 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Linear Networks
Sep 30, 2019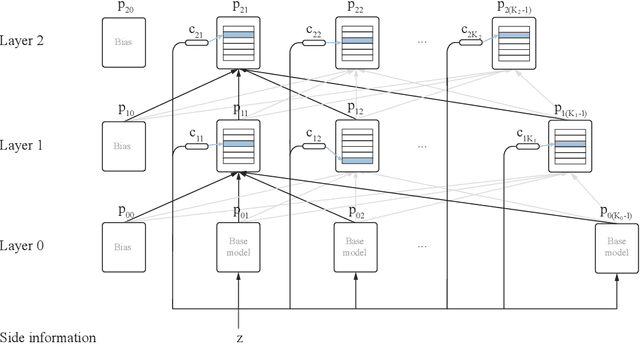
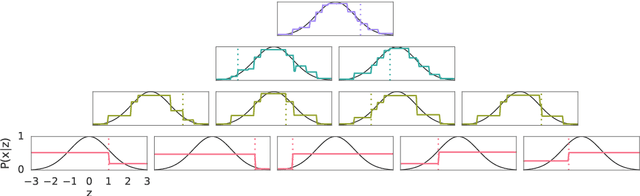
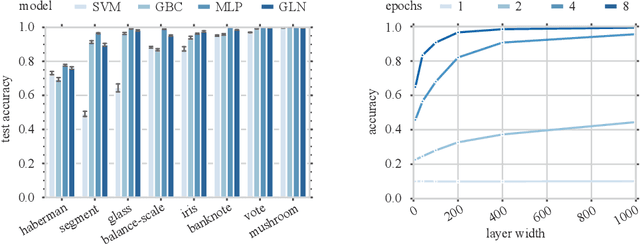
This paper presents a family of backpropagation-free neural architectures, Gated Linear Networks (GLNs),that are well suited to online learning applications where sample efficiency is of paramount importance. The impressive empirical performance of these architectures has long been known within the data compression community, but a theoretically satisfying explanation as to how and why they perform so well has proven difficult. What distinguishes these architectures from other neural systems is the distributed and local nature of their credit assignment mechanism; each neuron directly predicts the target and has its own set of hard-gated weights that are locally adapted via online convex optimization. By providing an interpretation, generalization and subsequent theoretical analysis, we show that sufficiently large GLNs are universal in a strong sense: not only can they model any compactly supported, continuous density function to arbitrary accuracy, but that any choice of no-regret online convex optimization technique will provably converge to the correct solution with enough data. Empirically we show a collection of single-pass learning results on established machine learning benchmarks that are competitive with results obtained with general purpose batch learning techniques.
A Framework for Data-Driven Robotics
Sep 26, 2019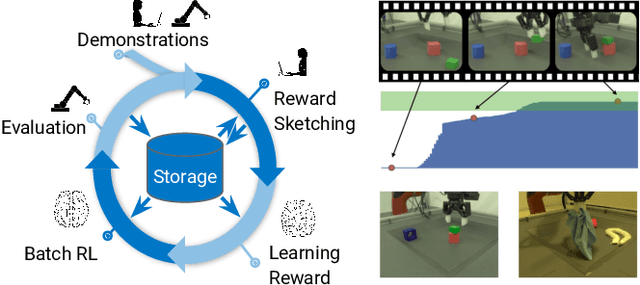
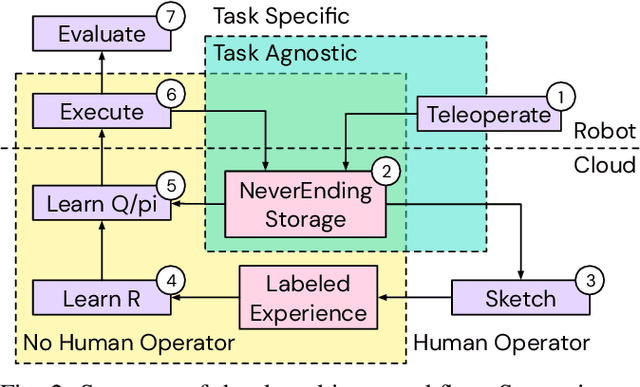
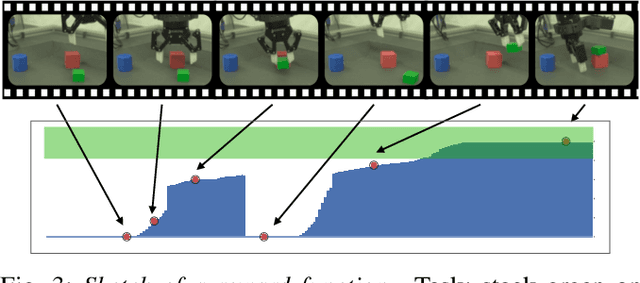
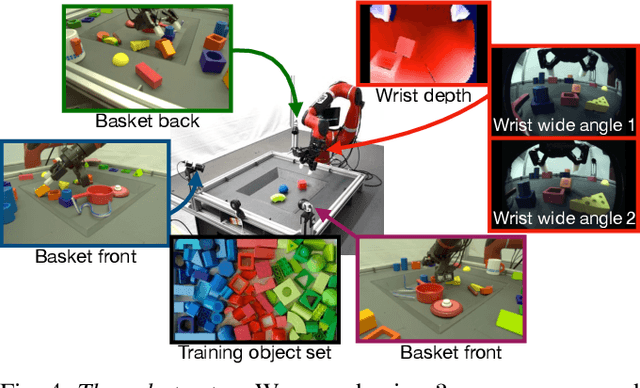
We present a framework for data-driven robotics that makes use of a large dataset of recorded robot experience and scales to several tasks using learned reward functions. We show how to apply this framework to accomplish three different object manipulation tasks on a real robot platform. Given demonstrations of a task together with task-agnostic recorded experience, we use a special form of human annotation as supervision to learn a reward function, which enables us to deal with real-world tasks where the reward signal cannot be acquired directly. Learned rewards are used in combination with a large dataset of experience from different tasks to learn a robot policy offline using batch RL. We show that using our approach it is possible to train agents to perform a variety of challenging manipulation tasks including stacking rigid objects and handling cloth.
Modular Meta-Learning with Shrinkage
Sep 12, 2019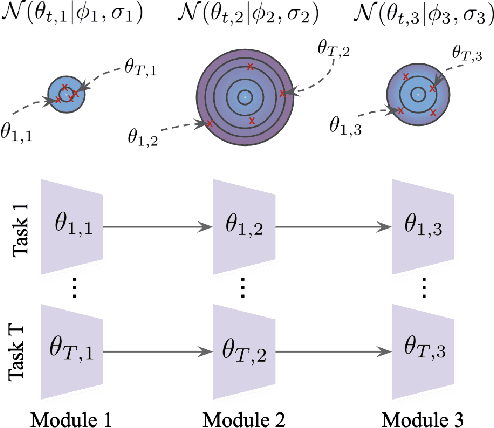
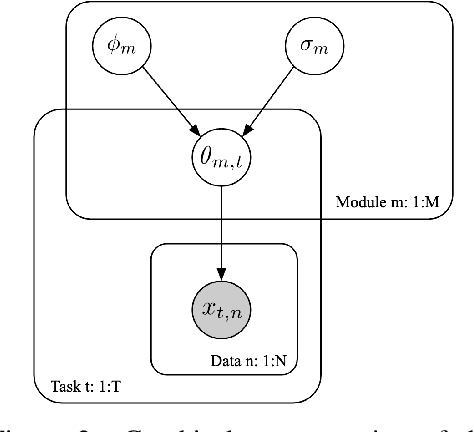
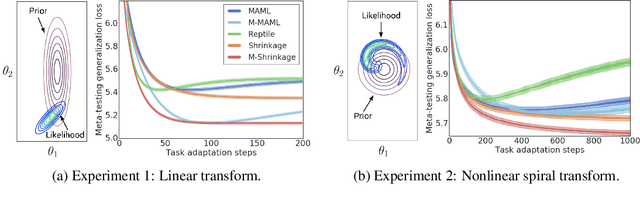
Most gradient-based approaches to meta-learning do not explicitly account for the fact that different parts of the underlying model adapt by different amounts when applied to a new task. For example, the input layers of an image classification convnet typically adapt very little, while the output layers can change significantly. This can cause parts of the model to begin to overfit while others underfit. To address this, we introduce a hierarchical Bayesian model with per-module shrinkage parameters, which we propose to learn by maximizing an approximation of the predictive likelihood using implicit differentiation. Our algorithm subsumes Reptile and outperforms variants of MAML on two synthetic few-shot meta-learning problems.
A Generalized Framework for Population Based Training
Feb 05, 2019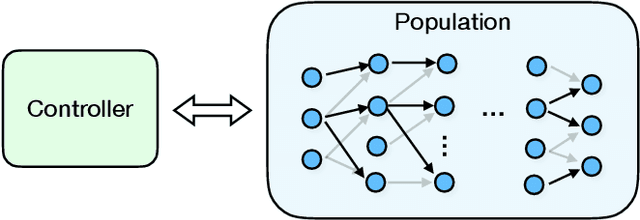

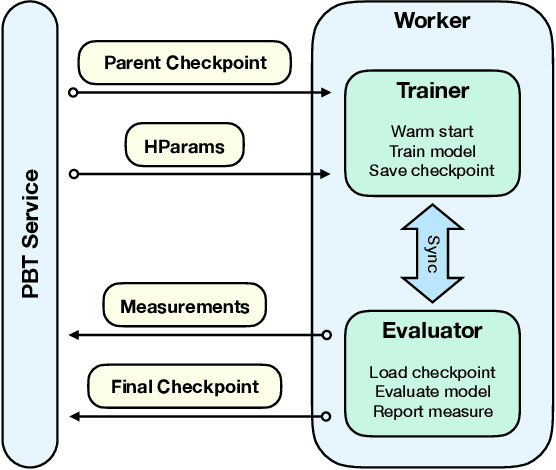
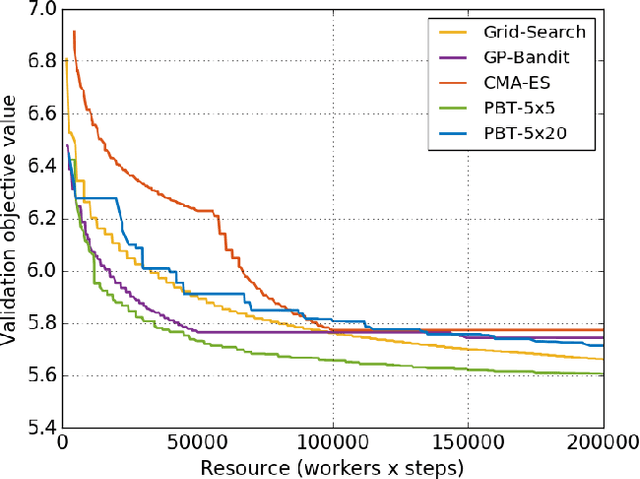
Population Based Training (PBT) is a recent approach that jointly optimizes neural network weights and hyperparameters which periodically copies weights of the best performers and mutates hyperparameters during training. Previous PBT implementations have been synchronized glass-box systems. We propose a general, black-box PBT framework that distributes many asynchronous "trials" (a small number of training steps with warm-starting) across a cluster, coordinated by the PBT controller. The black-box design does not make assumptions on model architectures, loss functions or training procedures. Our system supports dynamic hyperparameter schedules to optimize both differentiable and non-differentiable metrics. We apply our system to train a state-of-the-art WaveNet generative model for human voice synthesis. We show that our PBT system achieves better accuracy, less sensitivity and faster convergence compared to existing methods, given the same computational resource.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019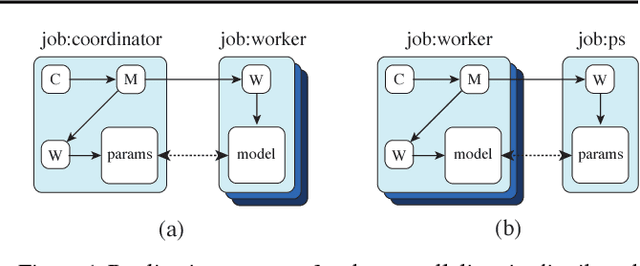

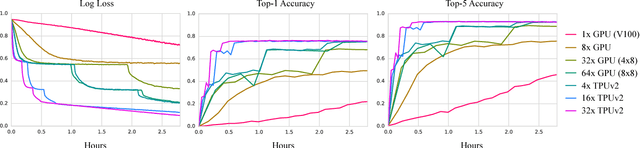
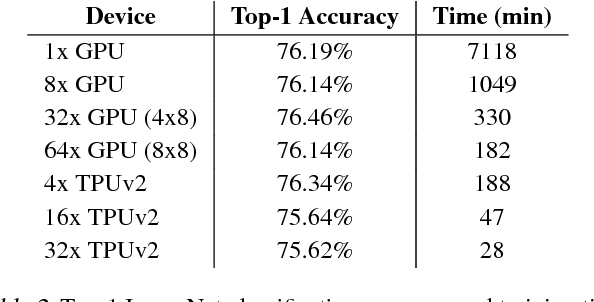
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
Oct 11, 2018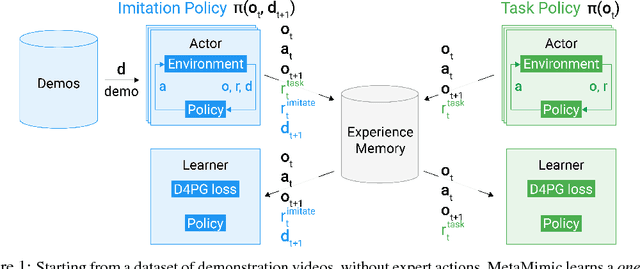
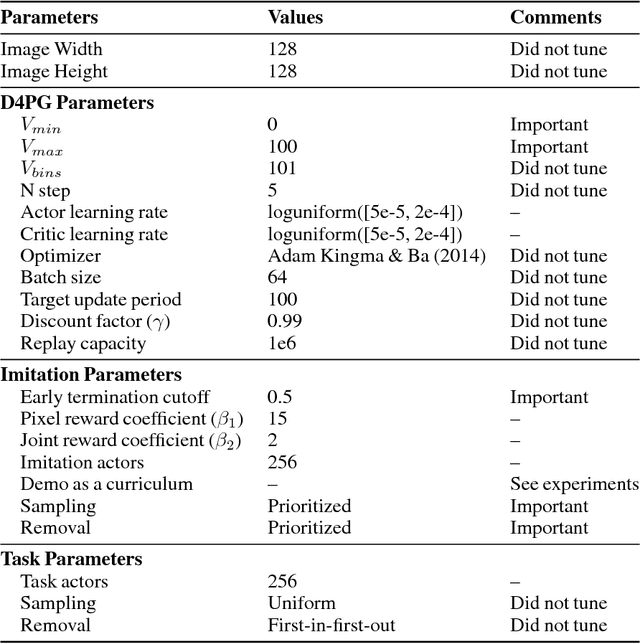
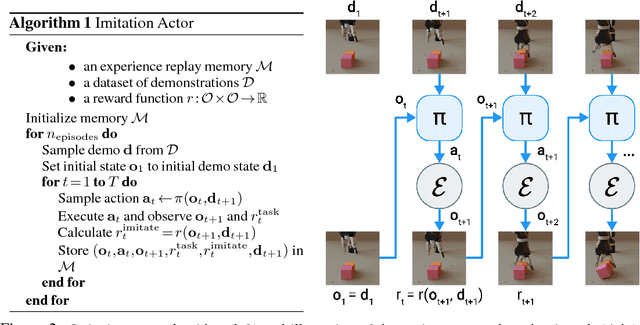
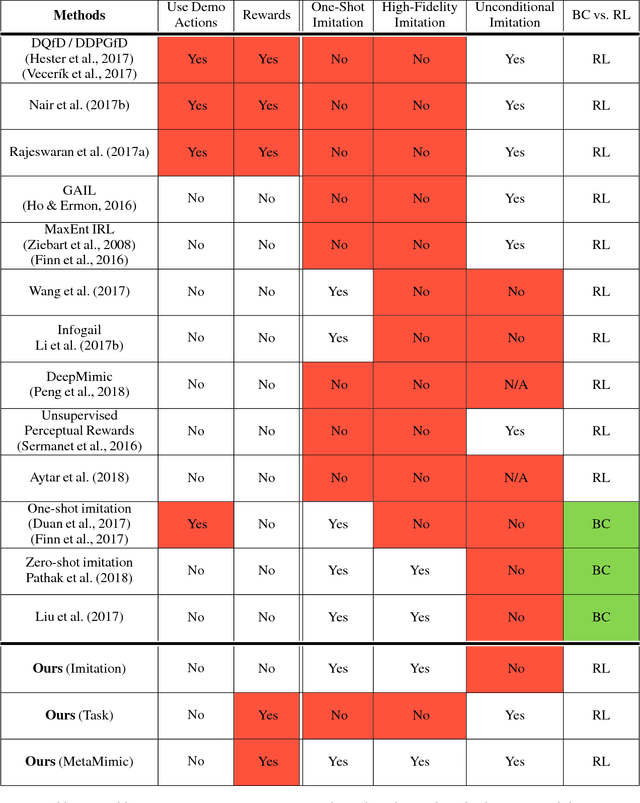
Humans are experts at high-fidelity imitation -- closely mimicking a demonstration, often in one attempt. Humans use this ability to quickly solve a task instance, and to bootstrap learning of new tasks. Achieving these abilities in autonomous agents is an open problem. In this paper, we introduce an off-policy RL algorithm (MetaMimic) to narrow this gap. MetaMimic can learn both (i) policies for high-fidelity one-shot imitation of diverse novel skills, and (ii) policies that enable the agent to solve tasks more efficiently than the demonstrators. MetaMimic relies on the principle of storing all experiences in a memory and replaying these to learn massive deep neural network policies by off-policy RL. This paper introduces, to the best of our knowledge, the largest existing neural networks for deep RL and shows that larger networks with normalization are needed to achieve one-shot high-fidelity imitation on a challenging manipulation task. The results also show that both types of policy can be learned from vision, in spite of the task rewards being sparse, and without access to demonstrator actions.
Sample Efficient Adaptive Text-to-Speech
Sep 27, 2018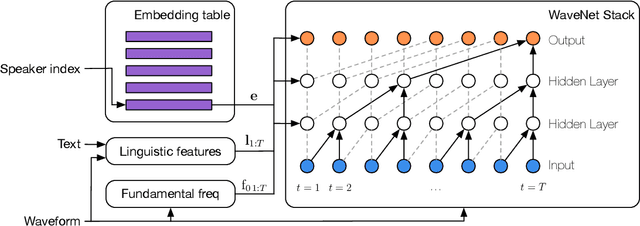
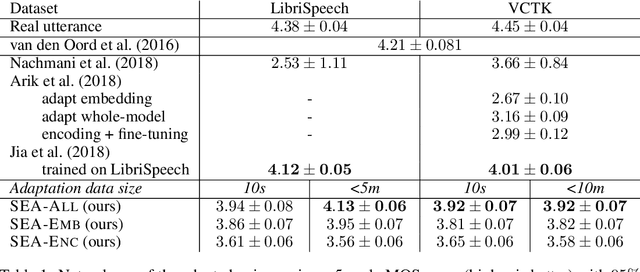
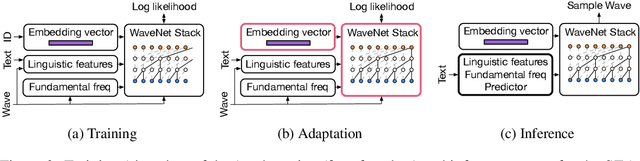
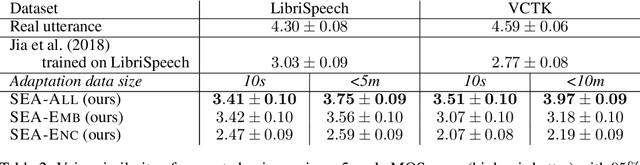
We present a meta-learning approach for adaptive text-to-speech (TTS) with few data. During training, we learn a multi-speaker model using a shared conditional WaveNet core and independent learned embeddings for each speaker. The aim of training is not to produce a neural network with fixed weights, which is then deployed as a TTS system. Instead, the aim is to produce a network that requires few data at deployment time to rapidly adapt to new speakers. We introduce and benchmark three strategies: (i) learning the speaker embedding while keeping the WaveNet core fixed, (ii) fine-tuning the entire architecture with stochastic gradient descent, and (iii) predicting the speaker embedding with a trained neural network encoder. The experiments show that these approaches are successful at adapting the multi-speaker neural network to new speakers, obtaining state-of-the-art results in both sample naturalness and voice similarity with merely a few minutes of audio data from new speakers.
Observe and Look Further: Achieving Consistent Performance on Atari
May 29, 2018
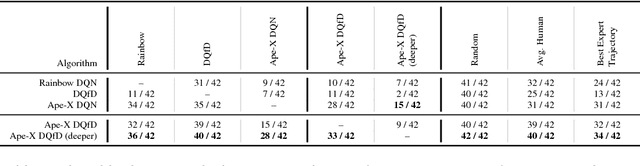
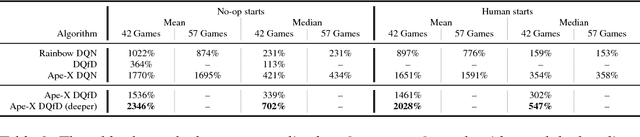
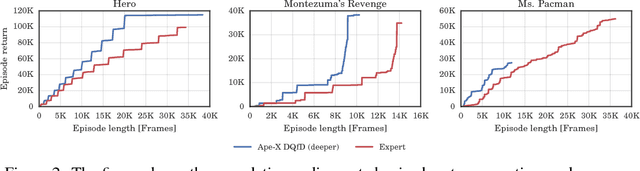
Despite significant advances in the field of deep Reinforcement Learning (RL), today's algorithms still fail to learn human-level policies consistently over a set of diverse tasks such as Atari 2600 games. We identify three key challenges that any algorithm needs to master in order to perform well on all games: processing diverse reward distributions, reasoning over long time horizons, and exploring efficiently. In this paper, we propose an algorithm that addresses each of these challenges and is able to learn human-level policies on nearly all Atari games. A new transformed Bellman operator allows our algorithm to process rewards of varying densities and scales; an auxiliary temporal consistency loss allows us to train stably using a discount factor of $\gamma = 0.999$ (instead of $\gamma = 0.99$) extending the effective planning horizon by an order of magnitude; and we ease the exploration problem by using human demonstrations that guide the agent towards rewarding states. When tested on a set of 42 Atari games, our algorithm exceeds the performance of an average human on 40 games using a common set of hyper parameters. Furthermore, it is the first deep RL algorithm to solve the first level of Montezuma's Revenge.
Playing hard exploration games by watching YouTube
May 29, 2018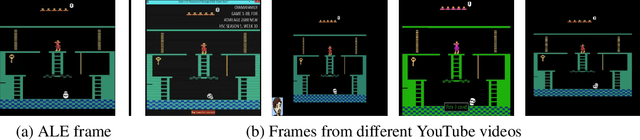

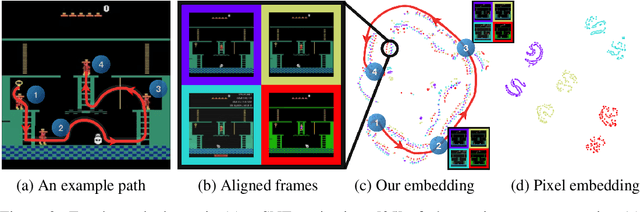
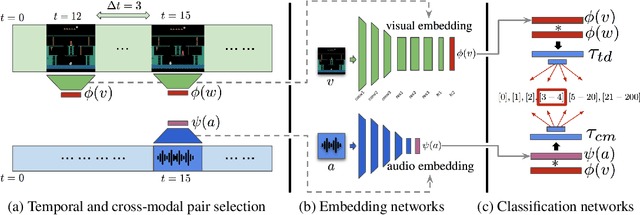
Deep reinforcement learning methods traditionally struggle with tasks where environment rewards are particularly sparse. One successful method of guiding exploration in these domains is to imitate trajectories provided by a human demonstrator. However, these demonstrations are typically collected under artificial conditions, i.e. with access to the agent's exact environment setup and the demonstrator's action and reward trajectories. Here we propose a two-stage method that overcomes these limitations by relying on noisy, unaligned footage without access to such data. First, we learn to map unaligned videos from multiple sources to a common representation using self-supervised objectives constructed over both time and modality (i.e. vision and sound). Second, we embed a single YouTube video in this representation to construct a reward function that encourages an agent to imitate human gameplay. This method of one-shot imitation allows our agent to convincingly exceed human-level performance on the infamously hard exploration games Montezuma's Revenge, Pitfall! and Private Eye for the first time, even if the agent is not presented with any environment rewards.
Distributed Distributional Deterministic Policy Gradients
Apr 23, 2018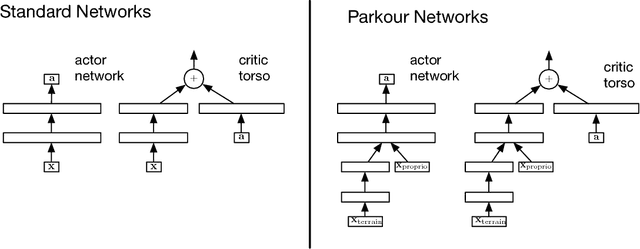
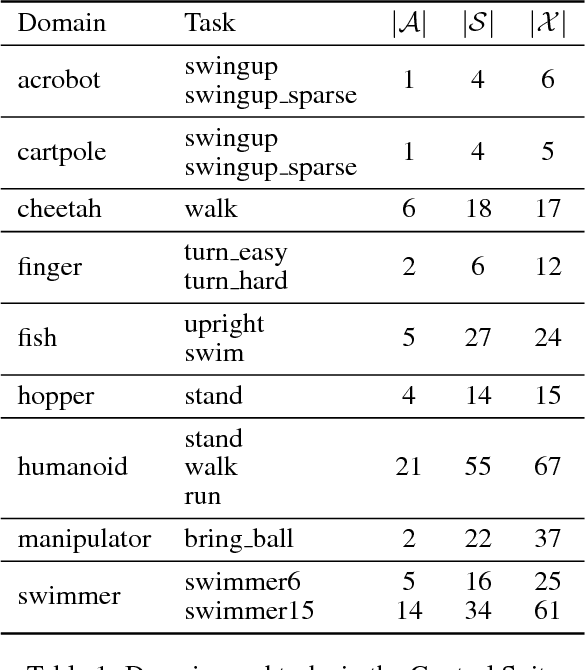
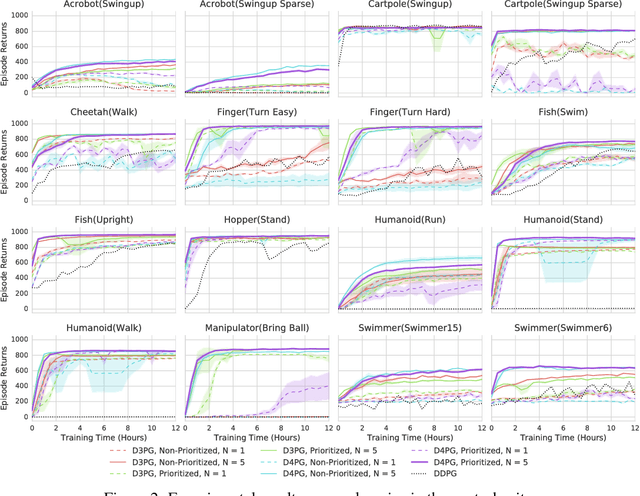
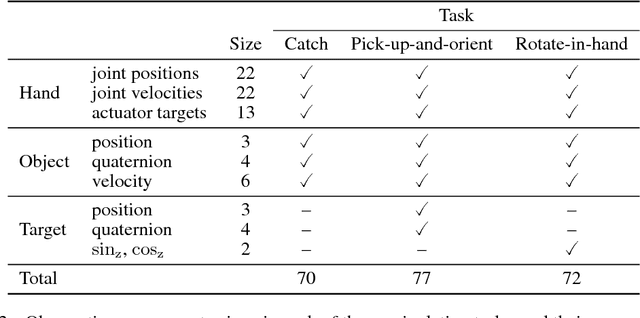
This work adopts the very successful distributional perspective on reinforcement learning and adapts it to the continuous control setting. We combine this within a distributed framework for off-policy learning in order to develop what we call the Distributed Distributional Deep Deterministic Policy Gradient algorithm, D4PG. We also combine this technique with a number of additional, simple improvements such as the use of $N$-step returns and prioritized experience replay. Experimentally we examine the contribution of each of these individual components, and show how they interact, as well as their combined contributions. Our results show that across a wide variety of simple control tasks, difficult manipulation tasks, and a set of hard obstacle-based locomotion tasks the D4PG algorithm achieves state of the art performance.