 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINCE: Shrinking LLM Evaluation Datasets via Few-Model Monte Carlo Calibration
Jun 22, 2026Evaluating LLMs across many model variants -- quantized, fine-tuned, or deployment-specific -- requires running large benchmarks repeatedly, a process that can take tens of hours per model on edge hardware such as NPUs. Existing subset selection methods reduce this cost but depend on large calibration pools or learned prediction layers. We introduce MINCE (Monte Carlo Informed N-sizing for Compact Evaluation), which uses Monte Carlo simulation over per-item logs from a small set of calibration models to find the minimum subset size that bounds accuracy drift and then fixes a randomly sampled subset at that size, with no prediction layer needed. MINCE reduces IFEVAL by 54\%, MMLU by 89\%, and GSM8K by 70\% with maximum drift $\leq$2.62\,pp on BF16 models and mean drift of 0.77--3.59\,pp on held-out NPU models, while delivering median GPU evaluation speedups of 2.7--8.1$\times$ and NPU evaluation speedups of 1.7--2.0$\times$. The method is robust to calibration pool size and achieves lower drift than tinyBenchmarks (12$\times$ lower on MMLU, 3.3$\times$ on GSM8K) while using 57$\times$ fewer calibration models.
Recover-LoRA for Aggressive Quantization: Reclaiming Accuracy in 2-Bit Language Models via Low-Rank Adaptation with Knowledge Distillation on Synthetic Data
Jun 02, 2026Aggressive weight quantization to 2-bit precision offers substantial throughput and memory gains for large language model (LLM) inference, but typically incurs severe accuracy degradation. These gains are particularly relevant for edge and on-device deployment, where memory capacity and bandwidth are primary constraints. In this work, we extend Recover-LoRA -- a lightweight, data-free accuracy recovery method originally developed for general model weight corruption -- to the setting of ultra-low-bit quantization. We propose a selective mixed-precision strategy in which only gate and up projection layers of the MLP are quantized to 2-bit (W2), while all other linear layers remain at higher precision, yielding a mixed-precision GateUp configuration. We demonstrate via roofline analysis across three model families (4B--20B) and two hardware platforms that a W4/W2-GateUp deployment (4-bit base with 2-bit gate/up) delivers 7.5--23.3\% TPS improvement over uniform W4 depending on model and context length, while confining quantization error to a predictable subset of layers. We then apply Recover-LoRA -- training low-rank adapters on the quantized layers via logit distillation with synthetic data -- to recover accuracy lost from 2-bit quantization of the gate and up layers. In a case study on Qwen3-4B, Recover-LoRA achieves 80--95\% accuracy recovery on 9 of 12 benchmarks, using only 10k synthetic training samples and no labeled data. We further demonstrate that synthetic data performs comparably to curated labeled data for distillation-based recovery, and that recovery generalizes to out-of-distribution evaluation tasks. Our results present Recover-LoRA as a practical post-quantization accuracy recovery tool for aggressive weight compression in deployment settings.
Bring Your Own Codegen to Deep Learning Compiler
May 03, 2021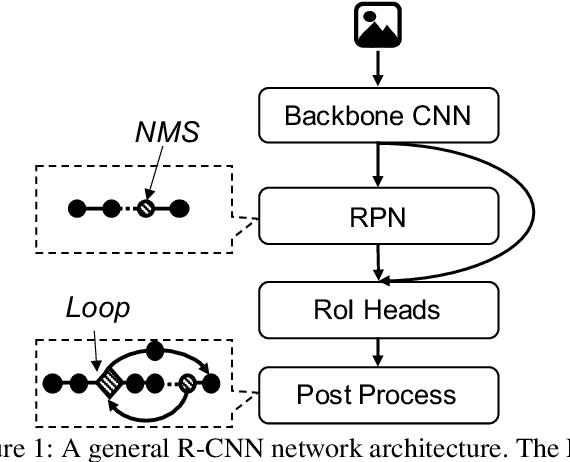
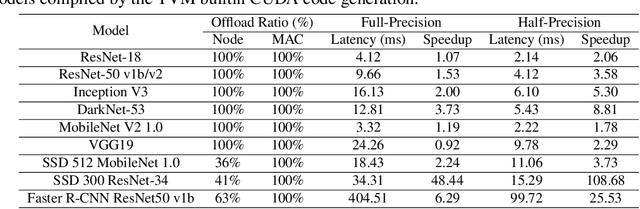

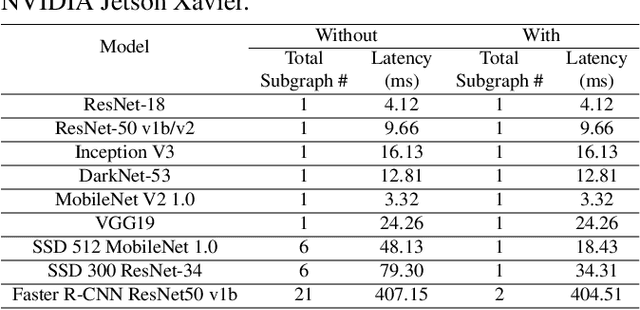
Deep neural networks (DNNs) have been ubiquitously applied in many applications, and accelerators are emerged as an enabler to support the fast and efficient inference tasks of these applications. However, to achieve high model coverage with high performance, each accelerator vendor has to develop a full compiler stack to ingest, optimize, and execute the DNNs. This poses significant challenges in the development and maintenance of the software stack. In addition, the vendors have to contiguously update their hardware and/or software to cope with the rapid evolution of the DNN model architectures and operators. To address these issues, this paper proposes an open source framework that enables users to only concentrate on the development of their proprietary code generation tools by reusing as many as possible components in the existing deep learning compilers. Our framework provides users flexible and easy-to-use interfaces to partition their models into segments that can be executed on "the best" processors to take advantage of the powerful computation capability of accelerators. Our case study shows that our framework has been deployed in multiple commercial vendors' compiler stacks with only a few thousand lines of code.
Quantizing Convolutional Neural Networks for Low-Power High-Throughput Inference Engines
May 21, 2018
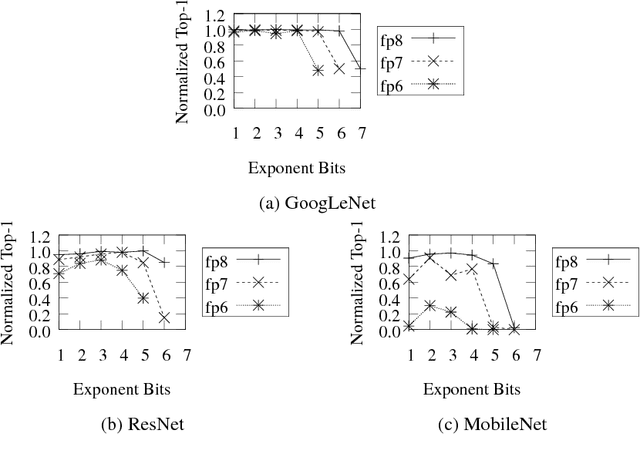
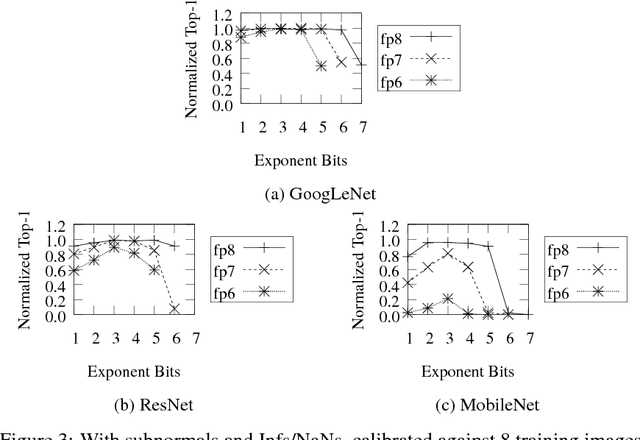
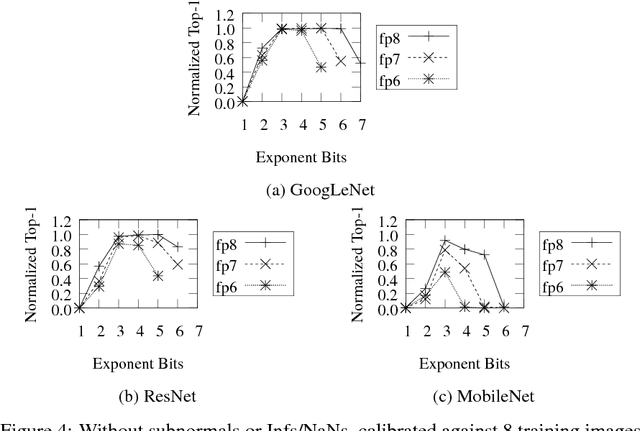
Deep learning as a means to inferencing has proliferated thanks to its versatility and ability to approach or exceed human-level accuracy. These computational models have seemingly insatiable appetites for computational resources not only while training, but also when deployed at scales ranging from data centers all the way down to embedded devices. As such, increasing consideration is being made to maximize the computational efficiency given limited hardware and energy resources and, as a result, inferencing with reduced precision has emerged as a viable alternative to the IEEE 754 Standard for Floating-Point Arithmetic. We propose a quantization scheme that allows inferencing to be carried out using arithmetic that is fundamentally more efficient when compared to even half-precision floating-point. Our quantization procedure is significant in that we determine our quantization scheme parameters by calibrating against its reference floating-point model using a single inference batch rather than (re)training and achieve end-to-end post quantization accuracies comparable to the reference model.