 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Fourier Up-Sampling
Oct 11, 2022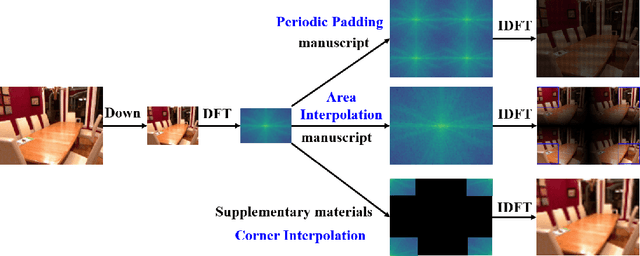
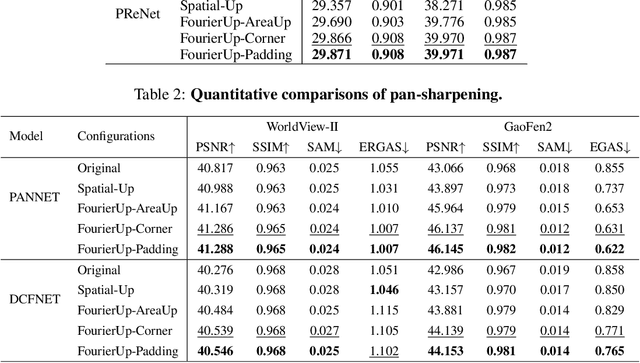
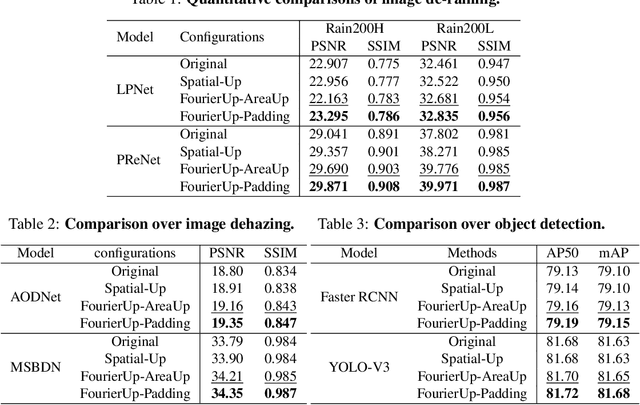
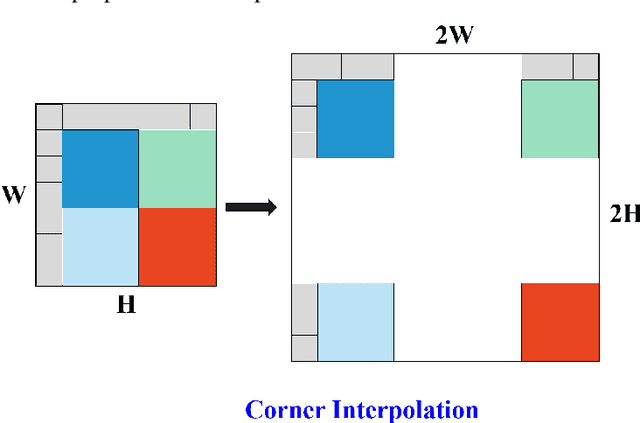
Existing convolutional neural networks widely adopt spatial down-/up-sampling for multi-scale modeling. However, spatial up-sampling operators (\emph{e.g.}, interpolation, transposed convolution, and un-pooling) heavily depend on local pixel attention, incapably exploring the global dependency. In contrast, the Fourier domain obeys the nature of global modeling according to the spectral convolution theorem. Unlike the spatial domain that performs up-sampling with the property of local similarity, up-sampling in the Fourier domain is more challenging as it does not follow such a local property. In this study, we propose a theoretically sound Deep Fourier Up-Sampling (FourierUp) to solve these issues. We revisit the relationships between spatial and Fourier domains and reveal the transform rules on the features of different resolutions in the Fourier domain, which provide key insights for FourierUp's designs. FourierUp as a generic operator consists of three key components: 2D discrete Fourier transform, Fourier dimension increase rules, and 2D inverse Fourier transform, which can be directly integrated with existing networks. Extensive experiments across multiple computer vision tasks, including object detection, image segmentation, image de-raining, image dehazing, and guided image super-resolution, demonstrate the consistent performance gains obtained by introducing our FourierUp.
A Learnable Optimization and Regularization Approach to Massive MIMO CSI Feedback
Sep 30, 2022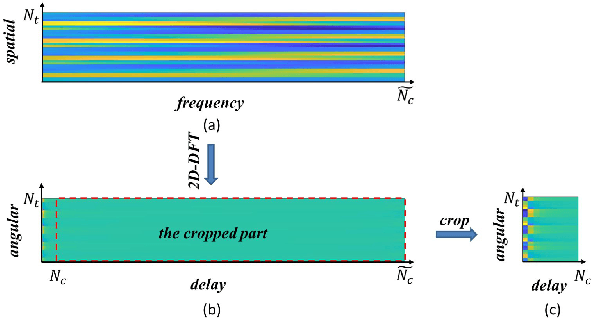
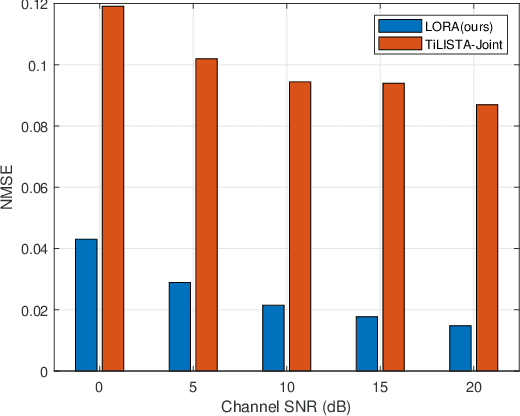
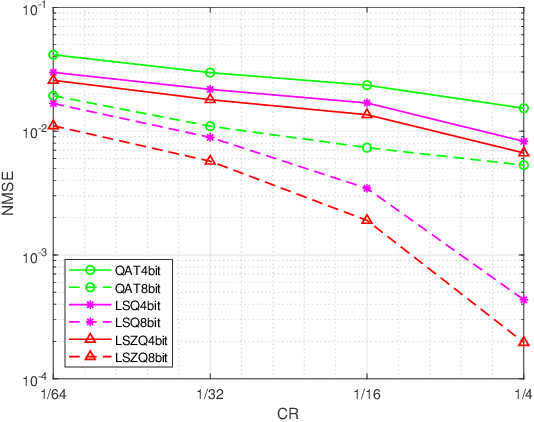
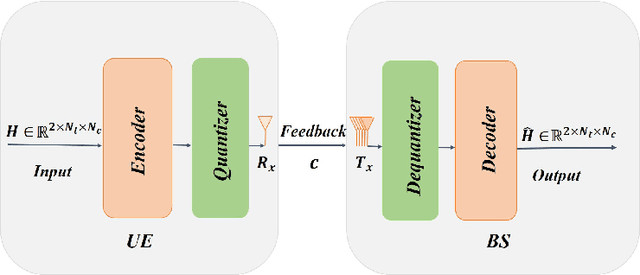
Channel state information (CSI) plays a critical role in achieving the potential benefits of massive multiple input multiple output (MIMO) systems. In frequency division duplex (FDD) massive MIMO systems, the base station (BS) relies on sustained and accurate CSI feedback from the users. However, due to the large number of antennas and users being served in massive MIMO systems, feedback overhead can become a bottleneck. In this paper, we propose a model-driven deep learning method for CSI feedback, called learnable optimization and regularization algorithm (LORA). Instead of using l1-norm as the regularization term, a learnable regularization module is introduced in LORA to automatically adapt to the characteristics of CSI. We unfold the conventional iterative shrinkage-thresholding algorithm (ISTA) to a neural network and learn both the optimization process and regularization term by end-toend training. We show that LORA improves the CSI feedback accuracy and speed. Besides, a novel learnable quantization method and the corresponding training scheme are proposed, and it is shown that LORA can operate successfully at different bit rates, providing flexibility in terms of the CSI feedback overhead. Various realistic scenarios are considered to demonstrate the effectiveness and robustness of LORA through numerical simulations.
KXNet: A Model-Driven Deep Neural Network for Blind Super-Resolution
Sep 22, 2022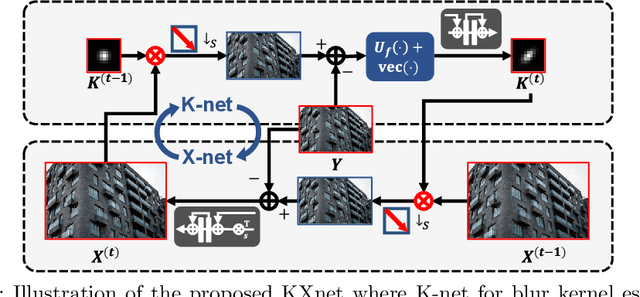
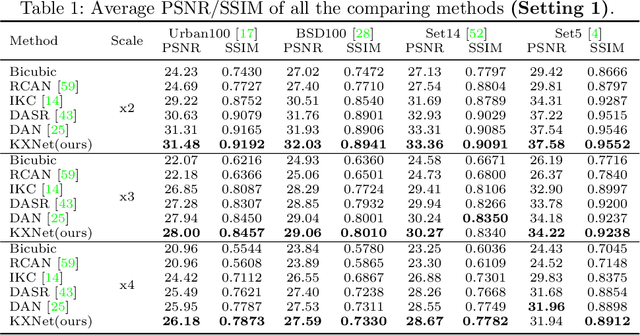
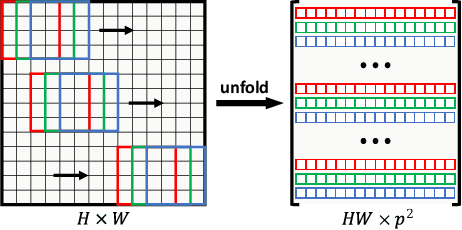
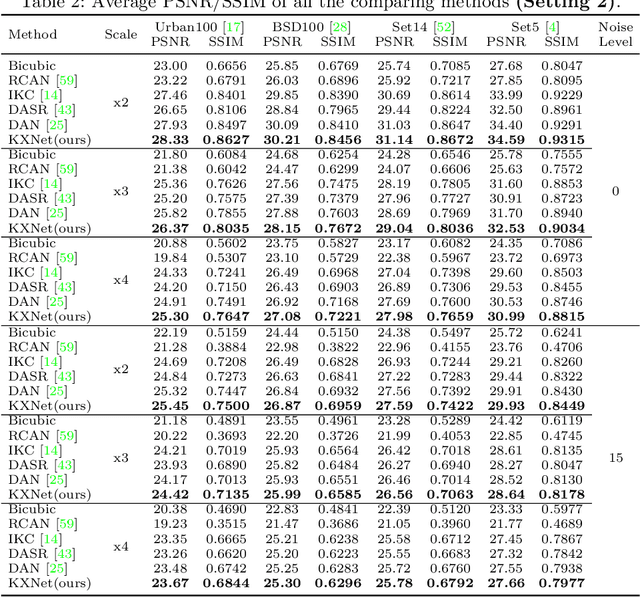
Although current deep learning-based methods have gained promising performance in the blind single image super-resolution (SISR) task, most of them mainly focus on heuristically constructing diverse network architectures and put less emphasis on the explicit embedding of the physical generation mechanism between blur kernels and high-resolution (HR) images. To alleviate this issue, we propose a model-driven deep neural network, called KXNet, for blind SISR. Specifically, to solve the classical SISR model, we propose a simple-yet-effective iterative algorithm. Then by unfolding the involved iterative steps into the corresponding network module, we naturally construct the KXNet. The main specificity of the proposed KXNet is that the entire learning process is fully and explicitly integrated with the inherent physical mechanism underlying this SISR task. Thus, the learned blur kernel has clear physical patterns and the mutually iterative process between blur kernel and HR image can soundly guide the KXNet to be evolved in the right direction. Extensive experiments on synthetic and real data finely demonstrate the superior accuracy and generality of our method beyond the current representative state-of-the-art blind SISR methods. Code is available at: https://github.com/jiahong-fu/KXNet.
Learning to Adapt Classifier for Imbalanced Semi-supervised Learning
Jul 28, 2022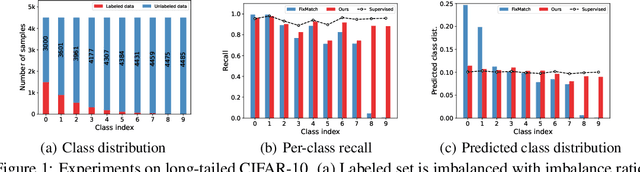
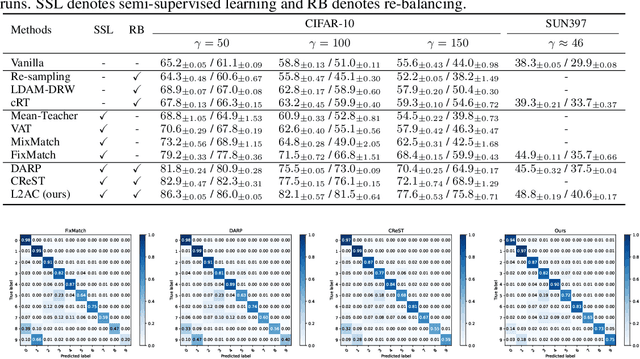
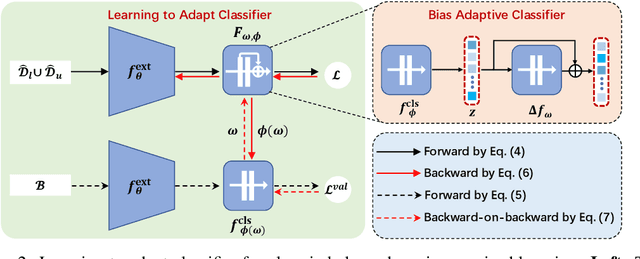
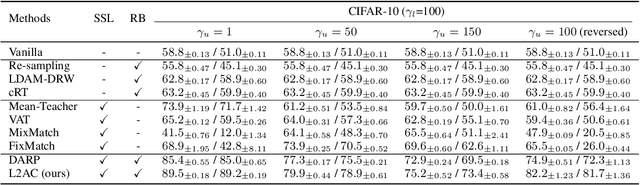
Pseudo-labeling has proven to be a promising semi-supervised learning (SSL) paradigm. Existing pseudo-labeling methods commonly assume that the class distributions of training data are balanced. However, such an assumption is far from realistic scenarios and existing pseudo-labeling methods suffer from severe performance degeneration in the context of class-imbalance. In this work, we investigate pseudo-labeling under imbalanced semi-supervised setups. The core idea is to automatically assimilate the training bias arising from class-imbalance, using a bias adaptive classifier that equips the original linear classifier with a bias attractor. The bias attractor is designed to be a light-weight residual network for adapting to the training bias. Specifically, the bias attractor is learned through a bi-level learning framework such that the bias adaptive classifier is able to fit imbalanced training data, while the linear classifier can give unbiased label prediction for each class. We conduct extensive experiments under various imbalanced semi-supervised setups, and the results demonstrate that our method can be applicable to different pseudo-labeling models and superior to the prior arts.
Adaptive Convolutional Dictionary Network for CT Metal Artifact Reduction
May 16, 2022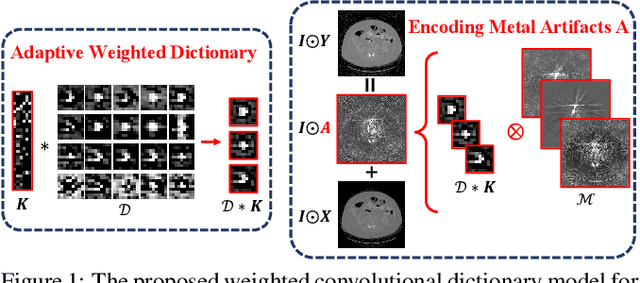
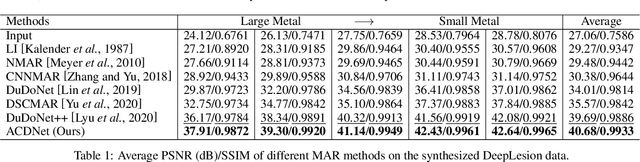
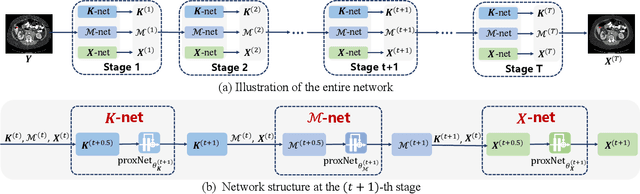

Inspired by the great success of deep neural networks, learning-based methods have gained promising performances for metal artifact reduction (MAR) in computed tomography (CT) images. However, most of the existing approaches put less emphasis on modelling and embedding the intrinsic prior knowledge underlying this specific MAR task into their network designs. Against this issue, we propose an adaptive convolutional dictionary network (ACDNet), which leverages both model-based and learning-based methods. Specifically, we explore the prior structures of metal artifacts, e.g., non-local repetitive streaking patterns, and encode them as an explicit weighted convolutional dictionary model. Then, a simple-yet-effective algorithm is carefully designed to solve the model. By unfolding every iterative substep of the proposed algorithm into a network module, we explicitly embed the prior structure into a deep network, \emph{i.e.,} a clear interpretability for the MAR task. Furthermore, our ACDNet can automatically learn the prior for artifact-free CT images via training data and adaptively adjust the representation kernels for each input CT image based on its content. Hence, our method inherits the clear interpretability of model-based methods and maintains the powerful representation ability of learning-based methods. Comprehensive experiments executed on synthetic and clinical datasets show the superiority of our ACDNet in terms of effectiveness and model generalization. {\color{blue}{{\textit{Code is available at {\url{https://github.com/hongwang01/ACDNet}}.}}}}
* https://github.com/hongwang01/ACDNet
Decoupled-and-Coupled Networks: Self-Supervised Hyperspectral Image Super-Resolution with Subpixel Fusion
May 07, 2022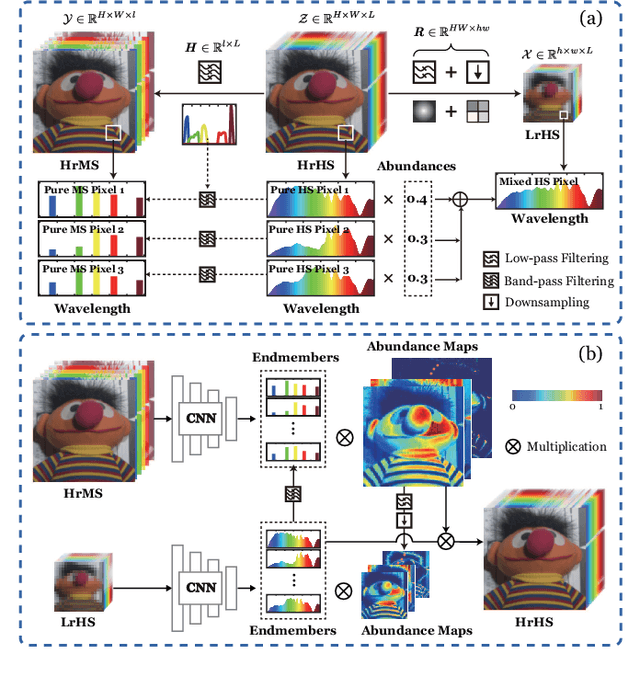
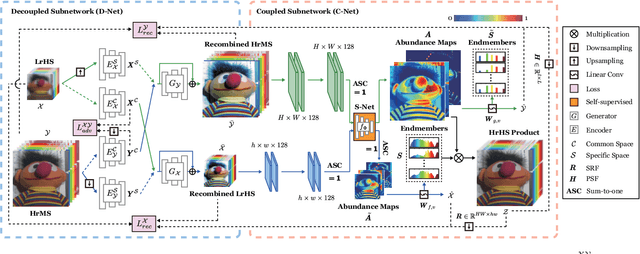
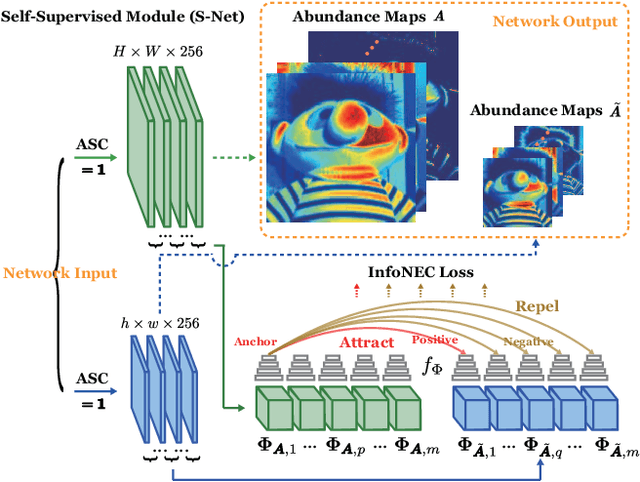
Enormous efforts have been recently made to super-resolve hyperspectral (HS) images with the aid of high spatial resolution multispectral (MS) images. Most prior works usually perform the fusion task by means of multifarious pixel-level priors. Yet the intrinsic effects of a large distribution gap between HS-MS data due to differences in the spatial and spectral resolution are less investigated. The gap might be caused by unknown sensor-specific properties or highly-mixed spectral information within one pixel (due to low spatial resolution). To this end, we propose a subpixel-level HS super-resolution framework by devising a novel decoupled-and-coupled network, called DC-Net, to progressively fuse HS-MS information from the pixel- to subpixel-level, from the image- to feature-level. As the name suggests, DC-Net first decouples the input into common (or cross-sensor) and sensor-specific components to eliminate the gap between HS-MS images before further fusion, and then fully blends them by a model-guided coupled spectral unmixing (CSU) net. More significantly, we append a self-supervised learning module behind the CSU net by guaranteeing the material consistency to enhance the detailed appearances of the restored HS product. Extensive experimental results show the superiority of our method both visually and quantitatively and achieve a significant improvement in comparison with the state-of-the-arts. Furthermore, the codes and datasets will be available at https://sites.google.com/view/danfeng-hong for the sake of reproducibility.
Two-Stream Graph Convolutional Network for Intra-oral Scanner Image Segmentation
Apr 19, 2022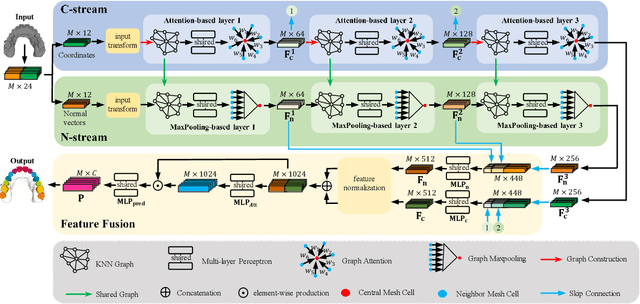
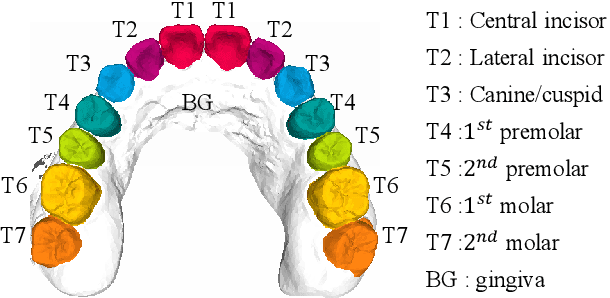
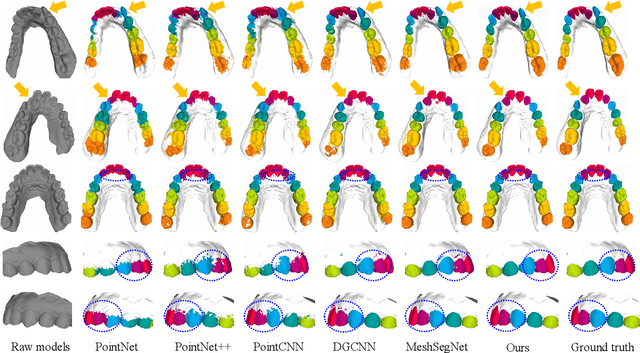
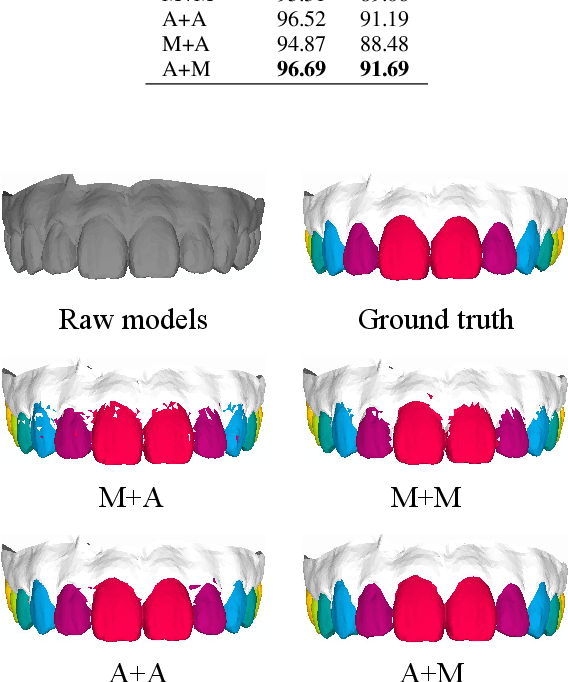
Precise segmentation of teeth from intra-oral scanner images is an essential task in computer-aided orthodontic surgical planning. The state-of-the-art deep learning-based methods often simply concatenate the raw geometric attributes (i.e., coordinates and normal vectors) of mesh cells to train a single-stream network for automatic intra-oral scanner image segmentation. However, since different raw attributes reveal completely different geometric information, the naive concatenation of different raw attributes at the (low-level) input stage may bring unnecessary confusion in describing and differentiating between mesh cells, thus hampering the learning of high-level geometric representations for the segmentation task. To address this issue, we design a two-stream graph convolutional network (i.e., TSGCN), which can effectively handle inter-view confusion between different raw attributes to more effectively fuse their complementary information and learn discriminative multi-view geometric representations. Specifically, our TSGCN adopts two input-specific graph-learning streams to extract complementary high-level geometric representations from coordinates and normal vectors, respectively. Then, these single-view representations are further fused by a self-attention module to adaptively balance the contributions of different views in learning more discriminative multi-view representations for accurate and fully automatic tooth segmentation. We have evaluated our TSGCN on a real-patient dataset of dental (mesh) models acquired by 3D intraoral scanners. Experimental results show that our TSGCN significantly outperforms state-of-the-art methods in 3D tooth (surface) segmentation. Github: https://github.com/ZhangLingMing1/TSGCNet.
* 11 pages, 6 figures. arXiv admin note: text overlap with arXiv:2012.13697
CMW-Net: Learning a Class-Aware Sample Weighting Mapping for Robust Deep Learning
Feb 22, 2022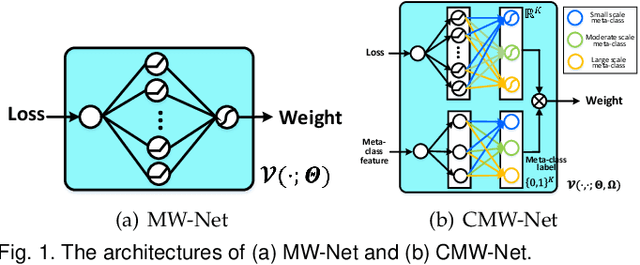
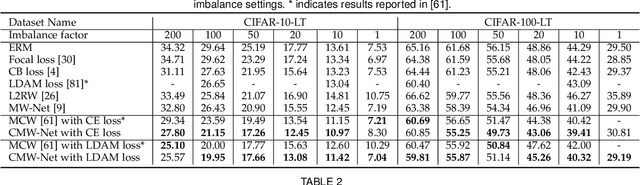
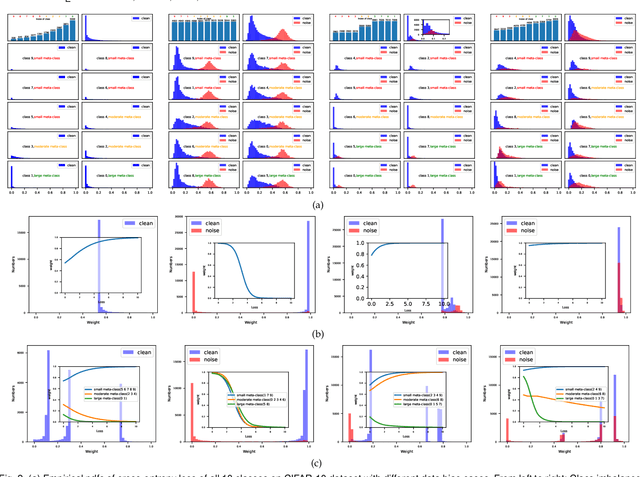
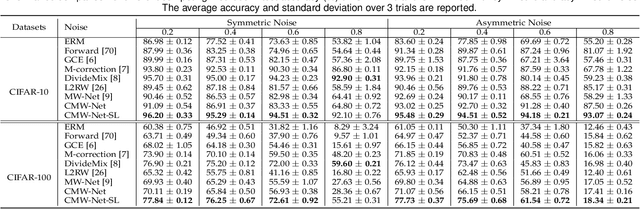
Modern deep neural networks can easily overfit to biased training data containing corrupted labels or class imbalance. Sample re-weighting methods are popularly used to alleviate this data bias issue. Most current methods, however, require to manually pre-specify the weighting schemes as well as their additional hyper-parameters relying on the characteristics of the investigated problem and training data. This makes them fairly hard to be generally applied in practical scenarios, due to their significant complexities and inter-class variations of data bias situations. To address this issue, we propose a meta-model capable of adaptively learning an explicit weighting scheme directly from data. Specifically, by seeing each training class as a separate learning task, our method aims to extract an explicit weighting function with sample loss and task/class feature as input, and sample weight as output, expecting to impose adaptively varying weighting schemes to different sample classes based on their own intrinsic bias characteristics. Synthetic and real data experiments substantiate the capability of our method on achieving proper weighting schemes in various data bias cases, like the class imbalance, feature-independent and dependent label noise scenarios, and more complicated bias scenarios beyond conventional cases. Besides, the task-transferability of the learned weighting scheme is also substantiated, by readily deploying the weighting function learned on relatively smaller-scale CIFAR-10 dataset on much larger-scale full WebVision dataset. A performance gain can be readily achieved compared with previous SOAT ones without additional hyper-parameter tuning and meta gradient descent step. The general availability of our method for multiple robust deep learning issues, including partial-label learning, semi-supervised learning and selective classification, has also been validated.
Diagnosing Batch Normalization in Class Incremental Learning
Feb 16, 2022
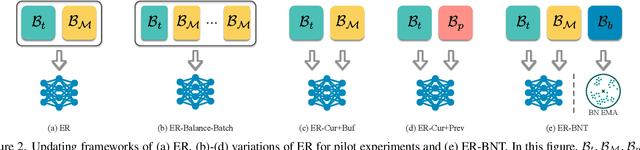
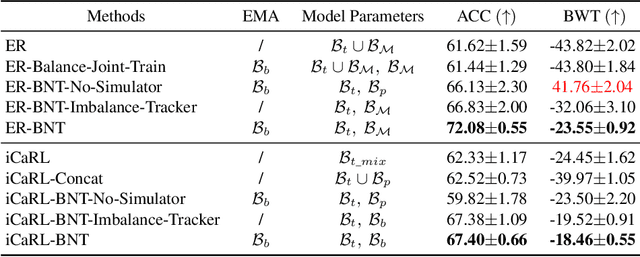
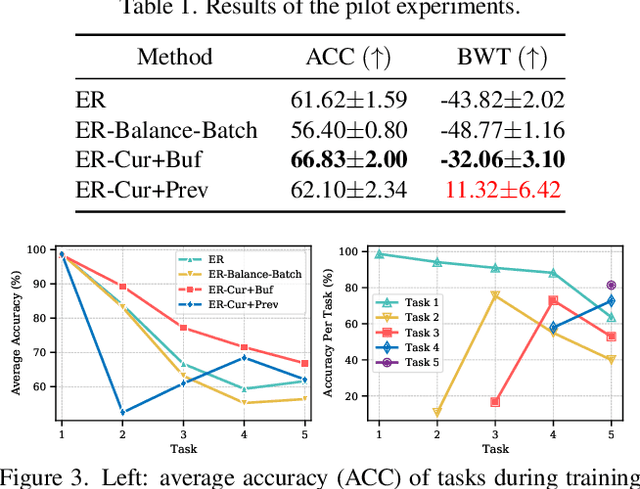
Extensive researches have applied deep neural networks (DNNs) in class incremental learning (Class-IL). As building blocks of DNNs, batch normalization (BN) standardizes intermediate feature maps and has been widely validated to improve training stability and convergence. However, we claim that the direct use of standard BN in Class-IL models is harmful to both the representation learning and the classifier training, thus exacerbating catastrophic forgetting. In this paper we investigate the influence of BN on Class-IL models by illustrating such BN dilemma. We further propose BN Tricks to address the issue by training a better feature extractor while eliminating classification bias. Without inviting extra hyperparameters, we apply BN Tricks to three baseline rehearsal-based methods, ER, DER++ and iCaRL. Through comprehensive experiments conducted on benchmark datasets of Seq-CIFAR-10, Seq-CIFAR-100 and Seq-Tiny-ImageNet, we show that BN Tricks can bring significant performance gains to all adopted baselines, revealing its potential generality along this line of research.
Low-light Image Enhancement by Retinex Based Algorithm Unrolling and Adjustment
Feb 15, 2022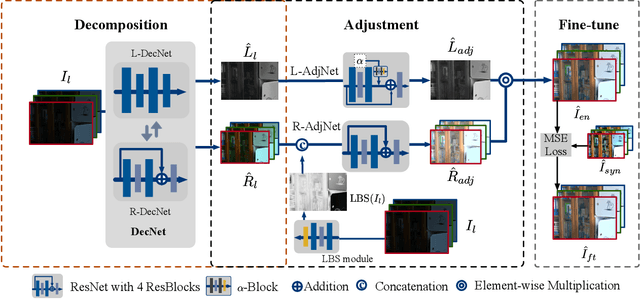

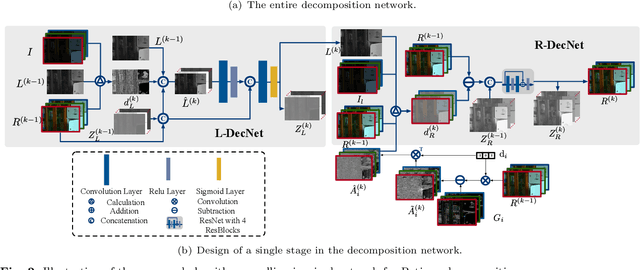
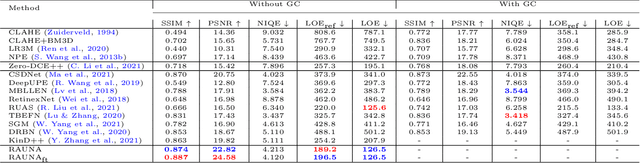
Motivated by their recent advances, deep learning techniques have been widely applied to low-light image enhancement (LIE) problem. Among which, Retinex theory based ones, mostly following a decomposition-adjustment pipeline, have taken an important place due to its physical interpretation and promising performance. However, current investigations on Retinex based deep learning are still not sufficient, ignoring many useful experiences from traditional methods. Besides, the adjustment step is either performed with simple image processing techniques, or by complicated networks, both of which are unsatisfactory in practice. To address these issues, we propose a new deep learning framework for the LIE problem. The proposed framework contains a decomposition network inspired by algorithm unrolling, and adjustment networks considering both global brightness and local brightness sensitivity. By virtue of algorithm unrolling, both implicit priors learned from data and explicit priors borrowed from traditional methods can be embedded in the network, facilitate to better decomposition. Meanwhile, the consideration of global and local brightness can guide designing simple yet effective network modules for adjustment. Besides, to avoid manually parameter tuning, we also propose a self-supervised fine-tuning strategy, which can always guarantee a promising performance. Experiments on a series of typical LIE datasets demonstrated the effectiveness of the proposed method, both quantitatively and visually, as compared with existing methods.