 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-IMAGE-EDIT-1.5M: A Million-Scale, GPT-Generated Image Dataset
Jul 28, 2025
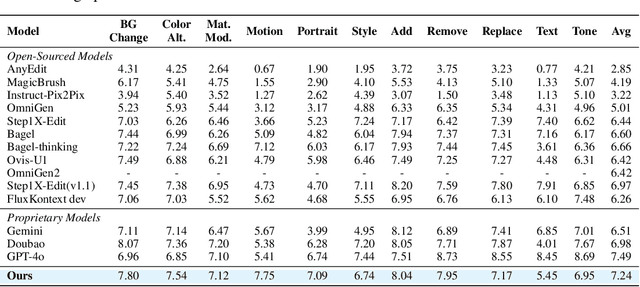

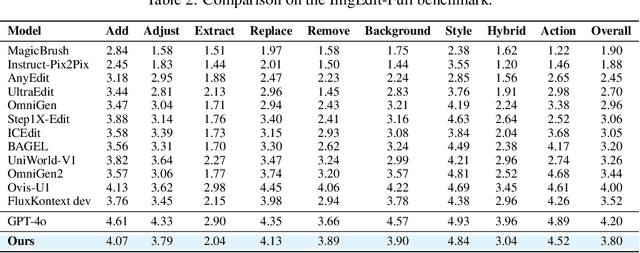
Recent advancements in large multimodal models like GPT-4o have set a new standard for high-fidelity, instruction-guided image editing. However, the proprietary nature of these models and their training data creates a significant barrier for open-source research. To bridge this gap, we introduce GPT-IMAGE-EDIT-1.5M, a publicly available, large-scale image-editing corpus containing more than 1.5 million high-quality triplets (instruction, source image, edited image). We systematically construct this dataset by leveraging the versatile capabilities of GPT-4o to unify and refine three popular image-editing datasets: OmniEdit, HQ-Edit, and UltraEdit. Specifically, our methodology involves 1) regenerating output images to enhance visual quality and instruction alignment, and 2) selectively rewriting prompts to improve semantic clarity. To validate the efficacy of our dataset, we fine-tune advanced open-source models on GPT-IMAGE-EDIT-1.5M. The empirical results are exciting, e.g., the fine-tuned FluxKontext achieves highly competitive performance across a comprehensive suite of benchmarks, including 7.24 on GEdit-EN, 3.80 on ImgEdit-Full, and 8.78 on Complex-Edit, showing stronger instruction following and higher perceptual quality while maintaining identity. These scores markedly exceed all previously published open-source methods and substantially narrow the gap to leading proprietary models. We hope the full release of GPT-IMAGE-EDIT-1.5M can help to catalyze further open research in instruction-guided image editing.
MedFrameQA: A Multi-Image Medical VQA Benchmark for Clinical Reasoning
May 22, 2025Existing medical VQA benchmarks mostly focus on single-image analysis, yet clinicians almost always compare a series of images before reaching a diagnosis. To better approximate this workflow, we introduce MedFrameQA -- the first benchmark that explicitly evaluates multi-image reasoning in medical VQA. To build MedFrameQA both at scale and in high-quality, we develop 1) an automated pipeline that extracts temporally coherent frames from medical videos and constructs VQA items whose content evolves logically across images, and 2) a multiple-stage filtering strategy, including model-based and manual review, to preserve data clarity, difficulty, and medical relevance. The resulting dataset comprises 2,851 VQA pairs (gathered from 9,237 high-quality frames in 3,420 videos), covering nine human body systems and 43 organs; every question is accompanied by two to five images. We comprehensively benchmark ten advanced Multimodal LLMs -- both proprietary and open source, with and without explicit reasoning modules -- on MedFrameQA. The evaluation challengingly reveals that all models perform poorly, with most accuracies below 50%, and accuracy fluctuates as the number of images per question increases. Error analysis further shows that models frequently ignore salient findings, mis-aggregate evidence across images, and propagate early mistakes through their reasoning chains; results also vary substantially across body systems, organs, and modalities. We hope this work can catalyze research on clinically grounded, multi-image reasoning and accelerate progress toward more capable diagnostic AI systems.
OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
May 07, 2025



OpenAI's CLIP, released in early 2021, have long been the go-to choice of vision encoder for building multimodal foundation models. Although recent alternatives such as SigLIP have begun to challenge this status quo, to our knowledge none are fully open: their training data remains proprietary and/or their training recipes are not released. This paper fills this gap with OpenVision, a fully-open, cost-effective family of vision encoders that match or surpass the performance of OpenAI's CLIP when integrated into multimodal frameworks like LLaVA. OpenVision builds on existing works -- e.g., CLIPS for training framework and Recap-DataComp-1B for training data -- while revealing multiple key insights in enhancing encoder quality and showcasing practical benefits in advancing multimodal models. By releasing vision encoders spanning from 5.9M to 632.1M parameters, OpenVision offers practitioners a flexible trade-off between capacity and efficiency in building multimodal models: larger models deliver enhanced multimodal performance, while smaller versions enable lightweight, edge-ready multimodal deployments.
$\texttt{Complex-Edit}$: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark
Apr 17, 2025We introduce $\texttt{Complex-Edit}$, a comprehensive benchmark designed to systematically evaluate instruction-based image editing models across instructions of varying complexity. To develop this benchmark, we harness GPT-4o to automatically collect a diverse set of editing instructions at scale. Our approach follows a well-structured ``Chain-of-Edit'' pipeline: we first generate individual atomic editing tasks independently and then integrate them to form cohesive, complex instructions. Additionally, we introduce a suite of metrics to assess various aspects of editing performance, along with a VLM-based auto-evaluation pipeline that supports large-scale assessments. Our benchmark yields several notable insights: 1) Open-source models significantly underperform relative to proprietary, closed-source models, with the performance gap widening as instruction complexity increases; 2) Increased instructional complexity primarily impairs the models' ability to retain key elements from the input images and to preserve the overall aesthetic quality; 3) Decomposing a complex instruction into a sequence of atomic steps, executed in a step-by-step manner, substantially degrades performance across multiple metrics; 4) A straightforward Best-of-N selection strategy improves results for both direct editing and the step-by-step sequential approach; and 5) We observe a ``curse of synthetic data'': when synthetic data is involved in model training, the edited images from such models tend to appear increasingly synthetic as the complexity of the editing instructions rises -- a phenomenon that intriguingly also manifests in the latest GPT-4o outputs.
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Apr 10, 2025



This work revisits the dominant supervised fine-tuning (SFT) then reinforcement learning (RL) paradigm for training Large Vision-Language Models (LVLMs), and reveals a key finding: SFT can significantly undermine subsequent RL by inducing ``pseudo reasoning paths'' imitated from expert models. While these paths may resemble the native reasoning paths of RL models, they often involve prolonged, hesitant, less informative steps, and incorrect reasoning. To systematically study this effect, we introduce VLAA-Thinking, a new multimodal dataset designed to support reasoning in LVLMs. Constructed via a six-step pipeline involving captioning, reasoning distillation, answer rewrite and verification, VLAA-Thinking comprises high-quality, step-by-step visual reasoning traces for SFT, along with a more challenging RL split from the same data source. Using this dataset, we conduct extensive experiments comparing SFT, RL and their combinations. Results show that while SFT helps models learn reasoning formats, it often locks aligned models into imitative, rigid reasoning modes that impede further learning. In contrast, building on the Group Relative Policy Optimization (GRPO) with a novel mixed reward module integrating both perception and cognition signals, our RL approach fosters more genuine, adaptive reasoning behavior. Notably, our model VLAA-Thinker, based on Qwen2.5VL 3B, achieves top-1 performance on Open LMM Reasoning Leaderboard (https://huggingface.co/spaces/opencompass/Open_LMM_Reasoning_Leaderboard) among 4B scale LVLMs, surpassing the previous state-of-the-art by 1.8%. We hope our findings provide valuable insights in developing reasoning-capable LVLMs and can inform future research in this area.
STAR-1: Safer Alignment of Reasoning LLMs with 1K Data
Apr 02, 2025This paper introduces STAR-1, a high-quality, just-1k-scale safety dataset specifically designed for large reasoning models (LRMs) like DeepSeek-R1. Built on three core principles -- diversity, deliberative reasoning, and rigorous filtering -- STAR-1 aims to address the critical needs for safety alignment in LRMs. Specifically, we begin by integrating existing open-source safety datasets from diverse sources. Then, we curate safety policies to generate policy-grounded deliberative reasoning samples. Lastly, we apply a GPT-4o-based safety scoring system to select training examples aligned with best practices. Experimental results show that fine-tuning LRMs with STAR-1 leads to an average 40% improvement in safety performance across four benchmarks, while only incurring a marginal decrease (e.g., an average of 1.1%) in reasoning ability measured across five reasoning tasks. Extensive ablation studies further validate the importance of our design principles in constructing STAR-1 and analyze its efficacy across both LRMs and traditional LLMs. Our project page is https://ucsc-vlaa.github.io/STAR-1.
ViLBench: A Suite for Vision-Language Process Reward Modeling
Mar 26, 2025Process-supervised reward models serve as a fine-grained function that provides detailed step-wise feedback to model responses, facilitating effective selection of reasoning trajectories for complex tasks. Despite its advantages, evaluation on PRMs remains less explored, especially in the multimodal domain. To address this gap, this paper first benchmarks current vision large language models (VLLMs) as two types of reward models: output reward models (ORMs) and process reward models (PRMs) on multiple vision-language benchmarks, which reveal that neither ORM nor PRM consistently outperforms across all tasks, and superior VLLMs do not necessarily yield better rewarding performance. To further advance evaluation, we introduce ViLBench, a vision-language benchmark designed to require intensive process reward signals. Notably, OpenAI's GPT-4o with Chain-of-Thought (CoT) achieves only 27.3% accuracy, indicating the benchmark's challenge for current VLLMs. Lastly, we preliminarily showcase a promising pathway towards bridging the gap between general VLLMs and reward models -- by collecting 73.6K vision-language process reward data using an enhanced tree-search algorithm, our 3B model is able to achieve an average improvement of 3.3% over standard CoT and up to 2.5% compared to its untrained counterpart on ViLBench by selecting OpenAI o1's generations. We release the implementations at https://ucsc-vlaa.github.io/ViLBench with our code, model, and data.
Scaling Laws in Patchification: An Image Is Worth 50,176 Tokens And More
Feb 06, 2025Since the introduction of Vision Transformer (ViT), patchification has long been regarded as a de facto image tokenization approach for plain visual architectures. By compressing the spatial size of images, this approach can effectively shorten the token sequence and reduce the computational cost of ViT-like plain architectures. In this work, we aim to thoroughly examine the information loss caused by this patchification-based compressive encoding paradigm and how it affects visual understanding. We conduct extensive patch size scaling experiments and excitedly observe an intriguing scaling law in patchification: the models can consistently benefit from decreased patch sizes and attain improved predictive performance, until it reaches the minimum patch size of 1x1, i.e., pixel tokenization. This conclusion is broadly applicable across different vision tasks, various input scales, and diverse architectures such as ViT and the recent Mamba models. Moreover, as a by-product, we discover that with smaller patches, task-specific decoder heads become less critical for dense prediction. In the experiments, we successfully scale up the visual sequence to an exceptional length of 50,176 tokens, achieving a competitive test accuracy of 84.6% with a base-sized model on the ImageNet-1k benchmark. We hope this study can provide insights and theoretical foundations for future works of building non-compressive vision models. Code is available at https://github.com/wangf3014/Patch_Scaling.
ARFlow: Autogressive Flow with Hybrid Linear Attention
Jan 27, 2025



Flow models are effective at progressively generating realistic images, but they generally struggle to capture long-range dependencies during the generation process as they compress all the information from previous time steps into a single corrupted image. To address this limitation, we propose integrating autoregressive modeling -- known for its excellence in modeling complex, high-dimensional joint probability distributions -- into flow models. During training, at each step, we construct causally-ordered sequences by sampling multiple images from the same semantic category and applying different levels of noise, where images with higher noise levels serve as causal predecessors to those with lower noise levels. This design enables the model to learn broader category-level variations while maintaining proper causal relationships in the flow process. During generation, the model autoregressively conditions the previously generated images from earlier denoising steps, forming a contextual and coherent generation trajectory. Additionally, we design a customized hybrid linear attention mechanism tailored to our modeling approach to enhance computational efficiency. Our approach, termed ARFlow, under 400k training steps, achieves 14.08 FID scores on ImageNet at 128 * 128 without classifier-free guidance, reaching 4.34 FID with classifier-free guidance 1.5, significantly outperforming the previous flow-based model SiT's 9.17 FID. Extensive ablation studies demonstrate the effectiveness of our modeling strategy and chunk-wise attention design.
Double Visual Defense: Adversarial Pre-training and Instruction Tuning for Improving Vision-Language Model Robustness
Jan 16, 2025



This paper investigates the robustness of vision-language models against adversarial visual perturbations and introduces a novel ``double visual defense" to enhance this robustness. Unlike previous approaches that resort to lightweight adversarial fine-tuning of a pre-trained CLIP model, we perform large-scale adversarial vision-language pre-training from scratch using web-scale data. We then strengthen the defense by incorporating adversarial visual instruction tuning. The resulting models from each stage, $\Delta$CLIP and $\Delta^2$LLaVA, show substantially enhanced zero-shot robustness and set a new state-of-the-art in adversarial defense for vision-language models. For example, the adversarial robustness of $\Delta$CLIP surpasses that of the previous best models on ImageNet-1k by ~20%. %For example, $\Delta$CLIP surpasses the previous best models on ImageNet-1k by ~20% in terms of adversarial robustness. Similarly, compared to prior art, $\Delta^2$LLaVA brings a ~30% robustness improvement to image captioning task and a ~20% robustness improvement to visual question answering task. Furthermore, our models exhibit stronger zero-shot recognition capability, fewer hallucinations, and superior reasoning performance compared to baselines. Our project page is https://doublevisualdefense.github.io/.