 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Mar 25, 2026Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To circumvent this, previous studies simulate dysfluent speech to generate training data. However, those approaches are not comprehensive enough to simulate PPA as holistic, multi-level phenotypes, instead relying on isolated dysfluencies. To address this, we propose a novel, clinically grounded simulation framework, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate behaviors of logopenic variant of PPA (lvPPA) with varying degrees of severity. To this end, semantic, phonological, and temporal deficits of lvPPA are systematically identified by clinical experts, and simulated. We demonstrate that our framework enables more accurate and generalizable detection models.
Conversational Behavior Modeling Foundation Model With Multi-Level Perception
Feb 11, 2026Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this perceptual pathway is key to building natural full-duplex interactive systems. We introduce a framework that models this process as multi-level perception, and then reasons over conversational behaviors via a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a high quality corpus that pairs controllable, event-rich dialogue data with human-annotated labels. The GoT framework structures streaming predictions as an evolving graph, enabling a transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
Asymmetric Hierarchical Anchoring for Audio-Visual Joint Representation: Resolving Information Allocation Ambiguity for Robust Cross-Modal Generalization
Feb 03, 2026Audio-visual joint representation learning under Cross-Modal Generalization (CMG) aims to transfer knowledge from a labeled source modality to an unlabeled target modality through a unified discrete representation space. Existing symmetric frameworks often suffer from information allocation ambiguity, where the absence of structural inductive bias leads to semantic-specific leakage across modalities. We propose Asymmetric Hierarchical Anchoring (AHA), which enforces directional information allocation by designating a structured semantic anchor within a shared hierarchy. In our instantiation, we exploit the hierarchical discrete representations induced by audio Residual Vector Quantization (RVQ) to guide video feature distillation into a shared semantic space. To ensure representational purity, we replace fragile mutual information estimators with a GRL-based adversarial decoupler that explicitly suppresses semantic leakage in modality-specific branches, and introduce Local Sliding Alignment (LSA) to encourage fine-grained temporal alignment across modalities. Extensive experiments on AVE and AVVP benchmarks demonstrate that AHA consistently outperforms symmetric baselines in cross-modal transfer. Additional analyses on talking-face disentanglement experiment further validate that the learned representations exhibit improved semantic consistency and disentanglement, indicating the broader applicability of the proposed framework.
HuPER: A Human-Inspired Framework for Phonetic Perception
Feb 02, 2026We propose HuPER, a human-inspired framework that models phonetic perception as adaptive inference over acoustic-phonetics evidence and linguistic knowledge. With only 100 hours of training data, HuPER achieves state-of-the-art phonetic error rates on five English benchmarks and strong zero-shot transfer to 95 unseen languages. HuPER is also the first framework to enable adaptive, multi-path phonetic perception under diverse acoustic conditions. All training data, models, and code are open-sourced. Code and demo avaliable at https://github.com/HuPER29/HuPER.
Enabling Conversational Behavior Reasoning Capabilities in Full-Duplex Speech
Dec 25, 2025



Human conversation is organized by an implicit chain of thoughts that manifests as timed speech acts. Capturing this causal pathway is key to building natural full-duplex interactive systems. We introduce a framework that enables reasoning over conversational behaviors by modeling this process as causal inference within a Graph-of-Thoughts (GoT). Our approach formalizes the intent-to-action pathway with a hierarchical labeling scheme, predicting high-level communicative intents and low-level speech acts to learn their causal and temporal dependencies. To train this system, we develop a hybrid corpus that pairs controllable, event-rich simulations with human-annotated rationales and real conversational speech. The GoT framework structures streaming predictions as an evolving graph, enabling a multimodal transformer to forecast the next speech act, generate concise justifications for its decisions, and dynamically refine its reasoning. Experiments on both synthetic and real duplex dialogues show that the framework delivers robust behavior detection, produces interpretable reasoning chains, and establishes a foundation for benchmarking conversational reasoning in full duplex spoken dialogue systems.
EMO-Reasoning: Benchmarking Emotional Reasoning Capabilities in Spoken Dialogue Systems
Aug 25, 2025Speech emotions play a crucial role in human-computer interaction, shaping engagement and context-aware communication. Despite recent advances in spoken dialogue systems, a holistic system for evaluating emotional reasoning is still lacking. To address this, we introduce EMO-Reasoning, a benchmark for assessing emotional coherence in dialogue systems. It leverages a curated dataset generated via text-to-speech to simulate diverse emotional states, overcoming the scarcity of emotional speech data. We further propose the Cross-turn Emotion Reasoning Score to assess the emotion transitions in multi-turn dialogues. Evaluating seven dialogue systems through continuous, categorical, and perceptual metrics, we show that our framework effectively detects emotional inconsistencies, providing insights for improving current dialogue systems. By releasing a systematic evaluation benchmark, we aim to advance emotion-aware spoken dialogue modeling toward more natural and adaptive interactions.
LCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Aug 05, 2025Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
May 28, 2025Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys -- the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
May 22, 2025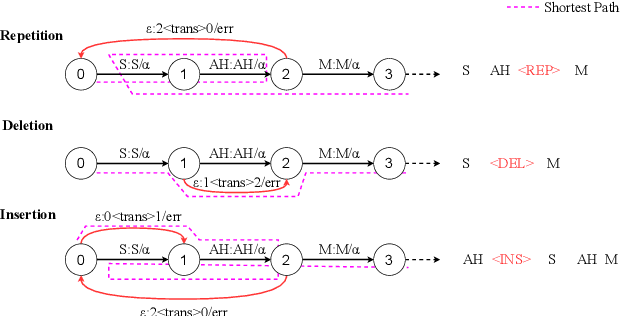

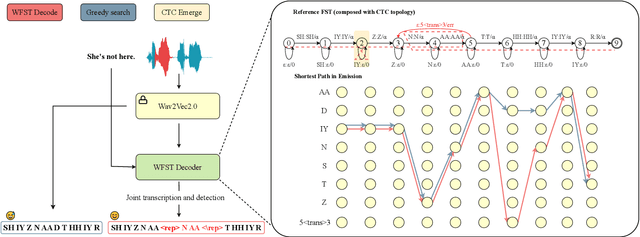
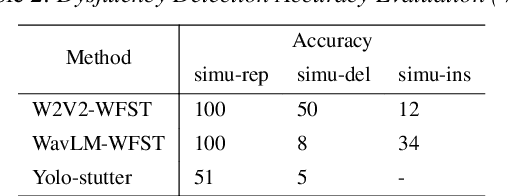
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.
Full-Duplex-Bench: A Benchmark to Evaluate Full-duplex Spoken Dialogue Models on Turn-taking Capabilities
Mar 06, 2025



Spoken dialogue modeling introduces unique challenges beyond text-based language modeling, demanding robust turn-taking, backchanneling, and real-time interaction. Although most Spoken Dialogue Models (SDMs) rely on half-duplex processing (handling speech one turn at a time), emerging full-duplex SDMs can listen and speak simultaneously, enabling more natural and engaging conversations. However, current evaluations of such models remain limited, often focusing on turn-based metrics or high-level corpus analyses (e.g., turn gaps, pauses). To address this gap, we present Full-Duplex-Bench, a new benchmark that systematically evaluates key conversational behaviors: pause handling, backchanneling, turn-taking, and interruption management. Our framework uses automatic metrics for consistent and reproducible assessments of SDMs' interactive performance. By offering an open and standardized evaluation benchmark, we aim to advance spoken dialogue modeling and encourage the development of more interactive and natural dialogue systems.