 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robust Cross-View Consistency in Self-Supervised Monocular Depth Estimation
Sep 19, 2022
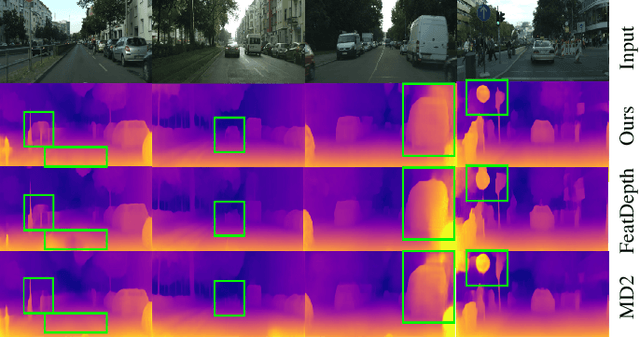
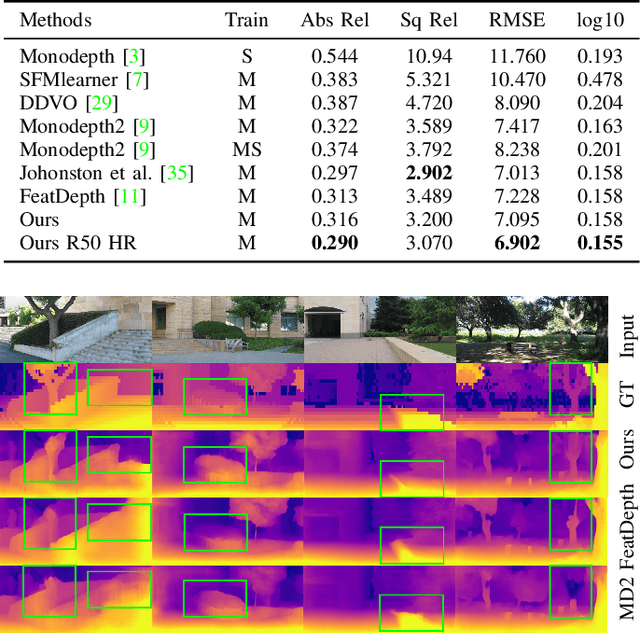
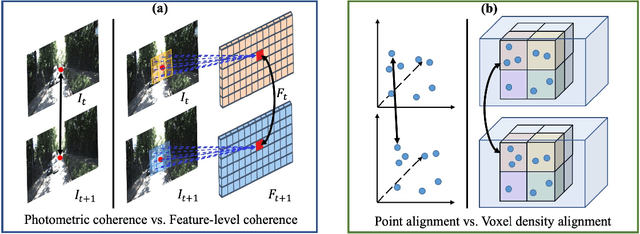
Remarkable progress has been made in self-supervised monocular depth estimation (SS-MDE) by exploring cross-view consistency, e.g., photometric consistency and 3D point cloud consistency. However, they are very vulnerable to illumination variance, occlusions, texture-less regions, as well as moving objects, making them not robust enough to deal with various scenes. To address this challenge, we study two kinds of robust cross-view consistency in this paper. Firstly, the spatial offset field between adjacent frames is obtained by reconstructing the reference frame from its neighbors via deformable alignment, which is used to align the temporal depth features via a Depth Feature Alignment (DFA) loss. Secondly, the 3D point clouds of each reference frame and its nearby frames are calculated and transformed into voxel space, where the point density in each voxel is calculated and aligned via a Voxel Density Alignment (VDA) loss. In this way, we exploit the temporal coherence in both depth feature space and 3D voxel space for SS-MDE, shifting the "point-to-point" alignment paradigm to the "region-to-region" one. Compared with the photometric consistency loss as well as the rigid point cloud alignment loss, the proposed DFA and VDA losses are more robust owing to the strong representation power of deep features as well as the high tolerance of voxel density to the aforementioned challenges. Experimental results on several outdoor benchmarks show that our method outperforms current state-of-the-art techniques. Extensive ablation study and analysis validate the effectiveness of the proposed losses, especially in challenging scenes. The code and models are available at https://github.com/sunnyHelen/RCVC-depth.
On the Complementarity between Pre-Training and Random-Initialization for Resource-Rich Machine Translation
Sep 15, 2022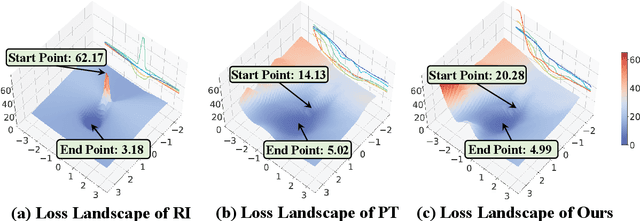
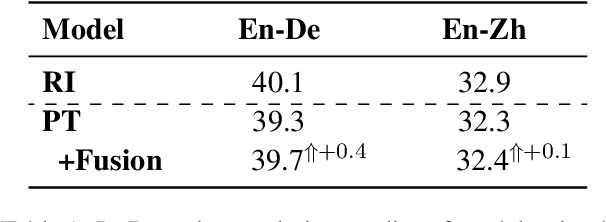
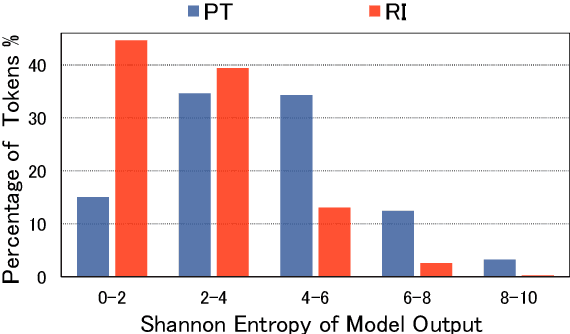
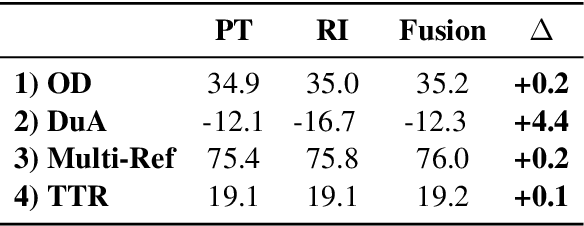
Pre-Training (PT) of text representations has been successfully applied to low-resource Neural Machine Translation (NMT). However, it usually fails to achieve notable gains (sometimes, even worse) on resource-rich NMT on par with its Random-Initialization (RI) counterpart. We take the first step to investigate the complementarity between PT and RI in resource-rich scenarios via two probing analyses, and find that: 1) PT improves NOT the accuracy, but the generalization by achieving flatter loss landscapes than that of RI; 2) PT improves NOT the confidence of lexical choice, but the negative diversity by assigning smoother lexical probability distributions than that of RI. Based on these insights, we propose to combine their complementarities with a model fusion algorithm that utilizes optimal transport to align neurons between PT and RI. Experiments on two resource-rich translation benchmarks, WMT'17 English-Chinese (20M) and WMT'19 English-German (36M), show that PT and RI could be nicely complementary to each other, achieving substantial improvements considering both translation accuracy, generalization, and negative diversity. Probing tools and code are released at: https://github.com/zanchangtong/PTvsRI.
Not All Instances Contribute Equally: Instance-adaptive Class Representation Learning for Few-Shot Visual Recognition
Sep 07, 2022
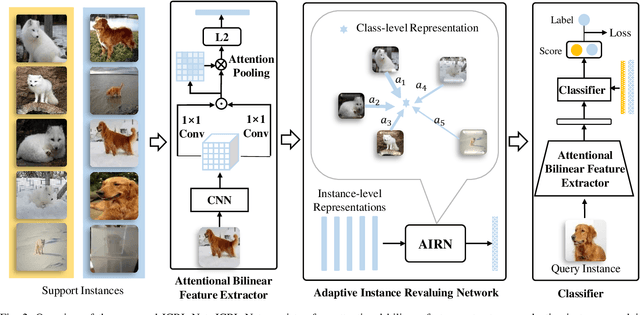
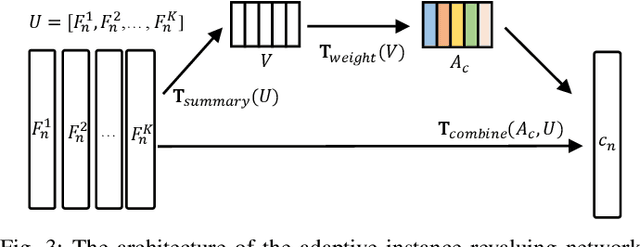
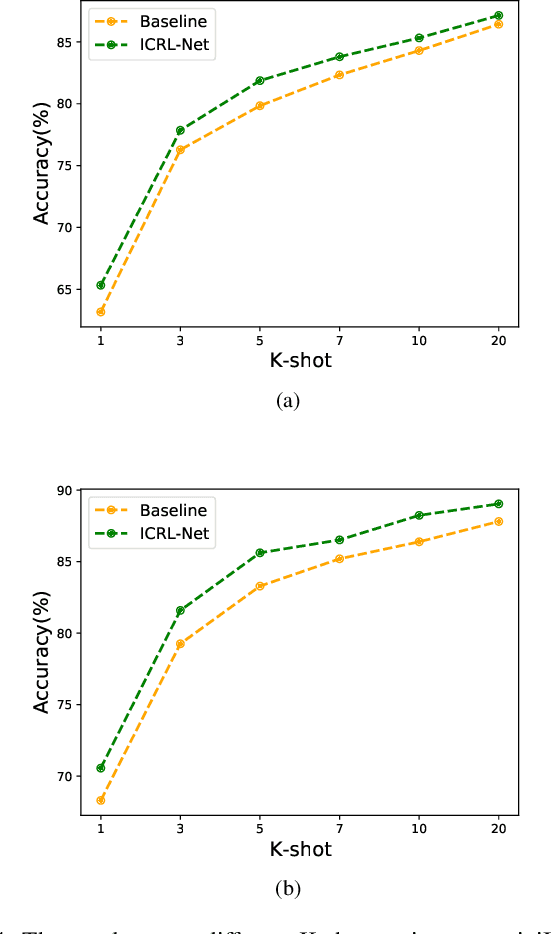
Few-shot visual recognition refers to recognize novel visual concepts from a few labeled instances. Many few-shot visual recognition methods adopt the metric-based meta-learning paradigm by comparing the query representation with class representations to predict the category of query instance. However, current metric-based methods generally treat all instances equally and consequently often obtain biased class representation, considering not all instances are equally significant when summarizing the instance-level representations for the class-level representation. For example, some instances may contain unrepresentative information, such as too much background and information of unrelated concepts, which skew the results. To address the above issues, we propose a novel metric-based meta-learning framework termed instance-adaptive class representation learning network (ICRL-Net) for few-shot visual recognition. Specifically, we develop an adaptive instance revaluing network with the capability to address the biased representation issue when generating the class representation, by learning and assigning adaptive weights for different instances according to their relative significance in the support set of corresponding class. Additionally, we design an improved bilinear instance representation and incorporate two novel structural losses, i.e., intra-class instance clustering loss and inter-class representation distinguishing loss, to further regulate the instance revaluation process and refine the class representation. We conduct extensive experiments on four commonly adopted few-shot benchmarks: miniImageNet, tieredImageNet, CIFAR-FS, and FC100 datasets. The experimental results compared with the state-of-the-art approaches demonstrate the superiority of our ICRL-Net.
Super-model ecosystem: A domain-adaptation perspective
Aug 30, 2022
This paper attempts to establish the theoretical foundation for the emerging super-model paradigm via domain adaptation, where one first trains a very large-scale model, {\it i.e.}, super model (or foundation model in some other papers), on a large amount of data and then adapts it to various specific domains. Super-model paradigms help reduce computational and data cost and carbon emission, which is critical to AI industry, especially enormous small and medium-sized enterprises. We model the super-model paradigm as a two-stage diffusion process: (1) in the pre-training stage, the model parameter diffuses from random initials and converges to a steady distribution; and (2) in the fine-tuning stage, the model parameter is transported to another steady distribution. Both training stages can be mathematically modeled by the Uhlenbeck-Ornstein process which converges to two Maxwell-Boltzmann distributions, respectively, each of which characterizes the corresponding convergent model. An $\mathcal O(1/\sqrt{N})$ generalization bound is then established via PAC-Bayesian framework. The theory finds that the generalization error of the fine-tuning stage is dominant in domain adaptation. In addition, our theory suggests that the generalization is determined by a new measure that characterizes the domain discrepancy between the source domain and target domain, based on the covariance matrices and the shift of the converged local minimum.
Symmetric Pruning in Quantum Neural Networks
Aug 30, 2022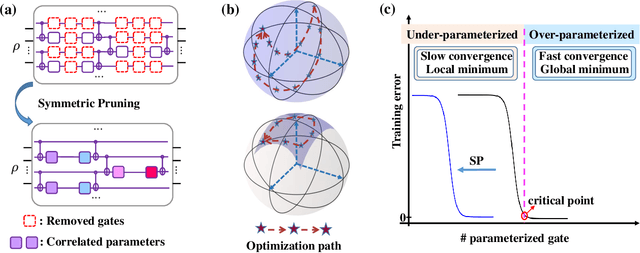
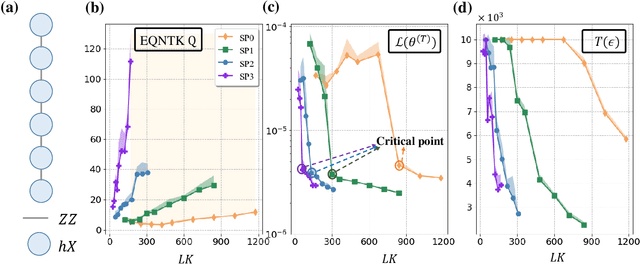
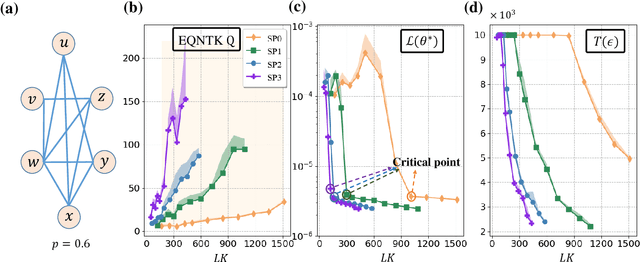
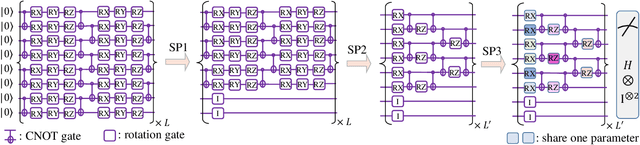
Many fundamental properties of a quantum system are captured by its Hamiltonian and ground state. Despite the significance of ground states preparation (GSP), this task is classically intractable for large-scale Hamiltonians. Quantum neural networks (QNNs), which exert the power of modern quantum machines, have emerged as a leading protocol to conquer this issue. As such, how to enhance the performance of QNNs becomes a crucial topic in GSP. Empirical evidence showed that QNNs with handcraft symmetric ansatzes generally experience better trainability than those with asymmetric ansatzes, while theoretical explanations have not been explored. To fill this knowledge gap, here we propose the effective quantum neural tangent kernel (EQNTK) and connect this concept with over-parameterization theory to quantify the convergence of QNNs towards the global optima. We uncover that the advance of symmetric ansatzes attributes to their large EQNTK value with low effective dimension, which requests few parameters and quantum circuit depth to reach the over-parameterization regime permitting a benign loss landscape and fast convergence. Guided by EQNTK, we further devise a symmetric pruning (SP) scheme to automatically tailor a symmetric ansatz from an over-parameterized and asymmetric one to greatly improve the performance of QNNs when the explicit symmetry information of Hamiltonian is unavailable. Extensive numerical simulations are conducted to validate the analytical results of EQNTK and the effectiveness of SP.
Grounded Affordance from Exocentric View
Aug 28, 2022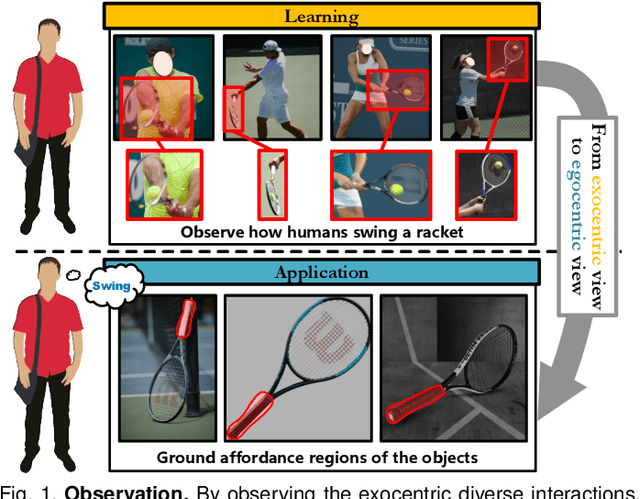
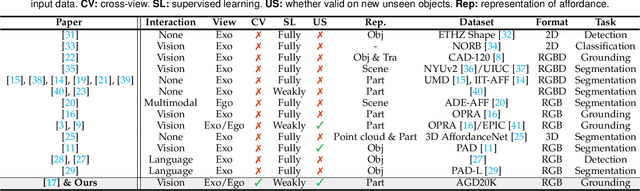


Affordance grounding aims to locate objects' "action possibilities" regions, which is an essential step toward embodied intelligence. Due to the diversity of interactive affordance, the uniqueness of different individuals leads to diverse interactions, which makes it difficult to establish an explicit link between object parts and affordance labels. Human has the ability that transforms the various exocentric interactions into invariant egocentric affordance to counter the impact of interactive diversity. To empower an agent with such ability, this paper proposes a task of affordance grounding from exocentric view, i.e., given exocentric human-object interaction and egocentric object images, learning the affordance knowledge of the object and transferring it to the egocentric image using only the affordance label as supervision. However, there is some "interaction bias" between personas, mainly regarding different regions and different views. To this end, we devise a cross-view affordance knowledge transfer framework that extracts affordance-specific features from exocentric interactions and transfers them to the egocentric view. Specifically, the perception of affordance regions is enhanced by preserving affordance co-relations. In addition, an affordance grounding dataset named AGD20K is constructed by collecting and labeling over 20K images from $36$ affordance categories. Experimental results demonstrate that our method outperforms the representative models regarding objective metrics and visual quality. Code is released at https://github.com/lhc1224/Cross-view-affordance-grounding.
Shortcut Learning of Large Language Models in Natural Language Understanding: A Survey
Aug 25, 2022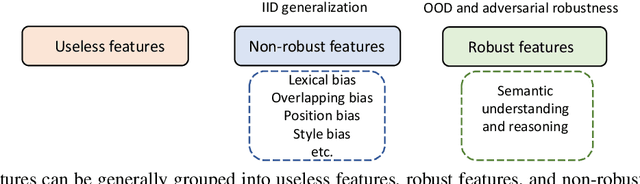

Large language models (LLMs) have achieved state-of-the-art performance on a series of natural language understanding tasks. However, these LLMs might rely on dataset bias and artifacts as shortcuts for prediction. This has significantly hurt their Out-of-Distribution (OOD) generalization and adversarial robustness. In this paper, we provide a review of recent developments that address the robustness challenge of LLMs. We first introduce the concepts and robustness challenge of LLMs. We then introduce methods to identify shortcut learning behavior in LLMs, characterize the reasons for shortcut learning, as well as introduce mitigation solutions. Finally, we identify key challenges and introduce the connections of this line of research to other directions.
Domain-Specific Risk Minimization
Aug 23, 2022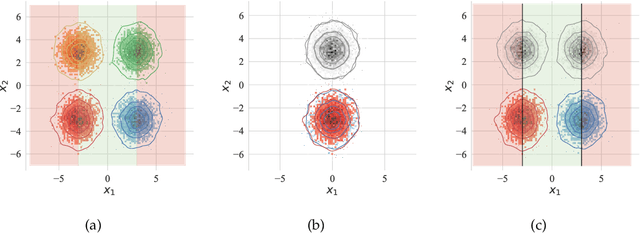
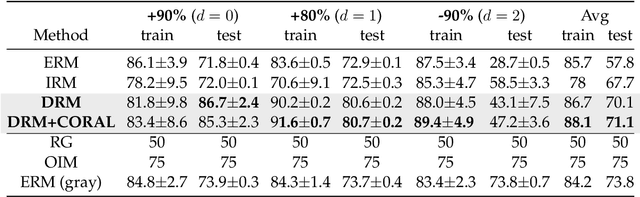
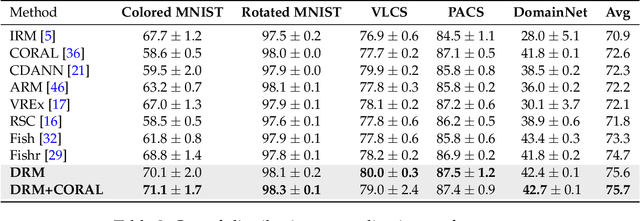
Learning a domain-invariant representation has become one of the most popular approaches for domain adaptation/generalization. In this paper, we show that the invariant representation may not be sufficient to guarantee a good generalization, where the labeling function shift should be taken into consideration. Inspired by this, we first derive a new generalization upper bound on the empirical risk that explicitly considers the labeling function shift. We then propose Domain-specific Risk Minimization (DRM), which can model the distribution shifts of different domains separately and select the most appropriate one for the target domain. Extensive experiments on four popular domain generalization datasets, CMNIST, PACS, VLCS, and DomainNet, demonstrate the effectiveness of the proposed DRM for domain generalization with the following advantages: 1) it significantly outperforms competitive baselines; 2) it enables either comparable or superior accuracies on all training domains comparing to vanilla empirical risk minimization (ERM); 3) it remains very simple and efficient during training, and 4) it is complementary to invariant learning approaches.
Hierarchical Perceptual Noise Injection for Social Media Fingerprint Privacy Protection
Aug 23, 2022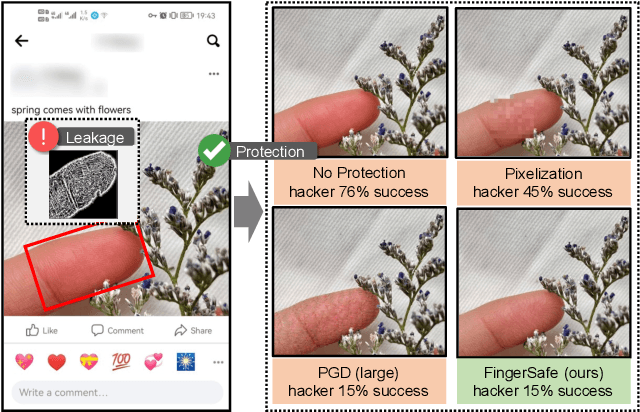
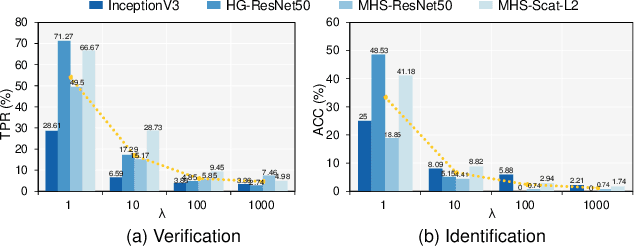
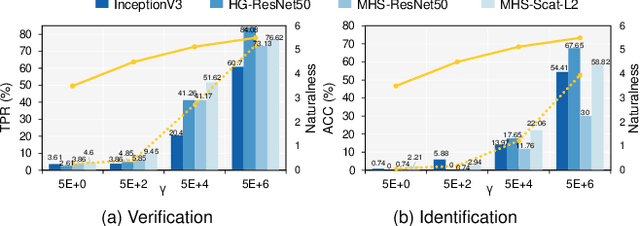
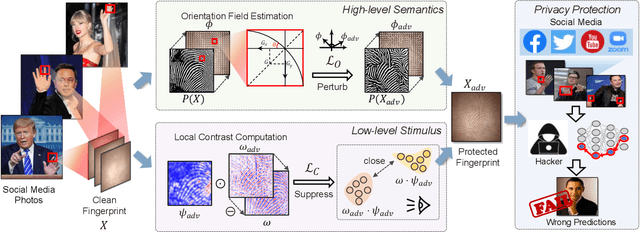
Billions of people are sharing their daily life images on social media every day. However, their biometric information (e.g., fingerprint) could be easily stolen from these images. The threat of fingerprint leakage from social media raises a strong desire for anonymizing shared images while maintaining image qualities, since fingerprints act as a lifelong individual biometric password. To guard the fingerprint leakage, adversarial attack emerges as a solution by adding imperceptible perturbations on images. However, existing works are either weak in black-box transferability or appear unnatural. Motivated by visual perception hierarchy (i.e., high-level perception exploits model-shared semantics that transfer well across models while low-level perception extracts primitive stimulus and will cause high visual sensitivities given suspicious stimulus), we propose FingerSafe, a hierarchical perceptual protective noise injection framework to address the mentioned problems. For black-box transferability, we inject protective noises on fingerprint orientation field to perturb the model-shared high-level semantics (i.e., fingerprint ridges). Considering visual naturalness, we suppress the low-level local contrast stimulus by regularizing the response of Lateral Geniculate Nucleus. Our FingerSafe is the first to provide feasible fingerprint protection in both digital (up to 94.12%) and realistic scenarios (Twitter and Facebook, up to 68.75%). Our code can be found at https://github.com/nlsde-safety-team/FingerSafe.
PANDA: Prompt Transfer Meets Knowledge Distillation for Efficient Model Adaptation
Aug 22, 2022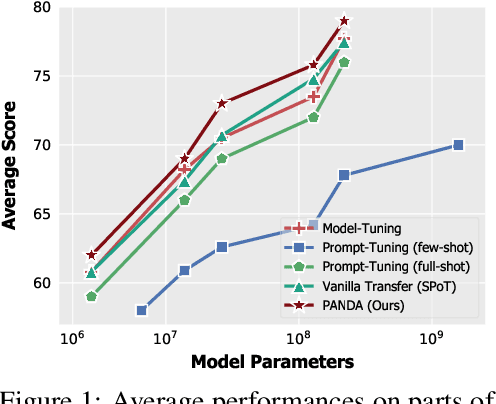
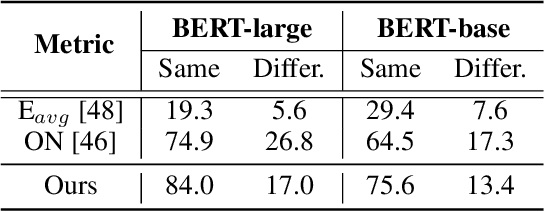
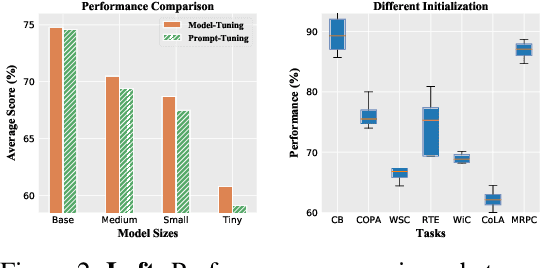
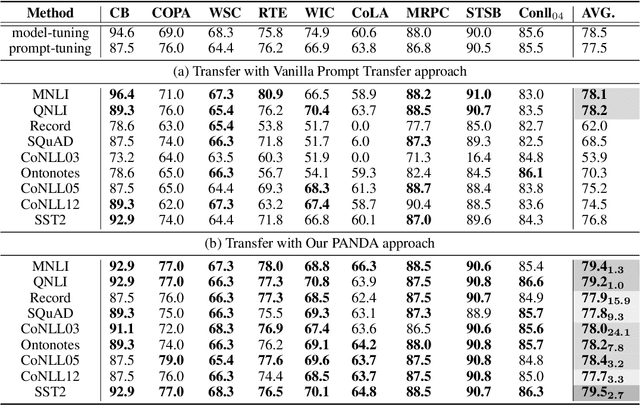
Prompt-tuning, which freezes pretrained language models (PLMs) and only fine-tunes few parameters of additional soft prompt, shows competitive performance against full-parameter fine-tuning (i.e.model-tuning) when the PLM has billions of parameters, but still performs poorly in the case of smaller PLMs. Hence, prompt transfer (PoT), which initializes the target prompt with the trained prompt of similar source tasks, is recently proposed to improve over prompt-tuning. However, such a vanilla PoT approach usually achieves sub-optimal performance, as (i) the PoT is sensitive to the similarity of source-target pair and (ii) directly fine-tuning the prompt initialized with source prompt on target task might lead to catastrophic forgetting of source knowledge. In response to these problems, we propose a new metric to accurately predict the prompt transferability (regarding (i)), and a novel PoT approach (namely PANDA) that leverages the knowledge distillation technique to transfer the "knowledge" from the source prompt to the target prompt in a subtle manner and alleviate the catastrophic forgetting effectively (regarding (ii)). Furthermore, to achieve adaptive prompt transfer for each source-target pair, we use our metric to control the knowledge transfer in our PANDA approach. Extensive and systematic experiments on 189 combinations of 21 source and 9 target datasets across 5 scales of PLMs demonstrate that: 1) our proposed metric works well to predict the prompt transferability; 2) our PANDA consistently outperforms the vanilla PoT approach by 2.3% average score (up to 24.1%) among all tasks and model sizes; 3) with our PANDA approach, prompt-tuning can achieve competitive and even better performance than model-tuning in various PLM scales scenarios. Code and models will be released upon acceptance.