 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGated Linear Networks
Paper and Code
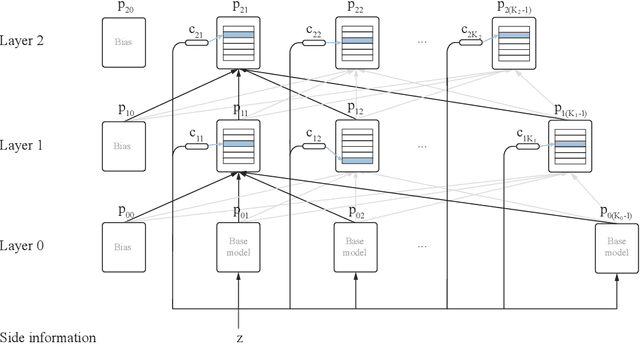
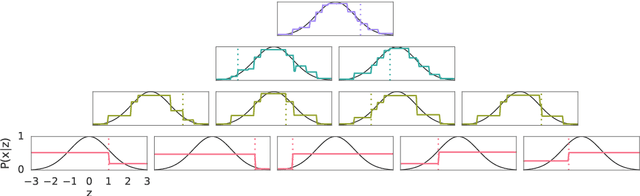
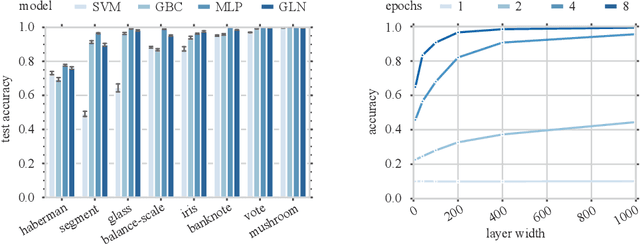
This paper presents a family of backpropagation-free neural architectures, Gated Linear Networks (GLNs),that are well suited to online learning applications where sample efficiency is of paramount importance. The impressive empirical performance of these architectures has long been known within the data compression community, but a theoretically satisfying explanation as to how and why they perform so well has proven difficult. What distinguishes these architectures from other neural systems is the distributed and local nature of their credit assignment mechanism; each neuron directly predicts the target and has its own set of hard-gated weights that are locally adapted via online convex optimization. By providing an interpretation, generalization and subsequent theoretical analysis, we show that sufficiently large GLNs are universal in a strong sense: not only can they model any compactly supported, continuous density function to arbitrary accuracy, but that any choice of no-regret online convex optimization technique will provably converge to the correct solution with enough data. Empirically we show a collection of single-pass learning results on established machine learning benchmarks that are competitive with results obtained with general purpose batch learning techniques.