 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVERINA: Benchmarking Verifiable Code Generation
May 29, 2025Large language models (LLMs) are increasingly integrated in software development, but ensuring correctness in LLM-generated code remains challenging and often requires costly manual review. Verifiable code generation -- jointly generating code, specifications, and proofs of code-specification alignment -- offers a promising path to address this limitation and further unleash LLMs' benefits in coding. Yet, there exists a significant gap in evaluation: current benchmarks often lack support for end-to-end verifiable code generation. In this paper, we introduce Verina (Verifiable Code Generation Arena), a high-quality benchmark enabling a comprehensive and modular evaluation of code, specification, and proof generation as well as their compositions. Verina consists of 189 manually curated coding tasks in Lean, with detailed problem descriptions, reference implementations, formal specifications, and extensive test suites. Our extensive evaluation of state-of-the-art LLMs reveals significant challenges in verifiable code generation, especially in proof generation, underscoring the need for improving LLM-based theorem provers in verification domains. The best model, OpenAI o4-mini, generates only 61.4% correct code, 51.0% sound and complete specifications, and 3.6% successful proofs, with one trial per task. We hope Verina will catalyze progress in verifiable code generation by providing a rigorous and comprehensive benchmark. We release our dataset on https://huggingface.co/datasets/sunblaze-ucb/verina and our evaluation code on https://github.com/sunblaze-ucb/verina.
OVERT: A Benchmark for Over-Refusal Evaluation on Text-to-Image Models
May 28, 2025Text-to-Image (T2I) models have achieved remarkable success in generating visual content from text inputs. Although multiple safety alignment strategies have been proposed to prevent harmful outputs, they often lead to overly cautious behavior -- rejecting even benign prompts -- a phenomenon known as $\textit{over-refusal}$ that reduces the practical utility of T2I models. Despite over-refusal having been observed in practice, there is no large-scale benchmark that systematically evaluates this phenomenon for T2I models. In this paper, we present an automatic workflow to construct synthetic evaluation data, resulting in OVERT ($\textbf{OVE}$r-$\textbf{R}$efusal evaluation on $\textbf{T}$ext-to-image models), the first large-scale benchmark for assessing over-refusal behaviors in T2I models. OVERT includes 4,600 seemingly harmful but benign prompts across nine safety-related categories, along with 1,785 genuinely harmful prompts (OVERT-unsafe) to evaluate the safety-utility trade-off. Using OVERT, we evaluate several leading T2I models and find that over-refusal is a widespread issue across various categories (Figure 1), underscoring the need for further research to enhance the safety alignment of T2I models without compromising their functionality. As a preliminary attempt to reduce over-refusal, we explore prompt rewriting; however, we find it often compromises faithfulness to the meaning of the original prompts. Finally, we demonstrate the flexibility of our generation framework in accommodating diverse safety requirements by generating customized evaluation data adapting to user-defined policies.
Learning to Reason without External Rewards
May 26, 2025



Training large language models (LLMs) for complex reasoning via Reinforcement Learning with Verifiable Rewards (RLVR) is effective but limited by reliance on costly, domain-specific supervision. We explore Reinforcement Learning from Internal Feedback (RLIF), a framework that enables LLMs to learn from intrinsic signals without external rewards or labeled data. We propose Intuitor, an RLIF method that uses a model's own confidence, termed self-certainty, as its sole reward signal. Intuitor replaces external rewards in Group Relative Policy Optimization (GRPO) with self-certainty scores, enabling fully unsupervised learning. Experiments demonstrate that Intuitor matches GRPO's performance on mathematical benchmarks while achieving superior generalization to out-of-domain tasks like code generation, without requiring gold solutions or test cases. Our findings show that intrinsic model signals can drive effective learning across domains, offering a scalable alternative to RLVR for autonomous AI systems where verifiable rewards are unavailable. Code is available at https://github.com/sunblaze-ucb/Intuitor
A Critical Evaluation of Defenses against Prompt Injection Attacks
May 23, 2025Large Language Models (LLMs) are vulnerable to prompt injection attacks, and several defenses have recently been proposed, often claiming to mitigate these attacks successfully. However, we argue that existing studies lack a principled approach to evaluating these defenses. In this paper, we argue the need to assess defenses across two critical dimensions: (1) effectiveness, measured against both existing and adaptive prompt injection attacks involving diverse target and injected prompts, and (2) general-purpose utility, ensuring that the defense does not compromise the foundational capabilities of the LLM. Our critical evaluation reveals that prior studies have not followed such a comprehensive evaluation methodology. When assessed using this principled approach, we show that existing defenses are not as successful as previously reported. This work provides a foundation for evaluating future defenses and guiding their development. Our code and data are available at: https://github.com/PIEval123/PIEval.
SafeKey: Amplifying Aha-Moment Insights for Safety Reasoning
May 22, 2025



Large Reasoning Models (LRMs) introduce a new generation paradigm of explicitly reasoning before answering, leading to remarkable improvements in complex tasks. However, they pose great safety risks against harmful queries and adversarial attacks. While recent mainstream safety efforts on LRMs, supervised fine-tuning (SFT), improve safety performance, we find that SFT-aligned models struggle to generalize to unseen jailbreak prompts. After thorough investigation of LRMs' generation, we identify a safety aha moment that can activate safety reasoning and lead to a safe response. This aha moment typically appears in the `key sentence', which follows models' query understanding process and can indicate whether the model will proceed safely. Based on these insights, we propose SafeKey, including two complementary objectives to better activate the safety aha moment in the key sentence: (1) a Dual-Path Safety Head to enhance the safety signal in the model's internal representations before the key sentence, and (2) a Query-Mask Modeling objective to improve the models' attention on its query understanding, which has important safety hints. Experiments across multiple safety benchmarks demonstrate that our methods significantly improve safety generalization to a wide range of jailbreak attacks and out-of-distribution harmful prompts, lowering the average harmfulness rate by 9.6\%, while maintaining general abilities. Our analysis reveals how SafeKey enhances safety by reshaping internal attention and improving the quality of hidden representations.
In-Context Watermarks for Large Language Models
May 22, 2025



The growing use of large language models (LLMs) for sensitive applications has highlighted the need for effective watermarking techniques to ensure the provenance and accountability of AI-generated text. However, most existing watermarking methods require access to the decoding process, limiting their applicability in real-world settings. One illustrative example is the use of LLMs by dishonest reviewers in the context of academic peer review, where conference organizers have no access to the model used but still need to detect AI-generated reviews. Motivated by this gap, we introduce In-Context Watermarking (ICW), which embeds watermarks into generated text solely through prompt engineering, leveraging LLMs' in-context learning and instruction-following abilities. We investigate four ICW strategies at different levels of granularity, each paired with a tailored detection method. We further examine the Indirect Prompt Injection (IPI) setting as a specific case study, in which watermarking is covertly triggered by modifying input documents such as academic manuscripts. Our experiments validate the feasibility of ICW as a model-agnostic, practical watermarking approach. Moreover, our findings suggest that as LLMs become more capable, ICW offers a promising direction for scalable and accessible content attribution.
BountyBench: Dollar Impact of AI Agent Attackers and Defenders on Real-World Cybersecurity Systems
May 21, 2025AI agents have the potential to significantly alter the cybersecurity landscape. To help us understand this change, we introduce the first framework to capture offensive and defensive cyber-capabilities in evolving real-world systems. Instantiating this framework with BountyBench, we set up 25 systems with complex, real-world codebases. To capture the vulnerability lifecycle, we define three task types: Detect (detecting a new vulnerability), Exploit (exploiting a specific vulnerability), and Patch (patching a specific vulnerability). For Detect, we construct a new success indicator, which is general across vulnerability types and provides localized evaluation. We manually set up the environment for each system, including installing packages, setting up server(s), and hydrating database(s). We add 40 bug bounties, which are vulnerabilities with monetary awards from \$10 to \$30,485, and cover 9 of the OWASP Top 10 Risks. To modulate task difficulty, we devise a new strategy based on information to guide detection, interpolating from identifying a zero day to exploiting a specific vulnerability. We evaluate 5 agents: Claude Code, OpenAI Codex CLI, and custom agents with GPT-4.1, Gemini 2.5 Pro Preview, and Claude 3.7 Sonnet Thinking. Given up to three attempts, the top-performing agents are Claude Code (5% on Detect, mapping to \$1,350), Custom Agent with Claude 3.7 Sonnet Thinking (5% on Detect, mapping to \$1,025; 67.5% on Exploit), and OpenAI Codex CLI (5% on Detect, mapping to \$2,400; 90% on Patch, mapping to \$14,422). OpenAI Codex CLI and Claude Code are more capable at defense, achieving higher Patch scores of 90% and 87.5%, compared to Exploit scores of 32.5% and 57.5% respectively; in contrast, the custom agents are relatively balanced between offense and defense, achieving Exploit scores of 40-67.5% and Patch scores of 45-60%.
Probing the Vulnerability of Large Language Models to Polysemantic Interventions
May 16, 2025

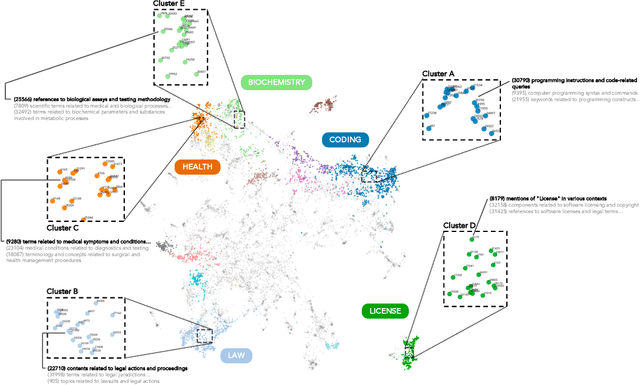

Polysemanticity -- where individual neurons encode multiple unrelated features -- is a well-known characteristic of large neural networks and remains a central challenge in the interpretability of language models. At the same time, its implications for model safety are also poorly understood. Leveraging recent advances in sparse autoencoders, we investigate the polysemantic structure of two small models (Pythia-70M and GPT-2-Small) and evaluate their vulnerability to targeted, covert interventions at the prompt, feature, token, and neuron levels. Our analysis reveals a consistent polysemantic topology shared across both models. Strikingly, we demonstrate that this structure can be exploited to mount effective interventions on two larger, black-box instruction-tuned models (LLaMA3.1-8B-Instruct and Gemma-2-9B-Instruct). These findings suggest not only the generalizability of the interventions but also point to a stable and transferable polysemantic structure that could potentially persist across architectures and training regimes.
AgentXploit: End-to-End Redteaming of Black-Box AI Agents
May 09, 2025



The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentXploit, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentXploit on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentXploit exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations
Apr 17, 2025Large language models (LLMs) frequently generate hallucinations-content that deviates from factual accuracy or provided context-posing challenges for diagnosis due to the complex interplay of underlying causes. This paper introduces a subsequence association framework to systematically trace and understand hallucinations. Our key insight is that hallucinations arise when dominant hallucinatory associations outweigh faithful ones. Through theoretical and empirical analyses, we demonstrate that decoder-only transformers effectively function as subsequence embedding models, with linear layers encoding input-output associations. We propose a tracing algorithm that identifies causal subsequences by analyzing hallucination probabilities across randomized input contexts. Experiments show our method outperforms standard attribution techniques in identifying hallucination causes and aligns with evidence from the model's training corpus. This work provides a unified perspective on hallucinations and a robust framework for their tracing and analysis.