 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJARVIS: A Multi-Agent Code Assistant for High-Quality EDA Script Generation
May 20, 2025



This paper presents JARVIS, a novel multi-agent framework that leverages Large Language Models (LLMs) and domain expertise to generate high-quality scripts for specialized Electronic Design Automation (EDA) tasks. By combining a domain-specific LLM trained with synthetically generated data, a custom compiler for structural verification, rule enforcement, code fixing capabilities, and advanced retrieval mechanisms, our approach achieves significant improvements over state-of-the-art domain-specific models. Our framework addresses the challenges of data scarcity and hallucination errors in LLMs, demonstrating the potential of LLMs in specialized engineering domains. We evaluate our framework on multiple benchmarks and show that it outperforms existing models in terms of accuracy and reliability. Our work sets a new precedent for the application of LLMs in EDA and paves the way for future innovations in this field.
ChipNeMo: Domain-Adapted LLMs for Chip Design
Nov 13, 2023



ChipNeMo aims to explore the applications of large language models (LLMs) for industrial chip design. Instead of directly deploying off-the-shelf commercial or open-source LLMs, we instead adopt the following domain adaptation techniques: custom tokenizers, domain-adaptive continued pretraining, supervised fine-tuning (SFT) with domain-specific instructions, and domain-adapted retrieval models. We evaluate these methods on three selected LLM applications for chip design: an engineering assistant chatbot, EDA script generation, and bug summarization and analysis. Our results show that these domain adaptation techniques enable significant LLM performance improvements over general-purpose base models across the three evaluated applications, enabling up to 5x model size reduction with similar or better performance on a range of design tasks. Our findings also indicate that there's still room for improvement between our current results and ideal outcomes. We believe that further investigation of domain-adapted LLM approaches will help close this gap in the future.
Unsupervised Typography Transfer
Feb 07, 2018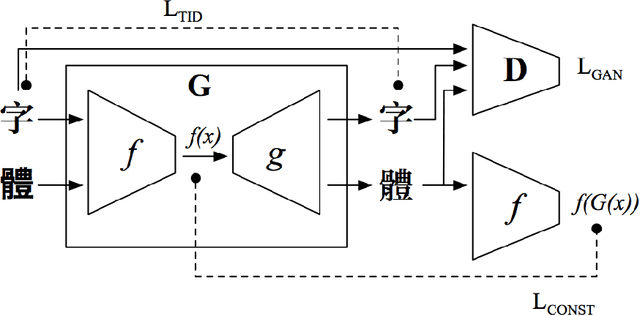

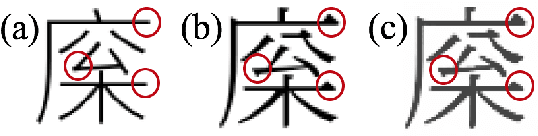

Traditional methods in Chinese typography synthesis view characters as an assembly of radicals and strokes, but they rely on manual definition of the key points, which is still time-costing. Some recent work on computer vision proposes a brand new approach: to treat every Chinese character as an independent and inseparable image, so the pre-processing and post-processing of each character can be avoided. Then with a combination of a transfer network and a discriminating network, one typography can be well transferred to another. Despite the quite satisfying performance of the model, the training process requires to be supervised, which means in the training data each character in the source domain and the target domain needs to be perfectly paired. Sometimes the pairing is time-costing, and sometimes there is no perfect pairing, such as the pairing between traditional Chinese and simplified Chinese characters. In this paper, we proposed an unsupervised typography transfer method which doesn't need pairing.
RubyStar: A Non-Task-Oriented Mixture Model Dialog System
Dec 16, 2017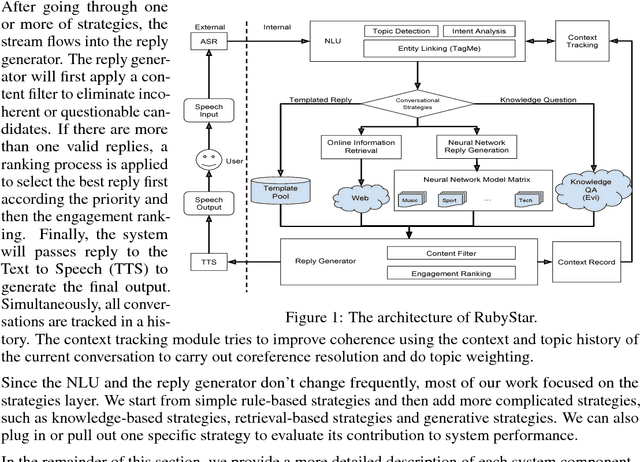


RubyStar is a dialog system designed to create "human-like" conversation by combining different response generation strategies. RubyStar conducts a non-task-oriented conversation on general topics by using an ensemble of rule-based, retrieval-based and generative methods. Topic detection, engagement monitoring, and context tracking are used for managing interaction. Predictable elements of conversation, such as the bot's backstory and simple question answering are handled by separate modules. We describe a rating scheme we developed for evaluating response generation. We find that character-level RNN is an effective generation model for general responses, with proper parameter settings; however other kinds of conversation topics might benefit from using other models.