 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamFusion: Scalable Sequence Parallelism for Distributed Inference of Diffusion Transformers on GPUs
Jan 28, 2026Diffusion Transformers (DiTs) have gained increasing adoption in high-quality image and video generation. As demand for higher-resolution images and longer videos increases, single-GPU inference becomes inefficient due to increased latency and large activation sizes. Current frameworks employ sequence parallelism (SP) techniques such as Ulysses Attention and Ring Attention to scale inference. However, these implementations have three primary limitations: (1) suboptimal communication patterns for network topologies on modern GPU machines, (2) latency bottlenecks from all-to-all operations in inter-machine communication, and (3) GPU sender-receiver synchronization and computation overheads from using two-sided communication libraries. To address these issues, we present StreamFusion, a topology-aware efficient DiT serving engine. StreamFusion incorporates three key innovations: (1) a topology-aware sequence parallelism technique that accounts for inter- and intra-machine bandwidth differences, (2) Torus Attention, a novel SP technique enabling overlapping of inter-machine all-to-all operations with computation, and (3) a one-sided communication implementation that minimizes GPU sender-receiver synchronization and computation overheads. Our experiments demonstrate that StreamFusion outperforms the state-of-the-art approach by an average of $1.35\times$ (up to $1.77\times$).
Axe: A Simple Unified Layout Abstraction for Machine Learning Compilers
Jan 27, 2026Scaling modern deep learning workloads demands coordinated placement of data and compute across device meshes, memory hierarchies, and heterogeneous accelerators. We present Axe Layout, a hardware-aware abstraction that maps logical tensor coordinates to a multi-axis physical space via named axes. Axe unifies tiling, sharding, replication, and offsets across inter-device distribution and on-device layouts, enabling collective primitives to be expressed consistently from device meshes to threads. Building on Axe, we design a multi-granularity, distribution-aware DSL and compiler that composes thread-local control with collective operators in a single kernel. Experiments show that our unified approach can bring performance close to hand-tuned kernels on across latest GPU devices and multi-device environments and accelerator backends.
Tilus: A Virtual Machine for Arbitrary Low-Precision GPGPU Computation in LLM Serving
Apr 25, 2025



Serving Large Language Models (LLMs) is critical for AI-powered applications but demands substantial computational resources, particularly in memory bandwidth and computational throughput. Low-precision computation has emerged as a key technique to improve efficiency while reducing resource consumption. Existing approaches for generating low-precision kernels are limited to weight bit widths that are powers of two and suffer from suboptimal performance due to high-level GPU programming abstractions. These abstractions restrict critical optimizations, such as fine-grained register management and optimized memory access patterns, which are essential for efficient low-precision computations. In this paper, we introduce a virtual machine (VM) designed for General-Purpose GPU (GPGPU) computing, enabling support for low-precision data types with arbitrary bit widths while maintaining GPU programmability. The proposed VM features a thread-block-level programming model, a hierarchical memory space, a novel algebraic layout system, and extensive support for diverse low-precision data types. VM programs are compiled into highly efficient GPU programs with automatic vectorization and instruction selection. Extensive experiments demonstrate that our VM efficiently supports a full spectrum of low-precision data types, and outperforms state-of-the-art low-precision kernels on their supported types. Compared to existing compilers like Triton and Ladder, as well as hand-optimized kernels such as QuantLLM and Marlin, our VM achieves performance improvements of 1.75x, 2.61x, 1.29x and 1.03x, respectively.
Hexcute: A Tile-based Programming Language with Automatic Layout and Task-Mapping Synthesis
Apr 22, 2025Deep learning (DL) workloads mainly run on accelerators like GPUs. Recent DL quantization techniques demand a new matrix multiplication operator with mixed input data types, further complicating GPU optimization. Prior high-level compilers like Triton lack the expressiveness to implement key optimizations like fine-grained data pipelines and hardware-friendly memory layouts for these operators, while low-level programming models, such as Hidet, Graphene, and CUTLASS, require significant programming efforts. To balance expressiveness with engineering effort, we propose Hexcute, a tile-based programming language that exposes shared memory and register abstractions to enable fine-grained optimization for these operators. Additionally, Hexcute leverages task mapping to schedule the GPU program, and to reduce programming efforts, it automates layout and task mapping synthesis with a novel type-inference-based algorithm. Our evaluation shows that Hexcute generalizes to a wide range of DL operators, achieves 1.7-11.28$\times$ speedup over existing DL compilers for mixed-type operators, and brings up to 2.91$\times$ speedup in the end-to-end evaluation.
A Virtual Machine for Arbitrary Low-Precision GPGPU Computation in LLM Serving
Apr 17, 2025Serving Large Language Models (LLMs) is critical for AI-powered applications but demands substantial computational resources, particularly in memory bandwidth and computational throughput. Low-precision computation has emerged as a key technique to improve efficiency while reducing resource consumption. Existing approaches for generating low-precision kernels are limited to weight bit widths that are powers of two and suffer from suboptimal performance due to high-level GPU programming abstractions. These abstractions restrict critical optimizations, such as fine-grained register management and optimized memory access patterns, which are essential for efficient low-precision computations. In this paper, we introduce a virtual machine (VM) designed for General-Purpose GPU (GPGPU) computing, enabling support for low-precision data types with arbitrary bit widths while maintaining GPU programmability. The proposed VM features a thread-block-level programming model, a hierarchical memory space, a novel algebraic layout system, and extensive support for diverse low-precision data types. VM programs are compiled into highly efficient GPU programs with automatic vectorization and instruction selection. Extensive experiments demonstrate that our VM efficiently supports a full spectrum of low-precision data types, and outperforms state-of-the-art low-precision kernels on their supported types. Compared to existing compilers like Triton and Ladder, as well as hand-optimized kernels such as QuantLLM and Marlin, our VM achieves performance improvements of 1.75x, 2.61x, 1.29x and 1.03x, respectively.
Hidet: Task Mapping Programming Paradigm for Deep Learning Tensor Programs
Oct 18, 2022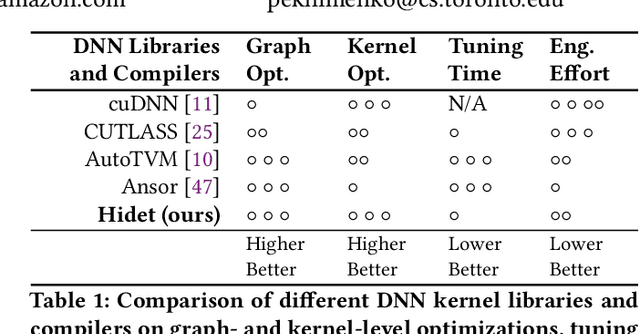
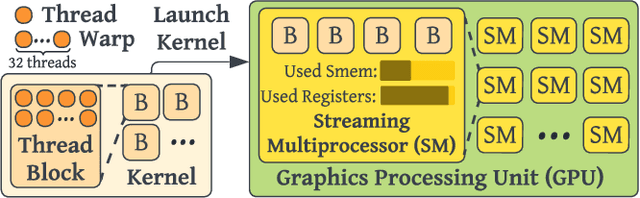

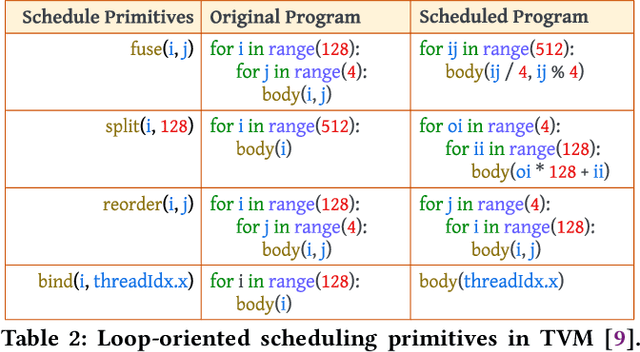
As deep learning models nowadays are widely adopted by both cloud services and edge devices, the latency of deep learning model inferences becomes crucial to provide efficient model serving. However, it is challenging to develop efficient tensor programs for deep learning operators due to the high complexity of modern accelerators (e.g., NVIDIA GPUs and Google TPUs) and the rapidly growing number of operators. Deep learning compilers, such as Apache TVM, adopt declarative scheduling primitives to lower the bar of developing tensor programs. However, we show that this approach is insufficient to cover state-of-the-art tensor program optimizations (e.g., double buffering). In this paper, we propose to embed the scheduling process into tensor programs and use dedicated mappings, called task mappings, to define the computation assignment and ordering directly in the tensor programs. This new approach greatly enriches the expressible optimizations by allowing developers to manipulate tensor programs at a much finer granularity (e.g., allowing program statement-level optimizations). We call the proposed method the task-mapping-oriented programming paradigm. With the proposed paradigm, we implement a deep learning compiler - Hidet. Extensive experiments on modern convolution and transformer models show that Hidet outperforms state-of-the-art DNN inference framework, ONNX Runtime, and compiler, TVM equipped with scheduler AutoTVM and Ansor, by up to 1.48x (1.22x on average) with enriched optimizations. It also reduces the tuning time by 20x and 11x compared with AutoTVM and Ansor, respectively.
IOS: Inter-Operator Scheduler for CNN Acceleration
Nov 02, 2020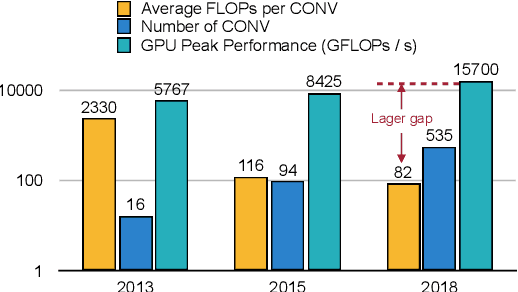
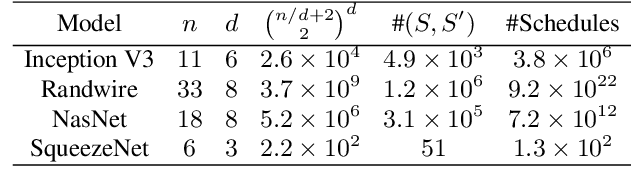
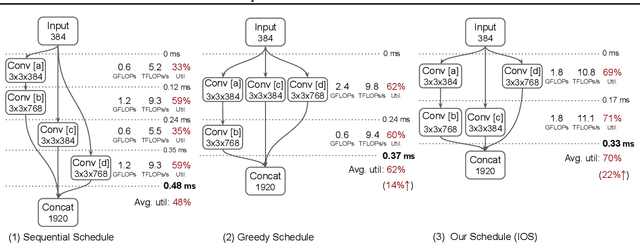
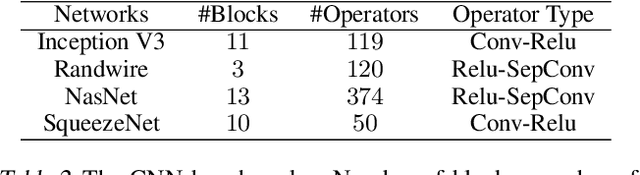
To accelerate CNN inference, existing deep learning frameworks focus on optimizing intra-operator parallelization. However, a single operator can no longer fully utilize the available parallelism given the rapid advances in high-performance hardware, resulting in a large gap between the peak performance and the real performance. This performance gap is more severe under smaller batch sizes. In this work, we extensively study the parallelism between operators and propose Inter-Operator Scheduler (IOS) to automatically schedule the execution of multiple operators in parallel. IOS utilizes dynamic programming to find a scheduling policy specialized for the target hardware. IOS consistently outperforms state-of-the-art libraries (e.g., TensorRT) by 1.1 to 1.5x on modern CNN benchmarks.
GAN Compression: Efficient Architectures for Interactive Conditional GANs
Mar 19, 2020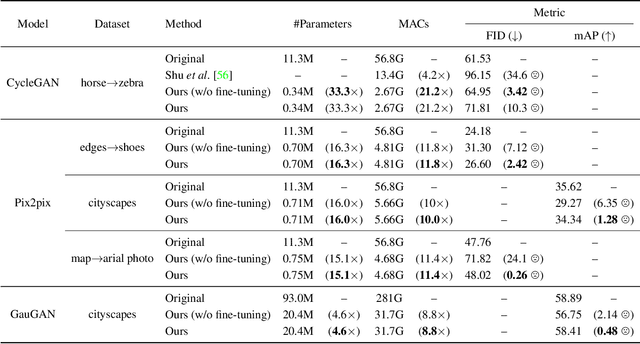
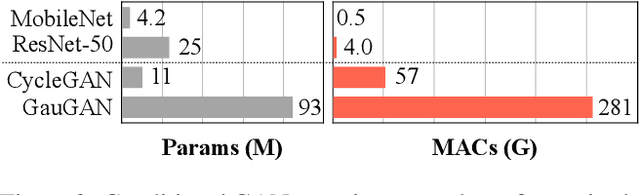
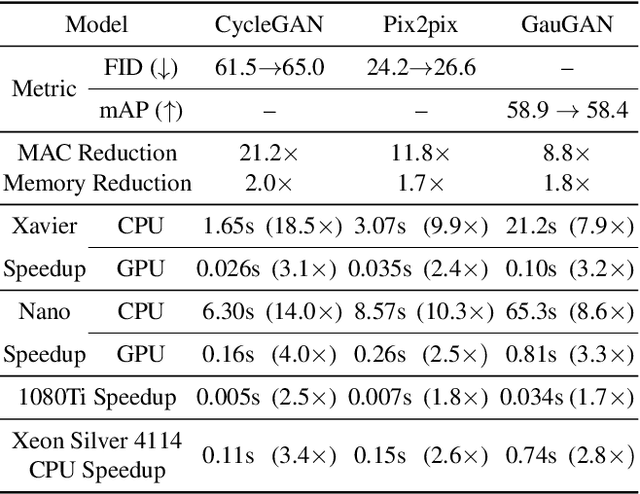
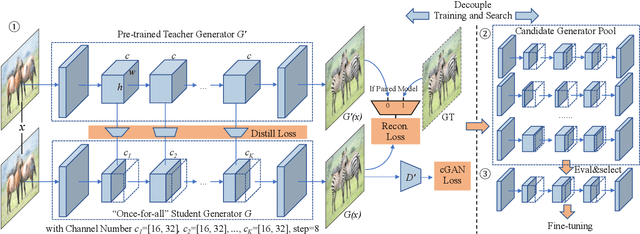
Conditional Generative Adversarial Networks (cGANs) have enabled controllable image synthesis for many computer vision and graphics applications. However, recent cGANs are 1-2 orders of magnitude more computationally-intensive than modern recognition CNNs. For example, GauGAN consumes 281G MACs per image, compared to 0.44G MACs for MobileNet-v3, making it difficult for interactive deployment. In this work, we propose a general-purpose compression framework for reducing the inference time and model size of the generator in cGANs. Directly applying existing CNNs compression methods yields poor performance due to the difficulty of GAN training and the differences in generator architectures. We address these challenges in two ways. First, to stabilize the GAN training, we transfer knowledge of multiple intermediate representations of the original model to its compressed model, and unify unpaired and paired learning. Second, instead of reusing existing CNN designs, our method automatically finds efficient architectures via neural architecture search (NAS). To accelerate the search process, we decouple the model training and architecture search via weight sharing. Experiments demonstrate the effectiveness of our method across different supervision settings (paired and unpaired), model architectures, and learning methods (e.g., pix2pix, GauGAN, CycleGAN). Without losing image quality, we reduce the computation of CycleGAN by more than 20X and GauGAN by 9X, paving the way for interactive image synthesis. The code and demo are publicly available.
CityFlow: A Multi-Agent Reinforcement Learning Environment for Large Scale City Traffic Scenario
May 13, 2019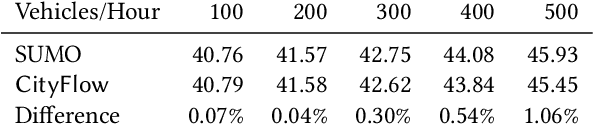
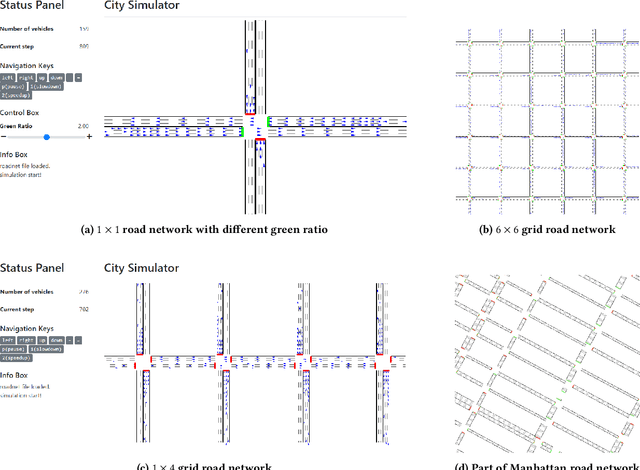
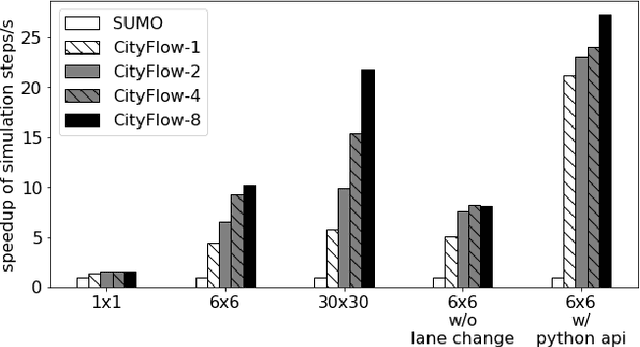
Traffic signal control is an emerging application scenario for reinforcement learning. Besides being as an important problem that affects people's daily life in commuting, traffic signal control poses its unique challenges for reinforcement learning in terms of adapting to dynamic traffic environment and coordinating thousands of agents including vehicles and pedestrians. A key factor in the success of modern reinforcement learning relies on a good simulator to generate a large number of data samples for learning. The most commonly used open-source traffic simulator SUMO is, however, not scalable to large road network and large traffic flow, which hinders the study of reinforcement learning on traffic scenarios. This motivates us to create a new traffic simulator CityFlow with fundamentally optimized data structures and efficient algorithms. CityFlow can support flexible definitions for road network and traffic flow based on synthetic and real-world data. It also provides user-friendly interface for reinforcement learning. Most importantly, CityFlow is more than twenty times faster than SUMO and is capable of supporting city-wide traffic simulation with an interactive render for monitoring. Besides traffic signal control, CityFlow could serve as the base for other transportation studies and can create new possibilities to test machine learning methods in the intelligent transportation domain.