 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap: Differentially Private Equivariant Deep Learning for Medical Image Analysis
Sep 09, 2022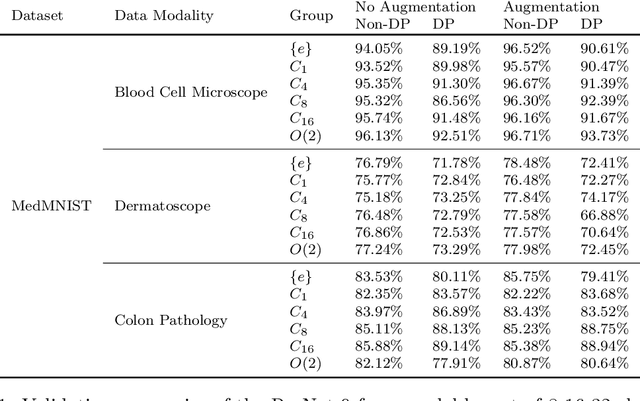
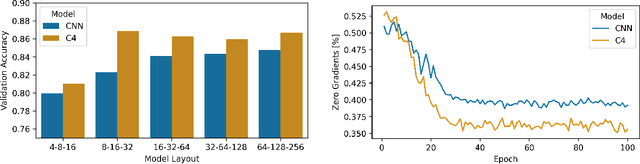
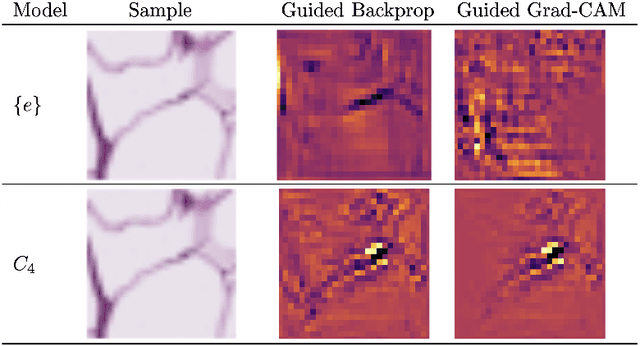
Machine learning with formal privacy-preserving techniques like Differential Privacy (DP) allows one to derive valuable insights from sensitive medical imaging data while promising to protect patient privacy, but it usually comes at a sharp privacy-utility trade-off. In this work, we propose to use steerable equivariant convolutional networks for medical image analysis with DP. Their improved feature quality and parameter efficiency yield remarkable accuracy gains, narrowing the privacy-utility gap.
Learning-based and unrolled motion-compensated reconstruction for cardiac MR CINE imaging
Sep 08, 2022



Motion-compensated MR reconstruction (MCMR) is a powerful concept with considerable potential, consisting of two coupled sub-problems: Motion estimation, assuming a known image, and image reconstruction, assuming known motion. In this work, we propose a learning-based self-supervised framework for MCMR, to efficiently deal with non-rigid motion corruption in cardiac MR imaging. Contrary to conventional MCMR methods in which the motion is estimated prior to reconstruction and remains unchanged during the iterative optimization process, we introduce a dynamic motion estimation process and embed it into the unrolled optimization. We establish a cardiac motion estimation network that leverages temporal information via a group-wise registration approach, and carry out a joint optimization between the motion estimation and reconstruction. Experiments on 40 acquired 2D cardiac MR CINE datasets demonstrate that the proposed unrolled MCMR framework can reconstruct high quality MR images at high acceleration rates where other state-of-the-art methods fail. We also show that the joint optimization mechanism is mutually beneficial for both sub-tasks, i.e., motion estimation and image reconstruction, especially when the MR image is highly undersampled.
Mesh-based 3D Motion Tracking in Cardiac MRI using Deep Learning
Sep 05, 2022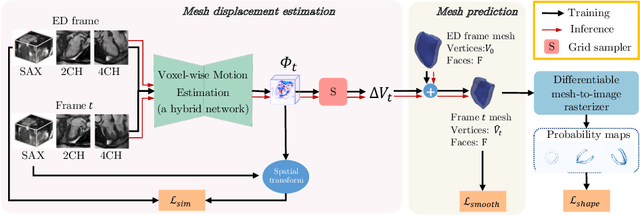
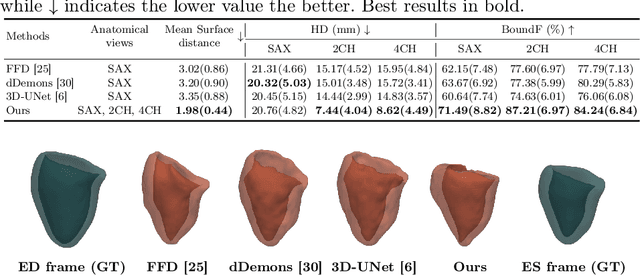
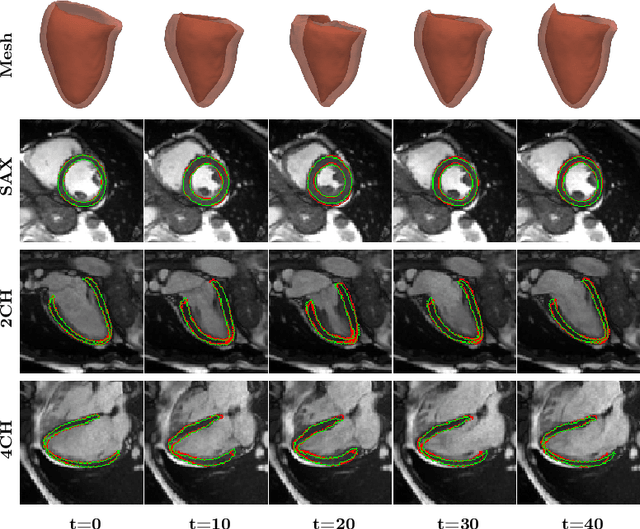

3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and diagnosis of cardiovascular diseases. Most of the previous methods focus on estimating pixel-/voxel-wise motion fields in the full image space, which ignore the fact that motion estimation is mainly relevant and useful within the object of interest, e.g., the heart. In this work, we model the heart as a 3D geometric mesh and propose a novel deep learning-based method that can estimate 3D motion of the heart mesh from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, the method is able to leverage the anatomical shape information from 2D multi-view CMR images for 3D motion estimation. The differentiability of the rasterizer enables us to train the method end-to-end. One advantage of the proposed method is that by tracking the motion of each vertex, it is able to keep the vertex correspondence of 3D meshes between time frames, which is important for quantitative assessment of the cardiac function on the mesh. We evaluate the proposed method on CMR images acquired from the UK Biobank study. Experimental results show that the proposed method quantitatively and qualitatively outperforms both conventional and learning-based cardiac motion tracking methods.
Generative Modelling of the Ageing Heart with Cross-Sectional Imaging and Clinical Data
Aug 28, 2022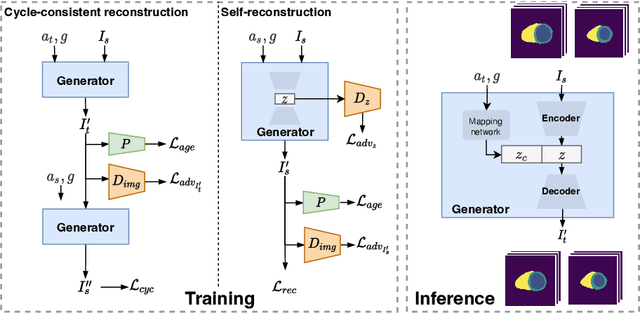

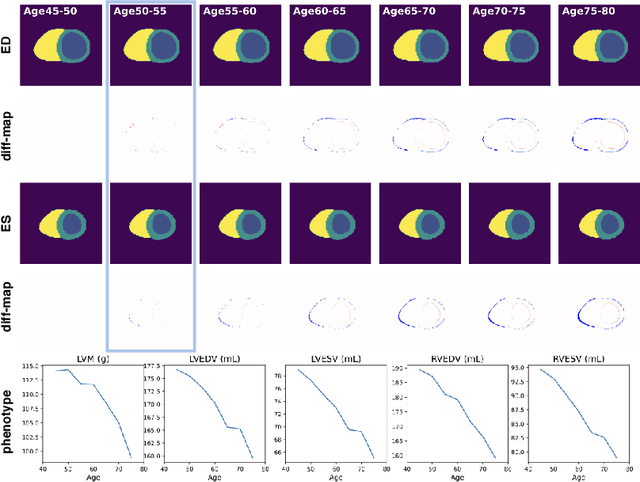

Cardiovascular disease, the leading cause of death globally, is an age-related disease. Understanding the morphological and functional changes of the heart during ageing is a key scientific question, the answer to which will help us define important risk factors of cardiovascular disease and monitor disease progression. In this work, we propose a novel conditional generative model to describe the changes of 3D anatomy of the heart during ageing. The proposed model is flexible and allows integration of multiple clinical factors (e.g. age, gender) into the generating process. We train the model on a large-scale cross-sectional dataset of cardiac anatomies and evaluate on both cross-sectional and longitudinal datasets. The model demonstrates excellent performance in predicting the longitudinal evolution of the ageing heart and modelling its data distribution.
Unsupervised Anomaly Localization with Structural Feature-Autoencoders
Aug 23, 2022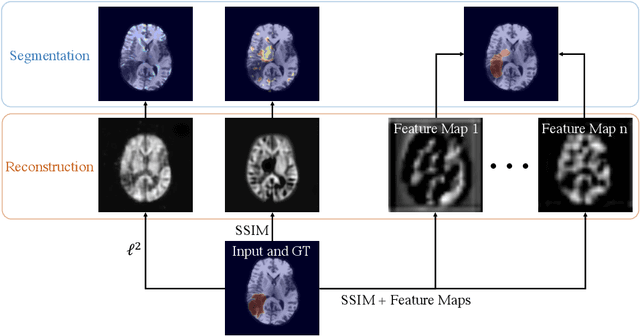
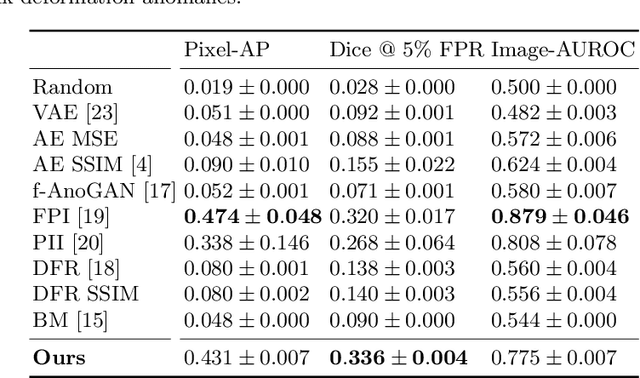
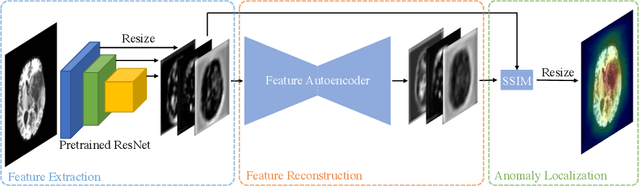
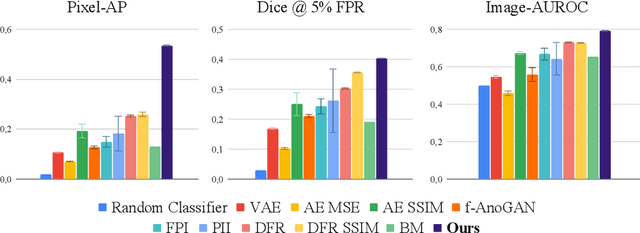
Unsupervised Anomaly Detection has become a popular method to detect pathologies in medical images as it does not require supervision or labels for training. Most commonly, the anomaly detection model generates a "normal" version of an input image, and the pixel-wise $l^p$-difference of the two is used to localize anomalies. However, large residuals often occur due to imperfect reconstruction of the complex anatomical structures present in most medical images. This method also fails to detect anomalies that are not characterized by large intensity differences to the surrounding tissue. We propose to tackle this problem using a feature-mapping function that transforms the input intensity images into a space with multiple channels where anomalies can be detected along different discriminative feature maps extracted from the original image. We then train an Autoencoder model in this space using structural similarity loss that does not only consider differences in intensity but also in contrast and structure. Our method significantly increases performance on two medical data sets for brain MRI. Code and experiments are available at https://github.com/FeliMe/feature-autoencoder
Improved post-hoc probability calibration for out-of-domain MRI segmentation
Aug 04, 2022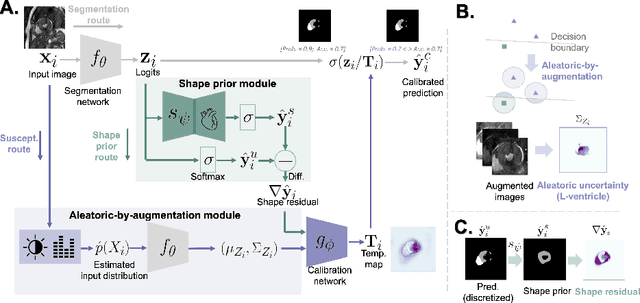
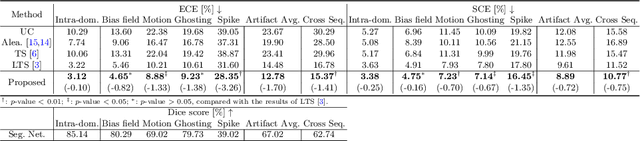

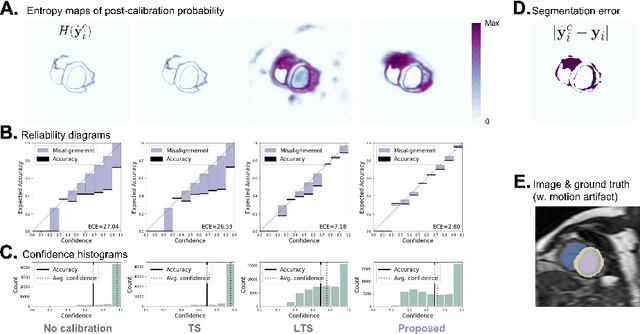
Probability calibration for deep models is highly desirable in safety-critical applications such as medical imaging. It makes output probabilities of deep networks interpretable, by aligning prediction probabilities with the actual accuracy in test data. In image segmentation, well-calibrated probabilities allow radiologists to identify regions where model-predicted segmentations are unreliable. These unreliable predictions often occur to out-of-domain (OOD) images that are caused by imaging artifacts or unseen imaging protocols. Unfortunately, most previous calibration methods for image segmentation perform sub-optimally on OOD images. To reduce the calibration error when confronted with OOD images, we propose a novel post-hoc calibration model. Our model leverages the pixel susceptibility against perturbations at the local level, and the shape prior information at the global level. The model is tested on cardiac MRI segmentation datasets that contain unseen imaging artifacts and images from an unseen imaging protocol. We demonstrate reduced calibration errors compared with the state-of-the-art calibration algorithm.
Metadata-enhanced contrastive learning from retinal optical coherence tomography images
Aug 04, 2022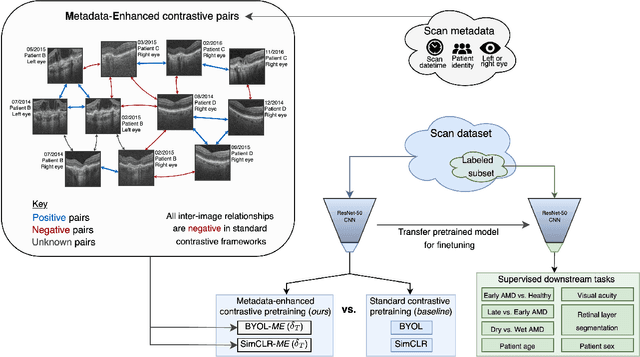
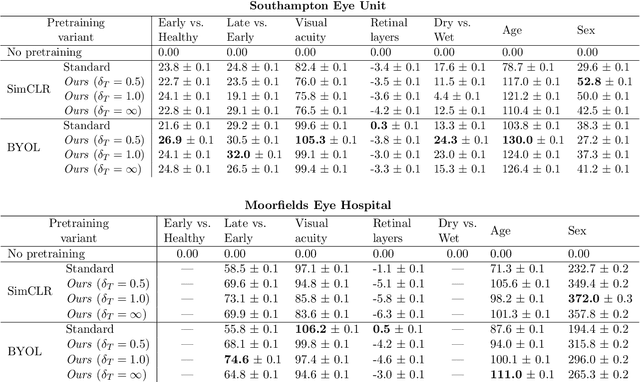
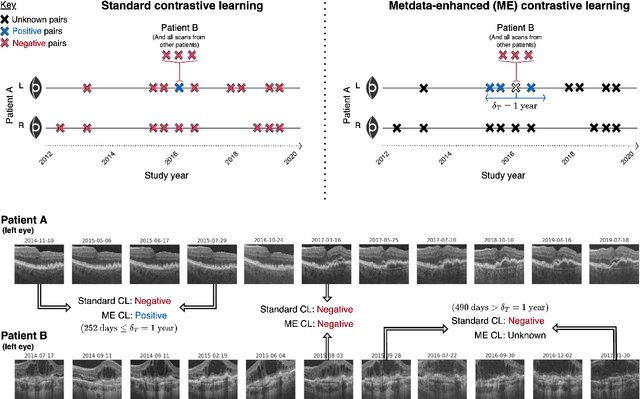
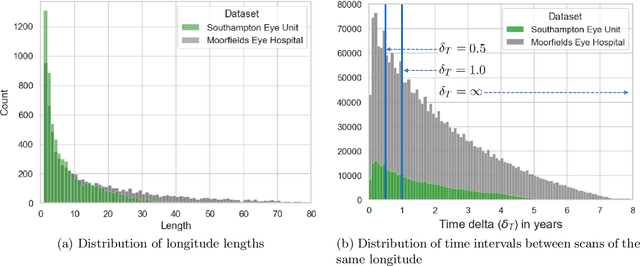
Supervised deep learning algorithms hold great potential to automate screening, monitoring and grading of medical images. However, training performant models has typically required vast quantities of labelled data, which is scarcely available in the medical domain. Self-supervised contrastive frameworks relax this dependency by first learning from unlabelled images. In this work we show that pretraining with two contrastive methods, SimCLR and BYOL, improves the utility of deep learning with regard to the clinical assessment of age-related macular degeneration (AMD). In experiments using two large clinical datasets containing 170,427 optical coherence tomography (OCT) images of 7,912 patients, we evaluate benefits attributed to pretraining across seven downstream tasks ranging from AMD stage and type classification to prediction of functional endpoints to segmentation of retinal layers, finding performance significantly increased in six out of seven tasks with fewer labels. However, standard contrastive frameworks have two known weaknesses that are detrimental to pretraining in the medical domain. Several of the image transformations used to create positive contrastive pairs are not applicable to greyscale medical scans. Furthermore, medical images often depict the same anatomical region and disease severity, resulting in numerous misleading negative pairs. To address these issues we develop a novel metadata-enhanced approach that exploits the rich set of inherently available patient information. To this end we employ records for patient identity, eye position (i.e. left or right) and time series data to indicate the typically unknowable set of inter-image contrastive relationships. By leveraging this often neglected information our metadata-enhanced contrastive pretraining leads to further benefits and outperforms conventional contrastive methods in five out of seven downstream tasks.
MulViMotion: Shape-aware 3D Myocardial Motion Tracking from Multi-View Cardiac MRI
Jul 29, 2022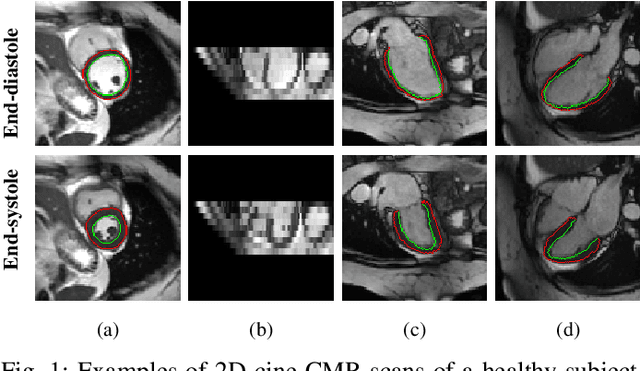
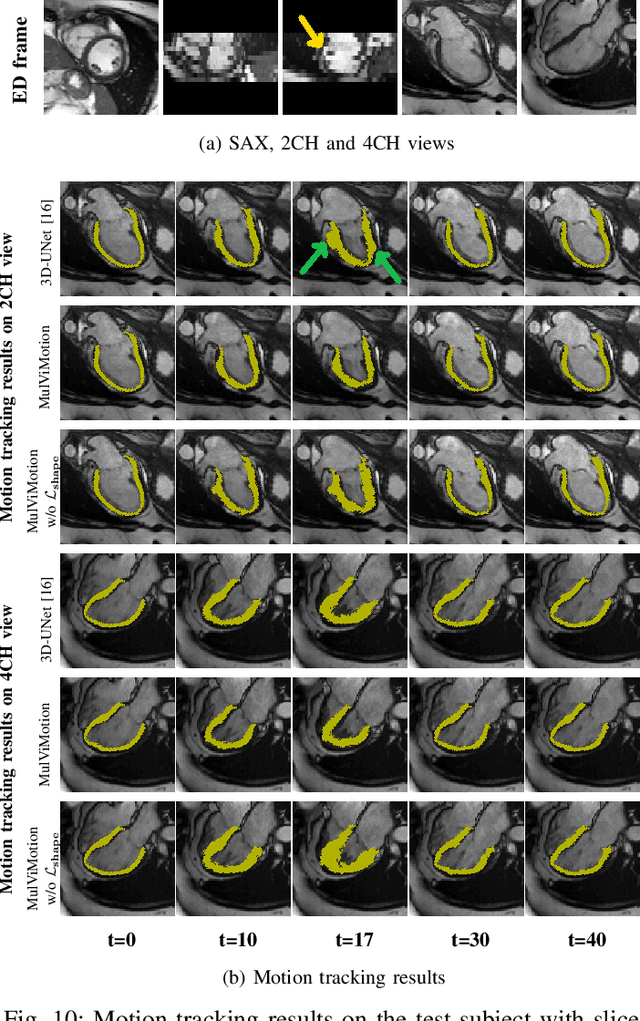
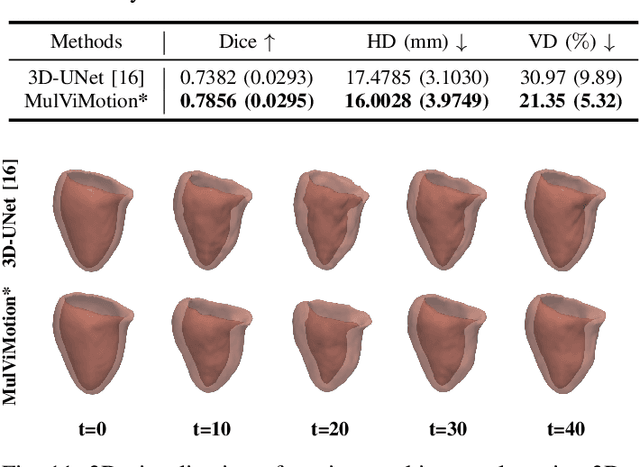
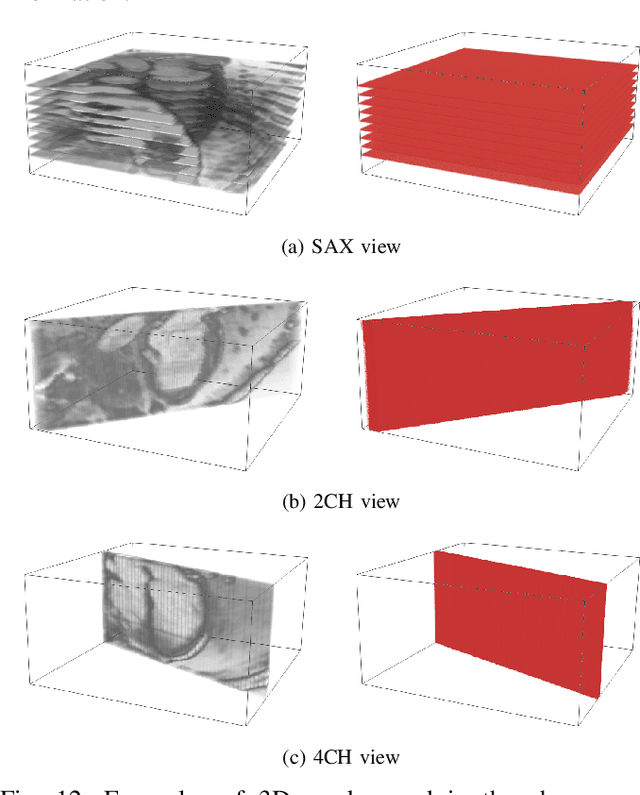
Recovering the 3D motion of the heart from cine cardiac magnetic resonance (CMR) imaging enables the assessment of regional myocardial function and is important for understanding and analyzing cardiovascular disease. However, 3D cardiac motion estimation is challenging because the acquired cine CMR images are usually 2D slices which limit the accurate estimation of through-plane motion. To address this problem, we propose a novel multi-view motion estimation network (MulViMotion), which integrates 2D cine CMR images acquired in short-axis and long-axis planes to learn a consistent 3D motion field of the heart. In the proposed method, a hybrid 2D/3D network is built to generate dense 3D motion fields by learning fused representations from multi-view images. To ensure that the motion estimation is consistent in 3D, a shape regularization module is introduced during training, where shape information from multi-view images is exploited to provide weak supervision to 3D motion estimation. We extensively evaluate the proposed method on 2D cine CMR images from 580 subjects of the UK Biobank study for 3D motion tracking of the left ventricular myocardium. Experimental results show that the proposed method quantitatively and qualitatively outperforms competing methods.
Physiology-based simulation of the retinal vasculature enables annotation-free segmentation of OCT angiographs
Jul 22, 2022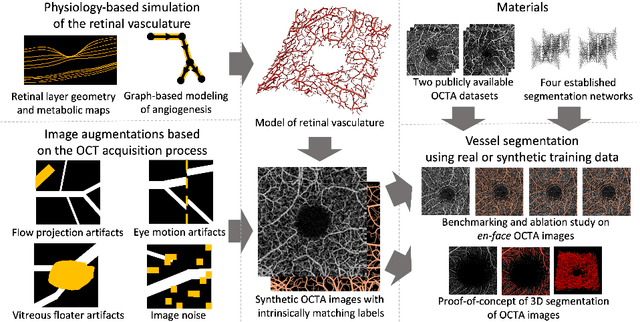
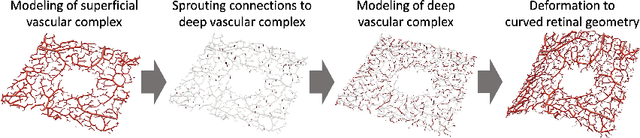
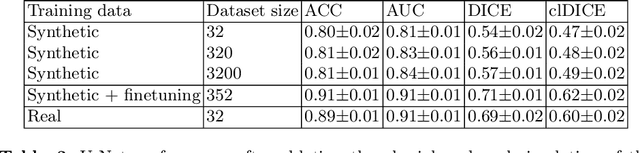
Optical coherence tomography angiography (OCTA) can non-invasively image the eye's circulatory system. In order to reliably characterize the retinal vasculature, there is a need to automatically extract quantitative metrics from these images. The calculation of such biomarkers requires a precise semantic segmentation of the blood vessels. However, deep-learning-based methods for segmentation mostly rely on supervised training with voxel-level annotations, which are costly to obtain. In this work, we present a pipeline to synthesize large amounts of realistic OCTA images with intrinsically matching ground truth labels; thereby obviating the need for manual annotation of training data. Our proposed method is based on two novel components: 1) a physiology-based simulation that models the various retinal vascular plexuses and 2) a suite of physics-based image augmentations that emulate the OCTA image acquisition process including typical artifacts. In extensive benchmarking experiments, we demonstrate the utility of our synthetic data by successfully training retinal vessel segmentation algorithms. Encouraged by our method's competitive quantitative and superior qualitative performance, we believe that it constitutes a versatile tool to advance the quantitative analysis of OCTA images.
Placenta Segmentation in Ultrasound Imaging: Addressing Sources of Uncertainty and Limited Field-of-View
Jun 29, 2022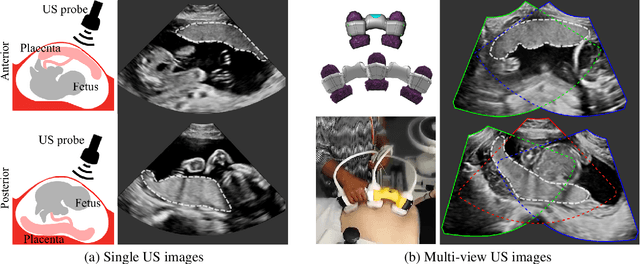
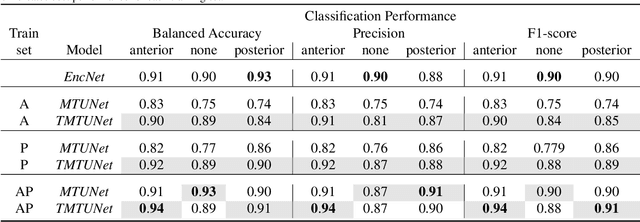
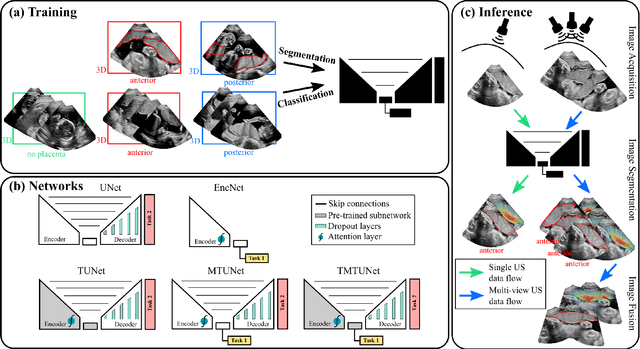
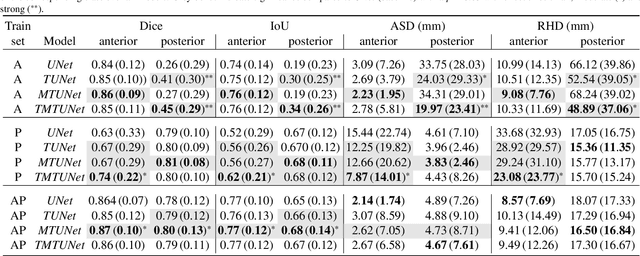
Automatic segmentation of the placenta in fetal ultrasound (US) is challenging due to the (i) high diversity of placenta appearance, (ii) the restricted quality in US resulting in highly variable reference annotations, and (iii) the limited field-of-view of US prohibiting whole placenta assessment at late gestation. In this work, we address these three challenges with a multi-task learning approach that combines the classification of placental location (e.g., anterior, posterior) and semantic placenta segmentation in a single convolutional neural network. Through the classification task the model can learn from larger and more diverse datasets while improving the accuracy of the segmentation task in particular in limited training set conditions. With this approach we investigate the variability in annotations from multiple raters and show that our automatic segmentations (Dice of 0.86 for anterior and 0.83 for posterior placentas) achieve human-level performance as compared to intra- and inter-observer variability. Lastly, our approach can deliver whole placenta segmentation using a multi-view US acquisition pipeline consisting of three stages: multi-probe image acquisition, image fusion and image segmentation. This results in high quality segmentation of larger structures such as the placenta in US with reduced image artifacts which are beyond the field-of-view of single probes.