 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Causal Effect of Data in Class-Incremental Learning
Mar 08, 2021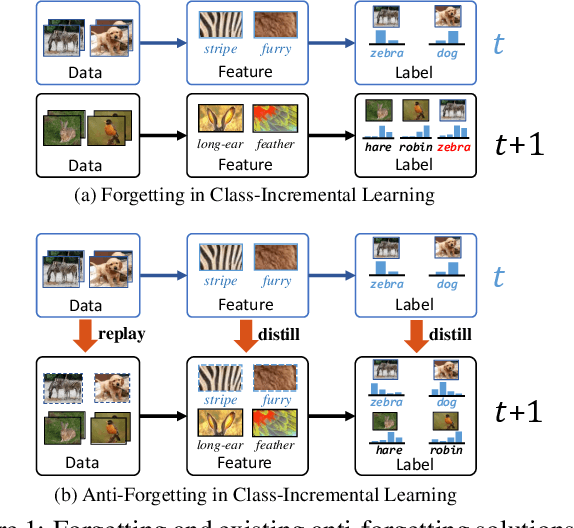
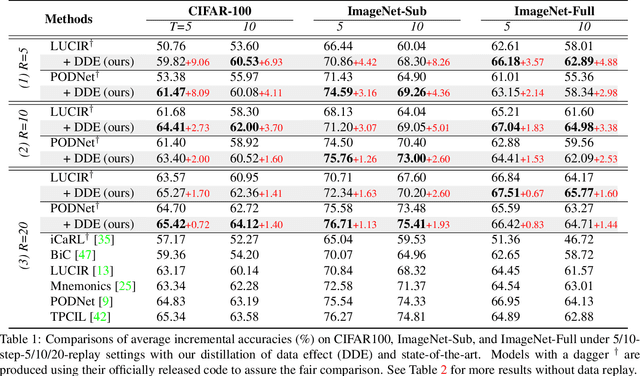
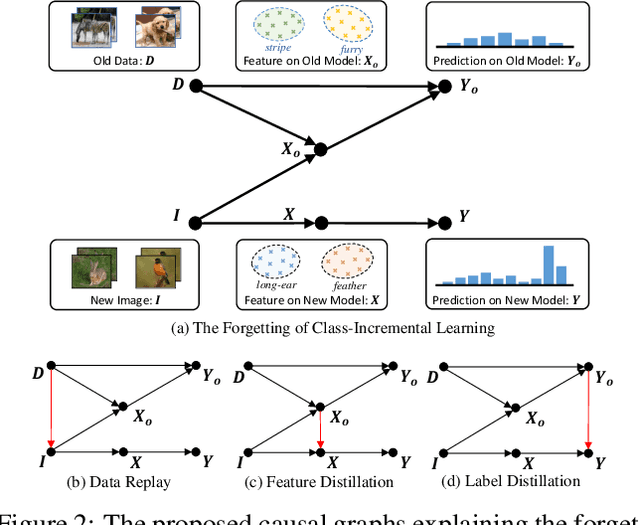
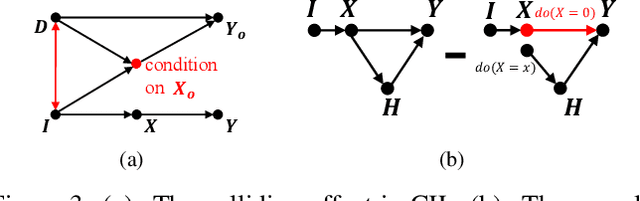
We propose a causal framework to explain the catastrophic forgetting in Class-Incremental Learning (CIL) and then derive a novel distillation method that is orthogonal to the existing anti-forgetting techniques, such as data replay and feature/label distillation. We first 1) place CIL into the framework, 2) answer why the forgetting happens: the causal effect of the old data is lost in new training, and then 3) explain how the existing techniques mitigate it: they bring the causal effect back. Based on the framework, we find that although the feature/label distillation is storage-efficient, its causal effect is not coherent with the end-to-end feature learning merit, which is however preserved by data replay. To this end, we propose to distill the Colliding Effect between the old and the new data, which is fundamentally equivalent to the causal effect of data replay, but without any cost of replay storage. Thanks to the causal effect analysis, we can further capture the Incremental Momentum Effect of the data stream, removing which can help to retain the old effect overwhelmed by the new data effect, and thus alleviate the forgetting of the old class in testing. Extensive experiments on three CIL benchmarks: CIFAR-100, ImageNet-Sub&Full, show that the proposed causal effect distillation can improve various state-of-the-art CIL methods by a large margin (0.72%--9.06%).
HYDRA: Hypergradient Data Relevance Analysis for Interpreting Deep Neural Networks
Mar 01, 2021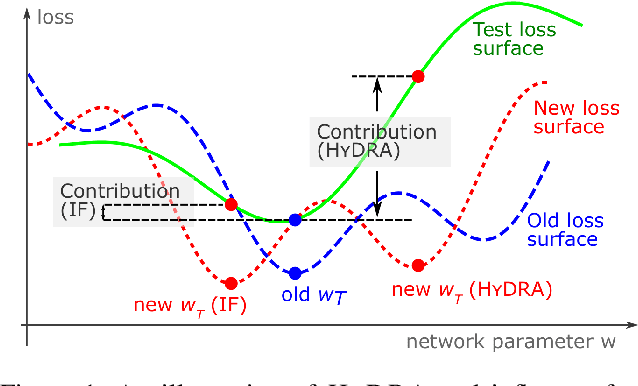
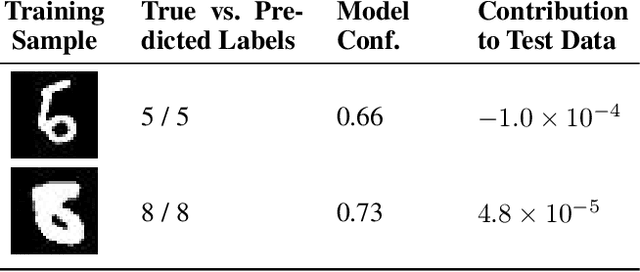
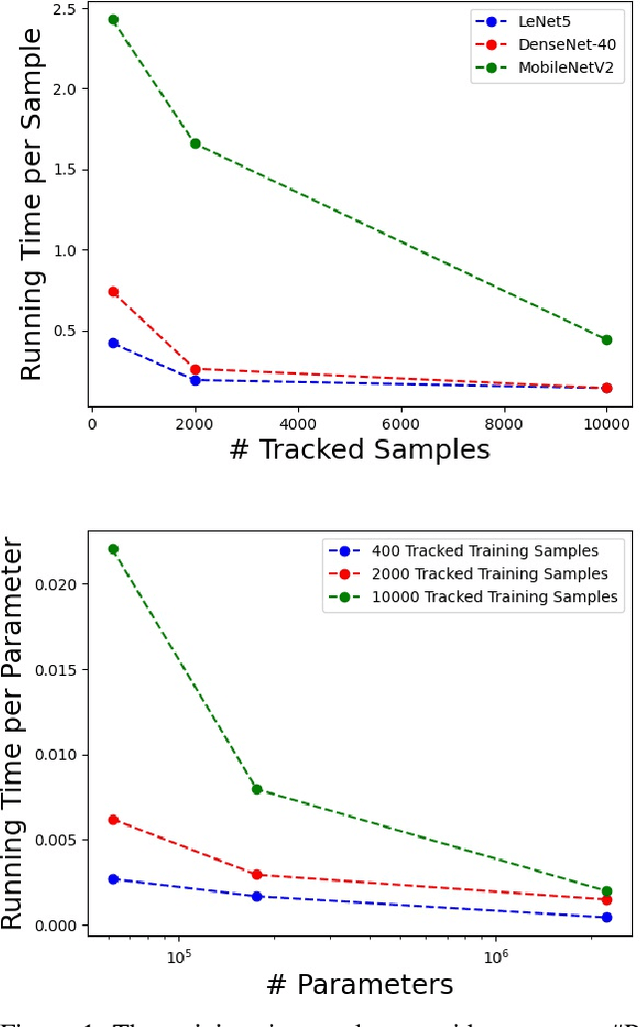
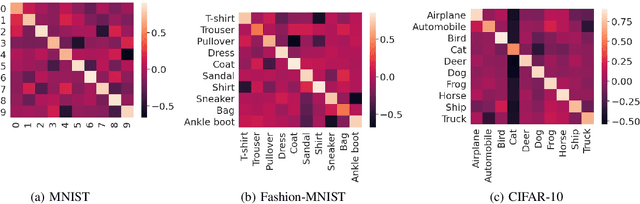
The behaviors of deep neural networks (DNNs) are notoriously resistant to human interpretations. In this paper, we propose Hypergradient Data Relevance Analysis, or HYDRA, which interprets the predictions made by DNNs as effects of their training data. Existing approaches generally estimate data contributions around the final model parameters and ignore how the training data shape the optimization trajectory. By unrolling the hypergradient of test loss w.r.t. the weights of training data, HYDRA assesses the contribution of training data toward test data points throughout the training trajectory. In order to accelerate computation, we remove the Hessian from the calculation and prove that, under moderate conditions, the approximation error is bounded. Corroborating this theoretical claim, empirical results indicate the error is indeed small. In addition, we quantitatively demonstrate that HYDRA outperforms influence functions in accurately estimating data contribution and detecting noisy data labels. The source code is available at https://github.com/cyyever/aaai_hydra_8686.
Keyword-Guided Neural Conversational Model
Dec 27, 2020
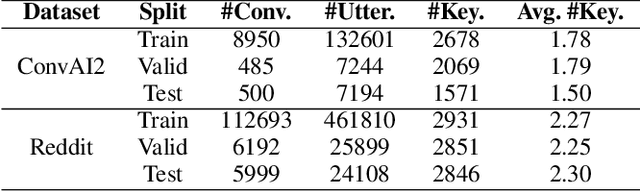

We study the problem of imposing conversational goals/keywords on open-domain conversational agents, where the agent is required to lead the conversation to a target keyword smoothly and fast. Solving this problem enables the application of conversational agents in many real-world scenarios, e.g., recommendation and psychotherapy. The dominant paradigm for tackling this problem is to 1) train a next-turn keyword classifier, and 2) train a keyword-augmented response retrieval model. However, existing approaches in this paradigm have two limitations: 1) the training and evaluation datasets for next-turn keyword classification are directly extracted from conversations without human annotations, thus, they are noisy and have low correlation with human judgements, and 2) during keyword transition, the agents solely rely on the similarities between word embeddings to move closer to the target keyword, which may not reflect how humans converse. In this paper, we assume that human conversations are grounded on commonsense and propose a keyword-guided neural conversational model that can leverage external commonsense knowledge graphs (CKG) for both keyword transition and response retrieval. Automatic evaluations suggest that commonsense improves the performance of both next-turn keyword prediction and keyword-augmented response retrieval. In addition, both self-play and human evaluations show that our model produces responses with smoother keyword transition and reaches the target keyword faster than competitive baselines.
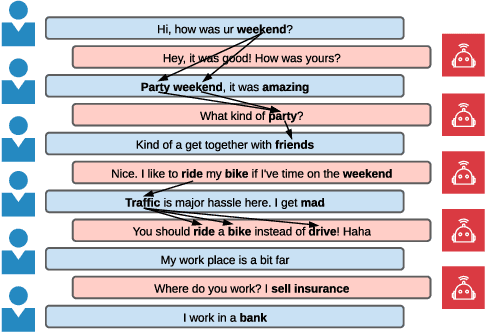
Brain-inspired Search Engine Assistant based on Knowledge Graph
Dec 25, 2020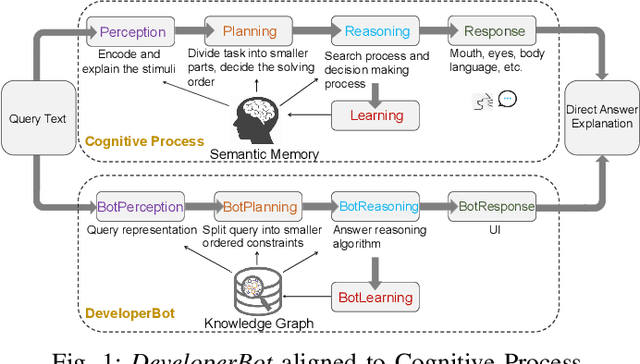
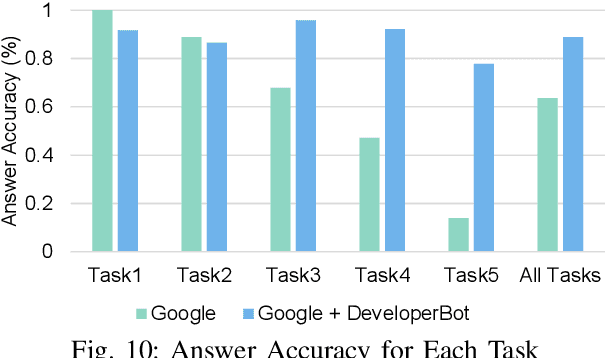
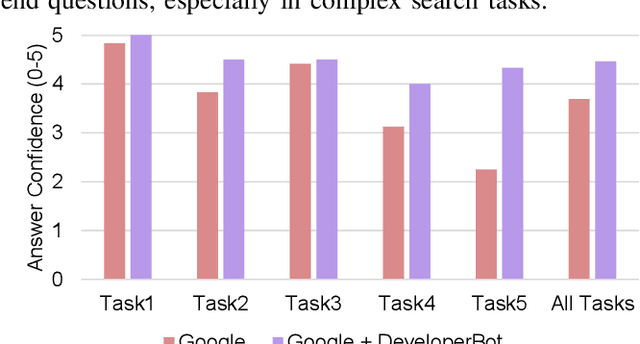
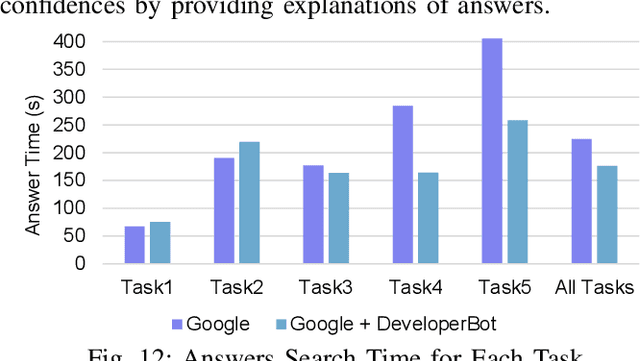
Search engines can quickly response a hyperlink list according to query keywords. However, when a query is complex, developers need to repeatedly refine the search keywords and open a large number of web pages to find and summarize answers. Many research works of question and answering (Q and A) system attempt to assist search engines by providing simple, accurate and understandable answers. However, without original semantic contexts, these answers lack explainability, making them difficult for users to trust and adopt. In this paper, a brain-inspired search engine assistant named DeveloperBot based on knowledge graph is proposed, which aligns to the cognitive process of human and has the capacity to answer complex queries with explainability. Specifically, DeveloperBot firstly constructs a multi-layer query graph by splitting a complex multi-constraint query into several ordered constraints. Then it models the constraint reasoning process as subgraph search process inspired by the spreading activation model of cognitive science. In the end, novel features of the subgraph will be extracted for decision-making. The corresponding reasoning subgraph and answer confidence will be derived as explanations. The results of the decision-making demonstrate that DeveloperBot can estimate the answers and answer confidences with high accuracy. We implement a prototype and conduct a user study to evaluate whether and how the direct answers and the explanations provided by DeveloperBot can assist developers' information needs.
A Hybrid Bandit Framework for Diversified Recommendation
Dec 24, 2020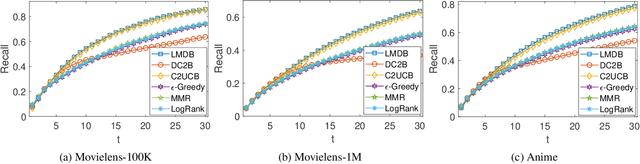
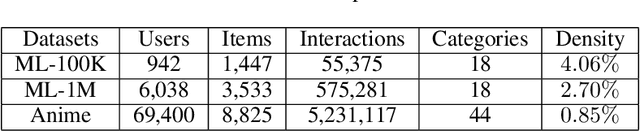
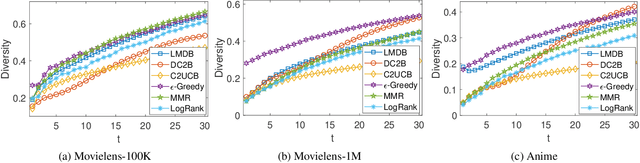
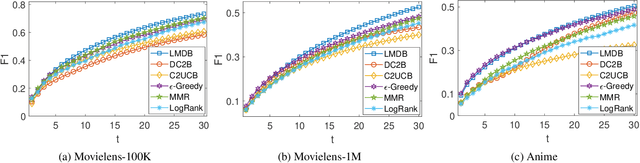
The interactive recommender systems involve users in the recommendation procedure by receiving timely user feedback to update the recommendation policy. Therefore, they are widely used in real application scenarios. Previous interactive recommendation methods primarily focus on learning users' personalized preferences on the relevance properties of an item set. However, the investigation of users' personalized preferences on the diversity properties of an item set is usually ignored. To overcome this problem, we propose the Linear Modular Dispersion Bandit (LMDB) framework, which is an online learning setting for optimizing a combination of modular functions and dispersion functions. Specifically, LMDB employs modular functions to model the relevance properties of each item, and dispersion functions to describe the diversity properties of an item set. Moreover, we also develop a learning algorithm, called Linear Modular Dispersion Hybrid (LMDH) to solve the LMDB problem and derive a gap-free bound on its n-step regret. Extensive experiments on real datasets are performed to demonstrate the effectiveness of the proposed LMDB framework in balancing the recommendation accuracy and diversity.
CARE: Commonsense-Aware Emotional Response Generation with Latent Concepts
Dec 15, 2020
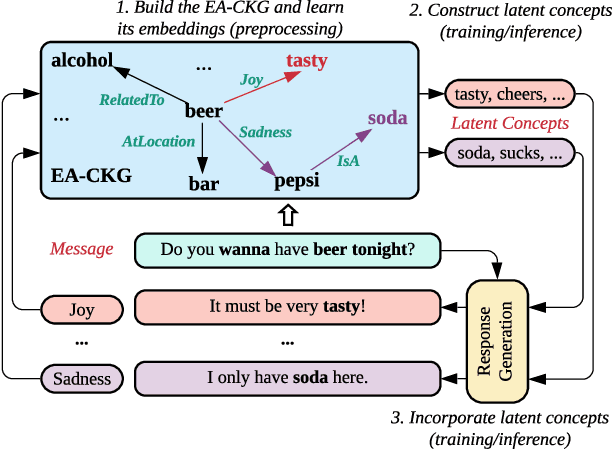

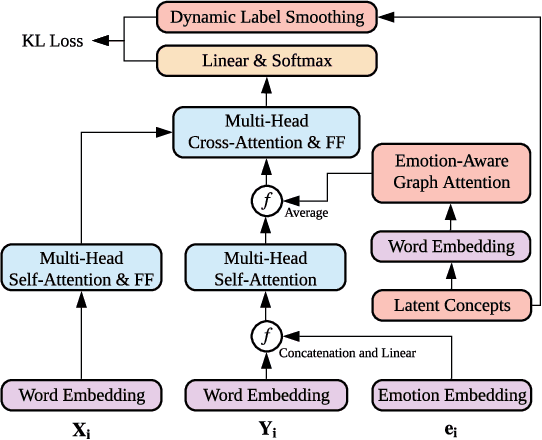
Rationality and emotion are two fundamental elements of humans. Endowing agents with rationality and emotion has been one of the major milestones in AI. However, in the field of conversational AI, most existing models only specialize in one aspect and neglect the other, which often leads to dull or unrelated responses. In this paper, we hypothesize that combining rationality and emotion into conversational agents can improve response quality. To test the hypothesis, we focus on one fundamental aspect of rationality, i.e., commonsense, and propose CARE, a novel model for commonsense-aware emotional response generation. Specifically, we first propose a framework to learn and construct commonsense-aware emotional latent concepts of the response given an input message and a desired emotion. We then propose three methods to collaboratively incorporate the latent concepts into response generation. Experimental results on two large-scale datasets support our hypothesis and show that our model can produce more accurate and commonsense-aware emotional responses and achieve better human ratings than state-of-the-art models that only specialize in one aspect.
Federated Learning with Diversified Preference for Humor Recognition
Dec 03, 2020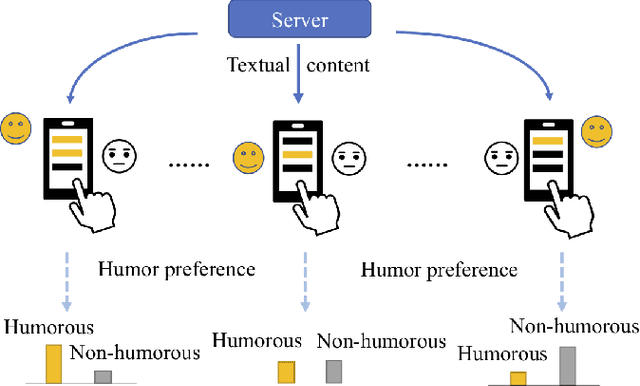
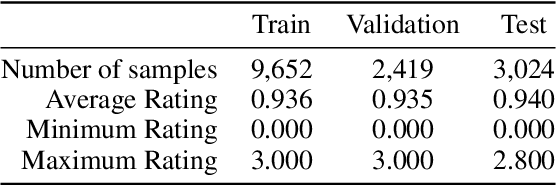
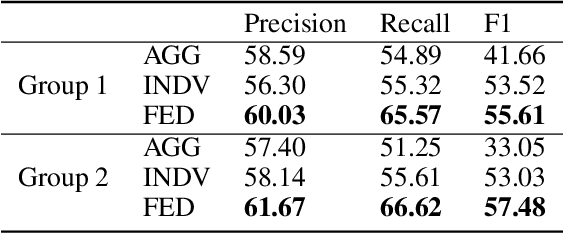
Understanding humor is critical to creative language modeling with many applications in human-AI interaction. However, due to differences in the cognitive systems of the audience, the perception of humor can be highly subjective. Thus, a given passage can be regarded as funny to different degrees by different readers. This makes training humorous text recognition models that can adapt to diverse humor preferences highly challenging. In this paper, we propose the FedHumor approach to recognize humorous text contents in a personalized manner through federated learning (FL). It is a federated BERT model capable of jointly considering the overall distribution of humor scores with humor labels by individuals for given texts. Extensive experiments demonstrate significant advantages of FedHumor in recognizing humor contents accurately for people with diverse humor preferences compared to 9 state-of-the-art humor recognition approaches.
DAGA: Data Augmentation with a Generation Approach for Low-resource Tagging Tasks
Nov 03, 2020

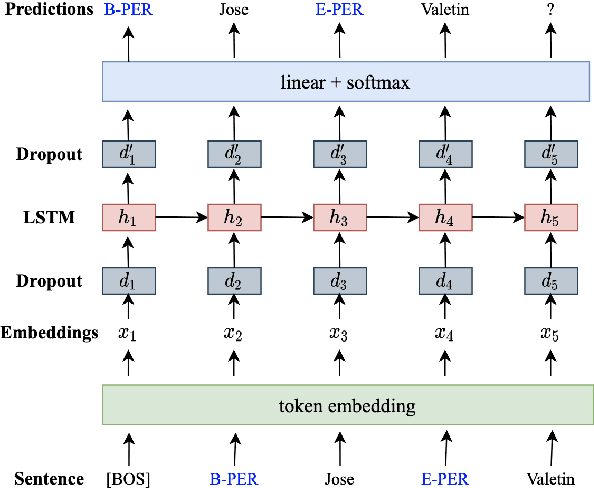
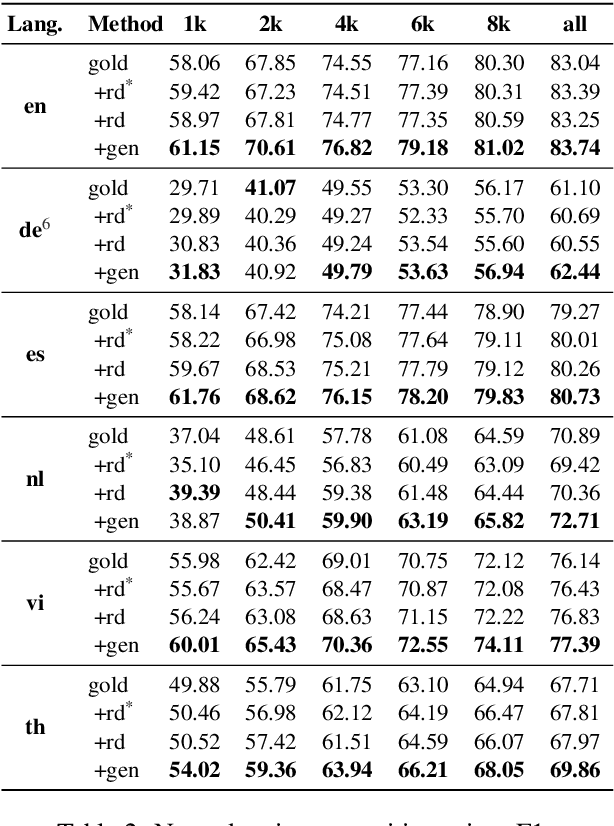
Data augmentation techniques have been widely used to improve machine learning performance as they enhance the generalization capability of models. In this work, to generate high quality synthetic data for low-resource tagging tasks, we propose a novel augmentation method with language models trained on the linearized labeled sentences. Our method is applicable to both supervised and semi-supervised settings. For the supervised settings, we conduct extensive experiments on named entity recognition (NER), part of speech (POS) tagging and end-to-end target based sentiment analysis (E2E-TBSA) tasks. For the semi-supervised settings, we evaluate our method on the NER task under the conditions of given unlabeled data only and unlabeled data plus a knowledge base. The results show that our method can consistently outperform the baselines, particularly when the given gold training data are less.
Commonsense knowledge adversarial dataset that challenges ELECTRA
Oct 25, 2020
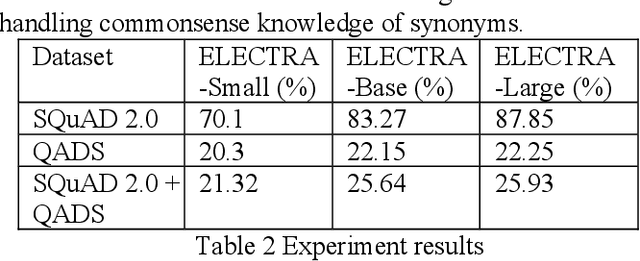
Commonsense knowledge is critical in human reading comprehension. While machine comprehension has made significant progress in recent years, the ability in handling commonsense knowledge remains limited. Synonyms are one of the most widely used commonsense knowledge. Constructing adversarial dataset is an important approach to find weak points of machine comprehension models and support the design of solutions. To investigate machine comprehension models' ability in handling the commonsense knowledge, we created a Question and Answer Dataset with common knowledge of Synonyms (QADS). QADS are questions generated based on SQuAD 2.0 by applying commonsense knowledge of synonyms. The synonyms are extracted from WordNet. Words often have multiple meanings and synonyms. We used an enhanced Lesk algorithm to perform word sense disambiguation to identify synonyms for the context. ELECTRA achieves the state-of-art result on the SQuAD 2.0 dataset in 2019. With scale, ELECTRA can achieve similar performance as BERT does. However, QADS shows that ELECTRA has little ability to handle commonsense knowledge of synonyms. In our experiment, ELECTRA-small can achieve 70% accuracy on SQuAD 2.0, but only 20% on QADS. ELECTRA-large did not perform much better. Its accuracy on SQuAD 2.0 is 88% but dropped significantly to 26% on QADS. In our earlier experiments, BERT, although also failed badly on QADS, was not as bad as ELECTRA. The result shows that even top-performing NLP models have little ability to handle commonsense knowledge which is essential in reading comprehension.
A Pre-training Strategy for Recommendation
Oct 23, 2020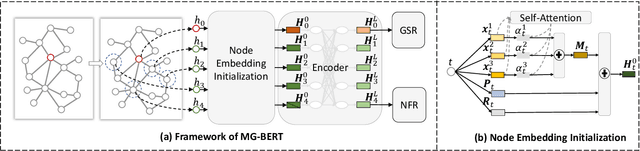
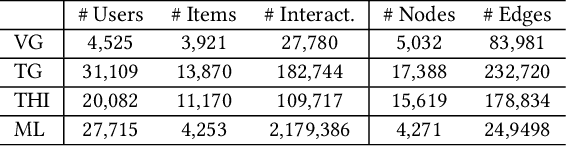
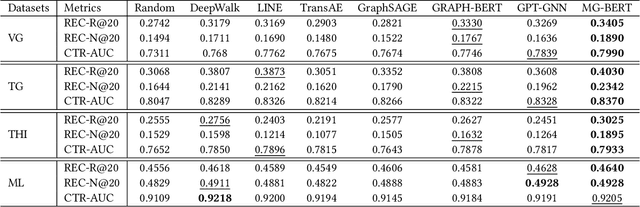
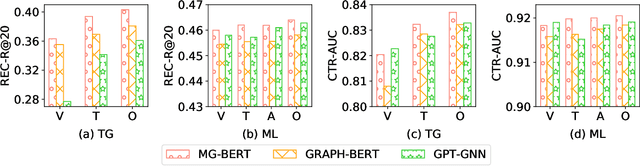
The side information of items has been shown to be effective in building the recommendation systems. Various methods have been developed to exploit the item side information for learning users' preferences on items. Differing from previous work, this paper focuses on developing an unsupervised pre-training strategy, which can exploit the items' multimodality side information (e.g., text and images) to learn the item representations that may benefit downstream applications, such as personalized item recommendation and click-through ratio prediction. Firstly, we employ a multimodal graph to describe the relationships between items and their multimodal feature information. Then, we propose a novel graph neural network, named Multimodal Graph-BERT (MG-BERT), to learn the item representations based on the item multimodal graph. Specifically, MG-BERT is trained by solving the following two graph reconstruction problems, i.e., graph structure reconstruction and masked node feature reconstruction. Experimental results on real datasets demonstrate that the proposed MG-BERT can effectively exploit the multimodality information of items to help downstream applications.