 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents
May 16, 2025Detecting vulnerabilities in source code remains a critical yet challenging task, especially when benign and vulnerable functions share significant similarities. In this work, we introduce VulTrial, a courtroom-inspired multi-agent framework designed to enhance automated vulnerability detection. It employs four role-specific agents, which are security researcher, code author, moderator, and review board. Through extensive experiments using GPT-3.5 and GPT-4o we demonstrate that Vultrial outperforms single-agent and multi-agent baselines. Using GPT-4o, VulTrial improves the performance by 102.39% and 84.17% over its respective baseline. Additionally, we show that role-specific instruction tuning in multi-agent with small data (50 pair samples) improves the performance of VulTrial further by 139.89% and 118.30%. Furthermore, we analyze the impact of increasing the number of agent interactions on VulTrial's overall performance. While multi-agent setups inherently incur higher costs due to increased token usage, our findings reveal that applying VulTrial to a cost-effective model like GPT-3.5 can improve its performance by 69.89% compared to GPT-4o in a single-agent setting, at a lower overall cost.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025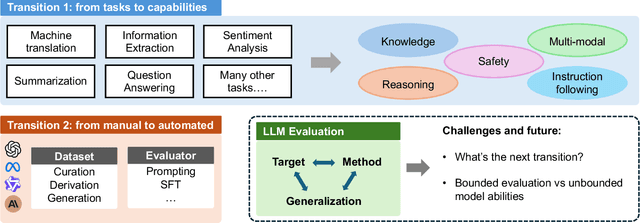
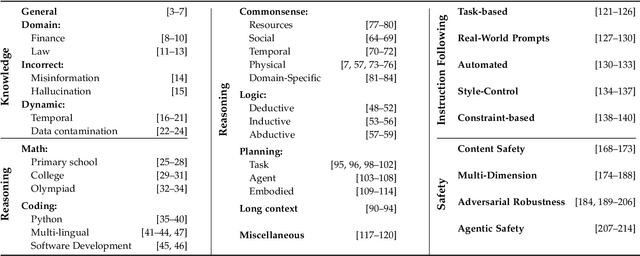
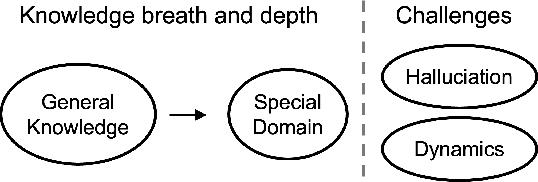
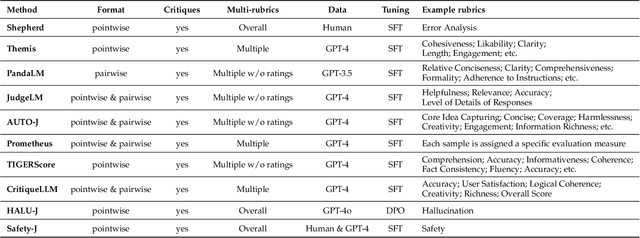
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Zero-Shot Cross-Domain Code Search without Fine-Tuning
Apr 10, 2025



Code search aims to retrieve semantically relevant code snippets for natural language queries. While pre-trained language models (PLMs) have shown remarkable performance in this task, they struggle in cross-domain scenarios, often requiring costly fine-tuning or facing performance drops in zero-shot settings. RAPID, which generates synthetic data for model fine-tuning, is currently the only effective method for zero-shot cross-domain code search. Despite its effectiveness, RAPID demands substantial computational resources for fine-tuning and needs to maintain specialized models for each domain, underscoring the need for a zero-shot, fine-tuning-free approach for cross-domain code search. The key to tackling zero-shot cross-domain code search lies in bridging the gaps among domains. In this work, we propose to break the query-code matching process of code search into two simpler tasks: query-comment matching and code-code matching. Our empirical study reveals the strong complementarity among the three matching schemas in zero-shot cross-domain settings, i.e., query-code, query-comment, and code-code matching. Based on the findings, we propose CodeBridge, a zero-shot, fine-tuning-free approach for cross-domain code search. Specifically, CodeBridge uses Large Language Models (LLMs) to generate comments and pseudo-code, then combines query-code, query-comment, and code-code matching via PLM-based similarity scoring and sampling-based fusion. Experimental results show that our approach outperforms the state-of-the-art PLM-based code search approaches, i.e., CoCoSoDa and UniXcoder, by an average of 21.4% and 24.9% in MRR, respectively, across three datasets. Our approach also yields results that are better than or comparable to those of the zero-shot cross-domain code search approach RAPID, which requires costly fine-tuning.
R2Vul: Learning to Reason about Software Vulnerabilities with Reinforcement Learning and Structured Reasoning Distillation
Apr 07, 2025



Large language models (LLMs) have shown promising performance in software vulnerability detection (SVD), yet their reasoning capabilities remain unreliable. Existing approaches relying on chain-of-thought (CoT) struggle to provide relevant and actionable security assessments. Additionally, effective SVD requires not only generating coherent reasoning but also differentiating between well-founded and misleading yet plausible security assessments, an aspect overlooked in prior work. To this end, we introduce R2Vul, a novel approach that distills structured reasoning into small LLMs using reinforcement learning from AI feedback (RLAIF). Through RLAIF, R2Vul enables LLMs to produce structured, security-aware reasoning that is actionable and reliable while explicitly learning to distinguish valid assessments from misleading ones. We evaluate R2Vul across five languages against SAST tools, CoT, instruction tuning, and classification-based baselines. Our results show that R2Vul with structured reasoning distillation enables a 1.5B student LLM to rival larger models while improving generalization to out-of-distribution vulnerabilities. Beyond model improvements, we contribute a large-scale, multilingual preference dataset featuring structured reasoning to support future research in SVD.
Towards Secure Program Partitioning for Smart Contracts with LLM's In-Context Learning
Feb 20, 2025



Smart contracts are highly susceptible to manipulation attacks due to the leakage of sensitive information. Addressing manipulation vulnerabilities is particularly challenging because they stem from inherent data confidentiality issues rather than straightforward implementation bugs. To tackle this by preventing sensitive information leakage, we present PartitionGPT, the first LLM-driven approach that combines static analysis with the in-context learning capabilities of large language models (LLMs) to partition smart contracts into privileged and normal codebases, guided by a few annotated sensitive data variables. We evaluated PartitionGPT on 18 annotated smart contracts containing 99 sensitive functions. The results demonstrate that PartitionGPT successfully generates compilable, and verified partitions for 78% of the sensitive functions while reducing approximately 30% code compared to function-level partitioning approach. Furthermore, we evaluated PartitionGPT on nine real-world manipulation attacks that lead to a total loss of 25 million dollars, PartitionGPT effectively prevents eight cases, highlighting its potential for broad applicability and the necessity for secure program partitioning during smart contract development to diminish manipulation vulnerabilities.
Less is More: On the Importance of Data Quality for Unit Test Generation
Feb 20, 2025Unit testing is crucial for software development and maintenance. Effective unit testing ensures and improves software quality, but writing unit tests is time-consuming and labor-intensive. Recent studies have proposed deep learning (DL) techniques or large language models (LLMs) to automate unit test generation. These models are usually trained or fine-tuned on large-scale datasets. Despite growing awareness of the importance of data quality, there has been limited research on the quality of datasets used for test generation. To bridge this gap, we systematically examine the impact of noise on the performance of learning-based test generation models. We first apply the open card sorting method to analyze the most popular and largest test generation dataset, Methods2Test, to categorize eight distinct types of noise. Further, we conduct detailed interviews with 17 domain experts to validate and assess the importance, reasonableness, and correctness of the noise taxonomy. Then, we propose CleanTest, an automated noise-cleaning framework designed to improve the quality of test generation datasets. CleanTest comprises three filters: a rule-based syntax filter, a rule-based relevance filter, and a model-based coverage filter. To evaluate its effectiveness, we apply CleanTest on two widely-used test generation datasets, i.e., Methods2Test and Atlas. Our findings indicate that 43.52% and 29.65% of datasets contain noise, highlighting its prevalence. Finally, we conduct comparative experiments using four LLMs (i.e., CodeBERT, AthenaTest, StarCoder, and CodeLlama7B) to assess the impact of noise on test generation performance. The results show that filtering noise positively influences the test generation ability of the models.
LessLeak-Bench: A First Investigation of Data Leakage in LLMs Across 83 Software Engineering Benchmarks
Feb 10, 2025Large Language Models (LLMs) are widely utilized in software engineering (SE) tasks, such as code generation and automated program repair. However, their reliance on extensive and often undisclosed pre-training datasets raises significant concerns about data leakage, where the evaluation benchmark data is unintentionally ``seen'' by LLMs during the model's construction phase. The data leakage issue could largely undermine the validity of LLM-based research and evaluations. Despite the increasing use of LLMs in the SE community, there is no comprehensive study that assesses the extent of data leakage in SE benchmarks for LLMs yet. To address this gap, this paper presents the first large-scale analysis of data leakage in 83 SE benchmarks concerning LLMs. Our results show that in general, data leakage in SE benchmarks is minimal, with average leakage ratios of only 4.8\%, 2.8\%, and 0.7\% for Python, Java, and C/C++ benchmarks, respectively. However, some benchmarks exhibit relatively higher leakage ratios, which raises concerns about their bias in evaluation. For instance, QuixBugs and BigCloneBench have leakage ratios of 100.0\% and 55.7\%, respectively. Furthermore, we observe that data leakage has a substantial impact on LLM evaluation. We also identify key causes of high data leakage, such as the direct inclusion of benchmark data in pre-training datasets and the use of coding platforms like LeetCode for benchmark construction. To address the data leakage, we introduce \textbf{LessLeak-Bench}, a new benchmark that removes leaked samples from the 83 SE benchmarks, enabling more reliable LLM evaluations in future research. Our study enhances the understanding of data leakage in SE benchmarks and provides valuable insights for future research involving LLMs in SE.
Do Existing Testing Tools Really Uncover Gender Bias in Text-to-Image Models?
Jan 27, 2025



Text-to-Image (T2I) models have recently gained significant attention due to their ability to generate high-quality images and are consequently used in a wide range of applications. However, there are concerns about the gender bias of these models. Previous studies have shown that T2I models can perpetuate or even amplify gender stereotypes when provided with neutral text prompts. Researchers have proposed automated gender bias uncovering detectors for T2I models, but a crucial gap exists: no existing work comprehensively compares the various detectors and understands how the gender bias detected by them deviates from the actual situation. This study addresses this gap by validating previous gender bias detectors using a manually labeled dataset and comparing how the bias identified by various detectors deviates from the actual bias in T2I models, as verified by manual confirmation. We create a dataset consisting of 6,000 images generated from three cutting-edge T2I models: Stable Diffusion XL, Stable Diffusion 3, and Dreamlike Photoreal 2.0. During the human-labeling process, we find that all three T2I models generate a portion (12.48% on average) of low-quality images (e.g., generate images with no face present), where human annotators cannot determine the gender of the person. Our analysis reveals that all three T2I models show a preference for generating male images, with SDXL being the most biased. Additionally, images generated using prompts containing professional descriptions (e.g., lawyer or doctor) show the most bias. We evaluate seven gender bias detectors and find that none fully capture the actual level of bias in T2I models, with some detectors overestimating bias by up to 26.95%. We further investigate the causes of inaccurate estimations, highlighting the limitations of detectors in dealing with low-quality images. Based on our findings, we propose an enhanced detector...
TACLR: A Scalable and Efficient Retrieval-based Method for Industrial Product Attribute Value Identification
Jan 07, 2025Product Attribute Value Identification (PAVI) involves identifying attribute values from product profiles, a key task for improving product search, recommendations, and business analytics on e-commerce platforms. However, existing PAVI methods face critical challenges, such as inferring implicit values, handling out-of-distribution (OOD) values, and producing normalized outputs. To address these limitations, we introduce Taxonomy-Aware Contrastive Learning Retrieval (TACLR), the first retrieval-based method for PAVI. TACLR formulates PAVI as an information retrieval task by encoding product profiles and candidate values into embeddings and retrieving values based on their similarity to the item embedding. It leverages contrastive training with taxonomy-aware hard negative sampling and employs adaptive inference with dynamic thresholds. TACLR offers three key advantages: (1) it effectively handles implicit and OOD values while producing normalized outputs; (2) it scales to thousands of categories, tens of thousands of attributes, and millions of values; and (3) it supports efficient inference for high-load industrial scenarios. Extensive experiments on proprietary and public datasets validate the effectiveness and efficiency of TACLR. Moreover, it has been successfully deployed in a real-world e-commerce platform, processing millions of product listings daily while supporting dynamic, large-scale attribute taxonomies.
How do Machine Learning Models Change?
Nov 14, 2024



The proliferation of Machine Learning (ML) models and their open-source implementations has transformed Artificial Intelligence research and applications. Platforms like Hugging Face (HF) enable the development, sharing, and deployment of these models, fostering an evolving ecosystem. While previous studies have examined aspects of models hosted on platforms like HF, a comprehensive longitudinal study of how these models change remains underexplored. This study addresses this gap by utilizing both repository mining and longitudinal analysis methods to examine over 200,000 commits and 1,200 releases from over 50,000 models on HF. We replicate and extend an ML change taxonomy for classifying commits and utilize Bayesian networks to uncover patterns in commit and release activities over time. Our findings indicate that commit activities align with established data science methodologies, such as CRISP-DM, emphasizing iterative refinement and continuous improvement. Additionally, release patterns tend to consolidate significant updates, particularly in documentation, distinguishing between granular changes and milestone-based releases. Furthermore, projects with higher popularity prioritize infrastructure enhancements early in their lifecycle, and those with intensive collaboration practices exhibit improved documentation standards. These and other insights enhance the understanding of model changes on community platforms and provide valuable guidance for best practices in model maintenance.