 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations
Sep 13, 2018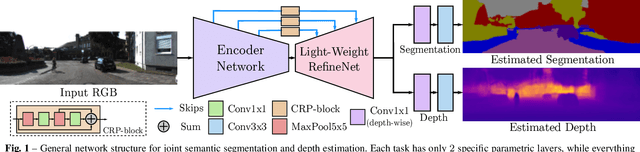

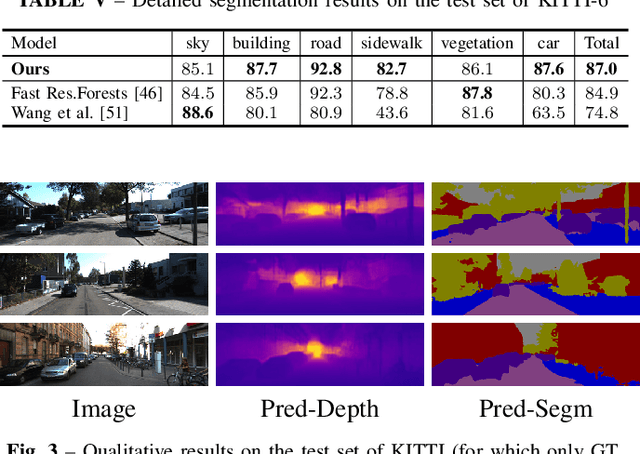

Deployment of deep learning models in robotics as sensory information extractors can be a daunting task to handle, even using generic GPU cards. Here, we address three of its most prominent hurdles, namely, i) the adaptation of a single model to perform multiple tasks at once (in this work, we consider depth estimation and semantic segmentation crucial for acquiring geometric and semantic understanding of the scene), while ii) doing it in real-time, and iii) using asymmetric datasets with uneven numbers of annotations per each modality. To overcome the first two issues, we adapt a recently proposed real-time semantic segmentation network, making few changes to further reduce the number of floating point operations. To approach the third issue, we embrace a simple solution based on hard knowledge distillation under the assumption of having access to a powerful `teacher' network. Finally, we showcase how our system can be easily extended to handle more tasks, and more datasets, all at once. Quantitatively, we achieve 42% mean iou, 0.56m RMSE (lin) and 0.20 RMSE (log) with a single model on NYUDv2-40, 87% mean iou, 3.45m RMSE (lin) and 0.18 RMSE (log) on KITTI-6 for segmentation and KITTI for depth estimation, with one forward pass costing just 17ms and 6.45 GFLOPs on 1200x350 inputs. All these results are either equivalent to (or better than) current state-of-the-art approaches, which were achieved with larger and slower models solving each task separately.
Towards Effective Deep Embedding for Zero-Shot Learning
Aug 30, 2018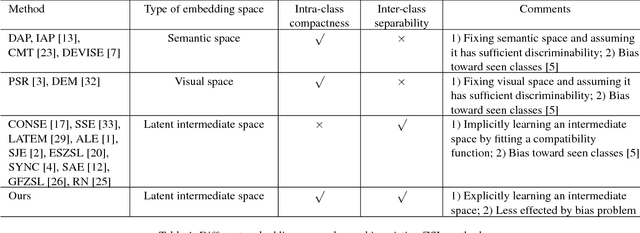
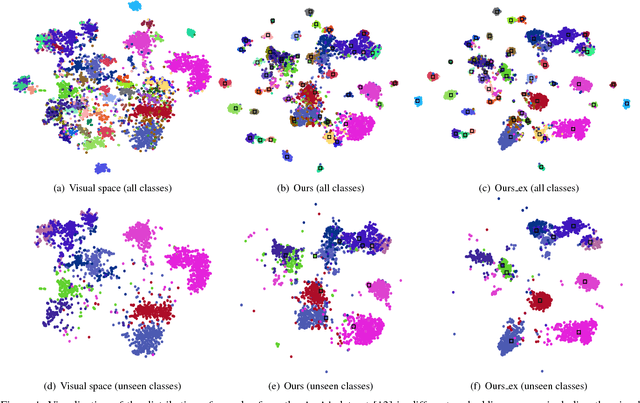

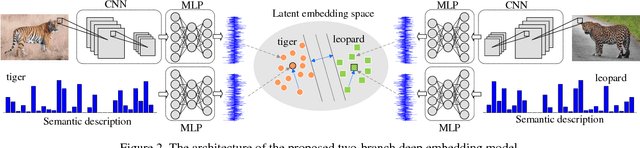
Zero-shot learning (ZSL) attempts to recognize visual samples of unseen classes by virtue of the semantic descriptions of those classes. We posit that the key to ZSL is to exploit an effective embedding space where 1) visual samples can be tightly centred around the semantic descriptions of classes that they belong to; 2) visual samples of different classes are separated from each other with a large enough margin. Towards this goal, we present a simple but surprisingly effective deep embedding model. In our model, we separately embed visual samples and semantic descriptions into a latent intermediate space such that visual samples not only coincide with associated semantic descriptions, but also can be correctly discriminated by a trainable linear classifier. By doing this, visual samples can be tightly centred around associated semantic descriptions and more importantly, they can be separated from other semantic descriptions with a large margin, thus leading to a new state-of-the-art for ZSL. Furthermore, due to lacking training samples, the generalization capacity of the learned embedding space to unseen classes can be further improved. To this end, we propose to upgrade our model with a refining strategy which progressively calibrates the embedding space based upon some test samples chosen from unseen classes with high-confidence pseudo labels, and ultimately improves the generalization capacity greatly. Experimental results on five benchmarks demonstrate the great advantage of our model over current state-of-the-art competitors. For example, on AwA1 dataset, our model improves the recognition accuracy on unseen classes by 16.9% in conventional ZSL setting and even by 38.6% in the generalized ZSL setting.
Troy: Give Attention to Saliency and for Saliency
Aug 14, 2018
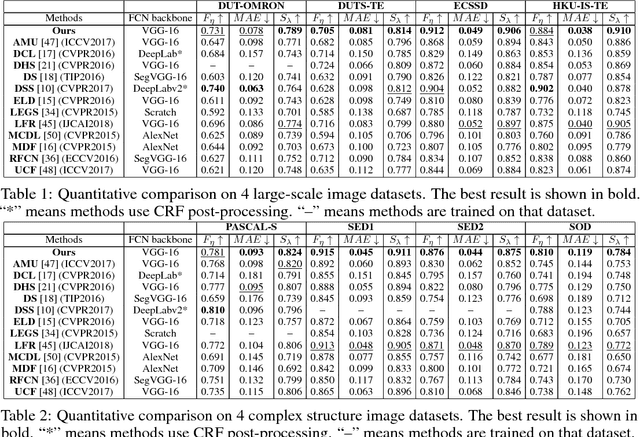
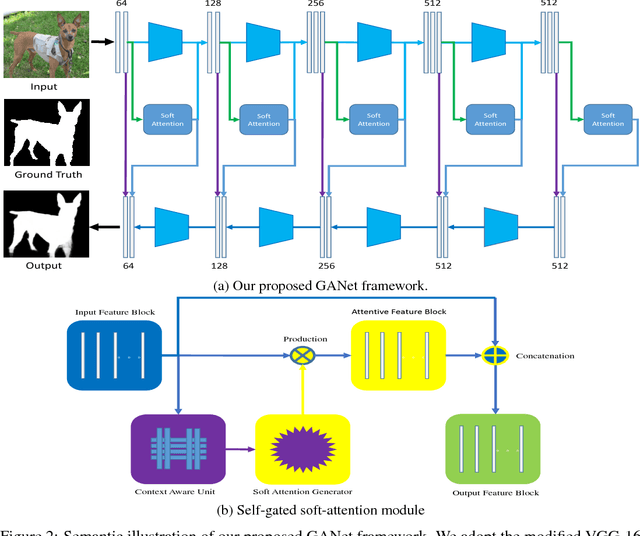

In addition, our work has text overlap with arXiv:1804.06242, arXiv:1705.00938 by other authors. We want to rewrite this paper for avoiding this fact.
Training Compact Neural Networks with Binary Weights and Low Precision Activations
Aug 08, 2018
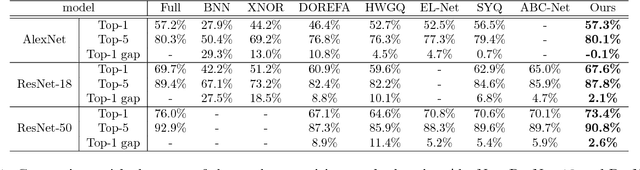
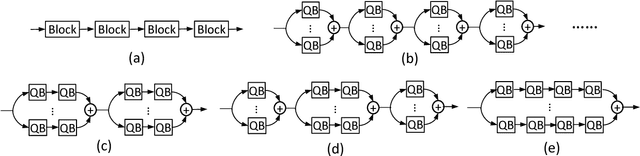
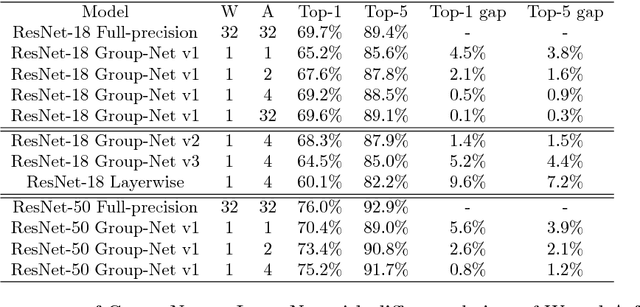
In this paper, we propose to train a network with binary weights and low-bitwidth activations, designed especially for mobile devices with limited power consumption. Most previous works on quantizing CNNs uncritically assume the same architecture, though with reduced precision. However, we take the view that for best performance it is possible (and even likely) that a different architecture may be better suited to dealing with low precision weights and activations. Specifically, we propose a "network expansion" strategy in which we aggregate a set of homogeneous low-precision branches to implicitly reconstruct the full-precision intermediate feature maps. Moreover, we also propose a group-wise feature approximation strategy which is very flexible and highly accurate. Experiments on ImageNet classification tasks demonstrate the superior performance of the proposed model, named Group-Net, over various popular architectures. In particular, with binary weights and activations, we outperform the previous best binary neural network in terms of accuracy as well as saving more than 5 times computational complexity on ImageNet with ResNet-18 and ResNet-50.
Learning to predict crisp boundaries
Jul 26, 2018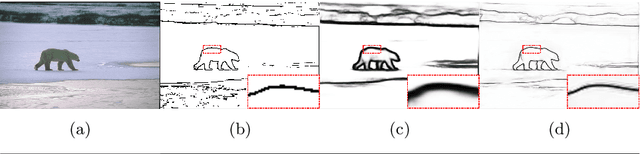



Recent methods for boundary or edge detection built on Deep Convolutional Neural Networks (CNNs) typically suffer from the issue of predicted edges being thick and need post-processing to obtain crisp boundaries. Highly imbalanced categories of boundary versus background in training data is one of main reasons for the above problem. In this work, the aim is to make CNNs produce sharp boundaries without post-processing. We introduce a novel loss for boundary detection, which is very effective for classifying imbalanced data and allows CNNs to produce crisp boundaries. Moreover, we propose an end-to-end network which adopts the bottom-up/top-down architecture to tackle the task. The proposed network effectively leverages hierarchical features and produces pixel-accurate boundary mask, which is critical to reconstruct the edge map. Our experiments illustrate that directly making crisp prediction not only promotes the visual results of CNNs, but also achieves better results against the state-of-the-art on the BSDS500 dataset (ODS F-score of .815) and the NYU Depth dataset (ODS F-score of .762).
Deep attention-based classification network for robust depth prediction
Jul 11, 2018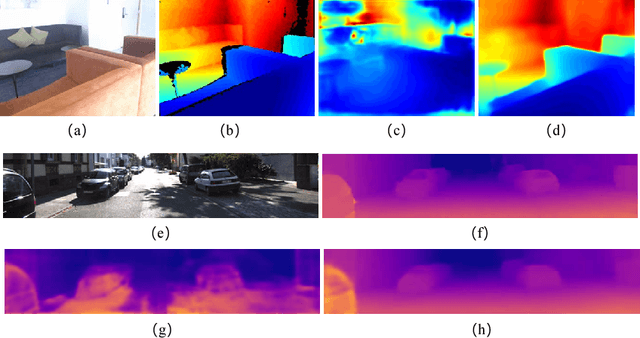
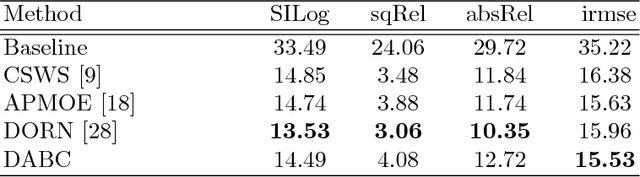
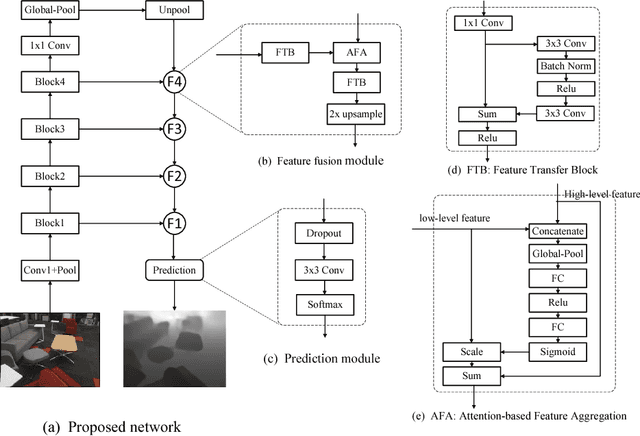
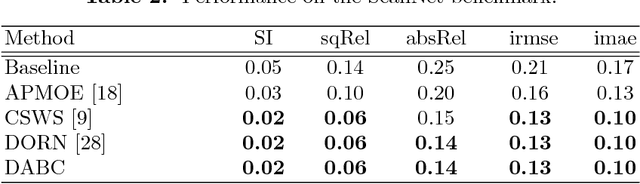
In this paper, we present our deep attention-based classification (DABC) network for robust single image depth prediction, in the context of the Robust Vision Challenge 2018 (ROB 2018). Unlike conventional depth prediction, our goal is to design a model that can perform well in both indoor and outdoor scenes with a single parameter set. However, robust depth prediction suffers from two challenging problems: a) How to extract more discriminative features for different scenes (compared to a single scene)? b) How to handle the large differences of depth ranges between indoor and outdoor datasets? To address these two problems, we first formulate depth prediction as a multi-class classification task and apply a softmax classifier to classify the depth label of each pixel. We then introduce a global pooling layer and a channel-wise attention mechanism to adaptively select the discriminative channels of features and to update the original features by assigning important channels with higher weights. Further, to reduce the influence of quantization errors, we employ a soft-weighted sum inference strategy for the final prediction. Experimental results on both indoor and outdoor datasets demonstrate the effectiveness of our method. It is worth mentioning that we won the 2-nd place in single image depth prediction entry of ROB 2018, in conjunction with IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018.
Adversarial Learning with Local Coordinate Coding
Jun 14, 2018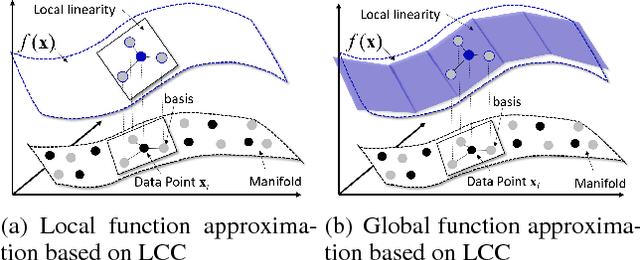
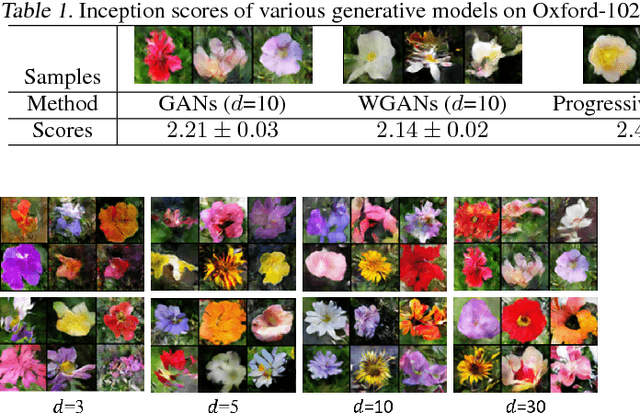
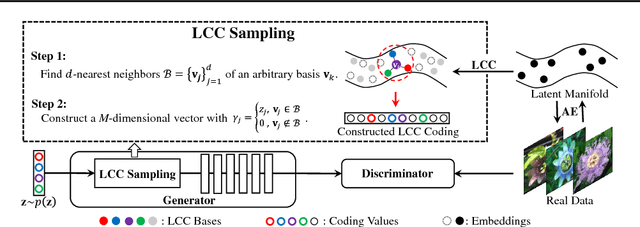
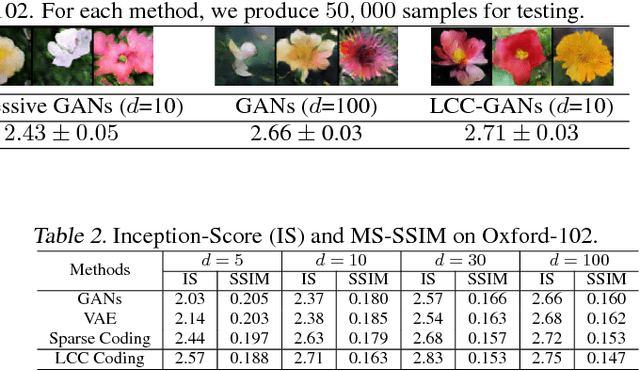
Generative adversarial networks (GANs) aim to generate realistic data from some prior distribution (e.g., Gaussian noises). However, such prior distribution is often independent of real data and thus may lose semantic information (e.g., geometric structure or content in images) of data. In practice, the semantic information might be represented by some latent distribution learned from data, which, however, is hard to be used for sampling in GANs. In this paper, rather than sampling from the pre-defined prior distribution, we propose a Local Coordinate Coding (LCC) based sampling method to improve GANs. We derive a generalization bound for LCC based GANs and prove that a small dimensional input is sufficient to achieve good generalization. Extensive experiments on various real-world datasets demonstrate the effectiveness of the proposed method.
Adaptive Importance Learning for Improving Lightweight Image Super-resolution Network
Jun 05, 2018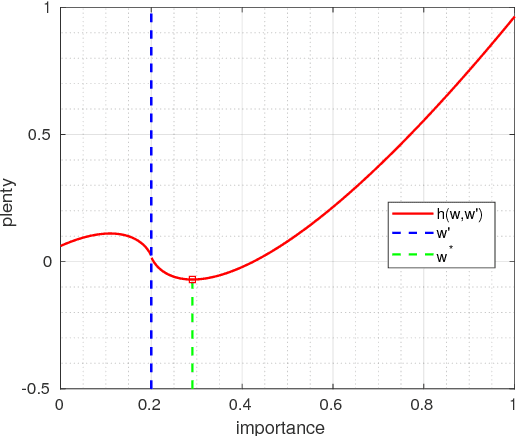
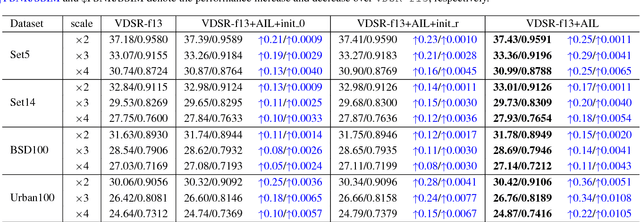
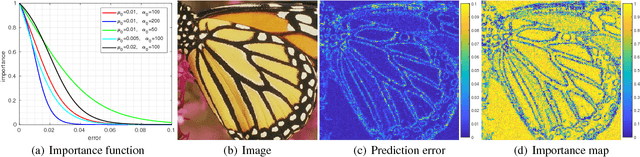
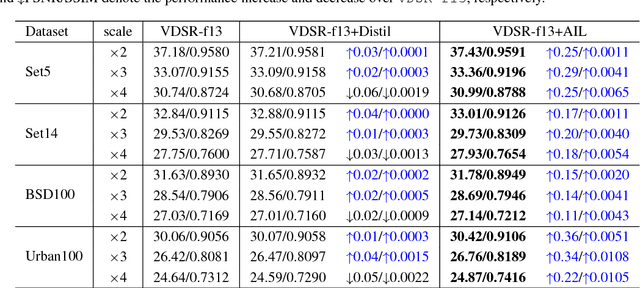
Deep neural networks have achieved remarkable success in single image super-resolution (SISR). The computing and memory requirements of these methods have hindered their application to broad classes of real devices with limited computing power, however. One approach to this problem has been lightweight network architectures that bal- ance the super-resolution performance and the computation burden. In this study, we revisit this problem from an orthog- onal view, and propose a novel learning strategy to maxi- mize the pixel-wise fitting capacity of a given lightweight network architecture. Considering that the initial capacity of the lightweight network is very limited, we present an adaptive importance learning scheme for SISR that trains the network with an easy-to-complex paradigm by dynam- ically updating the importance of image pixels on the basis of the training loss. Specifically, we formulate the network training and the importance learning into a joint optimization problem. With a carefully designed importance penalty function, the importance of individual pixels can be gradu- ally increased through solving a convex optimization problem. The training process thus begins with pixels that are easy to reconstruct, and gradually proceeds to more complex pixels as fitting improves.
Monocular Depth Estimation with Augmented Ordinal Depth Relationships
Jun 02, 2018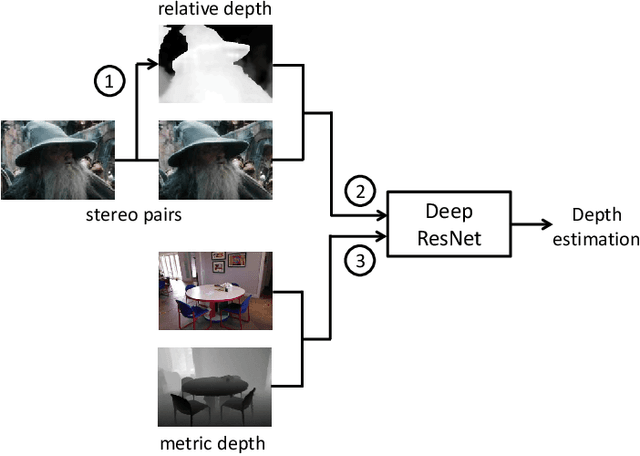

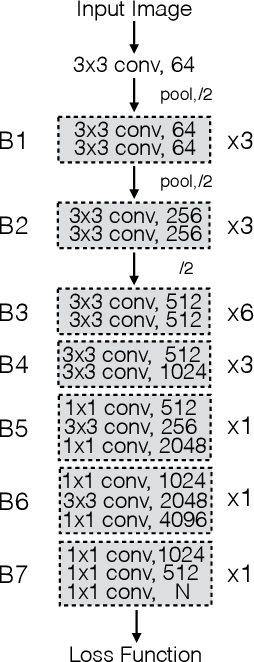
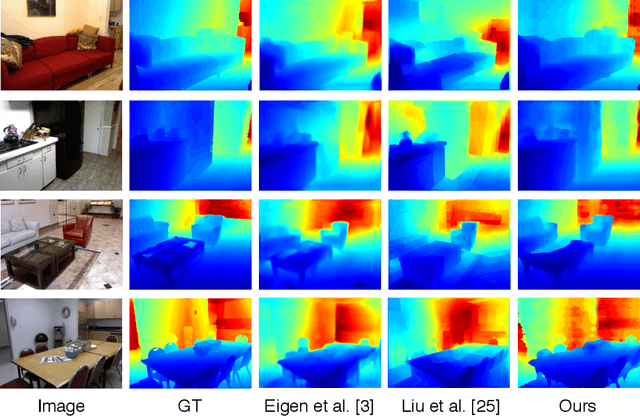
Most existing algorithms for depth estimation from single monocular images need large quantities of metric groundtruth depths for supervised learning. We show that relative depth can be an informative cue for metric depth estimation and can be easily obtained from vast stereo videos. Acquiring metric depths from stereo videos is sometimes impracticable due to the absence of camera parameters. In this paper, we propose to improve the performance of metric depth estimation with relative depths collected from stereo movie videos using existing stereo matching algorithm. We introduce a new "Relative Depth in Stereo" (RDIS) dataset densely labelled with relative depths. We first pretrain a ResNet model on our RDIS dataset. Then we finetune the model on RGB-D datasets with metric ground-truth depths. During our finetuning, we formulate depth estimation as a classification task. This re-formulation scheme enables us to obtain the confidence of a depth prediction in the form of probability distribution. With this confidence, we propose an information gain loss to make use of the predictions that are close to ground-truth. We evaluate our approach on both indoor and outdoor benchmark RGB-D datasets and achieve state-of-the-art performance.
Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples
May 11, 2018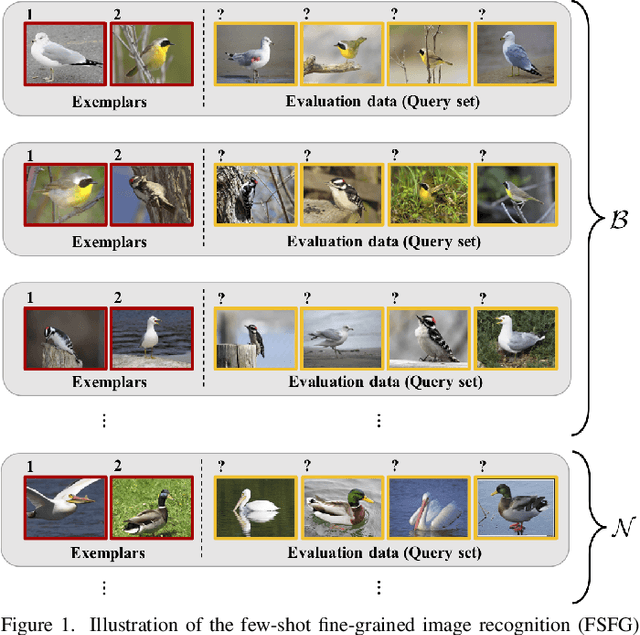
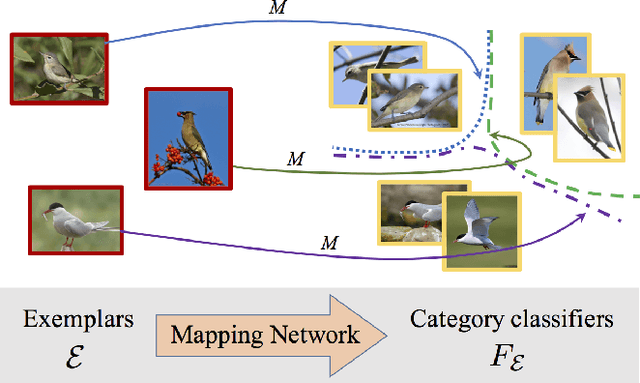
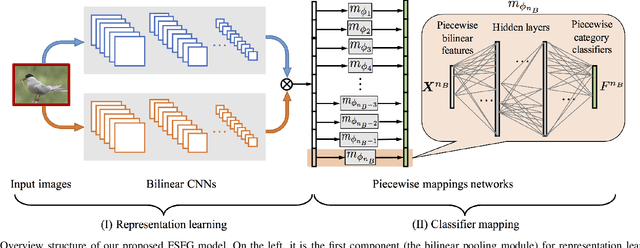

Humans are capable of learning a new fine-grained concept with very little supervision, e.g., few exemplary images for a species of bird, yet our best deep learning systems need hundreds or thousands of labeled examples. In this paper, we try to reduce this gap by studying the fine-grained image recognition problem in a challenging few-shot learning setting, termed few-shot fine-grained recognition (FSFG). The task of FSFG requires the learning systems to build classifiers for novel fine-grained categories from few examples (only one or less than five). To solve this problem, we propose an end-to-end trainable deep network which is inspired by the state-of-the-art fine-grained recognition model and is tailored for the FSFG task. Specifically, our network consists of a bilinear feature learning module and a classifier mapping module: while the former encodes the discriminative information of an exemplar image into a feature vector, the latter maps the intermediate feature into the decision boundary of the novel category. The key novelty of our model is a "piecewise mappings" function in the classifier mapping module, which generates the decision boundary via learning a set of more attainable sub-classifiers in a more parameter-economic way. We learn the exemplar-to-classifier mapping based on an auxiliary dataset in a meta-learning fashion, which is expected to be able to generalize to novel categories. By conducting comprehensive experiments on three fine-grained datasets, we demonstrate that the proposed method achieves superior performance over the competing baselines.