 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Down Text Encoders of Text-to-Image Diffusion Models
Mar 25, 2025



Text encoders in diffusion models have rapidly evolved, transitioning from CLIP to T5-XXL. Although this evolution has significantly enhanced the models' ability to understand complex prompts and generate text, it also leads to a substantial increase in the number of parameters. Despite T5 series encoders being trained on the C4 natural language corpus, which includes a significant amount of non-visual data, diffusion models with T5 encoder do not respond to those non-visual prompts, indicating redundancy in representational power. Therefore, it raises an important question: "Do we really need such a large text encoder?" In pursuit of an answer, we employ vision-based knowledge distillation to train a series of T5 encoder models. To fully inherit its capabilities, we constructed our dataset based on three criteria: image quality, semantic understanding, and text-rendering. Our results demonstrate the scaling down pattern that the distilled T5-base model can generate images of comparable quality to those produced by T5-XXL, while being 50 times smaller in size. This reduction in model size significantly lowers the GPU requirements for running state-of-the-art models such as FLUX and SD3, making high-quality text-to-image generation more accessible.
OmniPrism: Learning Disentangled Visual Concept for Image Generation
Dec 16, 2024



Creative visual concept generation often draws inspiration from specific concepts in a reference image to produce relevant outcomes. However, existing methods are typically constrained to single-aspect concept generation or are easily disrupted by irrelevant concepts in multi-aspect concept scenarios, leading to concept confusion and hindering creative generation. To address this, we propose OmniPrism, a visual concept disentangling approach for creative image generation. Our method learns disentangled concept representations guided by natural language and trains a diffusion model to incorporate these concepts. We utilize the rich semantic space of a multimodal extractor to achieve concept disentanglement from given images and concept guidance. To disentangle concepts with different semantics, we construct a paired concept disentangled dataset (PCD-200K), where each pair shares the same concept such as content, style, and composition. We learn disentangled concept representations through our contrastive orthogonal disentangled (COD) training pipeline, which are then injected into additional diffusion cross-attention layers for generation. A set of block embeddings is designed to adapt each block's concept domain in the diffusion models. Extensive experiments demonstrate that our method can generate high-quality, concept-disentangled results with high fidelity to text prompts and desired concepts.
Decompose Semantic Shifts for Composed Image Retrieval
Sep 18, 2023



Composed image retrieval is a type of image retrieval task where the user provides a reference image as a starting point and specifies a text on how to shift from the starting point to the desired target image. However, most existing methods focus on the composition learning of text and reference images and oversimplify the text as a description, neglecting the inherent structure and the user's shifting intention of the texts. As a result, these methods typically take shortcuts that disregard the visual cue of the reference images. To address this issue, we reconsider the text as instructions and propose a Semantic Shift network (SSN) that explicitly decomposes the semantic shifts into two steps: from the reference image to the visual prototype and from the visual prototype to the target image. Specifically, SSN explicitly decomposes the instructions into two components: degradation and upgradation, where the degradation is used to picture the visual prototype from the reference image, while the upgradation is used to enrich the visual prototype into the final representations to retrieve the desired target image. The experimental results show that the proposed SSN demonstrates a significant improvement of 5.42% and 1.37% on the CIRR and FashionIQ datasets, respectively, and establishes a new state-of-the-art performance. Codes will be publicly available.
Cocktail: Mixing Multi-Modality Controls for Text-Conditional Image Generation
Jun 01, 2023



Text-conditional diffusion models are able to generate high-fidelity images with diverse contents. However, linguistic representations frequently exhibit ambiguous descriptions of the envisioned objective imagery, requiring the incorporation of additional control signals to bolster the efficacy of text-guided diffusion models. In this work, we propose Cocktail, a pipeline to mix various modalities into one embedding, amalgamated with a generalized ControlNet (gControlNet), a controllable normalisation (ControlNorm), and a spatial guidance sampling method, to actualize multi-modal and spatially-refined control for text-conditional diffusion models. Specifically, we introduce a hyper-network gControlNet, dedicated to the alignment and infusion of the control signals from disparate modalities into the pre-trained diffusion model. gControlNet is capable of accepting flexible modality signals, encompassing the simultaneous reception of any combination of modality signals, or the supplementary fusion of multiple modality signals. The control signals are then fused and injected into the backbone model according to our proposed ControlNorm. Furthermore, our advanced spatial guidance sampling methodology proficiently incorporates the control signal into the designated region, thereby circumventing the manifestation of undesired objects within the generated image. We demonstrate the results of our method in controlling various modalities, proving high-quality synthesis and fidelity to multiple external signals.
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
May 10, 2023



Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.
ESceme: Vision-and-Language Navigation with Episodic Scene Memory
Mar 07, 2023Vision-and-language navigation (VLN) simulates a visual agent that follows natural-language navigation instructions in real-world scenes. Existing approaches have made enormous progress in navigation in new environments, such as beam search, pre-exploration, and dynamic or hierarchical history encoding. To balance generalization and efficiency, we resort to memorizing visited scenarios apart from the ongoing route while navigating. In this work, we introduce a mechanism of Episodic Scene memory (ESceme) for VLN that wakes an agent's memories of past visits when it enters the current scene. The episodic scene memory allows the agent to envision a bigger picture of the next prediction. This way, the agent learns to utilize dynamically updated information instead of merely adapting to static observations. We provide a simple yet effective implementation of ESceme by enhancing the accessible views at each location and progressively completing the memory while navigating. We verify the superiority of ESceme on short-horizon (R2R), long-horizon (R4R), and vision-and-dialog (CVDN) VLN tasks. Our ESceme also wins first place on the CVDN leaderboard. Code is available: \url{https://github.com/qizhust/esceme}.}
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
Mar 01, 2023



Automated machine learning (AutoML) seeks to build ML models with minimal human effort. While considerable research has been conducted in the area of AutoML in general, aiming to take humans out of the loop when building artificial intelligence (AI) applications, scant literature has focused on how AutoML works well in open-environment scenarios such as the process of training and updating large models, industrial supply chains or the industrial metaverse, where people often face open-loop problems during the search process: they must continuously collect data, update data and models, satisfy the requirements of the development and deployment environment, support massive devices, modify evaluation metrics, etc. Addressing the open-environment issue with pure data-driven approaches requires considerable data, computing resources, and effort from dedicated data engineers, making current AutoML systems and platforms inefficient and computationally intractable. Human-computer interaction is a practical and feasible way to tackle the problem of open-environment AI. In this paper, we introduce OmniForce, a human-centered AutoML (HAML) system that yields both human-assisted ML and ML-assisted human techniques, to put an AutoML system into practice and build adaptive AI in open-environment scenarios. Specifically, we present OmniForce in terms of ML version management; pipeline-driven development and deployment collaborations; a flexible search strategy framework; and widely provisioned and crowdsourced application algorithms, including large models. Furthermore, the (large) models constructed by OmniForce can be automatically turned into remote services in a few minutes; this process is dubbed model as a service (MaaS). Experimental results obtained in multiple search spaces and real-world use cases demonstrate the efficacy and efficiency of OmniForce.
Eliminating Prior Bias for Semantic Image Editing via Dual-Cycle Diffusion
Feb 07, 2023The recent success of text-to-image generation diffusion models has also revolutionized semantic image editing, enabling the manipulation of images based on query/target texts. Despite these advancements, a significant challenge lies in the potential introduction of prior bias in pre-trained models during image editing, e.g., making unexpected modifications to inappropriate regions. To this point, we present a novel Dual-Cycle Diffusion model that addresses the issue of prior bias by generating an unbiased mask as the guidance of image editing. The proposed model incorporates a Bias Elimination Cycle that consists of both a forward path and an inverted path, each featuring a Structural Consistency Cycle to ensure the preservation of image content during the editing process. The forward path utilizes the pre-trained model to produce the edited image, while the inverted path converts the result back to the source image. The unbiased mask is generated by comparing differences between the processed source image and the edited image to ensure that both conform to the same distribution. Our experiments demonstrate the effectiveness of the proposed method, as it significantly improves the D-CLIP score from 0.272 to 0.283. The code will be available at https://github.com/JohnDreamer/DualCycleDiffsion.
Cross-Modal Contrastive Learning for Robust Reasoning in VQA
Nov 21, 2022Multi-modal reasoning in visual question answering (VQA) has witnessed rapid progress recently. However, most reasoning models heavily rely on shortcuts learned from training data, which prevents their usage in challenging real-world scenarios. In this paper, we propose a simple but effective cross-modal contrastive learning strategy to get rid of the shortcut reasoning caused by imbalanced annotations and improve the overall performance. Different from existing contrastive learning with complex negative categories on coarse (Image, Question, Answer) triplet level, we leverage the correspondences between the language and image modalities to perform finer-grained cross-modal contrastive learning. We treat each Question-Answer (QA) pair as a whole, and differentiate between images that conform with it and those against it. To alleviate the issue of sampling bias, we further build connected graphs among images. For each positive pair, we regard the images from different graphs as negative samples and deduct the version of multi-positive contrastive learning. To our best knowledge, it is the first paper that reveals a general contrastive learning strategy without delicate hand-craft rules can contribute to robust VQA reasoning. Experiments on several mainstream VQA datasets demonstrate our superiority compared to the state of the arts. Code is available at \url{https://github.com/qizhust/cmcl_vqa_pl}.
SemMAE: Semantic-Guided Masking for Learning Masked Autoencoders
Jun 25, 2022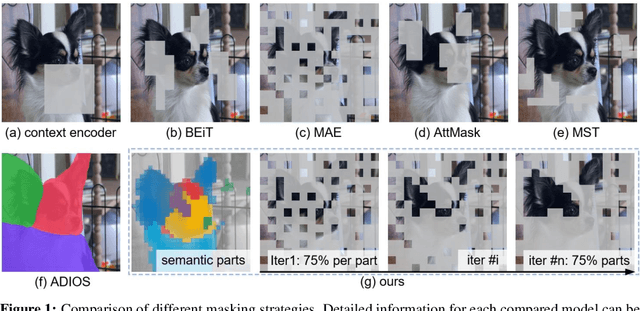

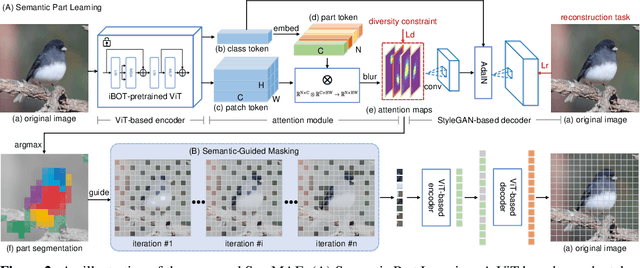

Recently, significant progress has been made in masked image modeling to catch up to masked language modeling. However, unlike words in NLP, the lack of semantic decomposition of images still makes masked autoencoding (MAE) different between vision and language. In this paper, we explore a potential visual analogue of words, i.e., semantic parts, and we integrate semantic information into the training process of MAE by proposing a Semantic-Guided Masking strategy. Compared to widely adopted random masking, our masking strategy can gradually guide the network to learn various information, i.e., from intra-part patterns to inter-part relations. In particular, we achieve this in two steps. 1) Semantic part learning: we design a self-supervised part learning method to obtain semantic parts by leveraging and refining the multi-head attention of a ViT-based encoder. 2) Semantic-guided MAE (SemMAE) training: we design a masking strategy that varies from masking a portion of patches in each part to masking a portion of (whole) parts in an image. Extensive experiments on various vision tasks show that SemMAE can learn better image representation by integrating semantic information. In particular, SemMAE achieves 84.5% fine-tuning accuracy on ImageNet-1k, which outperforms the vanilla MAE by 1.4%. In the semantic segmentation and fine-grained recognition tasks, SemMAE also brings significant improvements and yields the state-of-the-art performance.