 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagellan: Autonomous Discovery of Novel Compiler Optimization Heuristics with AlphaEvolve
Jan 28, 2026Modern compilers rely on hand-crafted heuristics to guide optimization passes. These human-designed rules often struggle to adapt to the complexity of modern software and hardware and lead to high maintenance burden. To address this challenge, we present Magellan, an agentic framework that evolves the compiler pass itself by synthesizing executable C++ decision logic. Magellan couples an LLM coding agent with evolutionary search and autotuning in a closed loop of generation, evaluation on user-provided macro-benchmarks, and refinement, producing compact heuristics that integrate directly into existing compilers. Across several production optimization tasks, Magellan discovers policies that match or surpass expert baselines. In LLVM function inlining, Magellan synthesizes new heuristics that outperform decades of manual engineering for both binary-size reduction and end-to-end performance. In register allocation, it learns a concise priority rule for live-range processing that matches intricate human-designed policies on a large-scale workload. We also report preliminary results on XLA problems, demonstrating portability beyond LLVM with reduced engineering effort.
HeuriGym: An Agentic Benchmark for LLM-Crafted Heuristics in Combinatorial Optimization
Jun 09, 2025While Large Language Models (LLMs) have demonstrated significant advancements in reasoning and agent-based problem-solving, current evaluation methodologies fail to adequately assess their capabilities: existing benchmarks either rely on closed-ended questions prone to saturation and memorization, or subjective comparisons that lack consistency and rigor. In this work, we introduce HeuriGym, an agentic framework designed for evaluating heuristic algorithms generated by LLMs for combinatorial optimization problems, characterized by clearly defined objectives and expansive solution spaces. HeuriGym empowers LLMs to propose heuristics, receive evaluative feedback via code execution, and iteratively refine their solutions. We evaluate nine state-of-the-art models on nine problems across domains such as computer systems, logistics, and biology, exposing persistent limitations in tool use, planning, and adaptive reasoning. To quantify performance, we propose the Quality-Yield Index (QYI), a metric that captures both solution pass rate and quality. Even top models like GPT-o4-mini-high and Gemini-2.5-Pro attain QYI scores of only 0.6, well below the expert baseline of 1. Our open-source benchmark aims to guide the development of LLMs toward more effective and realistic problem-solving in scientific and engineering domains.
Allo: A Programming Model for Composable Accelerator Design
Apr 07, 2024



Special-purpose hardware accelerators are increasingly pivotal for sustaining performance improvements in emerging applications, especially as the benefits of technology scaling continue to diminish. However, designers currently lack effective tools and methodologies to construct complex, high-performance accelerator architectures in a productive manner. Existing high-level synthesis (HLS) tools often require intrusive source-level changes to attain satisfactory quality of results. Despite the introduction of several new accelerator design languages (ADLs) aiming to enhance or replace HLS, their advantages are more evident in relatively simple applications with a single kernel. Existing ADLs prove less effective for realistic hierarchical designs with multiple kernels, even if the design hierarchy is flattened. In this paper, we introduce Allo, a composable programming model for efficient spatial accelerator design. Allo decouples hardware customizations, including compute, memory, communication, and data type from algorithm specification, and encapsulates them as a set of customization primitives. Allo preserves the hierarchical structure of an input program by combining customizations from different functions in a bottom-up, type-safe manner. This approach facilitates holistic optimizations that span across function boundaries. We conduct comprehensive experiments on commonly-used HLS benchmarks and several realistic deep learning models. Our evaluation shows that Allo can outperform state-of-the-art HLS tools and ADLs on all test cases in the PolyBench. For the GPT2 model, the inference latency of the Allo generated accelerator is 1.7x faster than the NVIDIA A100 GPU with 5.4x higher energy efficiency, demonstrating the capability of Allo to handle large-scale designs.
Understanding the Potential of FPGA-Based Spatial Acceleration for Large Language Model Inference
Dec 23, 2023



Recent advancements in large language models (LLMs) boasting billions of parameters have generated a significant demand for efficient deployment in inference workloads. The majority of existing approaches rely on temporal architectures that reuse hardware units for different network layers and operators. However, these methods often encounter challenges in achieving low latency due to considerable memory access overhead. This paper investigates the feasibility and potential of model-specific spatial acceleration for LLM inference on FPGAs. Our approach involves the specialization of distinct hardware units for specific operators or layers, facilitating direct communication between them through a dataflow architecture while minimizing off-chip memory accesses. We introduce a comprehensive analytical model for estimating the performance of a spatial LLM accelerator, taking into account the on-chip compute and memory resources available on an FPGA. Through our analysis, we can determine the scenarios in which FPGA-based spatial acceleration can outperform its GPU-based counterpart. To enable more productive implementations of an LLM model on FPGAs, we further provide a library of high-level synthesis (HLS) kernels that are composable and reusable. This library will be made available as open-source. To validate the effectiveness of both our analytical model and HLS library, we have implemented BERT and GPT2 on an AMD Alveo U280 FPGA device. Experimental results demonstrate our approach can achieve up to 16.1x speedup when compared to previous FPGA-based accelerators for the BERT model. For GPT generative inference, we attain a 2.2x speedup compared to DFX, an FPGA overlay, in the prefill stage, while achieving a 1.9x speedup and a 5.7x improvement in energy efficiency compared to the NVIDIA A100 GPU in the decode stage.
Decoupled Model Schedule for Deep Learning Training
Feb 16, 2023Recent years have seen an increase in the development of large deep learning (DL) models, which makes training efficiency crucial. Common practice is struggling with the trade-off between usability and performance. On one hand, DL frameworks such as PyTorch use dynamic graphs to facilitate model developers at a price of sub-optimal model training performance. On the other hand, practitioners propose various approaches to improving the training efficiency by sacrificing some of the flexibility, ranging from making the graph static for more thorough optimization (e.g., XLA) to customizing optimization towards large-scale distributed training (e.g., DeepSpeed and Megatron-LM). In this paper, we aim to address the tension between usability and training efficiency through separation of concerns. Inspired by DL compilers that decouple the platform-specific optimizations of a tensor-level operator from its arithmetic definition, this paper proposes a schedule language to decouple model execution from definition. Specifically, the schedule works on a PyTorch model and uses a set of schedule primitives to convert the model for common model training optimizations such as high-performance kernels, effective 3D parallelism, and efficient activation checkpointing. Compared to existing optimization solutions, we optimize the model as-needed through high-level primitives, and thus preserving programmability and debuggability for users to a large extent. Our evaluation results show that by scheduling the existing hand-crafted optimizations in a systematic way, we are able to improve training throughput by up to 3.35x on a single machine with 8 NVIDIA V100 GPUs, and by up to 1.32x on multiple machines with up to 64 GPUs, when compared to the out-of-the-box performance of DeepSpeed and Megatron-LM.
Structured Pruning is All You Need for Pruning CNNs at Initialization
Mar 04, 2022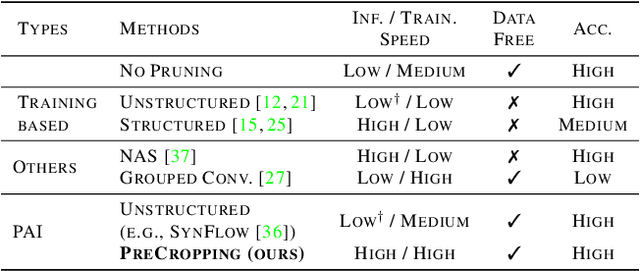
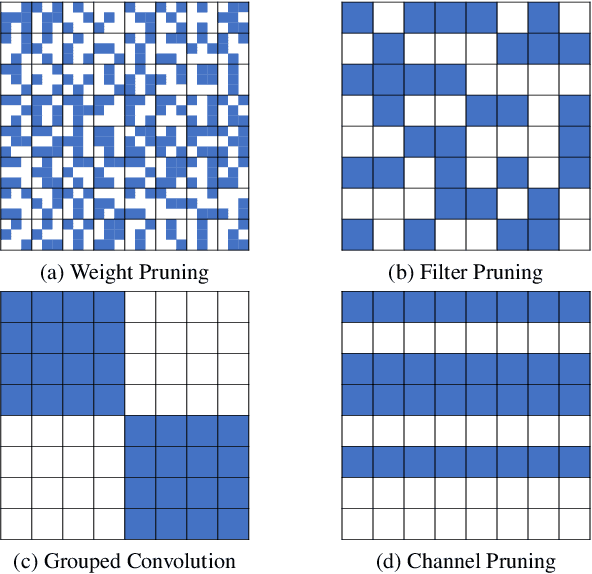
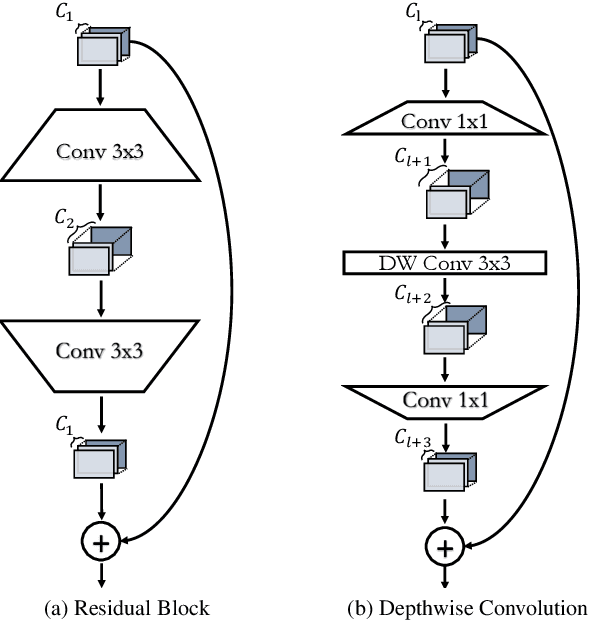
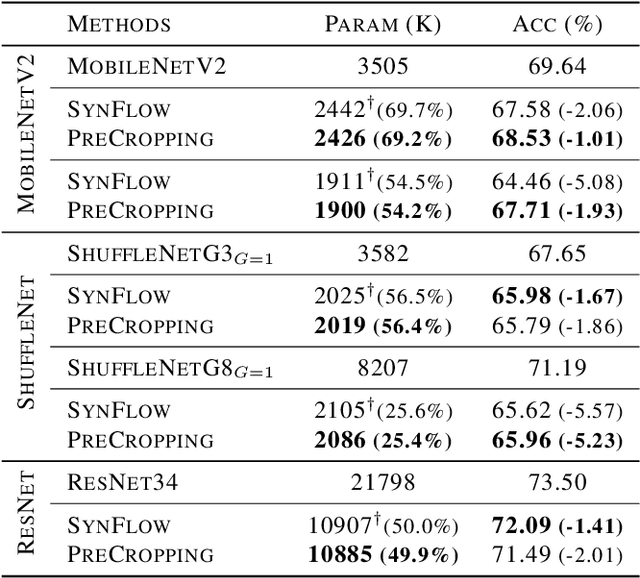
Pruning is a popular technique for reducing the model size and computational cost of convolutional neural networks (CNNs). However, a slow retraining or fine-tuning procedure is often required to recover the accuracy loss caused by pruning. Recently, a new research direction on weight pruning, pruning-at-initialization (PAI), is proposed to directly prune CNNs before training so that fine-tuning or retraining can be avoided. While PAI has shown promising results in reducing the model size, existing approaches rely on fine-grained weight pruning which requires unstructured sparse matrix computation, making it difficult to achieve real speedup in practice unless the sparsity is very high. This work is the first to show that fine-grained weight pruning is in fact not necessary for PAI. Instead, the layerwise compression ratio is the main critical factor to determine the accuracy of a CNN model pruned at initialization. Based on this key observation, we propose PreCropping, a structured hardware-efficient model compression scheme. PreCropping directly compresses the model at the channel level following the layerwise compression ratio. Compared to weight pruning, the proposed scheme is regular and dense in both storage and computation without sacrificing accuracy. In addition, since PreCropping compresses CNNs at initialization, the computational and memory costs of CNNs are reduced for both training and inference on commodity hardware. We empirically demonstrate our approaches on several modern CNN architectures, including ResNet, ShuffleNet, and MobileNet for both CIFAR-10 and ImageNet.
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing
Dec 16, 2021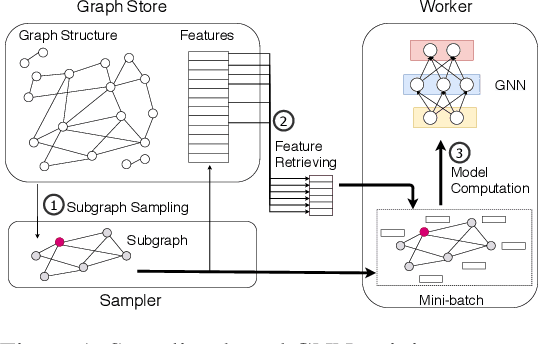
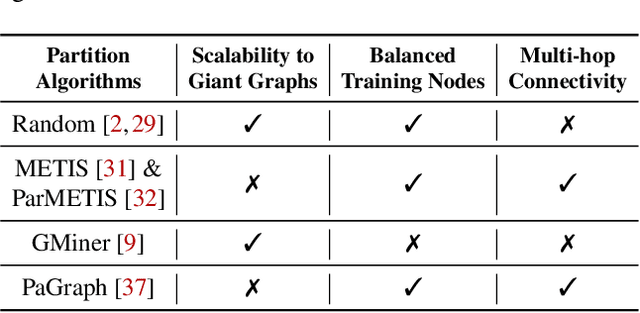
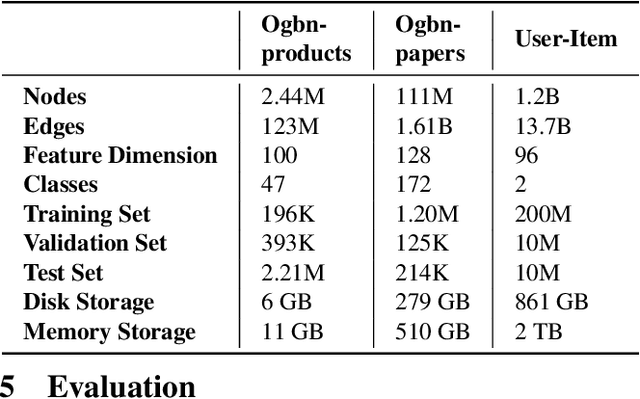
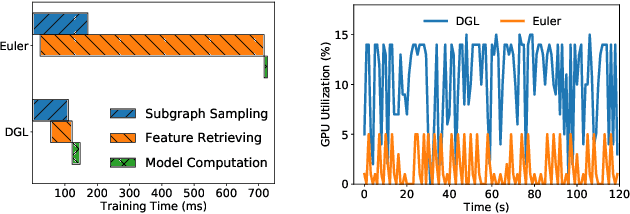
Graph neural networks (GNNs) have extended the success of deep neural networks (DNNs) to non-Euclidean graph data, achieving ground-breaking performance on various tasks such as node classification and graph property prediction. Nonetheless, existing systems are inefficient to train large graphs with billions of nodes and edges with GPUs. The main bottlenecks are the process of preparing data for GPUs - subgraph sampling and feature retrieving. This paper proposes BGL, a distributed GNN training system designed to address the bottlenecks with a few key ideas. First, we propose a dynamic cache engine to minimize feature retrieving traffic. By a co-design of caching policy and the order of sampling, we find a sweet spot of low overhead and high cache hit ratio. Second, we improve the graph partition algorithm to reduce cross-partition communication during subgraph sampling. Finally, careful resource isolation reduces contention between different data preprocessing stages. Extensive experiments on various GNN models and large graph datasets show that BGL significantly outperforms existing GNN training systems by 20.68x on average.
FracBNN: Accurate and FPGA-Efficient Binary Neural Networks with Fractional Activations
Dec 22, 2020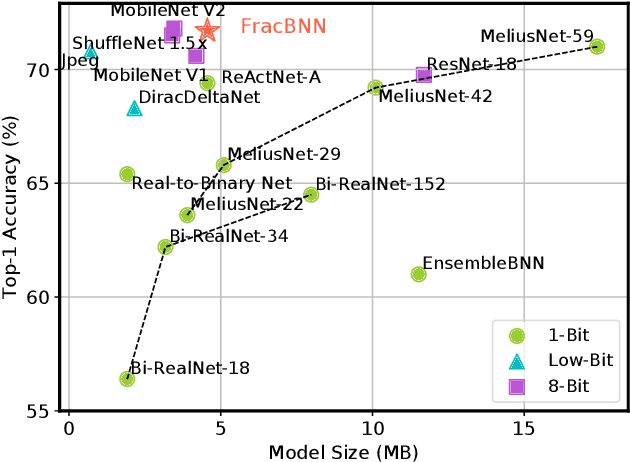

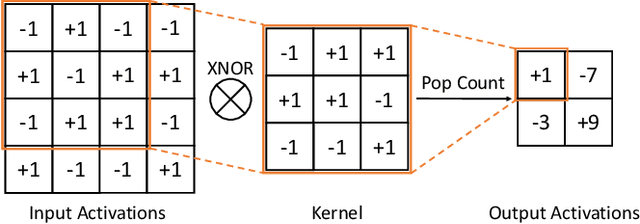
Binary neural networks (BNNs) have 1-bit weights and activations. Such networks are well suited for FPGAs, as their dominant computations are bitwise arithmetic and the memory requirement is also significantly reduced. However, compared to start-of-the-art compact convolutional neural network (CNN) models, BNNs tend to produce a much lower accuracy on realistic datasets such as ImageNet. In addition, the input layer of BNNs has gradually become a major compute bottleneck, because it is conventionally excluded from binarization to avoid a large accuracy loss. This work proposes FracBNN, which exploits fractional activations to substantially improve the accuracy of BNNs. Specifically, our approach employs a dual-precision activation scheme to compute features with up to two bits, using an additional sparse binary convolution. We further binarize the input layer using a novel thermometer encoding. Overall, FracBNN preserves the key benefits of conventional BNNs, where all convolutional layers are computed in pure binary MAC operations (BMACs). We design an efficient FPGA-based accelerator for our novel BNN model that supports the fractional activations. To evaluate the performance of FracBNN under a resource-constrained scenario, we implement the entire optimized network architecture on an embedded FPGA (Xilinx Ultra96v2). Our experiments on ImageNet show that FracBNN achieves an accuracy comparable to MobileNetV2, surpassing the best-known BNN design on FPGAs with an increase of 28.9% in top-1 accuracy and a 2.5x reduction in model size. FracBNN also outperforms a recently introduced BNN model with an increase of 2.4% in top-1 accuracy while using the same model size. On the embedded FPGA device, FracBNN demonstrates the ability of real-time image classification.