 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight Distillation Reasoning with Knowledge Encouragement Preference for Knowledge-based Visual Question Answering
Nov 14, 2025



Knowledge-based Visual Question Answering (KBVQA) necessitates external knowledge incorporation beyond cross-modal understanding. Existing KBVQA methods either utilize implicit knowledge in multimodal large language models (MLLMs) via in-context learning or explicit knowledge via retrieval augmented generation. However, their reasoning processes remain implicit, without explicit multi-step trajectories from MLLMs. To address this gap, we provide a Hindsight Distilled Reasoning (HinD) framework with Knowledge Encouragement Preference Optimization (KEPO), designed to elicit and harness internal knowledge reasoning ability in MLLMs. First, to tackle the reasoning supervision problem, we propose to emphasize the hindsight wisdom of MLLM by prompting a frozen 7B-size MLLM to complete the reasoning process between the question and its ground truth answer, constructing Hindsight-Zero training data. Then we self-distill Hindsight-Zero into Chain-of-Thought (CoT) Generator and Knowledge Generator, enabling the generation of sequential steps and discrete facts. Secondly, to tackle the misalignment between knowledge correctness and confidence, we optimize the Knowledge Generator with KEPO, preferring under-confident but helpful knowledge over the over-confident but unhelpful one. The generated CoT and sampled knowledge are then exploited for answer prediction. Experiments on OK-VQA and A-OKVQA validate the effectiveness of HinD, showing that HinD with elicited reasoning from 7B-size MLLM achieves superior performance without commercial model APIs or outside knowledge.
Plan of Knowledge: Retrieval-Augmented Large Language Models for Temporal Knowledge Graph Question Answering
Nov 06, 2025



Temporal Knowledge Graph Question Answering (TKGQA) aims to answer time-sensitive questions by leveraging factual information from Temporal Knowledge Graphs (TKGs). While previous studies have employed pre-trained TKG embeddings or graph neural networks to inject temporal knowledge, they fail to fully understand the complex semantic information of time constraints. Recently, Large Language Models (LLMs) have shown remarkable progress, benefiting from their strong semantic understanding and reasoning generalization capabilities. However, their temporal reasoning ability remains limited. LLMs frequently suffer from hallucination and a lack of knowledge. To address these limitations, we propose the Plan of Knowledge framework with a contrastive temporal retriever, which is named PoK. Specifically, the proposed Plan of Knowledge module decomposes a complex temporal question into a sequence of sub-objectives from the pre-defined tools, serving as intermediate guidance for reasoning exploration. In parallel, we construct a Temporal Knowledge Store (TKS) with a contrastive retrieval framework, enabling the model to selectively retrieve semantically and temporally aligned facts from TKGs. By combining structured planning with temporal knowledge retrieval, PoK effectively enhances the interpretability and factual consistency of temporal reasoning. Extensive experiments on four benchmark TKGQA datasets demonstrate that PoK significantly improves the retrieval precision and reasoning accuracy of LLMs, surpassing the performance of the state-of-the-art TKGQA methods by 56.0% at most.
Contrast then Memorize: Semantic Neighbor Retrieval-Enhanced Inductive Multimodal Knowledge Graph Completion
Jul 03, 2024



A large number of studies have emerged for Multimodal Knowledge Graph Completion (MKGC) to predict the missing links in MKGs. However, fewer studies have been proposed to study the inductive MKGC (IMKGC) involving emerging entities unseen during training. Existing inductive approaches focus on learning textual entity representations, which neglect rich semantic information in visual modality. Moreover, they focus on aggregating structural neighbors from existing KGs, which of emerging entities are usually limited. However, the semantic neighbors are decoupled from the topology linkage and usually imply the true target entity. In this paper, we propose the IMKGC task and a semantic neighbor retrieval-enhanced IMKGC framework CMR, where the contrast brings the helpful semantic neighbors close, and then the memorize supports semantic neighbor retrieval to enhance inference. Specifically, we first propose a unified cross-modal contrastive learning to simultaneously capture the textual-visual and textual-textual correlations of query-entity pairs in a unified representation space. The contrastive learning increases the similarity of positive query-entity pairs, therefore making the representations of helpful semantic neighbors close. Then, we explicitly memorize the knowledge representations to support the semantic neighbor retrieval. At test time, we retrieve the nearest semantic neighbors and interpolate them to the query-entity similarity distribution to augment the final prediction. Extensive experiments validate the effectiveness of CMR on three inductive MKGC datasets. Codes are available at https://github.com/OreOZhao/CMR.
UniRetriever: Multi-task Candidates Selection for Various Context-Adaptive Conversational Retrieval
Feb 28, 2024



Conversational retrieval refers to an information retrieval system that operates in an iterative and interactive manner, requiring the retrieval of various external resources, such as persona, knowledge, and even response, to effectively engage with the user and successfully complete the dialogue. However, most previous work trained independent retrievers for each specific resource, resulting in sub-optimal performance and low efficiency. Thus, we propose a multi-task framework function as a universal retriever for three dominant retrieval tasks during the conversation: persona selection, knowledge selection, and response selection. To this end, we design a dual-encoder architecture consisting of a context-adaptive dialogue encoder and a candidate encoder, aiming to attention to the relevant context from the long dialogue and retrieve suitable candidates by simply a dot product. Furthermore, we introduce two loss constraints to capture the subtle relationship between dialogue context and different candidates by regarding historically selected candidates as hard negatives. Extensive experiments and analysis establish state-of-the-art retrieval quality both within and outside its training domain, revealing the promising potential and generalization capability of our model to serve as a universal retriever for different candidate selection tasks simultaneously.
Self-DC: When to retrieve and When to generate? Self Divide-and-Conquer for Compositional Unknown Questions
Feb 21, 2024



Retrieve-then-read and generate-then-read are two typical solutions to handle unknown and known questions in open-domain question-answering, while the former retrieves necessary external knowledge and the later prompt the large language models to generate internal known knowledge encoded in the parameters. However, few of previous works consider the compositional unknown questions, which consist of several known or unknown sub-questions. Thus, simple binary classification (known or unknown) becomes sub-optimal and inefficient since it will call external retrieval excessively for each compositional unknown question. To this end, we propose the first Compositional unknown Question-Answering dataset (CuQA), and introduce a Self Divide-and-Conquer (Self-DC) framework to empower LLMs to adaptively call different methods on-demand, resulting in better performance and efficiency. Experimental results on two datasets (CuQA and FreshQA) demonstrate that Self-DC can achieve comparable or even better performance with much more less retrieval times compared with several strong baselines.
Multi-grained Label Refinement Network with Dependency Structures for Joint Intent Detection and Slot Filling
Sep 09, 2022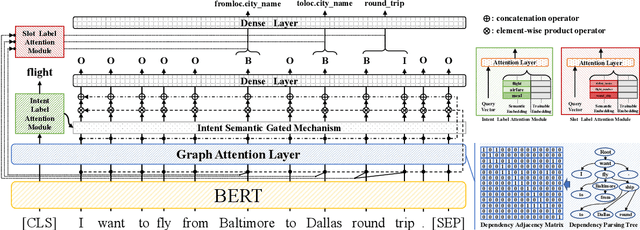

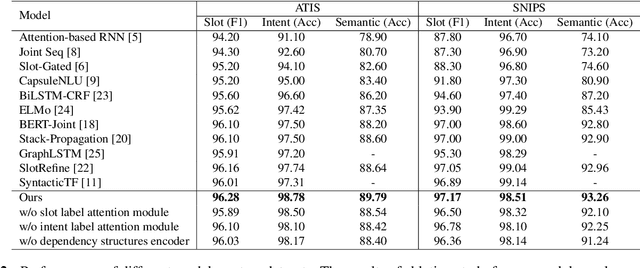
Slot filling and intent detection are two fundamental tasks in the field of natural language understanding. Due to the strong correlation between these two tasks, previous studies make efforts on modeling them with multi-task learning or designing feature interaction modules to improve the performance of each task. However, none of the existing approaches consider the relevance between the structural information of sentences and the label semantics of two tasks. The intent and semantic components of a utterance are dependent on the syntactic elements of a sentence. In this paper, we investigate a multi-grained label refinement network, which utilizes dependency structures and label semantic embeddings. Considering to enhance syntactic representations, we introduce the dependency structures of sentences into our model by graph attention layer. To capture the semantic dependency between the syntactic information and task labels, we combine the task specific features with corresponding label embeddings by attention mechanism. The experimental results demonstrate that our model achieves the competitive performance on two public datasets.