 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlacenta Segmentation in Ultrasound Imaging: Addressing Sources of Uncertainty and Limited Field-of-View
Jun 29, 2022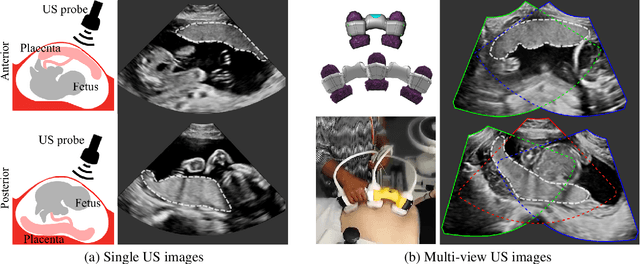
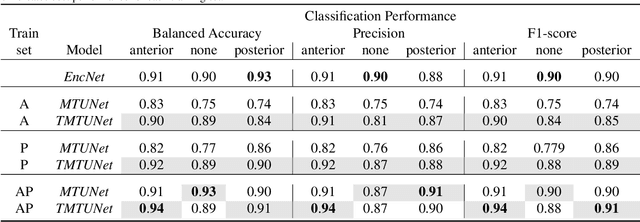
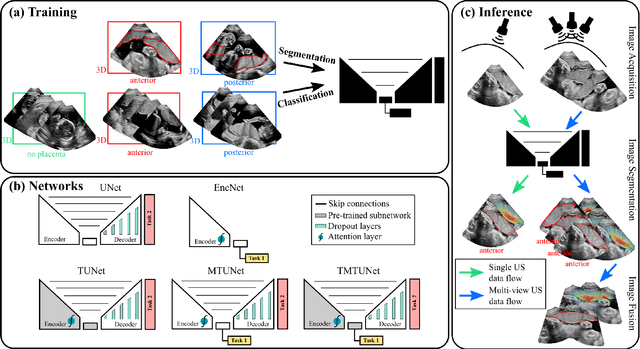
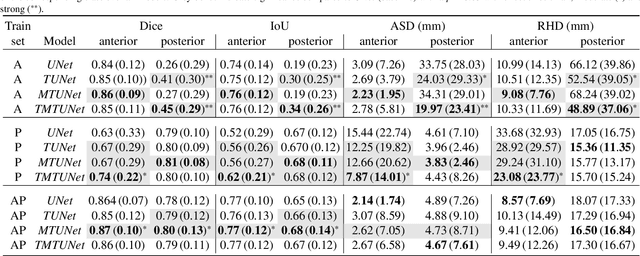
Automatic segmentation of the placenta in fetal ultrasound (US) is challenging due to the (i) high diversity of placenta appearance, (ii) the restricted quality in US resulting in highly variable reference annotations, and (iii) the limited field-of-view of US prohibiting whole placenta assessment at late gestation. In this work, we address these three challenges with a multi-task learning approach that combines the classification of placental location (e.g., anterior, posterior) and semantic placenta segmentation in a single convolutional neural network. Through the classification task the model can learn from larger and more diverse datasets while improving the accuracy of the segmentation task in particular in limited training set conditions. With this approach we investigate the variability in annotations from multiple raters and show that our automatic segmentations (Dice of 0.86 for anterior and 0.83 for posterior placentas) achieve human-level performance as compared to intra- and inter-observer variability. Lastly, our approach can deliver whole placenta segmentation using a multi-view US acquisition pipeline consisting of three stages: multi-probe image acquisition, image fusion and image segmentation. This results in high quality segmentation of larger structures such as the placenta in US with reduced image artifacts which are beyond the field-of-view of single probes.
Can non-specialists provide high quality gold standard labels in challenging modalities?
Jul 30, 2021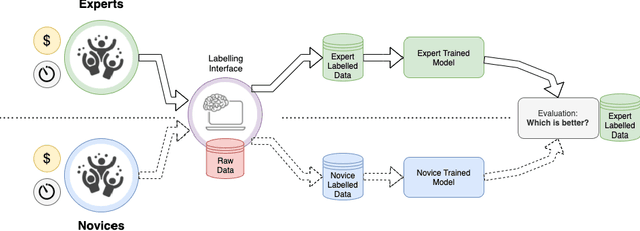
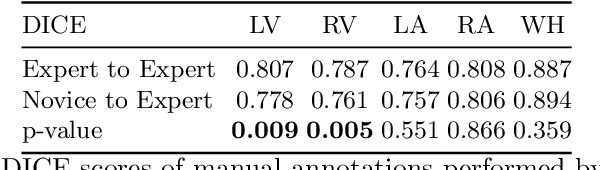
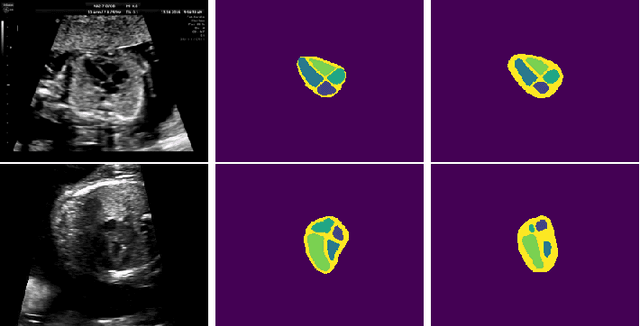
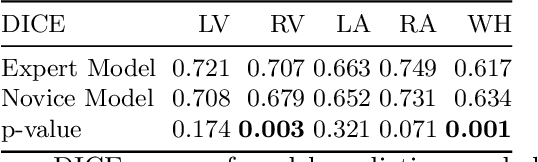
Probably yes. -- Supervised Deep Learning dominates performance scores for many computer vision tasks and defines the state-of-the-art. However, medical image analysis lags behind natural image applications. One of the many reasons is the lack of well annotated medical image data available to researchers. One of the first things researchers are told is that we require significant expertise to reliably and accurately interpret and label such data. We see significant inter- and intra-observer variability between expert annotations of medical images. Still, it is a widely held assumption that novice annotators are unable to provide useful annotations for use by clinical Deep Learning models. In this work we challenge this assumption and examine the implications of using a minimally trained novice labelling workforce to acquire annotations for a complex medical image dataset. We study the time and cost implications of using novice annotators, the raw performance of novice annotators compared to gold-standard expert annotators, and the downstream effects on a trained Deep Learning segmentation model's performance for detecting a specific congenital heart disease (hypoplastic left heart syndrome) in fetal ultrasound imaging.