 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPC-3D-Diff: Equivariant Physics Consistent Conditional 3D Latent Diffusion for CBCT to CT Synthesis
May 19, 2026Cone-beam CT (CBCT) is routinely acquired during radiotherapy for patient setup, but its quantitative reliability is degraded by scatter, noise, and reconstruction artifacts, limiting Hounsfield Unit (HU) accuracy. We propose EPC-3D-Diff, a novel conditional 3D latent diffusion framework for volumetric CBCT to CT synthesis that introduces a projection domain equivariance loss derived from acquisition physics. Unlike common image domain equivariance, we exploit the fact that an in plane rotation of the volume corresponds to an angular shift in its projections. During training, we enforce this relationship by forward projecting rotated synthesized CT volumes and matching them to appropriately angle shifted projections of the paired target CT, yielding a physics consistent equivariance constraint integrated into the diffusion objective. To capture full 3D context efficiently, conditional diffusion is performed in a compact latent space learnt by a lightweight 3D autoencoder, preserving axial depth while downsampling in plane resolution for stable training. We validate on a paired head CBCT/CT phantom dataset, including repeat scans, and paired clinical data using patient wise splits, and perform single and mixed domain training, ablations, and comparisons with diffusion and CycleGAN. EPC-3D-Diff generalizes well and achieved substantial improvements, +7.4 dB (phantom) and +1.8 dB (clinical data) in PSNR compared to state of the art methods, alongside improved SSIM and HU accuracy, within tissue boundaries. Overall, EPC-3D-Diff improves robustness and physics consistency, supporting HU aware synthesis for downstream radiotherapy workflows.
Flexible Multi-Target Angular Emulation for Over-the-Air Testing of Large-Scale ISAC Base Stations: Principle and Experimental Verification
Mar 11, 2026Over-the-air (OTA) emulation of diverse sensing target characteristics in a controlled laboratory environment is pivotal for advancing integrated sensing and communication (ISAC) technology, as it facilitates the non-invasive performance evaluation of ISAC base stations (BSs) across complex scenarios. In this work, a flexible multi-target OTA emulation framework based on a wireless cable method is proposed to evaluate the sensing performance of large-scale ISAC BSs. The core concept leverages an amplitude and phase modulation (APM) network to simultaneously establish wireless cables and simulate target spatial characteristics without consuming additional resources on costly radar target emulators. For the wireless cable method, the condition number increases as the number of antennas scales up, which affects the performance of the wireless cable. Although the wireless cable concept has been established for devices-under-test (DUTs) with a limited number of antenna ports, establishing wireless cables for large-scale DUTs remains an open question in the community. We address this problem by optimizing the OTA probe array configuration based on the theoretical properties of strictly diagonally dominant matrices. Experimental results validate the proposed framework, demonstrating high-isolation wireless cables for a 32-element DUT and an extremely low condition number for a 128-element synthetic array. Furthermore, the OTA emulation of a dynamic dual-drone scenario confirms the method's effectiveness and practicality in reproducing complex sensing environments.
EqDiff-CT: Equivariant Conditional Diffusion model for CT Image Synthesis from CBCT
Sep 26, 2025



Cone-beam computed tomography (CBCT) is widely used for image-guided radiotherapy (IGRT). It provides real time visualization at low cost and dose. However, photon scattering and beam hindrance cause artifacts in CBCT. These include inaccurate Hounsfield Units (HU), reducing reliability for dose calculation, and adaptive planning. By contrast, computed tomography (CT) offers better image quality and accurate HU calibration but is usually acquired offline and fails to capture intra-treatment anatomical changes. Thus, accurate CBCT-to-CT synthesis is needed to close the imaging-quality gap in adaptive radiotherapy workflows. To cater to this, we propose a novel diffusion-based conditional generative model, coined EqDiff-CT, to synthesize high-quality CT images from CBCT. EqDiff-CT employs a denoising diffusion probabilistic model (DDPM) to iteratively inject noise and learn latent representations that enable reconstruction of anatomically consistent CT images. A group-equivariant conditional U-Net backbone, implemented with e2cnn steerable layers, enforces rotational equivariance (cyclic C4 symmetry), helping preserve fine structural details while minimizing noise and artifacts. The system was trained and validated on the SynthRAD2025 dataset, comprising CBCT-CT scans across multiple head-and-neck anatomical sites, and we compared it with advanced methods such as CycleGAN and DDPM. EqDiff-CT provided substantial gains in structural fidelity, HU accuracy and quantitative metrics. Visual findings further confirm the improved recovery, sharper soft tissue boundaries, and realistic bone reconstructions. The findings suggest that the diffusion model has offered a robust and generalizable framework for CBCT improvements. The proposed solution helps in improving the image quality as well as the clinical confidence in the CBCT-guided treatment planning and dose calculations.
JARVIS: A Multi-Agent Code Assistant for High-Quality EDA Script Generation
May 20, 2025



This paper presents JARVIS, a novel multi-agent framework that leverages Large Language Models (LLMs) and domain expertise to generate high-quality scripts for specialized Electronic Design Automation (EDA) tasks. By combining a domain-specific LLM trained with synthetically generated data, a custom compiler for structural verification, rule enforcement, code fixing capabilities, and advanced retrieval mechanisms, our approach achieves significant improvements over state-of-the-art domain-specific models. Our framework addresses the challenges of data scarcity and hallucination errors in LLMs, demonstrating the potential of LLMs in specialized engineering domains. We evaluate our framework on multiple benchmarks and show that it outperforms existing models in terms of accuracy and reliability. Our work sets a new precedent for the application of LLMs in EDA and paves the way for future innovations in this field.
Channel Sounding Using Multiplicative Arrays Based on Successive Interference Cancellation Principle
Jan 19, 2025



Ultra-massive multiple-input and multiple-output (MIMO) systems have been seen as the key radio technology for the advancement of wireless communication systems, due to its capability to better utilize the spatial dimension of the propagation channels. Channel sounding is essential for developing accurate and realistic channel models for the massive MIMO systems. However, channel sounding with large-scale antenna systems has faced significant challenges in practice. The real antenna array based (RAA) sounder suffers from high complexity and cost, while virtual antenna array (VAA) solutions are known for its long measurement time. Notably, these issues will become more pronounced as the antenna array configuration gets larger for future radio systems. In this paper, we propose the concept of multiplicative array (MA) for channel sounding applications to achieve large antenna aperture size with reduced number of required antenna elements. The unique characteristics of the MA are exploited for wideband spatial channel sounding purposes, supported by both one-path and multi-path numerical simulations. To address the fake paths and distortion in the angle delay profile issues inherent for MA in multipath channel sounding, a novel channel parameter estimation algorithm for MA based on successive interference cancellation (SIC) principle is proposed. Both numerical simulations and experimental validation results are provided to demonstrate the effectiveness and robustness of the proposed SIC algorithm for the MA. This research contributes significantly to the channel sounding and characterization of massive MIMO systems for future applications.
Bifurcated Generative Flow Networks
Jun 04, 2024

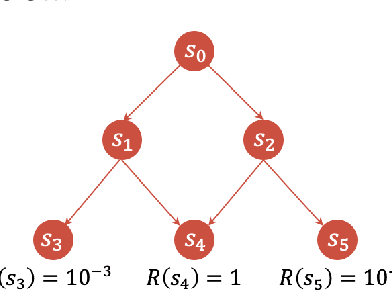
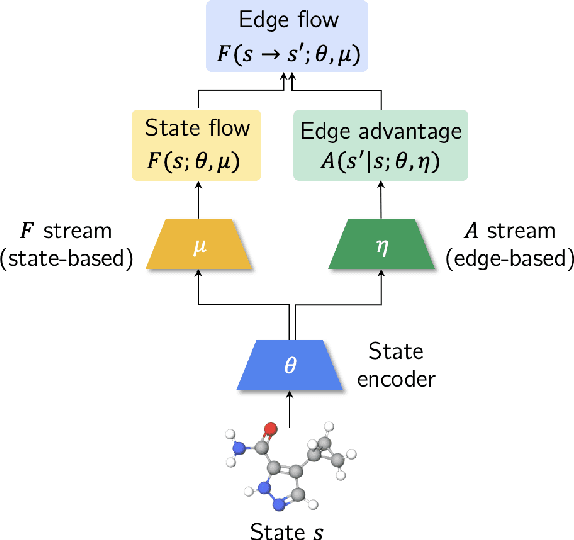
Generative Flow Networks (GFlowNets), a new family of probabilistic samplers, have recently emerged as a promising framework for learning stochastic policies that generate high-quality and diverse objects proportionally to their rewards. However, existing GFlowNets often suffer from low data efficiency due to the direct parameterization of edge flows or reliance on backward policies that may struggle to scale up to large action spaces. In this paper, we introduce Bifurcated GFlowNets (BN), a novel approach that employs a bifurcated architecture to factorize the flows into separate representations for state flows and edge-based flow allocation. This factorization enables BN to learn more efficiently from data and better handle large-scale problems while maintaining the convergence guarantee. Through extensive experiments on standard evaluation benchmarks, we demonstrate that BN significantly improves learning efficiency and effectiveness compared to strong baselines.
AlignGPT: Multi-modal Large Language Models with Adaptive Alignment Capability
May 23, 2024



Multimodal Large Language Models (MLLMs) are widely regarded as crucial in the exploration of Artificial General Intelligence (AGI). The core of MLLMs lies in their capability to achieve cross-modal alignment. To attain this goal, current MLLMs typically follow a two-phase training paradigm: the pre-training phase and the instruction-tuning phase. Despite their success, there are shortcomings in the modeling of alignment capabilities within these models. Firstly, during the pre-training phase, the model usually assumes that all image-text pairs are uniformly aligned, but in fact the degree of alignment between different image-text pairs is inconsistent. Secondly, the instructions currently used for finetuning incorporate a variety of tasks, different tasks's instructions usually require different levels of alignment capabilities, but previous MLLMs overlook these differentiated alignment needs. To tackle these issues, we propose a new multimodal large language model AlignGPT. In the pre-training stage, instead of treating all image-text pairs equally, we assign different levels of alignment capabilities to different image-text pairs. Then, in the instruction-tuning phase, we adaptively combine these different levels of alignment capabilities to meet the dynamic alignment needs of different instructions. Extensive experimental results show that our model achieves competitive performance on 12 benchmarks.
EFUF: Efficient Fine-grained Unlearning Framework for Mitigating Hallucinations in Multimodal Large Language Models
Feb 15, 2024



Multimodal large language models (MLLMs) have attracted increasing attention in the past few years, but they may still generate descriptions that include objects not present in the corresponding images, a phenomenon known as object hallucination. To eliminate hallucinations, existing methods manually annotate paired responses with and without hallucinations, and then employ various alignment algorithms to improve the alignment capability between images and text. However, they not only demand considerable computation resources during the finetuning stage but also require expensive human annotation to construct paired data needed by the alignment algorithms. To address these issues, we borrow the idea of unlearning and propose an efficient fine-grained unlearning framework (EFUF), which can eliminate hallucinations without the need for paired data. Extensive experiments show that our method consistently reduces hallucinations while preserving the generation quality with modest computational overhead. Our code and datasets will be publicly available.
CPIA Dataset: A Comprehensive Pathological Image Analysis Dataset for Self-supervised Learning Pre-training
Oct 27, 2023Pathological image analysis is a crucial field in computer-aided diagnosis, where deep learning is widely applied. Transfer learning using pre-trained models initialized on natural images has effectively improved the downstream pathological performance. However, the lack of sophisticated domain-specific pathological initialization hinders their potential. Self-supervised learning (SSL) enables pre-training without sample-level labels, which has great potential to overcome the challenge of expensive annotations. Thus, studies focusing on pathological SSL pre-training call for a comprehensive and standardized dataset, similar to the ImageNet in computer vision. This paper presents the comprehensive pathological image analysis (CPIA) dataset, a large-scale SSL pre-training dataset combining 103 open-source datasets with extensive standardization. The CPIA dataset contains 21,427,877 standardized images, covering over 48 organs/tissues and about 100 kinds of diseases, which includes two main data types: whole slide images (WSIs) and characteristic regions of interest (ROIs). A four-scale WSI standardization process is proposed based on the uniform resolution in microns per pixel (MPP), while the ROIs are divided into three scales artificially. This multi-scale dataset is built with the diagnosis habits under the supervision of experienced senior pathologists. The CPIA dataset facilitates a comprehensive pathological understanding and enables pattern discovery explorations. Additionally, to launch the CPIA dataset, several state-of-the-art (SOTA) baselines of SSL pre-training and downstream evaluation are specially conducted. The CPIA dataset along with baselines is available at https://github.com/zhanglab2021/CPIA_Dataset.
M2DF: Multi-grained Multi-curriculum Denoising Framework for Multimodal Aspect-based Sentiment Analysis
Oct 23, 2023



Multimodal Aspect-based Sentiment Analysis (MABSA) is a fine-grained Sentiment Analysis task, which has attracted growing research interests recently. Existing work mainly utilizes image information to improve the performance of MABSA task. However, most of the studies overestimate the importance of images since there are many noise images unrelated to the text in the dataset, which will have a negative impact on model learning. Although some work attempts to filter low-quality noise images by setting thresholds, relying on thresholds will inevitably filter out a lot of useful image information. Therefore, in this work, we focus on whether the negative impact of noisy images can be reduced without modifying the data. To achieve this goal, we borrow the idea of Curriculum Learning and propose a Multi-grained Multi-curriculum Denoising Framework (M2DF), which can achieve denoising by adjusting the order of training data. Extensive experimental results show that our framework consistently outperforms state-of-the-art work on three sub-tasks of MABSA.