 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyHopper -- Hyperparameter optimization
Oct 10, 2022
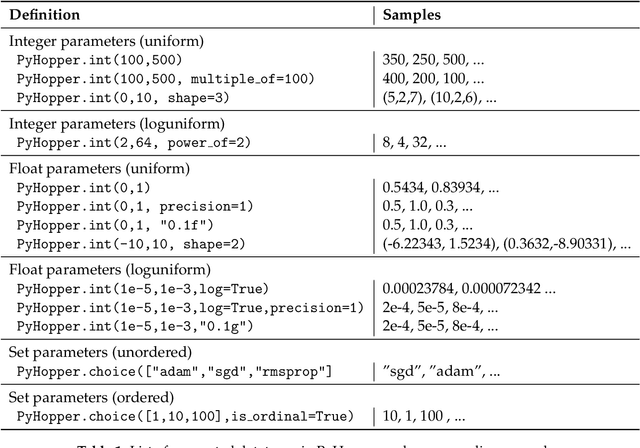
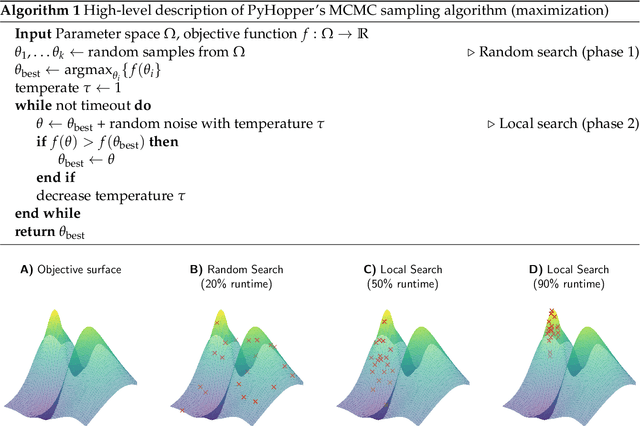
Hyperparameter tuning is a fundamental aspect of machine learning research. Setting up the infrastructure for systematic optimization of hyperparameters can take a significant amount of time. Here, we present PyHopper, a black-box optimization platform designed to streamline the hyperparameter tuning workflow of machine learning researchers. PyHopper's goal is to integrate with existing code with minimal effort and run the optimization process with minimal necessary manual oversight. With simplicity as the primary theme, PyHopper is powered by a single robust Markov-chain Monte-Carlo optimization algorithm that scales to millions of dimensions. Compared to existing tuning packages, focusing on a single algorithm frees the user from having to decide between several algorithms and makes PyHopper easily customizable. PyHopper is publicly available under the Apache-2.0 license at https://github.com/PyHopper/PyHopper.
On the Forward Invariance of Neural ODEs
Oct 10, 2022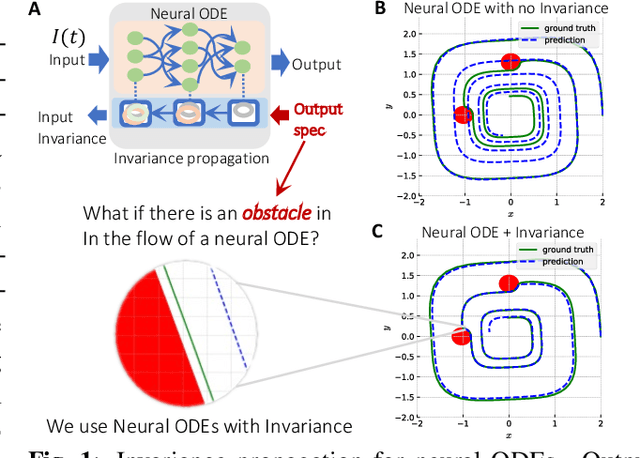

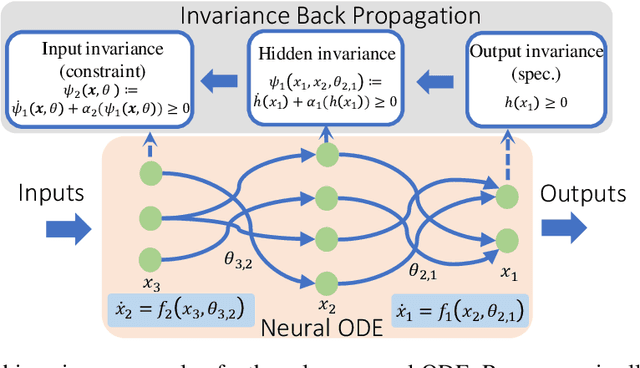
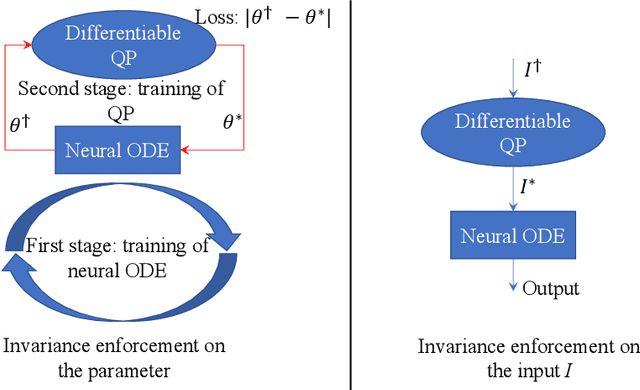
To ensure robust and trustworthy decision-making, it is highly desirable to enforce constraints over a neural network's parameters and its inputs automatically by back-propagating output specifications. This way, we can guarantee that the network makes reliable decisions under perturbations. Here, we propose a new method for achieving a class of specification guarantees for neural Ordinary Differentiable Equations (ODEs) by using invariance set propagation. An invariance of a neural ODE is defined as an output specification, such as to satisfy mathematical formulae, physical laws, and system safety. We use control barrier functions to specify the invariance of a neural ODE on the output layer and propagate it back to the input layer. Through the invariance backpropagation, we map output specifications onto constraints on the neural ODE parameters or its input. The satisfaction of the corresponding constraints implies the satisfaction of output specifications. This allows us to achieve output specification guarantees by changing the input or parameters while maximally preserving the model performance. We demonstrate the invariance propagation on a comprehensive series of representation learning tasks, including spiral curve regression, autoregressive modeling of joint physical dynamics, convexity portrait of a function, and safe neural control of collision avoidance for autonomous vehicles.
Are All Vision Models Created Equal? A Study of the Open-Loop to Closed-Loop Causality Gap
Oct 09, 2022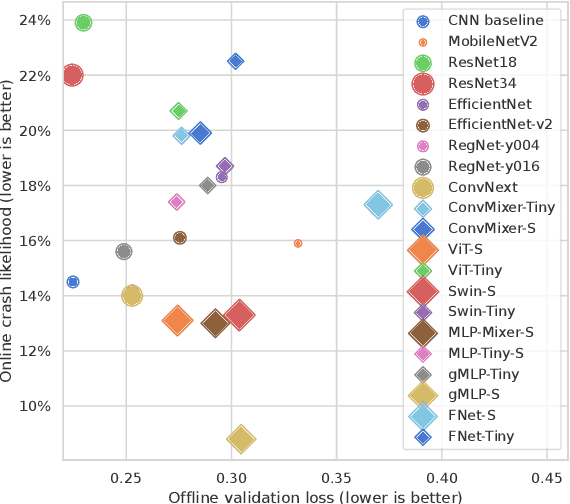
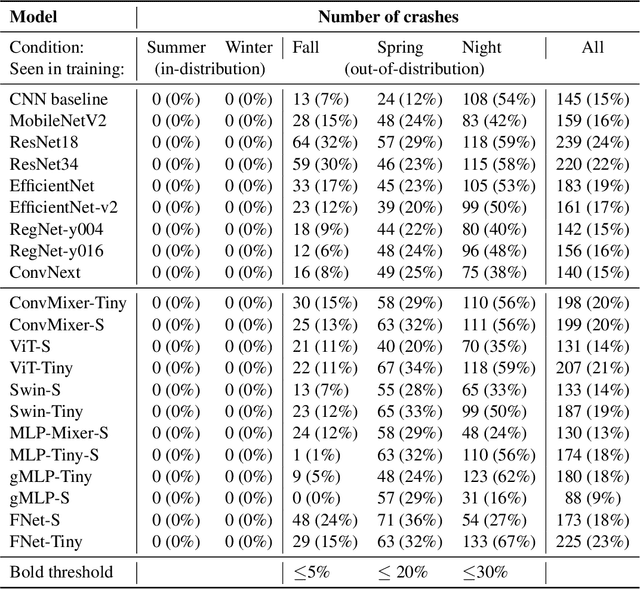

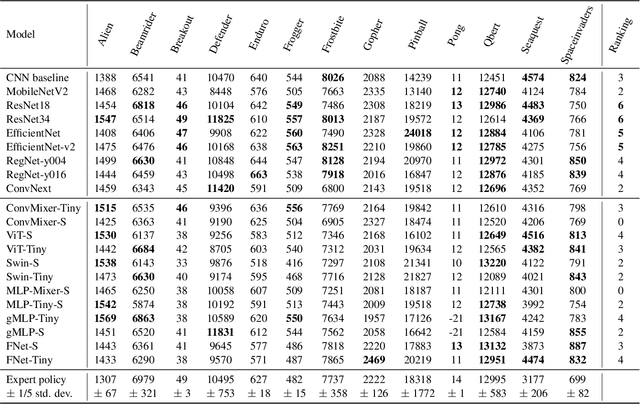
There is an ever-growing zoo of modern neural network models that can efficiently learn end-to-end control from visual observations. These advanced deep models, ranging from convolutional to patch-based networks, have been extensively tested on offline image classification and regression tasks. In this paper, we study these vision architectures with respect to the open-loop to closed-loop causality gap, i.e., offline training followed by an online closed-loop deployment. This causality gap typically emerges in robotics applications such as autonomous driving, where a network is trained to imitate the control commands of a human. In this setting, two situations arise: 1) Closed-loop testing in-distribution, where the test environment shares properties with those of offline training data. 2) Closed-loop testing under distribution shifts and out-of-distribution. Contrary to recently reported results, we show that under proper training guidelines, all vision models perform indistinguishably well on in-distribution deployment, resolving the causality gap. In situation 2, We observe that the causality gap disrupts performance regardless of the choice of the model architecture. Our results imply that the causality gap can be solved in situation one with our proposed training guideline with any modern network architecture, whereas achieving out-of-distribution generalization (situation two) requires further investigations, for instance, on data diversity rather than the model architecture.
Intention Communication and Hypothesis Likelihood in Game-Theoretic Motion Planning
Sep 26, 2022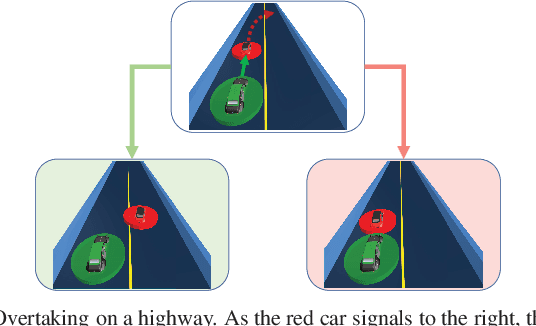
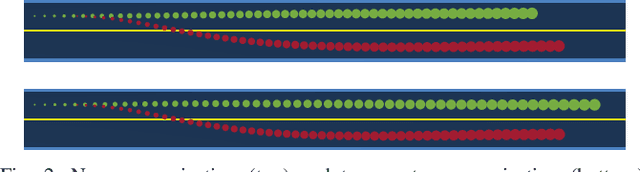
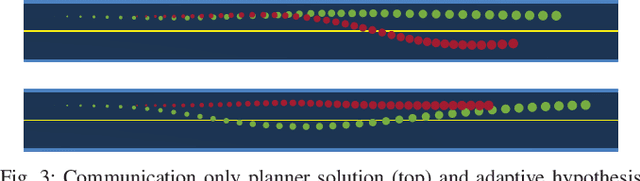

Game-theoretic motion planners are a potent solution for controlling systems of multiple highly interactive robots. Most existing game-theoretic planners unrealistically assume a priori objective function knowledge is available to all agents. To address this, we propose a fault-tolerant receding horizon game-theoretic motion planner that leverages inter-agent communication with intention hypothesis likelihood. Specifically, robots communicate their objective function incorporating their intentions. A discrete Bayesian filter is designed to infer the objectives in real-time based on the discrepancy between observed trajectories and the ones from communicated intentions. In simulation, we consider three safety-critical autonomous driving scenarios of overtaking, lane-merging and intersection crossing, to demonstrate our planner's ability to capitalize on alternative intention hypotheses to generate safe trajectories in the presence of faulty transmissions in the communication network.
Liquid Structural State-Space Models
Sep 26, 2022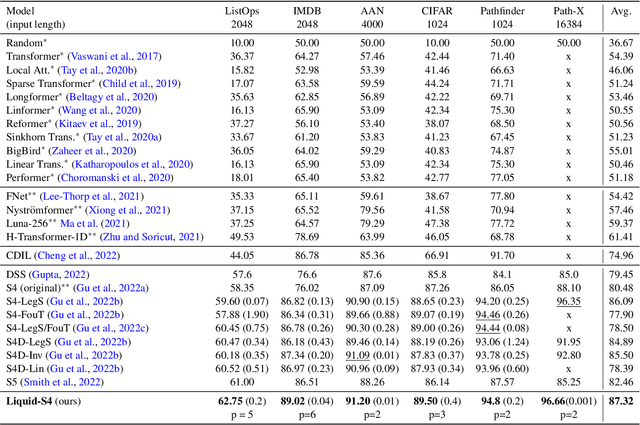
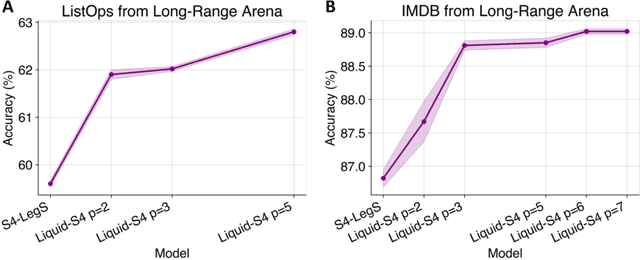
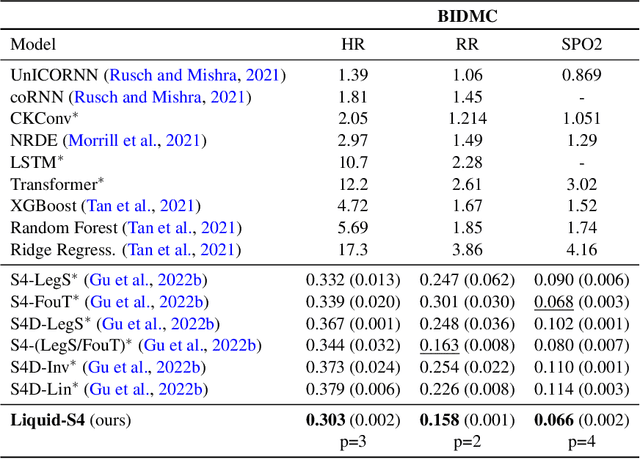
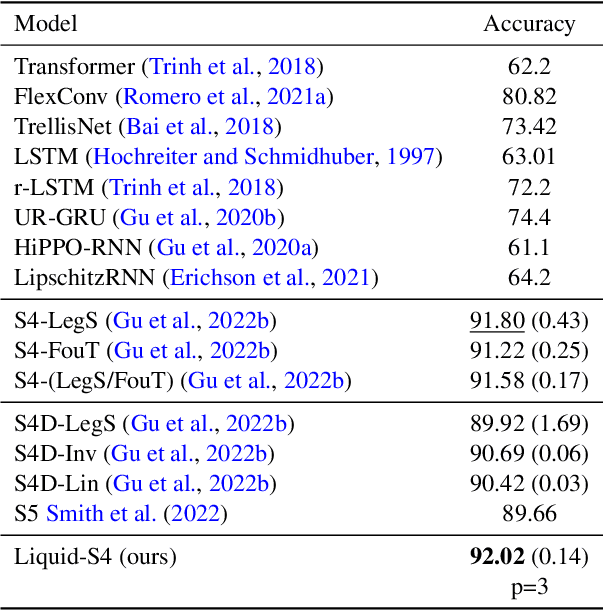
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.
Deep Learning on Home Drone: Searching for the Optimal Architecture
Sep 21, 2022
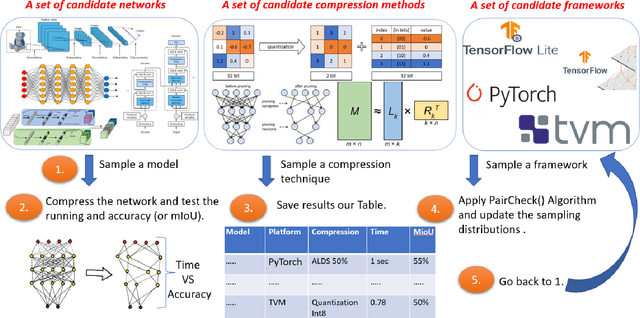


We suggest the first system that runs real-time semantic segmentation via deep learning on a weak micro-computer such as the Raspberry Pi Zero v2 (whose price was \$15) attached to a toy-drone. In particular, since the Raspberry Pi weighs less than $16$ grams, and its size is half of a credit card, we could easily attach it to the common commercial DJI Tello toy-drone (<\$100, <90 grams, 98 $\times$ 92.5 $\times$ 41 mm). The result is an autonomous drone (no laptop nor human in the loop) that can detect and classify objects in real-time from a video stream of an on-board monocular RGB camera (no GPS or LIDAR sensors). The companion videos demonstrate how this Tello drone scans the lab for people (e.g. for the use of firefighters or security forces) and for an empty parking slot outside the lab. Existing deep learning solutions are either much too slow for real-time computation on such IoT devices, or provide results of impractical quality. Our main challenge was to design a system that takes the best of all worlds among numerous combinations of networks, deep learning platforms/frameworks, compression techniques, and compression ratios. To this end, we provide an efficient searching algorithm that aims to find the optimal combination which results in the best tradeoff between the network running time and its accuracy/performance.
BIMS-PU: Bi-Directional and Multi-Scale Point Cloud Upsampling
Jun 25, 2022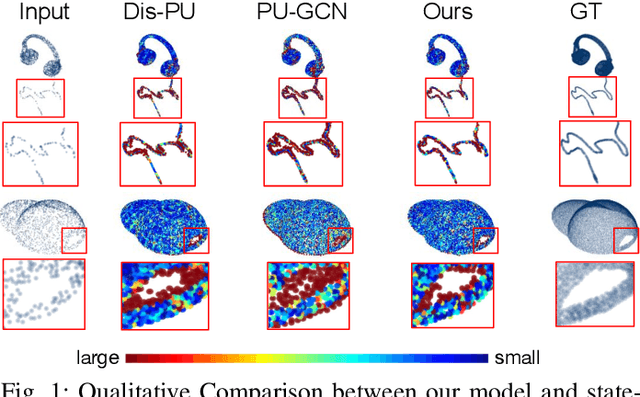
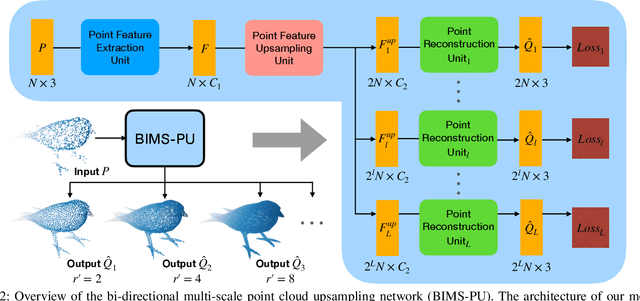
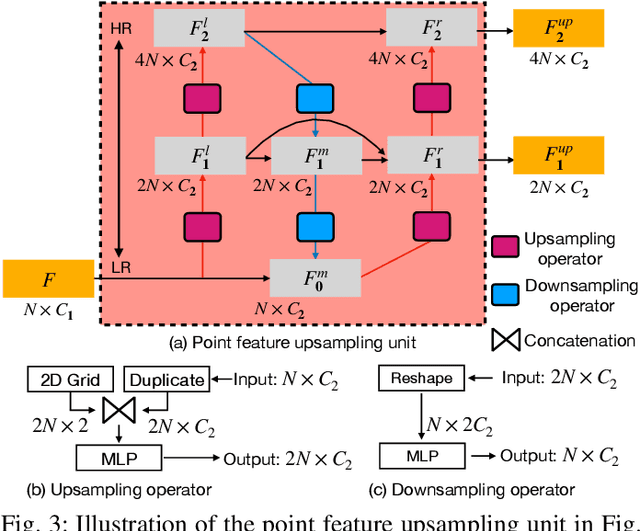
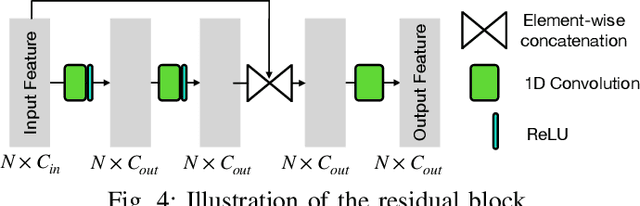
The learning and aggregation of multi-scale features are essential in empowering neural networks to capture the fine-grained geometric details in the point cloud upsampling task. Most existing approaches extract multi-scale features from a point cloud of a fixed resolution, hence obtain only a limited level of details. Though an existing approach aggregates a feature hierarchy of different resolutions from a cascade of upsampling sub-network, the training is complex with expensive computation. To address these issues, we construct a new point cloud upsampling pipeline called BIMS-PU that integrates the feature pyramid architecture with a bi-directional up and downsampling path. Specifically, we decompose the up/downsampling procedure into several up/downsampling sub-steps by breaking the target sampling factor into smaller factors. The multi-scale features are naturally produced in a parallel manner and aggregated using a fast feature fusion method. Supervision signal is simultaneously applied to all upsampled point clouds of different scales. Moreover, we formulate a residual block to ease the training of our model. Extensive quantitative and qualitative experiments on different datasets show that our method achieves superior results to state-of-the-art approaches. Last but not least, we demonstrate that point cloud upsampling can improve robot perception by ameliorating the 3D data quality.
* Accepted to RA-L 2022. in IEEE Robotics and Automation Letters
Entangled Residual Mappings
Jun 02, 2022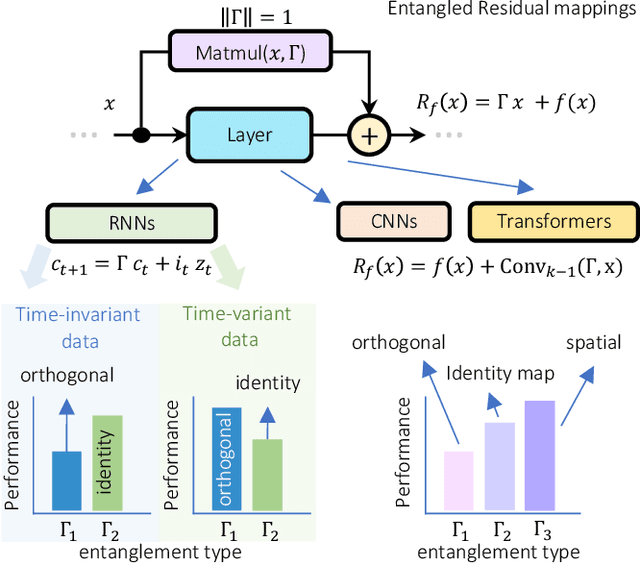
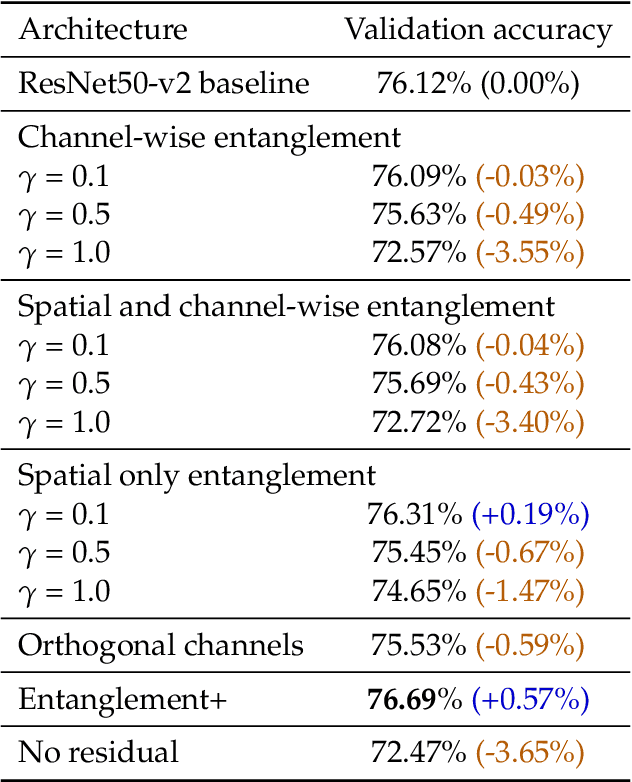
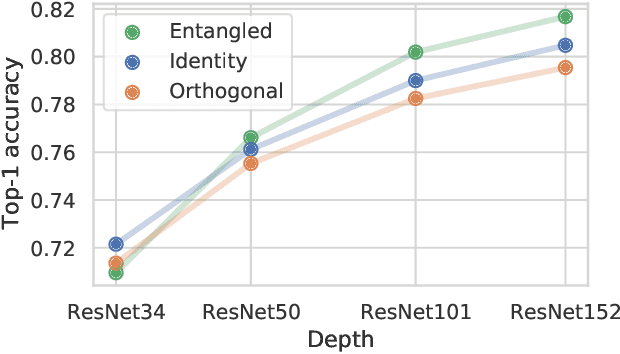
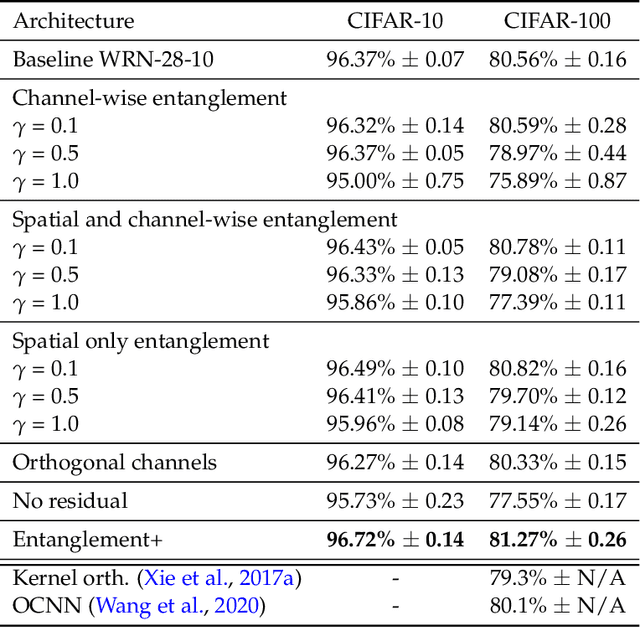
Residual mappings have been shown to perform representation learning in the first layers and iterative feature refinement in higher layers. This interplay, combined with their stabilizing effect on the gradient norms, enables them to train very deep networks. In this paper, we take a step further and introduce entangled residual mappings to generalize the structure of the residual connections and evaluate their role in iterative learning representations. An entangled residual mapping replaces the identity skip connections with specialized entangled mappings such as orthogonal, sparse, and structural correlation matrices that share key attributes (eigenvalues, structure, and Jacobian norm) with identity mappings. We show that while entangled mappings can preserve the iterative refinement of features across various deep models, they influence the representation learning process in convolutional networks differently than attention-based models and recurrent neural networks. In general, we find that for CNNs and Vision Transformers entangled sparse mapping can help generalization while orthogonal mappings hurt performance. For recurrent networks, orthogonal residual mappings form an inductive bias for time-variant sequences, which degrades accuracy on time-invariant tasks.
Multi-robot Task Assignment for Aerial Tracking with Viewpoint Constraints
May 31, 2022
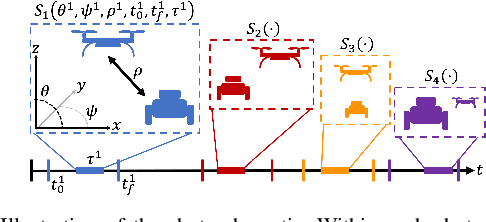
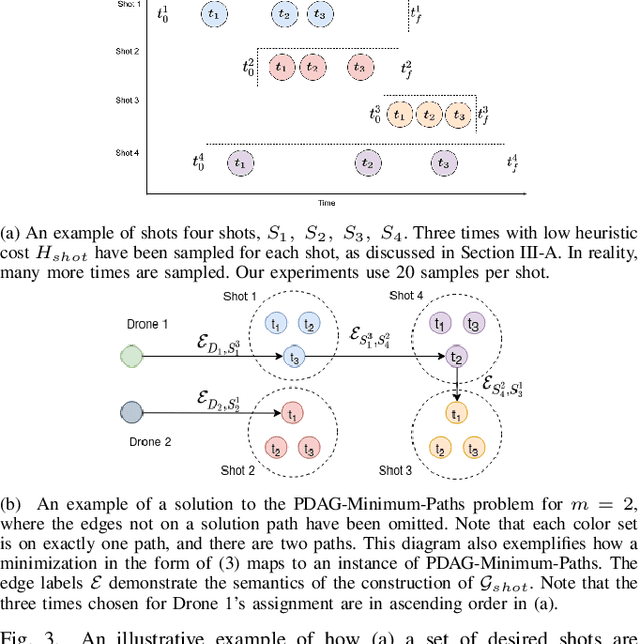
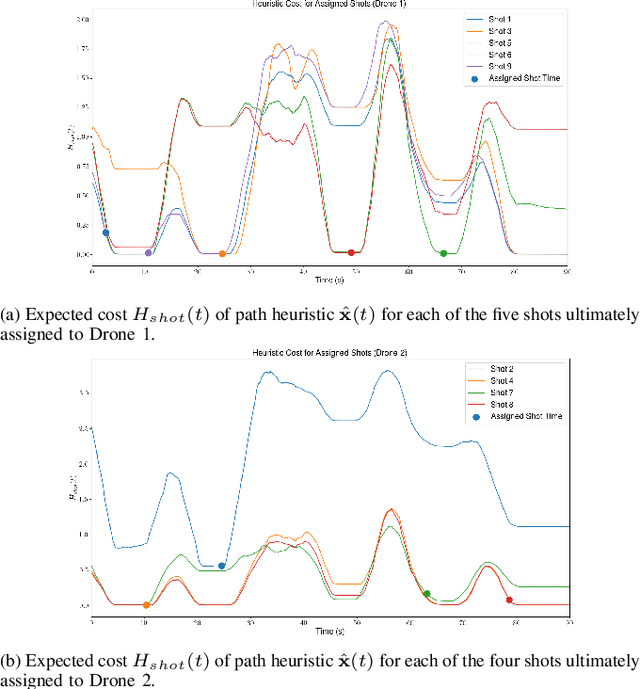
We address the problem of assigning a team of drones to autonomously capture a set desired shots of a dynamic target in the presence of obstacles. We present a two-stage planning pipeline that generates offline an assignment of drone to shots and locally optimizes online the viewpoint. Given desired shot parameters, the high-level planner uses a visibility heuristic to predict good times for capturing each shot and uses an Integer Linear Program to compute drone assignments. An online Model Predictive Control algorithm uses the assignments as reference to capture the shots. The algorithm is validated in hardware with a pair of drones and a remote controlled car.
Free-Space Ellipsoid Graphs for Multi-Agent Target Monitoring
May 31, 2022

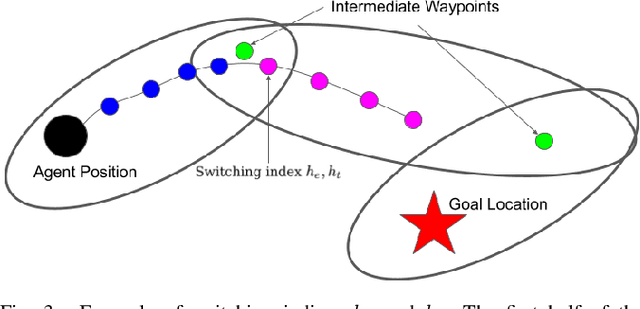
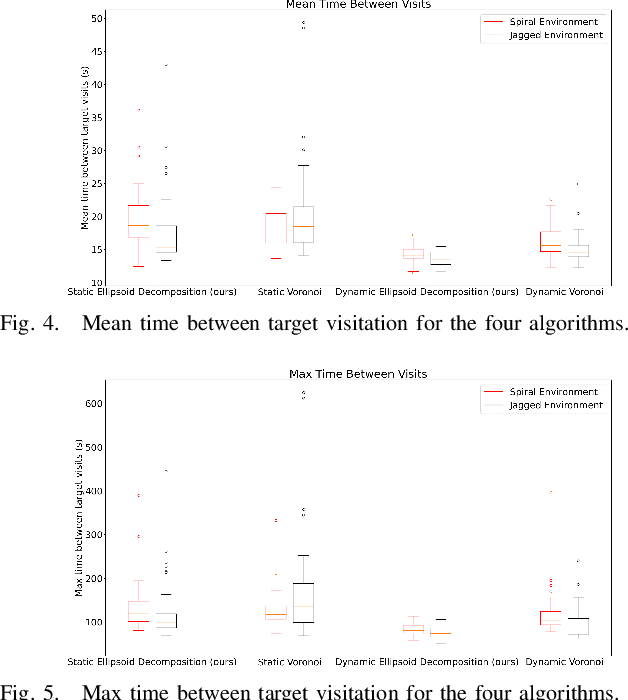
We apply a novel framework for decomposing and reasoning about free space in an environment to a multi-agent persistent monitoring problem. Our decomposition method represents free space as a collection of ellipsoids associated with a weighted connectivity graph. The same ellipsoids used for reasoning about connectivity and distance during high level planning can be used as state constraints in a Model Predictive Control algorithm to enforce collision-free motion. This structure allows for streamlined implementation in distributed multi-agent tasks in 2D and 3D environments. We illustrate its effectiveness for a team of tracking agents tasked with monitoring a group of target agents. Our algorithm uses the ellipsoid decomposition as a primitive for the coordination, path planning, and control of the tracking agents. Simulations with four tracking agents monitoring fifteen dynamic targets in obstacle-rich environments demonstrate the performance of our algorithm.