 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Optimizing Speculative Decoding for Serving Large Language Models Using Goodput
Jun 20, 2024



Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Efficient Memory Management for Large Language Model Serving with PagedAttention
Sep 12, 2023



High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$\times$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
Nimble: Lightweight and Parallel GPU Task Scheduling for Deep Learning
Dec 04, 2020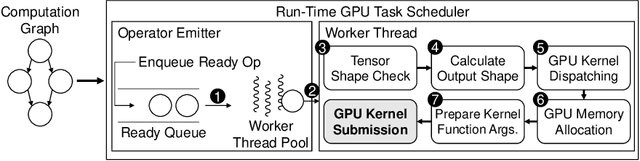
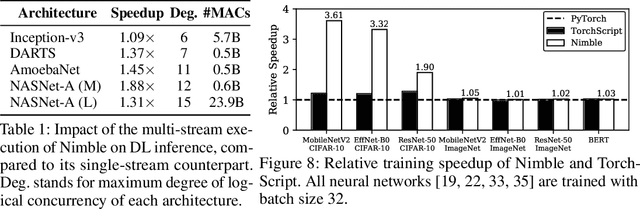
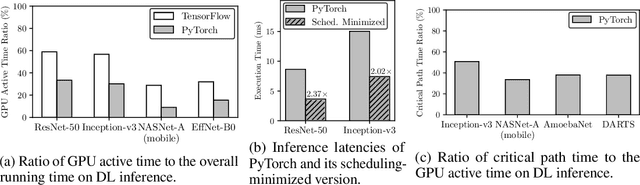
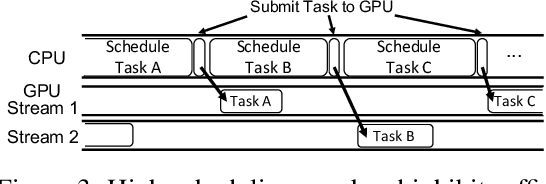
Deep learning (DL) frameworks take advantage of GPUs to improve the speed of DL inference and training. Ideally, DL frameworks should be able to fully utilize the computation power of GPUs such that the running time depends on the amount of computation assigned to GPUs. Yet, we observe that in scheduling GPU tasks, existing DL frameworks suffer from inefficiencies such as large scheduling overhead and unnecessary serial execution. To this end, we propose Nimble, a DL execution engine that runs GPU tasks in parallel with minimal scheduling overhead. Nimble introduces a novel technique called ahead-of-time (AoT) scheduling. Here, the scheduling procedure finishes before executing the GPU kernel, thereby removing most of the scheduling overhead during run time. Furthermore, Nimble automatically parallelizes the execution of GPU tasks by exploiting multiple GPU streams in a single GPU. Evaluation on a variety of neural networks shows that compared to PyTorch, Nimble speeds up inference and training by up to 22.34$\times$ and 3.61$\times$, respectively. Moreover, Nimble outperforms state-of-the-art inference systems, TensorRT and TVM, by up to 2.81$\times$ and 1.70$\times$, respectively.