 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel2Scene: Learning 3D Scene Representation via Contrastive Language-CAD Models Pre-training
Sep 29, 2023Current successful methods of 3D scene perception rely on the large-scale annotated point cloud, which is tedious and expensive to acquire. In this paper, we propose Model2Scene, a novel paradigm that learns free 3D scene representation from Computer-Aided Design (CAD) models and languages. The main challenges are the domain gaps between the CAD models and the real scene's objects, including model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object). To handle the above challenges, Model2Scene first simulates a crowded scene by mixing data-augmented CAD models. Next, we propose a novel feature regularization operation, termed Deep Convex-hull Regularization (DCR), to project point features into a unified convex hull space, reducing the domain gap. Ultimately, we impose contrastive loss on language embedding and the point features of CAD models to pre-train the 3D network. Extensive experiments verify the learned 3D scene representation is beneficial for various downstream tasks, including label-free 3D object salient detection, label-efficient 3D scene perception and zero-shot 3D semantic segmentation. Notably, Model2Scene yields impressive label-free 3D object salient detection with an average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets, respectively. The code will be publicly available.
Learning to Control and Coordinate Hybrid Traffic Through Robot Vehicles at Complex and Unsignalized Intersections
Jan 12, 2023Intersections are essential road infrastructures for traffic in modern metropolises; however, they can also be the bottleneck of traffic flows due to traffic incidents or the absence of traffic coordination mechanisms such as traffic lights. Thus, various control and coordination mechanisms that are beyond traditional control methods have been proposed to improve the efficiency of intersection traffic. Amongst these methods, the control of foreseeable hybrid traffic that consists of human-driven vehicles (HVs) and robot vehicles (RVs) has recently emerged. We propose a decentralized reinforcement learning approach for the control and coordination of hybrid traffic at real-world, complex intersections--a topic that has not been previously explored. Comprehensive experiments are conducted to show the effectiveness of our approach. In particular, we show that using 5% RVs, we can prevent congestion formation inside the intersection under the actual traffic demand of 700 vehicles per hour. In contrast, without RVs, congestion starts to develop when the traffic demand reaches as low as 200 vehicles per hour. Further performance gains (reduced waiting time of vehicles at the intersection) are obtained as the RV penetration rate increases. When there exist more than 50% RVs in traffic, our method starts to outperform traffic signals on the average waiting time of all vehicles at the intersection. Our method is also robust against both blackout events and sudden RV percentage drops, and enjoys excellent generalizablility, which is illustrated by its successful deployment in two unseen intersections.
Deep Anomaly Detection and Search via Reinforcement Learning
Aug 31, 2022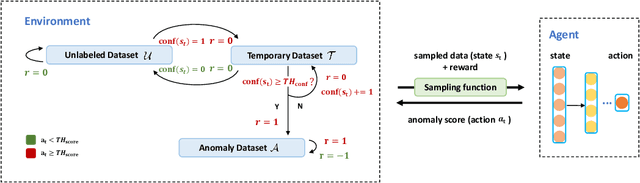
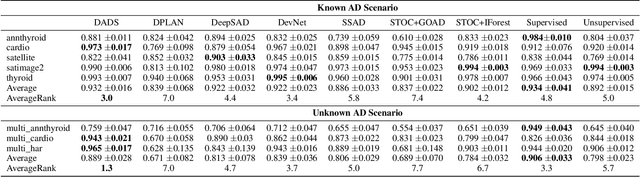
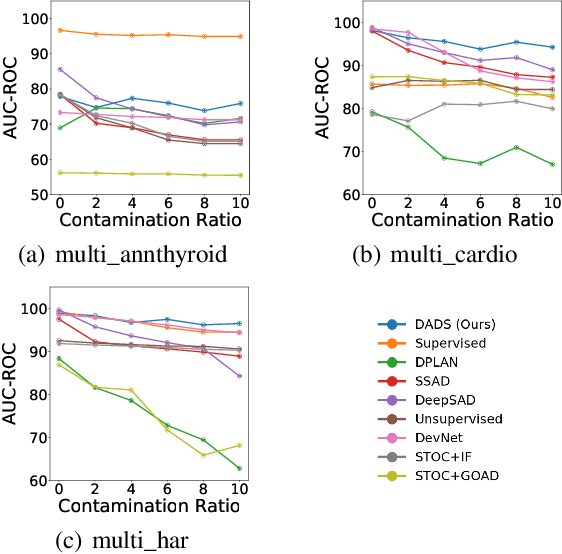
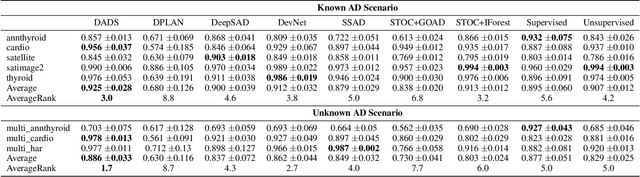
Semi-supervised Anomaly Detection (AD) is a kind of data mining task which aims at learning features from partially-labeled datasets to help detect outliers. In this paper, we classify existing semi-supervised AD methods into two categories: unsupervised-based and supervised-based, and point out that most of them suffer from insufficient exploitation of labeled data and under-exploration of unlabeled data. To tackle these problems, we propose Deep Anomaly Detection and Search (DADS), which applies Reinforcement Learning (RL) to balance exploitation and exploration. During the training process, the agent searches for possible anomalies with hierarchically-structured datasets and uses the searched anomalies to enhance performance, which in essence draws lessons from the idea of ensemble learning. Experimentally, we compare DADS with several state-of-the-art methods in the settings of leveraging labeled known anomalies to detect both other known anomalies and unknown anomalies. Results show that DADS can efficiently and precisely search anomalies from unlabeled data and learn from them, thus achieving good performance.
CD and PMD Effect on Cyclostationarity-Based Timing Recovery for Optical Coherent Receivers
Aug 30, 2022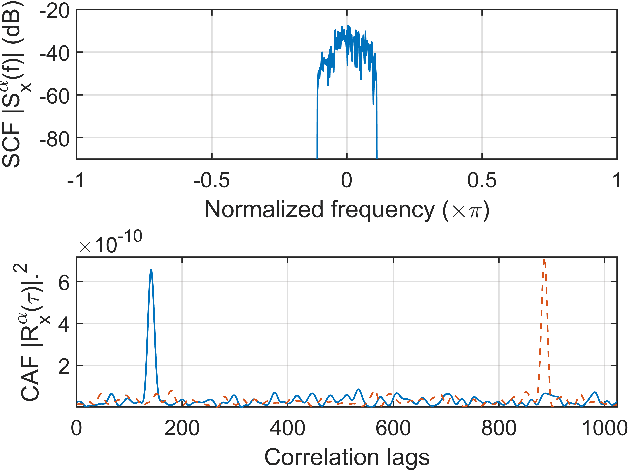

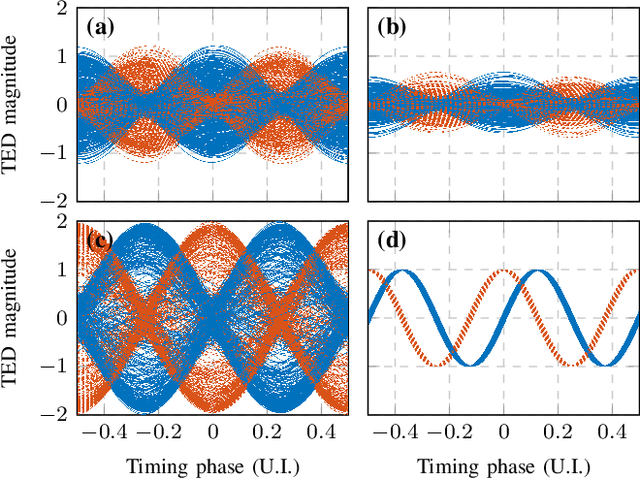
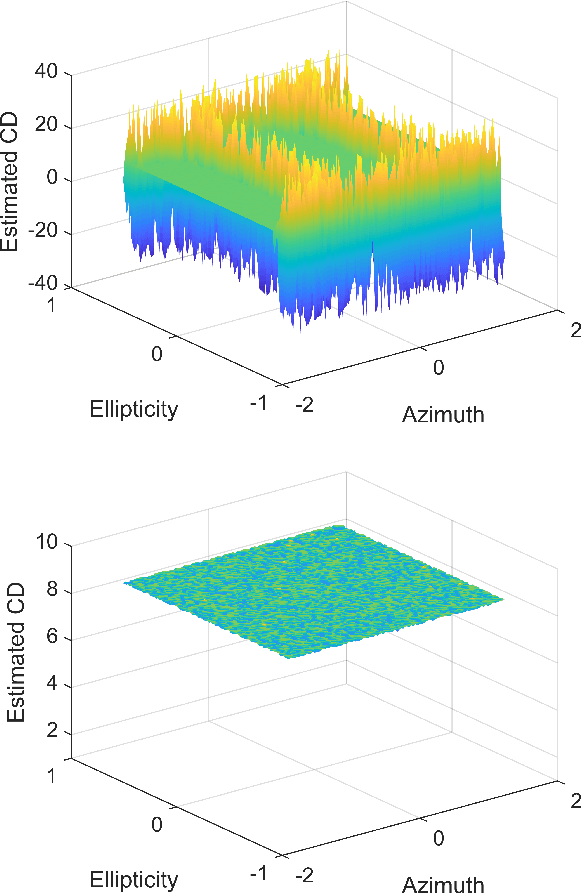
Timing recovery is critical for synchronizing the clocks at the transmitting and receiving ends of a digital coherent communication system. The core of timing recovery is to determine reliably the current sampling error of the local digitizer so that the timing circuit may lock to a stable operation point. Conventional timing phase detectors need to adapt to the optical fiber channel so that the common effects of this channel, such as chromatic dispersion (CD) and polarization mode dispersion (PMD), on the timing phase extraction must be understood. Here we exploit the cyclostationarity of the optical signal and derive a model for studying the CD and PMD effect. We prove that the CD-adjusted cyclic correlation matrix contains full information about timing and PMD, and the determinant of the matrix is a timing phase detector immune to both CD and PMD. We also obtain other results such as a completely PMD-independent CD estimator, etc. Our analysis is supported by both simulations and experiments over a field implemented optical cable.
Jacobian Methods for Dynamic Polarization Control in Optical Applications
Aug 29, 2022
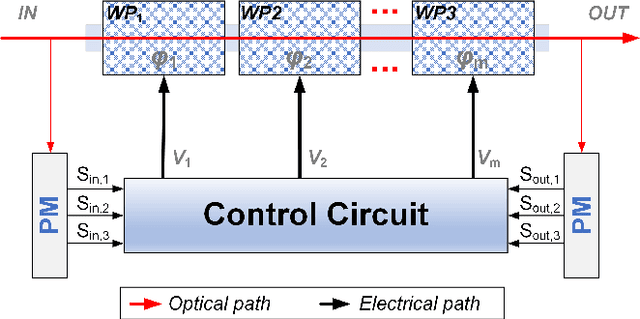
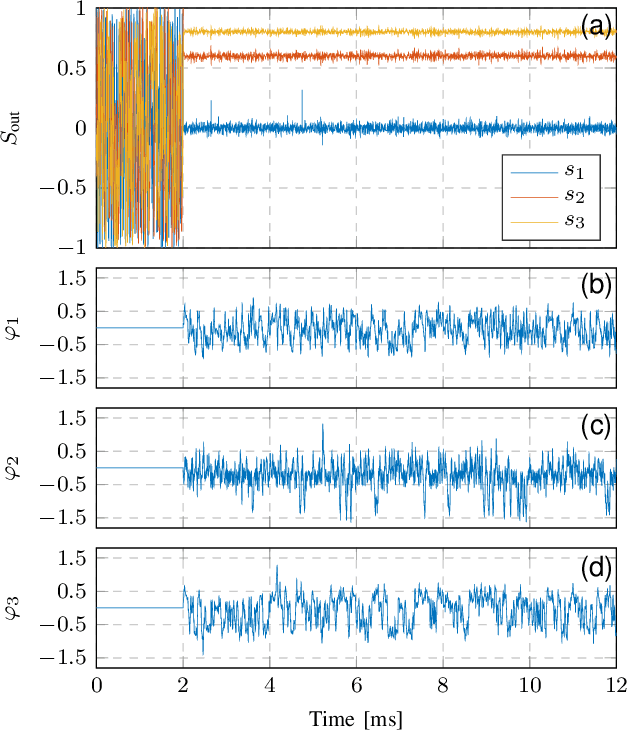
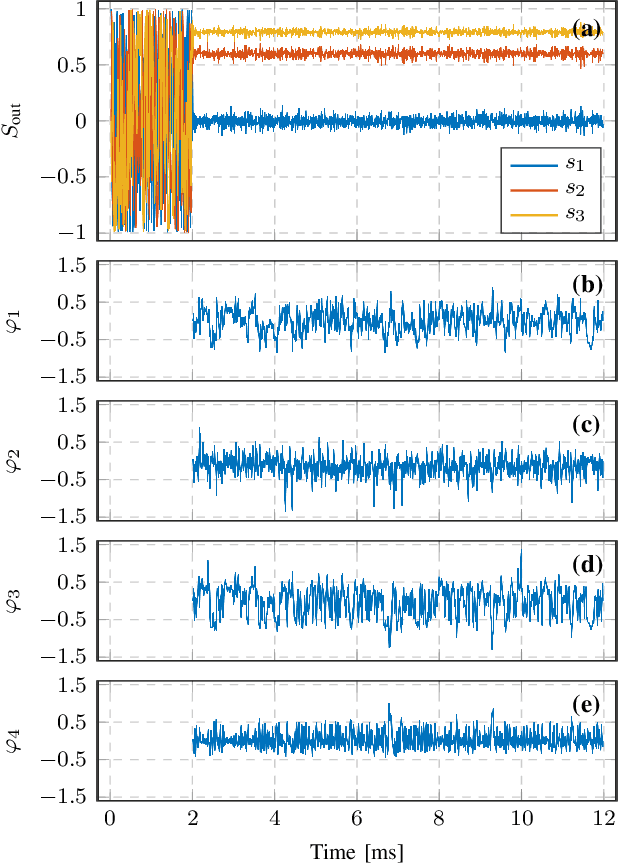
Dynamic polarization control (DPC) is beneficial for many optical applications. It uses adjustable waveplates to perform automatic polarization tracking and manipulation. Efficient algorithms are essential to realizing an endless polarization control process at high speed. However, the standard gradientbased algorithm is not well analyzed. Here we model the DPC with a Jacobian-based control theory framework that finds a lot in common with robot kinematics. We then give a detailed analysis of the condition of the Stokes vector gradient as a Jacobian matrix. We identify the multi-stage DPC as a redundant system enabling control algorithms with null-space operations. An efficient, reset-free algorithm can be found. We anticipate more customized DPC algorithms to follow the same framework in various optical systems.
A Concept and Argumentation based Interpretable Model in High Risk Domains
Aug 17, 2022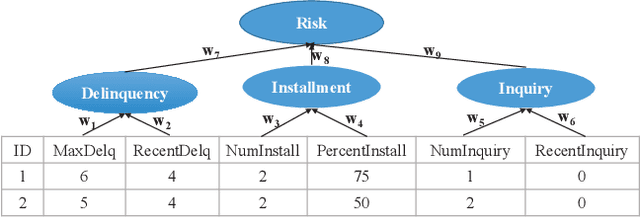

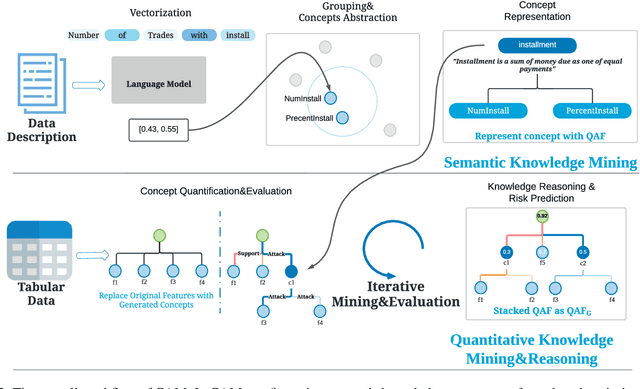
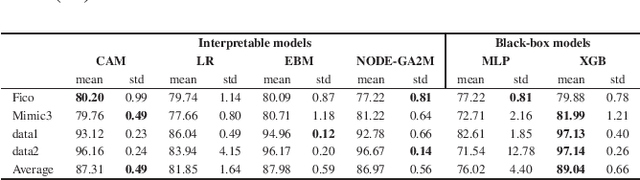
Interpretability has become an essential topic for artificial intelligence in some high-risk domains such as healthcare, bank and security. For commonly-used tabular data, traditional methods trained end-to-end machine learning models with numerical and categorical data only, and did not leverage human understandable knowledge such as data descriptions. Yet mining human-level knowledge from tabular data and using it for prediction remain a challenge. Therefore, we propose a concept and argumentation based model (CAM) that includes the following two components: a novel concept mining method to obtain human understandable concepts and their relations from both descriptions of features and the underlying data, and a quantitative argumentation-based method to do knowledge representation and reasoning. As a result of it, CAM provides decisions that are based on human-level knowledge and the reasoning process is intrinsically interpretable. Finally, to visualize the purposed interpretable model, we provide a dialogical explanation that contain dominated reasoning path within CAM. Experimental results on both open source benchmark dataset and real-word business dataset show that (1) CAM is transparent and interpretable, and the knowledge inside the CAM is coherent with human understanding; (2) Our interpretable approach can reach competitive results comparing with other state-of-art models.
Towards 3D Scene Understanding by Referring Synthetic Models
Mar 20, 2022
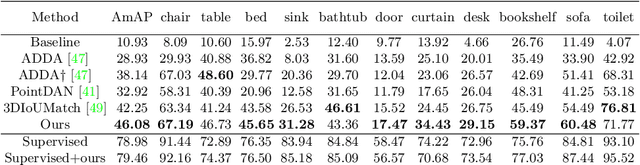
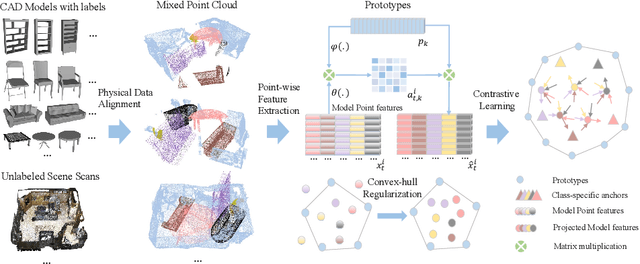
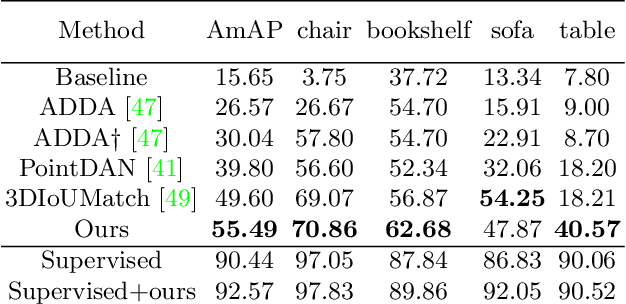
Promising performance has been achieved for visual perception on the point cloud. However, the current methods typically rely on labour-extensive annotations on the scene scans. In this paper, we explore how synthetic models alleviate the real scene annotation burden, i.e., taking the labelled 3D synthetic models as reference for supervision, the neural network aims to recognize specific categories of objects on a real scene scan (without scene annotation for supervision). The problem studies how to transfer knowledge from synthetic 3D models to real 3D scenes and is named Referring Transfer Learning (RTL). The main challenge is solving the model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object) gap between the synthetic model and the real scene. To this end, we propose a simple yet effective framework to perform two alignment operations. First, physical data alignment aims to make the synthetic models cover the diversity of the scene's objects with data processing techniques. Then a novel \textbf{convex-hull regularized feature alignment} introduces learnable prototypes to project the point features of both synthetic models and real scenes to a unified feature space, which alleviates the domain gap. These operations ease the model-to-scene and synthetic-to-real difficulty for a network to recognize the target objects on a real unseen scene. Experiments show that our method achieves the average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets by learning the synthetic models from the ModelNet dataset. Code will be publicly available.
An Intelligent Self-driving Truck System For Highway Transportation
Dec 31, 2021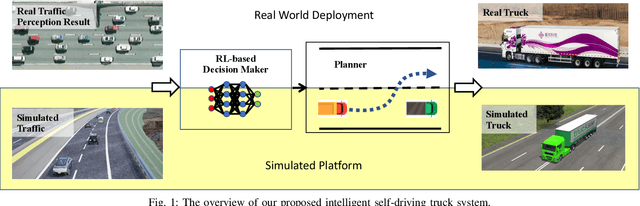
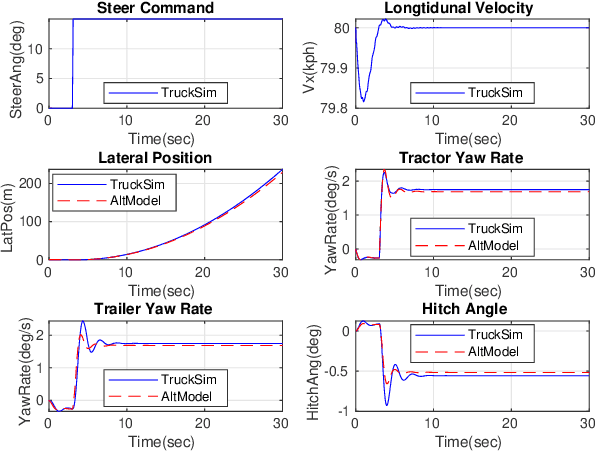
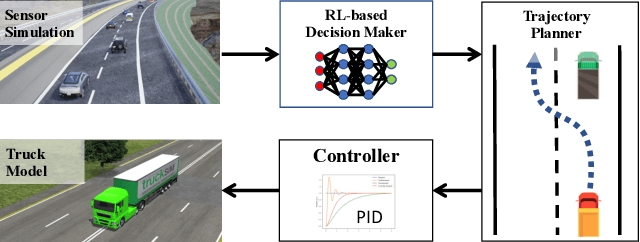
Recently, there have been many advances in autonomous driving society, attracting a lot of attention from academia and industry. However, existing works mainly focus on cars, extra development is still required for self-driving truck algorithms and models. In this paper, we introduce an intelligent self-driving truck system. Our presented system consists of three main components, 1) a realistic traffic simulation module for generating realistic traffic flow in testing scenarios, 2) a high-fidelity truck model which is designed and evaluated for mimicking real truck response in real-world deployment, 3) an intelligent planning module with learning-based decision making algorithm and multi-mode trajectory planner, taking into account the truck's constraints, road slope changes, and the surrounding traffic flow. We provide quantitative evaluations for each component individually to demonstrate the fidelity and performance of each part. We also deploy our proposed system on a real truck and conduct real world experiments which shows our system's capacity of mitigating sim-to-real gap. Our code is available at https://github.com/InceptioResearch/IITS
Multi-Rate Nyquist-SCM for C-Band 100Gbit/s Signal over 50km Dispersion-Uncompensated Link
Jul 25, 2021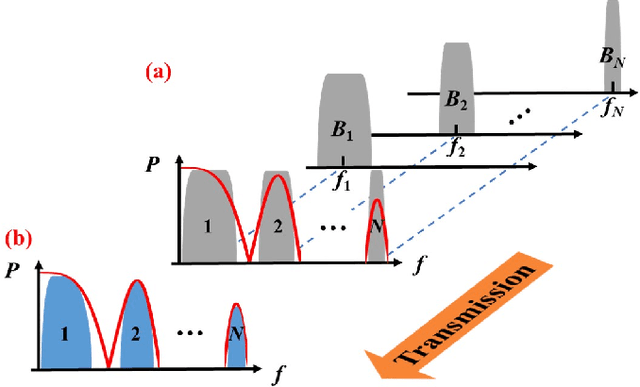

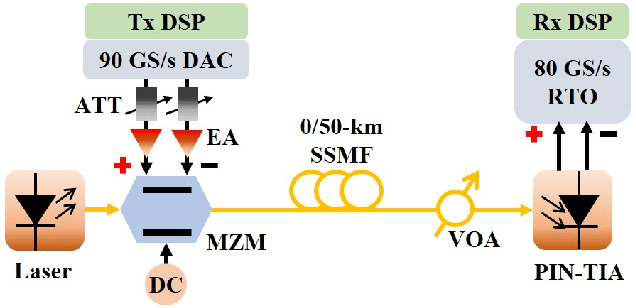
In this paper, to the best of our knowledge, we propose the first multi-rate Nyquist-subcarriers modulation (SCM) for C-band 100Gbit/s signal transmission over 50km dispersion-uncompensated link. Chromatic dispersion (CD) introduces severe spectral nulls on optical double-sideband signal, which greatly degrades the performance of intensity-modulation and direct-detection systems. In the previous works, high-complexity digital signal processing (DSP) is required to resist the CD-caused spectral nulls. Based on the characteristics of dispersive channel, Nyquist-SCM with multi-rate subcarriers is proposed to keep away from the CD-caused spectral nulls flexibly. Signal on each subcarrier can be individually recovered by a DSP with an acceptable complexity, including the feed-forward equalizer with no more than 31 taps, a two-tap post filter, and maximum likelihood sequence estimation with one memory length. Combining with entropy loading based on probabilistic constellation shaping to maximize the capacity-reach, the C-band 100Gbit/s multi-rate Nyquist-SCM signal over 50km dispersion-uncompensated link can achieve 7% hard-decision forward error correction limit and average normalized generalized mutual information of 0.967. In conclusion, the multi-rate Nyquist-SCM shows great potentials in solving the CD-caused spectral distortions.
Pixel Codec Avatars
Apr 09, 2021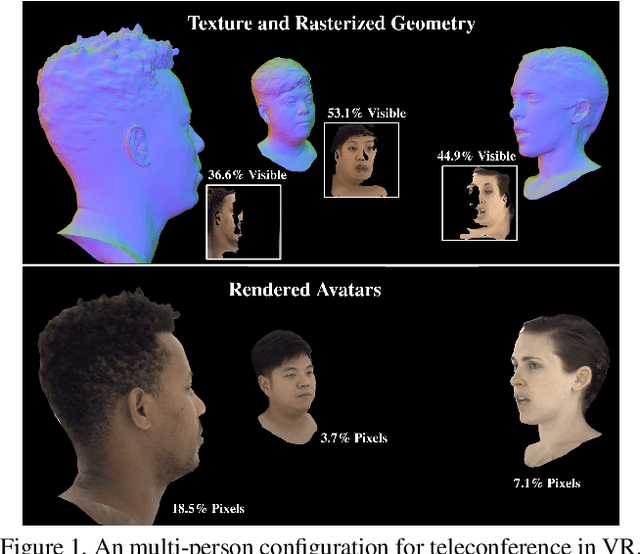
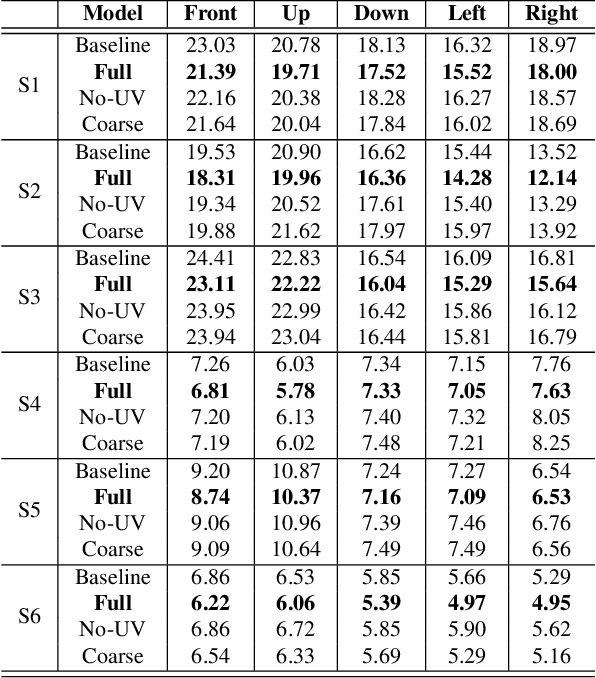
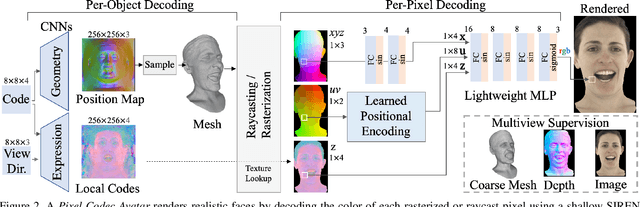
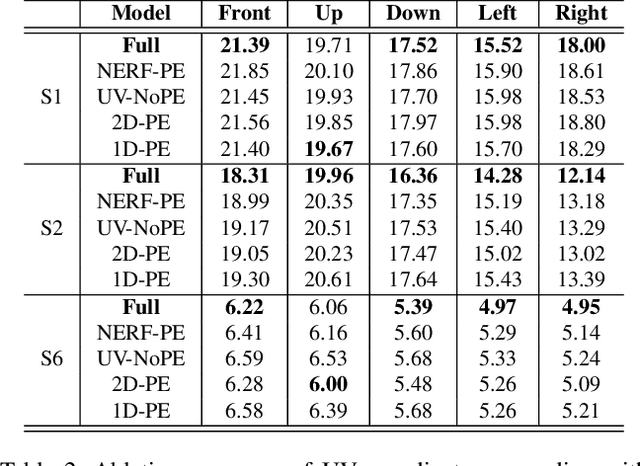
Telecommunication with photorealistic avatars in virtual or augmented reality is a promising path for achieving authentic face-to-face communication in 3D over remote physical distances. In this work, we present the Pixel Codec Avatars (PiCA): a deep generative model of 3D human faces that achieves state of the art reconstruction performance while being computationally efficient and adaptive to the rendering conditions during execution. Our model combines two core ideas: (1) a fully convolutional architecture for decoding spatially varying features, and (2) a rendering-adaptive per-pixel decoder. Both techniques are integrated via a dense surface representation that is learned in a weakly-supervised manner from low-topology mesh tracking over training images. We demonstrate that PiCA improves reconstruction over existing techniques across testing expressions and views on persons of different gender and skin tone. Importantly, we show that the PiCA model is much smaller than the state-of-art baseline model, and makes multi-person telecommunicaiton possible: on a single Oculus Quest 2 mobile VR headset, 5 avatars are rendered in realtime in the same scene.