 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence
Nov 10, 2025Recent advances in depth-recurrent language models show that recurrence can decouple train-time compute and parameter count from test-time compute. In this work, we study how to convert existing pretrained non-recurrent language models into depth-recurrent models. We find that using a curriculum of recurrences to increase the effective depth of the model over the course of training preserves performance while reducing total computational cost. In our experiments, on mathematics, we observe that converting pretrained models to recurrent ones results in better performance at a given compute budget than simply post-training the original non-recurrent language model.
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Sep 30, 2025Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at https://github.com/HyperPotatoNeo/RSA.
Modeling Code: Is Text All You Need?
Jul 15, 2025Code LLMs have become extremely popular recently for modeling source code across a variety of tasks, such as generation, translation, and summarization. However, transformer-based models are limited in their capabilities to reason through structured, analytical properties of code, such as control and data flow. Previous work has explored the modeling of these properties with structured data and graph neural networks. However, these approaches lack the generative capabilities and scale of modern LLMs. In this work, we introduce a novel approach to combine the strengths of modeling both code as text and more structured forms.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
AegisLLM: Scaling Agentic Systems for Self-Reflective Defense in LLM Security
Apr 29, 2025We introduce AegisLLM, a cooperative multi-agent defense against adversarial attacks and information leakage. In AegisLLM, a structured workflow of autonomous agents - orchestrator, deflector, responder, and evaluator - collaborate to ensure safe and compliant LLM outputs, while self-improving over time through prompt optimization. We show that scaling agentic reasoning system at test-time - both by incorporating additional agent roles and by leveraging automated prompt optimization (such as DSPy)- substantially enhances robustness without compromising model utility. This test-time defense enables real-time adaptability to evolving attacks, without requiring model retraining. Comprehensive evaluations across key threat scenarios, including unlearning and jailbreaking, demonstrate the effectiveness of AegisLLM. On the WMDP unlearning benchmark, AegisLLM achieves near-perfect unlearning with only 20 training examples and fewer than 300 LM calls. For jailbreaking benchmarks, we achieve 51% improvement compared to the base model on StrongReject, with false refusal rates of only 7.9% on PHTest compared to 18-55% for comparable methods. Our results highlight the advantages of adaptive, agentic reasoning over static defenses, establishing AegisLLM as a strong runtime alternative to traditional approaches based on model modifications. Code is available at https://github.com/zikuicai/aegisllm
STAR-1: Safer Alignment of Reasoning LLMs with 1K Data
Apr 02, 2025This paper introduces STAR-1, a high-quality, just-1k-scale safety dataset specifically designed for large reasoning models (LRMs) like DeepSeek-R1. Built on three core principles -- diversity, deliberative reasoning, and rigorous filtering -- STAR-1 aims to address the critical needs for safety alignment in LRMs. Specifically, we begin by integrating existing open-source safety datasets from diverse sources. Then, we curate safety policies to generate policy-grounded deliberative reasoning samples. Lastly, we apply a GPT-4o-based safety scoring system to select training examples aligned with best practices. Experimental results show that fine-tuning LRMs with STAR-1 leads to an average 40% improvement in safety performance across four benchmarks, while only incurring a marginal decrease (e.g., an average of 1.1%) in reasoning ability measured across five reasoning tasks. Extensive ablation studies further validate the importance of our design principles in constructing STAR-1 and analyze its efficacy across both LRMs and traditional LLMs. Our project page is https://ucsc-vlaa.github.io/STAR-1.
Trajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training
Mar 24, 2025Reinforcement learning (RL) is a critical component of large language model (LLM) post-training. However, existing on-policy algorithms used for post-training are inherently incompatible with the use of experience replay buffers, which can be populated scalably by distributed off-policy actors to enhance exploration as compute increases. We propose efficiently obtaining this benefit of replay buffers via Trajectory Balance with Asynchrony (TBA), a massively scalable LLM RL system. In contrast to existing approaches, TBA uses a larger fraction of compute on search, constantly generating off-policy data for a central replay buffer. A training node simultaneously samples data from this buffer based on reward or recency to update the policy using Trajectory Balance (TB), a diversity-seeking RL objective introduced for GFlowNets. TBA offers three key advantages: (1) decoupled training and search, speeding up training wall-clock time by 4x or more; (2) improved diversity through large-scale off-policy sampling; and (3) scalable search for sparse reward settings. On mathematical reasoning, preference-tuning, and automated red-teaming (diverse and representative post-training tasks), TBA produces speed and performance improvements over strong baselines.
Constrained Language Generation with Discrete Diffusion Models
Mar 12, 2025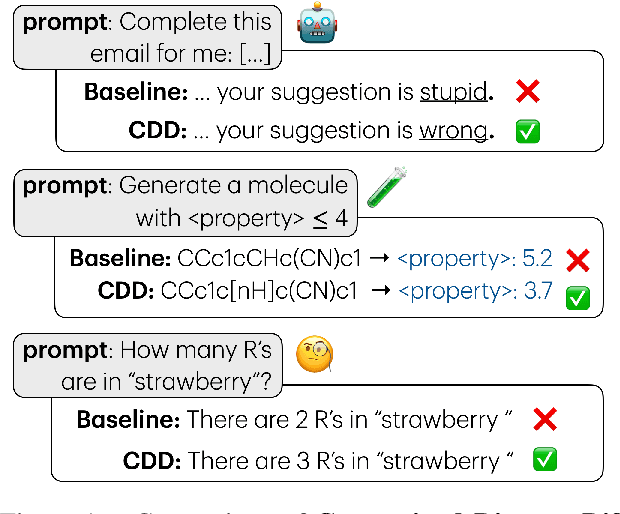



Constraints are critical in text generation as LLM outputs are often unreliable when it comes to ensuring generated outputs adhere to user defined instruction or general safety guidelines. To address this gap, we present Constrained Discrete Diffusion (CDD), a novel method for enforcing constraints on natural language by integrating discrete diffusion models with differentiable optimization. Unlike conventional text generators, which often rely on post-hoc filtering or model retraining for controllable generation, we propose imposing constraints directly into the discrete diffusion sampling process. We illustrate how this technique can be applied to satisfy a variety of natural language constraints, including (i) toxicity mitigation by preventing harmful content from emerging, (ii) character and sequence level lexical constraints, and (iii) novel molecule sequence generation with specific property adherence. Experimental results show that our constraint-aware procedure achieves high fidelity in meeting these requirements while preserving fluency and semantic coherence, outperforming auto-regressive and existing discrete diffusion approaches.
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Feb 07, 2025



We study a novel language model architecture that is capable of scaling test-time computation by implicitly reasoning in latent space. Our model works by iterating a recurrent block, thereby unrolling to arbitrary depth at test-time. This stands in contrast to mainstream reasoning models that scale up compute by producing more tokens. Unlike approaches based on chain-of-thought, our approach does not require any specialized training data, can work with small context windows, and can capture types of reasoning that are not easily represented in words. We scale a proof-of-concept model to 3.5 billion parameters and 800 billion tokens. We show that the resulting model can improve its performance on reasoning benchmarks, sometimes dramatically, up to a computation load equivalent to 50 billion parameters.
ELFS: Enhancing Label-Free Coreset Selection via Clustering-based Pseudo-Labeling
Jun 06, 2024



High-quality human-annotated data is crucial for modern deep learning pipelines, yet the human annotation process is both costly and time-consuming. Given a constrained human labeling budget, selecting an informative and representative data subset for labeling can significantly reduce human annotation effort. Well-performing state-of-the-art (SOTA) coreset selection methods require ground-truth labels over the whole dataset, failing to reduce the human labeling burden. Meanwhile, SOTA label-free coreset selection methods deliver inferior performance due to poor geometry-based scores. In this paper, we introduce ELFS, a novel label-free coreset selection method. ELFS employs deep clustering to estimate data difficulty scores without ground-truth labels. Furthermore, ELFS uses a simple but effective double-end pruning method to mitigate bias on calculated scores, which further improves the performance on selected coresets. We evaluate ELFS on five vision benchmarks and show that ELFS consistently outperforms SOTA label-free baselines. For instance, at a 90% pruning rate, ELFS surpasses the best-performing baseline by 5.3% on CIFAR10 and 7.1% on CIFAR100. Moreover, ELFS even achieves comparable performance to supervised coreset selection at low pruning rates (e.g., 30% and 50%) on CIFAR10 and ImageNet-1K.