 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClusIR: Towards Cluster-Guided All-in-One Image Restoration
Dec 11, 2025All-in-One Image Restoration (AiOIR) aims to recover high-quality images from diverse degradations within a unified framework. However, existing methods often fail to explicitly model degradation types and struggle to adapt their restoration behavior to complex or mixed degradations. To address these issues, we propose ClusIR, a Cluster-Guided Image Restoration framework that explicitly models degradation semantics through learnable clustering and propagates cluster-aware cues across spatial and frequency domains for adaptive restoration. Specifically, ClusIR comprises two key components: a Probabilistic Cluster-Guided Routing Mechanism (PCGRM) and a Degradation-Aware Frequency Modulation Module (DAFMM). The proposed PCGRM disentangles degradation recognition from expert activation, enabling discriminative degradation perception and stable expert routing. Meanwhile, DAFMM leverages the cluster-guided priors to perform adaptive frequency decomposition and targeted modulation, collaboratively refining structural and textural representations for higher restoration fidelity. The cluster-guided synergy seamlessly bridges semantic cues with frequency-domain modulation, empowering ClusIR to attain remarkable restoration results across a wide range of degradations. Extensive experiments on diverse benchmarks validate that ClusIR reaches competitive performance under several scenarios.
Drawback of Enforcing Equivariance and its Compensation via the Lens of Expressive Power
Dec 10, 2025Equivariant neural networks encode symmetry as an inductive bias and have achieved strong empirical performance in wide domains. However, their expressive power remains not well understood. Focusing on 2-layer ReLU networks, this paper investigates the impact of equivariance constraints on the expressivity of equivariant and layer-wise equivariant networks. By examining the boundary hyperplanes and the channel vectors of ReLU networks, we construct an example showing that equivariance constraints could strictly limit expressive power. However, we demonstrate that this drawback can be compensated via enlarging the model size. Furthermore, we show that despite a larger model size, the resulting architecture could still correspond to a hypothesis space with lower complexity, implying superior generalizability for equivariant networks.
Free-Form Scene Editor: Enabling Multi-Round Object Manipulation like in a 3D Engine
Nov 17, 2025Recent advances in text-to-image (T2I) diffusion models have significantly improved semantic image editing, yet most methods fall short in performing 3D-aware object manipulation. In this work, we present FFSE, a 3D-aware autoregressive framework designed to enable intuitive, physically-consistent object editing directly on real-world images. Unlike previous approaches that either operate in image space or require slow and error-prone 3D reconstruction, FFSE models editing as a sequence of learned 3D transformations, allowing users to perform arbitrary manipulations, such as translation, scaling, and rotation, while preserving realistic background effects (e.g., shadows, reflections) and maintaining global scene consistency across multiple editing rounds. To support learning of multi-round 3D-aware object manipulation, we introduce 3DObjectEditor, a hybrid dataset constructed from simulated editing sequences across diverse objects and scenes, enabling effective training under multi-round and dynamic conditions. Extensive experiments show that the proposed FFSE significantly outperforms existing methods in both single-round and multi-round 3D-aware editing scenarios.
Reason-KE++: Aligning the Process, Not Just the Outcome, for Faithful LLM Knowledge Editing
Nov 16, 2025



Aligning Large Language Models (LLMs) to be faithful to new knowledge in complex, multi-hop reasoning tasks is a critical, yet unsolved, challenge. We find that SFT-based methods, e.g., Reason-KE, while state-of-the-art, suffer from a "faithfulness gap": they optimize for format mimicry rather than sound reasoning. This gap enables the LLM's powerful parametric priors to override new contextual facts, resulting in critical factual hallucinations (e.g., incorrectly reasoning "Houston" from "NASA" despite an explicit edit). To solve this core LLM alignment problem, we propose Reason-KE++, an SFT+RL framework that instills process-level faithfulness. Its core is a Stage-aware Reward mechanism that provides dense supervision for intermediate reasoning steps (e.g., Decomposition, Sub-answer Correctness). Crucially, we identify that naive outcome-only RL is a deceptive trap for LLM alignment: it collapses reasoning integrity (e.g., 19.00% Hop acc) while superficially boosting final accuracy. Our process-aware framework sets a new SOTA of 95.48% on MQUAKE-CF-3k (+5.28%), demonstrating that for complex tasks, aligning the reasoning process is essential for building trustworthy LLMs.
Sparse by Rule: Probability-Based N:M Pruning for Spiking Neural Networks
Nov 15, 2025Brain-inspired Spiking neural networks (SNNs) promise energy-efficient intelligence via event-driven, sparse computation, but deeper architectures inflate parameters and computational cost, hindering their edge deployment. Recent progress in SNN pruning helps alleviate this burden, yet existing efforts fall into only two families: \emph{unstructured} pruning, which attains high sparsity but is difficult to accelerate on general hardware, and \emph{structured} pruning, which eases deployment but lack flexibility and often degrades accuracy at matched sparsity. In this work, we introduce \textbf{SpikeNM}, the first SNN-oriented \emph{semi-structured} \(N{:}M\) pruning framework that learns sparse SNNs \emph{from scratch}, enforcing \emph{at most \(N\)} non-zeros per \(M\)-weight block. To avoid the combinatorial space complexity \(\sum_{k=1}^{N}\binom{M}{k}\) growing exponentially with \(M\), SpikeNM adopts an \(M\)-way basis-logit parameterization with a differentiable top-\(k\) sampler, \emph{linearizing} per-block complexity to \(\mathcal O(M)\) and enabling more aggressive sparsification. Further inspired by neuroscience, we propose \emph{eligibility-inspired distillation} (EID), which converts temporally accumulated credits into block-wise soft targets to align mask probabilities with spiking dynamics, reducing sampling variance and stabilizing search under high sparsity. Experiments show that at \(2{:}4\) sparsity, SpikeNM maintains and even with gains across main-stream datasets, while yielding hardware-amenable patterns that complement intrinsic spike sparsity.
Hindsight Distillation Reasoning with Knowledge Encouragement Preference for Knowledge-based Visual Question Answering
Nov 14, 2025



Knowledge-based Visual Question Answering (KBVQA) necessitates external knowledge incorporation beyond cross-modal understanding. Existing KBVQA methods either utilize implicit knowledge in multimodal large language models (MLLMs) via in-context learning or explicit knowledge via retrieval augmented generation. However, their reasoning processes remain implicit, without explicit multi-step trajectories from MLLMs. To address this gap, we provide a Hindsight Distilled Reasoning (HinD) framework with Knowledge Encouragement Preference Optimization (KEPO), designed to elicit and harness internal knowledge reasoning ability in MLLMs. First, to tackle the reasoning supervision problem, we propose to emphasize the hindsight wisdom of MLLM by prompting a frozen 7B-size MLLM to complete the reasoning process between the question and its ground truth answer, constructing Hindsight-Zero training data. Then we self-distill Hindsight-Zero into Chain-of-Thought (CoT) Generator and Knowledge Generator, enabling the generation of sequential steps and discrete facts. Secondly, to tackle the misalignment between knowledge correctness and confidence, we optimize the Knowledge Generator with KEPO, preferring under-confident but helpful knowledge over the over-confident but unhelpful one. The generated CoT and sampled knowledge are then exploited for answer prediction. Experiments on OK-VQA and A-OKVQA validate the effectiveness of HinD, showing that HinD with elicited reasoning from 7B-size MLLM achieves superior performance without commercial model APIs or outside knowledge.
SWAP: Towards Copyright Auditing of Soft Prompts via Sequential Watermarking
Nov 05, 2025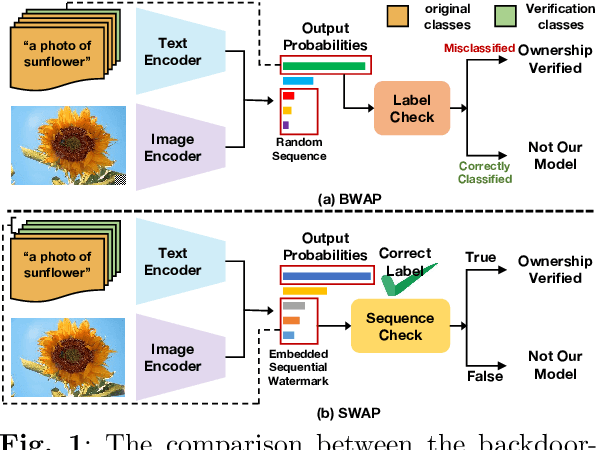
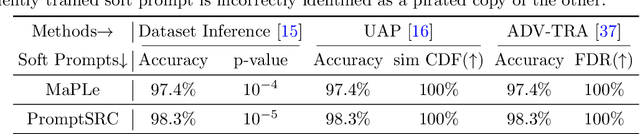
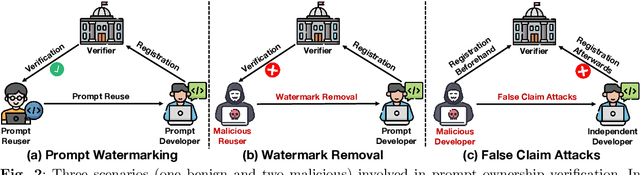
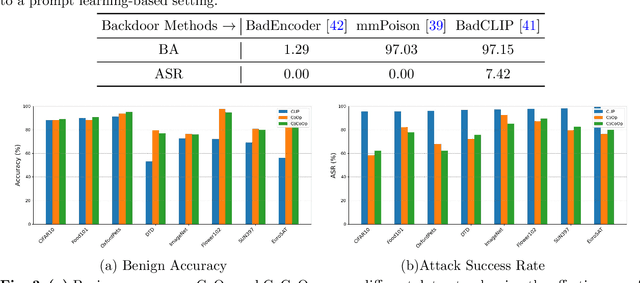
Large-scale vision-language models, especially CLIP, have demonstrated remarkable performance across diverse downstream tasks. Soft prompts, as carefully crafted modules that efficiently adapt vision-language models to specific tasks, necessitate effective copyright protection. In this paper, we investigate model copyright protection by auditing whether suspicious third-party models incorporate protected soft prompts. While this can be viewed as a special case of model ownership auditing, our analysis shows that existing techniques are ineffective due to prompt learning's unique characteristics. Non-intrusive auditing is inherently prone to false positives when independent models share similar data distributions with victim models. Intrusive approaches also fail: backdoor methods designed for CLIP cannot embed functional triggers, while extending traditional DNN backdoor techniques to prompt learning suffers from harmfulness and ambiguity challenges. We find that these failures in intrusive auditing stem from the same fundamental reason: watermarking operates within the same decision space as the primary task yet pursues opposing objectives. Motivated by these findings, we propose sequential watermarking for soft prompts (SWAP), which implants watermarks into a different and more complex space. SWAP encodes watermarks through a specific order of defender-specified out-of-distribution classes, inspired by the zero-shot prediction capability of CLIP. This watermark, which is embedded in a more complex space, keeps the original prediction label unchanged, making it less opposed to the primary task. We further design a hypothesis-test-guided verification protocol for SWAP and provide theoretical analyses of success conditions. Extensive experiments on 11 datasets demonstrate SWAP's effectiveness, harmlessness, and robustness against potential adaptive attacks.
Sparse Model Inversion: Efficient Inversion of Vision Transformers for Data-Free Applications
Oct 31, 2025



Model inversion, which aims to reconstruct the original training data from pre-trained discriminative models, is especially useful when the original training data is unavailable due to privacy, usage rights, or size constraints. However, existing dense inversion methods attempt to reconstruct the entire image area, making them extremely inefficient when inverting high-resolution images from large-scale Vision Transformers (ViTs). We further identify two underlying causes of this inefficiency: the redundant inversion of noisy backgrounds and the unintended inversion of spurious correlations--a phenomenon we term "hallucination" in model inversion. To address these limitations, we propose a novel sparse model inversion strategy, as a plug-and-play extension to speed up existing dense inversion methods with no need for modifying their original loss functions. Specifically, we selectively invert semantic foregrounds while stopping the inversion of noisy backgrounds and potential spurious correlations. Through both theoretical and empirical studies, we validate the efficacy of our approach in achieving significant inversion acceleration (up to 3.79 faster) while maintaining comparable or even enhanced downstream performance in data-free model quantization and data-free knowledge transfer. Code is available at https://github.com/Egg-Hu/SMI.
Adaptive Defense against Harmful Fine-Tuning for Large Language Models via Bayesian Data Scheduler
Oct 31, 2025Harmful fine-tuning poses critical safety risks to fine-tuning-as-a-service for large language models. Existing defense strategies preemptively build robustness via attack simulation but suffer from fundamental limitations: (i) the infeasibility of extending attack simulations beyond bounded threat models due to the inherent difficulty of anticipating unknown attacks, and (ii) limited adaptability to varying attack settings, as simulation fails to capture their variability and complexity. To address these challenges, we propose Bayesian Data Scheduler (BDS), an adaptive tuning-stage defense strategy with no need for attack simulation. BDS formulates harmful fine-tuning defense as a Bayesian inference problem, learning the posterior distribution of each data point's safety attribute, conditioned on the fine-tuning and alignment datasets. The fine-tuning process is then constrained by weighting data with their safety attributes sampled from the posterior, thus mitigating the influence of harmful data. By leveraging the post hoc nature of Bayesian inference, the posterior is conditioned on the fine-tuning dataset, enabling BDS to tailor its defense to the specific dataset, thereby achieving adaptive defense. Furthermore, we introduce a neural scheduler based on amortized Bayesian learning, enabling efficient transfer to new data without retraining. Comprehensive results across diverse attack and defense settings demonstrate the state-of-the-art performance of our approach. Code is available at https://github.com/Egg-Hu/Bayesian-Data-Scheduler.
Effective Policy Learning for Multi-Agent Online Coordination Beyond Submodular Objectives
Sep 26, 2025



In this paper, we present two effective policy learning algorithms for multi-agent online coordination(MA-OC) problem. The first one, \texttt{MA-SPL}, not only can achieve the optimal $(1-\frac{c}{e})$-approximation guarantee for the MA-OC problem with submodular objectives but also can handle the unexplored $\alpha$-weakly DR-submodular and $(\gamma,\beta)$-weakly submodular scenarios, where $c$ is the curvature of the investigated submodular functions, $\alpha$ denotes the diminishing-return(DR) ratio and the tuple $(\gamma,\beta)$ represents the submodularity ratios. Subsequently, in order to reduce the reliance on the unknown parameters $\alpha,\gamma,\beta$ inherent in the \texttt{MA-SPL} algorithm, we further introduce the second online algorithm named \texttt{MA-MPL}. This \texttt{MA-MPL} algorithm is entirely \emph{parameter-free} and simultaneously can maintain the same approximation ratio as the first \texttt{MA-SPL} algorithm. The core of our \texttt{MA-SPL} and \texttt{MA-MPL} algorithms is a novel continuous-relaxation technique termed as \emph{policy-based continuous extension}. Compared with the well-established \emph{multi-linear extension}, a notable advantage of this new \emph{policy-based continuous extension} is its ability to provide a lossless rounding scheme for any set function, thereby enabling us to tackle the challenging weakly submodular objectives. Finally, extensive simulations are conducted to validate the effectiveness of our proposed algorithms.