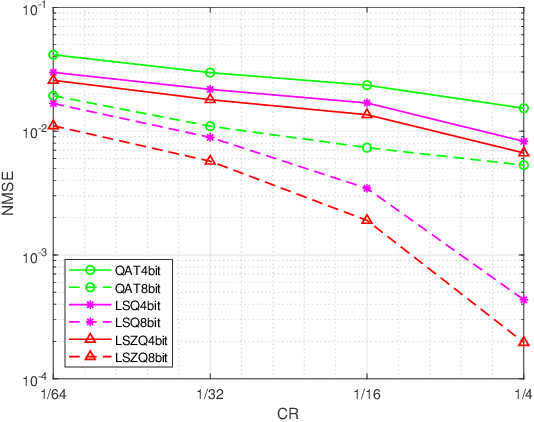
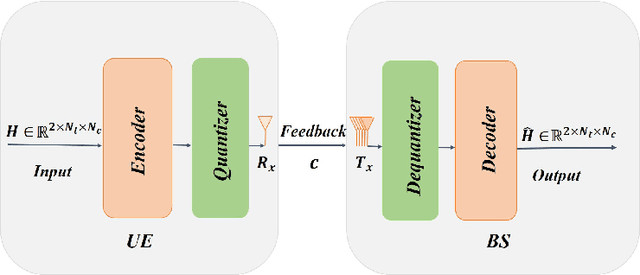
Channel state information (CSI) plays a critical role in achieving the potential benefits of massive multiple input multiple output (MIMO) systems. In frequency division duplex (FDD) massive MIMO systems, the base station (BS) relies on sustained and accurate CSI feedback from the users. However, due to the large number of antennas and users being served in massive MIMO systems, feedback overhead can become a bottleneck. In this paper, we propose a model-driven deep learning method for CSI feedback, called learnable optimization and regularization algorithm (LORA). Instead of using l1-norm as the regularization term, a learnable regularization module is introduced in LORA to automatically adapt to the characteristics of CSI. We unfold the conventional iterative shrinkage-thresholding algorithm (ISTA) to a neural network and learn both the optimization process and regularization term by end-toend training. We show that LORA improves the CSI feedback accuracy and speed. Besides, a novel learnable quantization method and the corresponding training scheme are proposed, and it is shown that LORA can operate successfully at different bit rates, providing flexibility in terms of the CSI feedback overhead. Various realistic scenarios are considered to demonstrate the effectiveness and robustness of LORA through numerical simulations.