 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepEMD: Few-Shot Image Classification with Differentiable Earth Mover's Distance and Structured Classifiers
Mar 25, 2020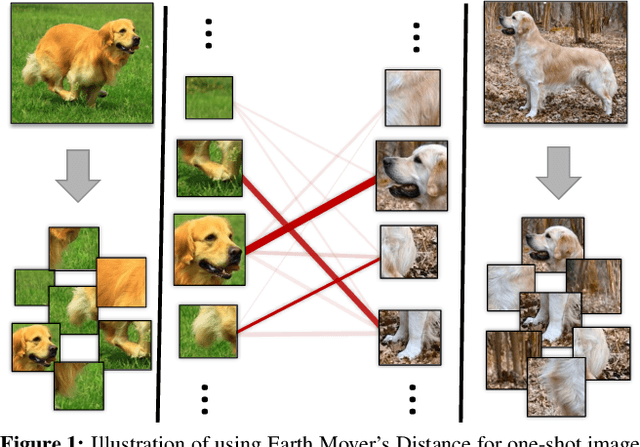
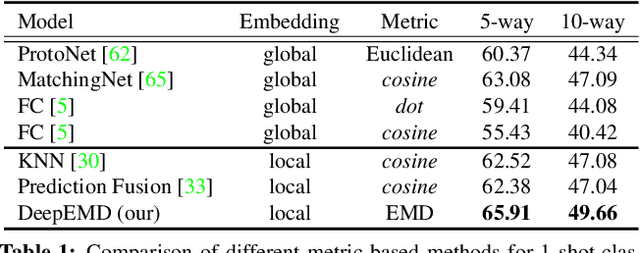
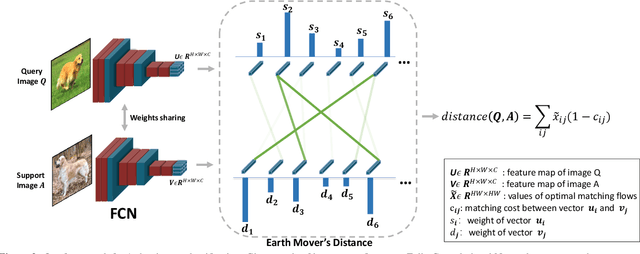
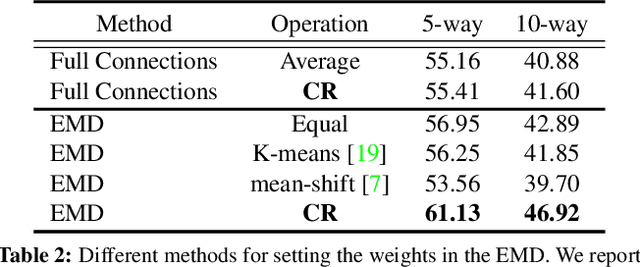
In this paper, we address the few-shot classification task from a new perspective of optimal matching between image regions. We adopt the Earth Mover's Distance (EMD) as a metric to compute a structural distance between dense image representations to determine image relevance. The EMD generates the optimal matching flows between structural elements that have the minimum matching cost, which is used to represent the image distance for classification. To generate the important weights of elements in the EMD formulation, we design a cross-reference mechanism, which can effectively minimize the impact caused by the cluttered background and large intra-class appearance variations. To handle k-shot classification, we propose to learn a structured fully connected layer that can directly classify dense image representations with the EMD. Based on the implicit function theorem, the EMD can be inserted as a layer into the network for end-to-end training. We conduct comprehensive experiments to validate our algorithm and we set new state-of-the-art performance on four popular few-shot classification benchmarks, namely miniImageNet, tieredImageNet, Fewshot-CIFAR100 (FC100) and Caltech-UCSD Birds-200-2011 (CUB).
SOLOv2: Dynamic, Faster and Stronger
Mar 23, 2020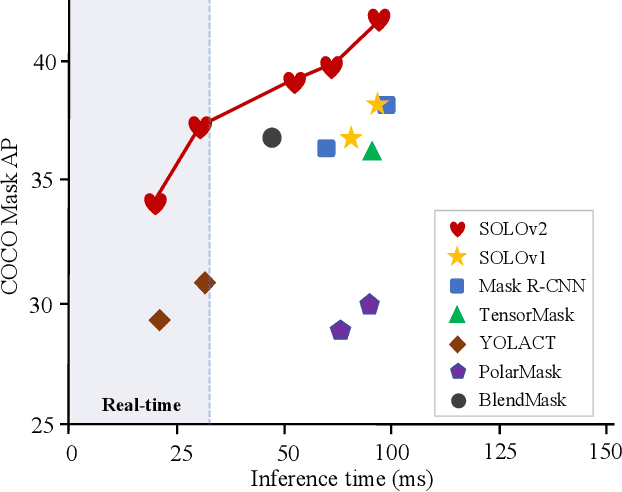
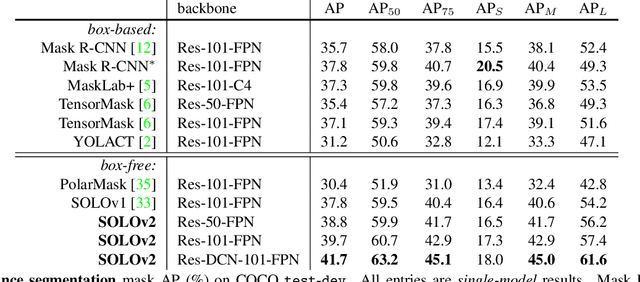
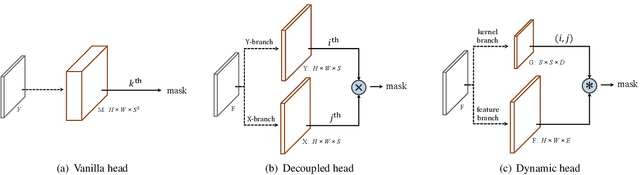
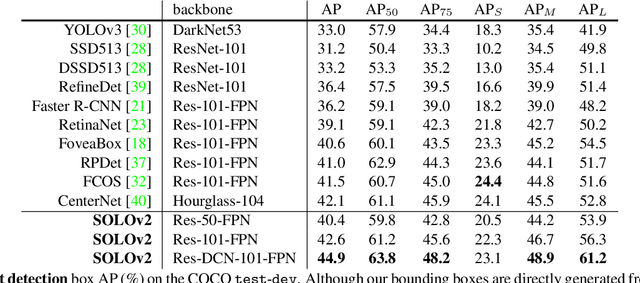
In this work, we aim at building a simple, direct, and fast instance segmentation framework with strong performance. We follow the principle of the SOLO method of Wang et al. "SOLO: segmenting objects by locations". Importantly, we take one step further by dynamically learning the mask head of the object segmenter such that the mask head is conditioned on the location. Specifically, the mask branch is decoupled into a mask kernel branch and mask feature branch, which are responsible for learning the convolution kernel and the convolved features respectively. Moreover, we propose Matrix NMS (non maximum suppression) to significantly reduce the inference time overhead due to NMS of masks. Our Matrix NMS performs NMS with parallel matrix operations in one shot, and yields better results. We demonstrate a simple direct instance segmentation system, outperforming a few state-of-the-art methods in both speed and accuracy. A light-weight version of SOLOv2 executes at 31.3 FPS and yields 37.1% AP. Moreover, our state-of-the-art results in object detection (from our mask byproduct) and panoptic segmentation show the potential to serve as a new strong baseline for many instance-level recognition tasks besides instance segmentation. Code is available at: https://git.io/AdelaiDet
Conditional Convolutions for Instance Segmentation
Mar 19, 2020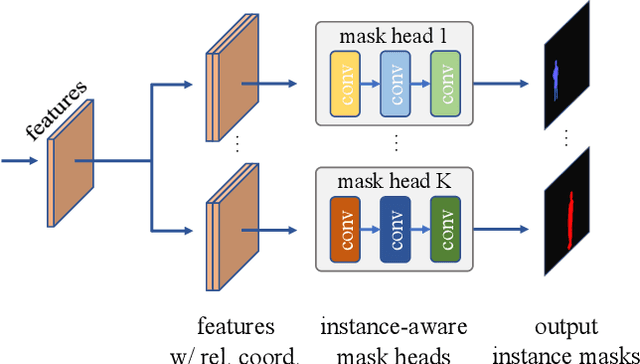


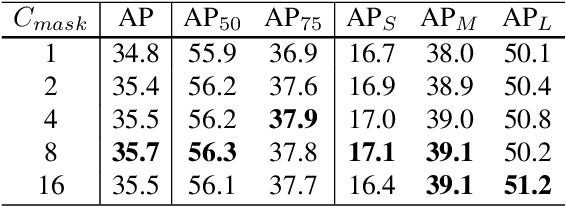
We propose a simple yet effective instance segmentation framework, termed CondInst (conditional convolutions for instance segmentation). Top-performing instance segmentation methods such as Mask R-CNN rely on ROI operations (typically ROIPool or ROIAlign) to obtain the final instance masks. In contrast, we propose to solve instance segmentation from a new perspective. Instead of using instance-wise ROIs as inputs to a network of fixed weights, we employ dynamic instance-aware networks, conditioned on instances. CondInst enjoys two advantages: 1) Instance segmentation is solved by a fully convolutional network, eliminating the need for ROI cropping and feature alignment. 2) Due to the much improved capacity of dynamically-generated conditional convolutions, the mask head can be very compact (e.g., 3 conv. layers, each having only 8 channels), leading to significantly faster inference. We demonstrate a simpler instance segmentation method that can achieve improved performance in both accuracy and inference speed. On the COCO dataset, we outperform a few recent methods including well-tuned Mask RCNN baselines, without longer training schedules needed. Code is available: https://github.com/aim-uofa/adet
Self-trained Deep Ordinal Regression for End-to-End Video Anomaly Detection
Mar 15, 2020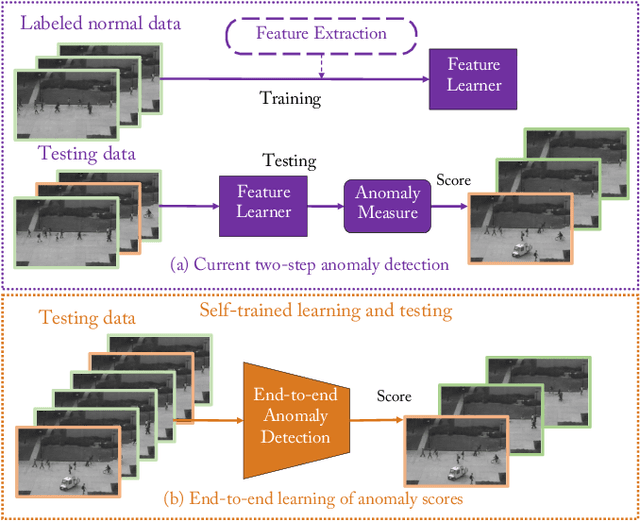
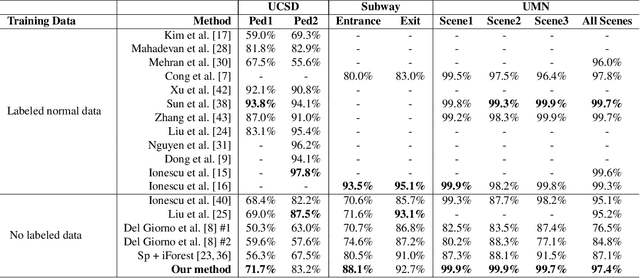
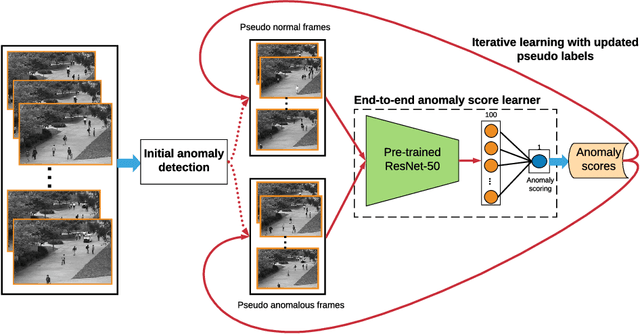
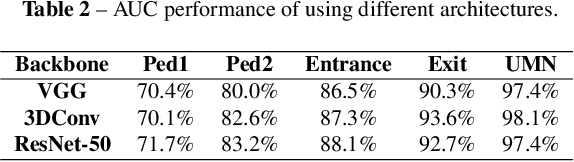
Video anomaly detection is of critical practical importance to a variety of real applications because it allows human attention to be focused on events that are likely to be of interest, in spite of an otherwise overwhelming volume of video. We show that applying self-trained deep ordinal regression to video anomaly detection overcomes two key limitations of existing methods, namely, 1) being highly dependent on manually labeled normal training data; and 2) sub-optimal feature learning. By formulating a surrogate two-class ordinal regression task we devise an end-to-end trainable video anomaly detection approach that enables joint representation learning and anomaly scoring without manually labeled normal/abnormal data. Experiments on eight real-world video scenes show that our proposed method outperforms state-of-the-art methods that require no labeled training data by a substantial margin, and enables easy and accurate localization of the identified anomalies. Furthermore, we demonstrate that our method offers effective human-in-the-loop anomaly detection which can be critical in applications where anomalies are rare and the false-negative cost is high.
Efficient Semantic Video Segmentation with Per-frame Inference
Feb 26, 2020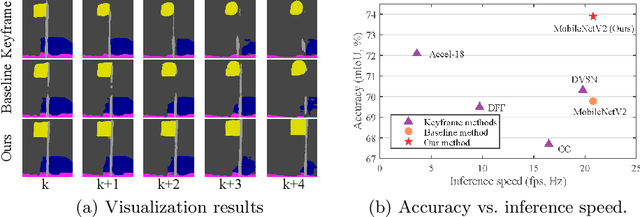
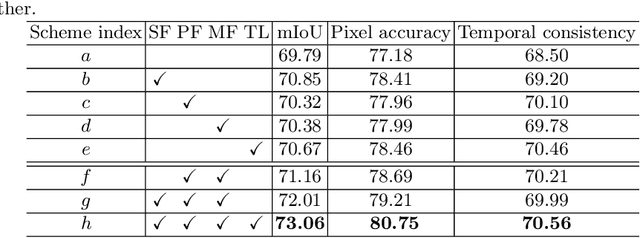
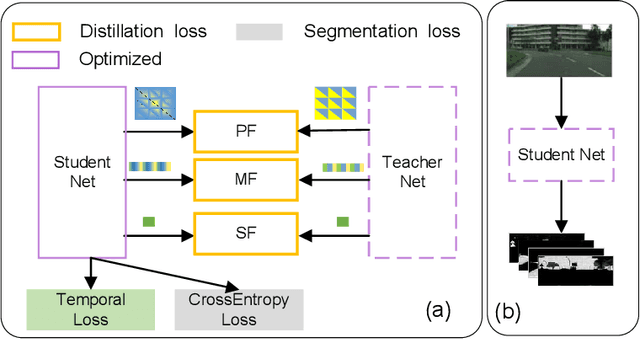
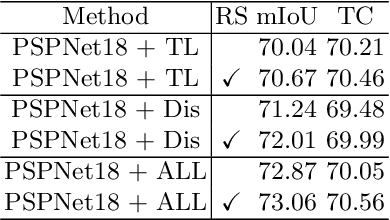
In semantic segmentation, most existing real-time deep models trained with each frame independently may produce inconsistent results for a video sequence. Advanced methods take into considerations the correlations in the video sequence, e.g., by propagating the results to the neighboring frames using optical flow, or extracting the frame representations with other frames, which may lead to inaccurate results or unbalanced latency. In this work, we process efficient semantic video segmentation in a per-frame fashion during the inference process. Different from previous per-frame models, we explicitly consider the temporal consistency among frames as extra constraints during the training process and embed the temporal consistency into the segmentation network. Therefore, in the inference process, we can process each frame independently with no latency, and improve the temporal consistency with no extra computational cost and post-processing. We employ compact models for real-time execution. To narrow the performance gap between compact models and large models, new knowledge distillation methods are designed. Our results outperform previous keyframe based methods with a better trade-off between the accuracy and the inference speed on popular benchmarks, including the Cityscapes and Camvid. The temporal consistency is also improved compared with corresponding baselines which are trained with each frame independently. Code is available at: https://tinyurl.com/segment-video
On the General Value of Evidence, and Bilingual Scene-Text Visual Question Answering
Feb 26, 2020
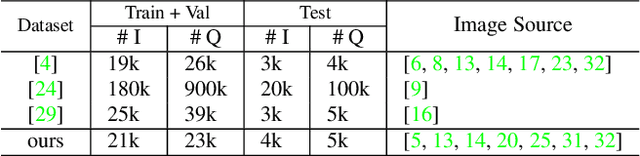

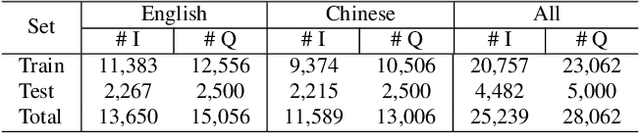
Visual Question Answering (VQA) methods have made incredible progress, but suffer from a failure to generalize. This is visible in the fact that they are vulnerable to learning coincidental correlations in the data rather than deeper relations between image content and ideas expressed in language. We present a dataset that takes a step towards addressing this problem in that it contains questions expressed in two languages, and an evaluation process that co-opts a well understood image-based metric to reflect the method's ability to reason. Measuring reasoning directly encourages generalization by penalizing answers that are coincidentally correct. The dataset reflects the scene-text version of the VQA problem, and the reasoning evaluation can be seen as a text-based version of a referring expression challenge. Experiments and analysis are provided that show the value of the dataset.
ABCNet: Real-time Scene Text Spotting with Adaptive Bezier-Curve Network
Feb 25, 2020
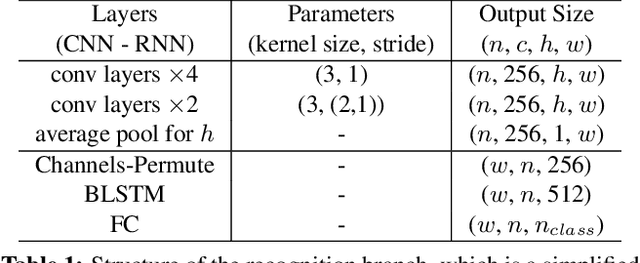
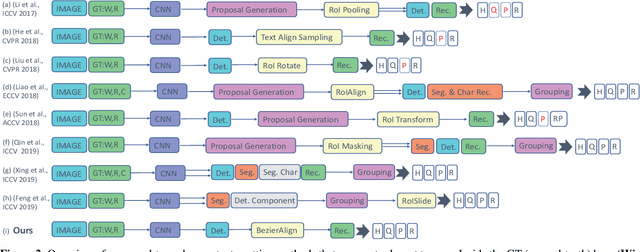
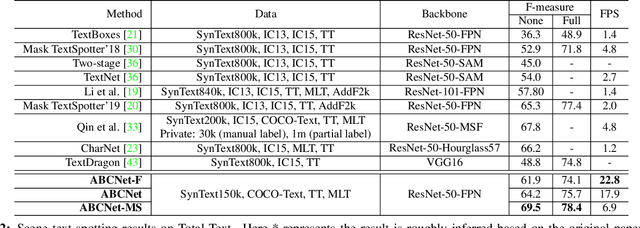
Scene text detection and recognition has received increasing research attention. Existing methods can be roughly categorized into two groups: character-based and segmentation-based. These methods either are costly for character annotation or need to maintain a complex pipeline, which is often not suitable for real-time applications. Here we address the problem by proposing the Adaptive Bezier-Curve Network (ABCNet). Our contributions are three-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance with arbitrary shapes, significantly improving the precision compared with previous methods. 3) Compared with standard bounding box detection, our Bezier curve detection introduces negligible computation overhead, resulting in superiority of our method in both efficiency and accuracy. Experiments on arbitrarily-shaped benchmark datasets, namely Total-Text and CTW1500, demonstrate that ABCNet achieves state-of-the-art accuracy, meanwhile significantly improving the speed. In particular, on Total-Text, our realtime version is over 10 times faster than recent state-of-the-art methods with a competitive recognition accuracy. Code is available at https://tinyurl.com/AdelaiDet
DiverseDepth: Affine-invariant Depth Prediction Using Diverse Data
Feb 14, 2020
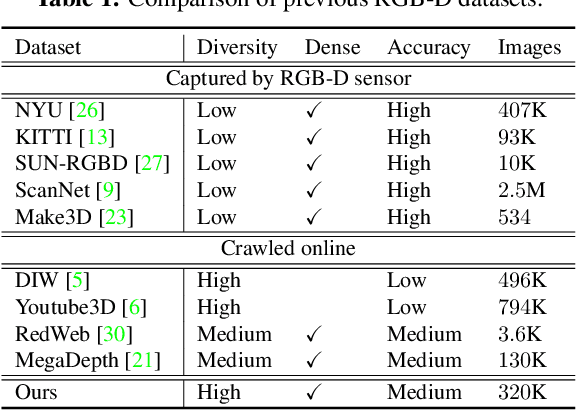


We present a method for depth estimation with monocular images, which can predict high-quality depth on diverse scenes up to an affine transformation, thus preserving accurate shapes of a scene. Previous methods that predict metric depth often work well only for a specific scene. In contrast, learning relative depth (information of being closer or further) can enjoy better generalization, with the price of failing to recover the accurate geometric shape of the scene. In this work, we propose a dataset and methods to tackle this dilemma, aiming to predict accurate depth up to an affine transformation with good generalization to diverse scenes. First we construct a large-scale and diverse dataset, termed Diverse Scene Depth dataset (DiverseDepth), which has a broad range of scenes and foreground contents. Compared with previous learning objectives, i.e., learning metric depth or relative depth, we propose to learn the affine-invariant depth using our diverse dataset to ensure both generalization and high-quality geometric shapes of scenes. Furthermore, in order to train the model on the complex dataset effectively, we propose a multi-curriculum learning method. Experiments show that our method outperforms previous methods on 8 datasets by a large margin with the zero-shot test setting, demonstrating the excellent generalization capacity of the learned model to diverse scenes. The reconstructed point clouds with the predicted depth show that our method can recover high-quality 3D shapes.
Joint Deep Learning of Facial Expression Synthesis and Recognition
Feb 06, 2020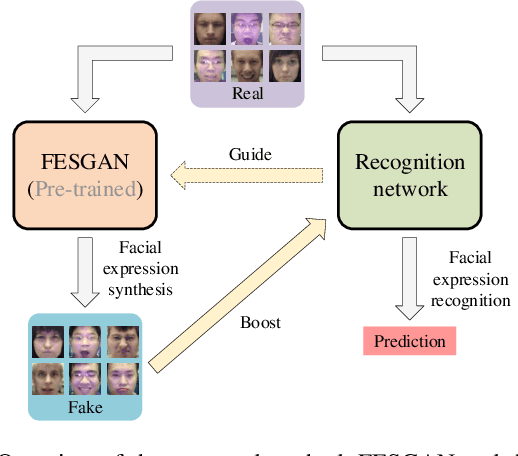
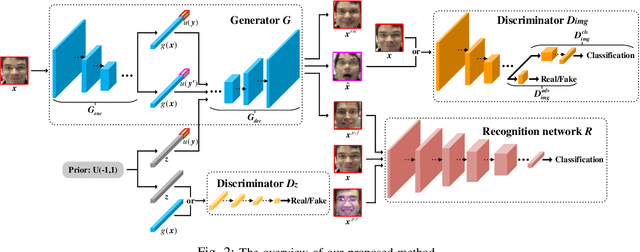
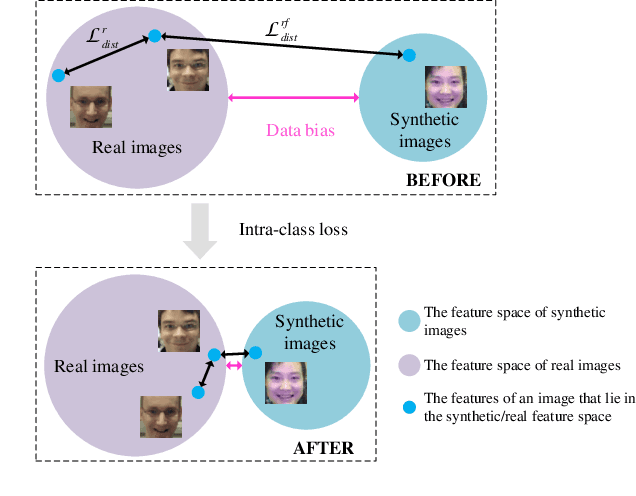

Recently, deep learning based facial expression recognition (FER) methods have attracted considerable attention and they usually require large-scale labelled training data. Nonetheless, the publicly available facial expression databases typically contain a small amount of labelled data. In this paper, to overcome the above issue, we propose a novel joint deep learning of facial expression synthesis and recognition method for effective FER. More specifically, the proposed method involves a two-stage learning procedure. Firstly, a facial expression synthesis generative adversarial network (FESGAN) is pre-trained to generate facial images with different facial expressions. To increase the diversity of the training images, FESGAN is elaborately designed to generate images with new identities from a prior distribution. Secondly, an expression recognition network is jointly learned with the pre-trained FESGAN in a unified framework. In particular, the classification loss computed from the recognition network is used to simultaneously optimize the performance of both the recognition network and the generator of FESGAN. Moreover, in order to alleviate the problem of data bias between the real images and the synthetic images, we propose an intra-class loss with a novel real data-guided back-propagation (RDBP) algorithm to reduce the intra-class variations of images from the same class, which can significantly improve the final performance. Extensive experimental results on public facial expression databases demonstrate the superiority of the proposed method compared with several state-of-the-art FER methods.
Separating Content from Style Using Adversarial Learning for Recognizing Text in the Wild
Jan 13, 2020

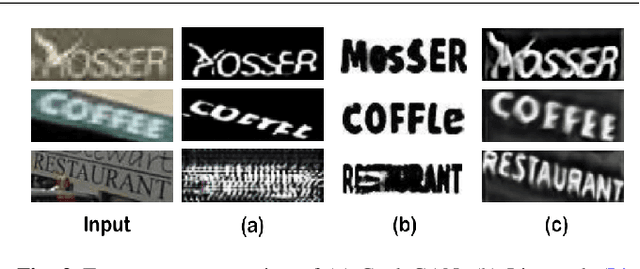

In this work we propose to improve text recognition from a new perspective by separating text content from complex backgrounds. We exploit the generative adversarial networks (GANs) for removing backgrounds while retaining the text content. As vanilla GANs are not sufficiently robust to generate sequence-like characters in natural images, we propose an adversarial learning framework for the generation and recognition of multiple characters in an image. The proposed framework consists of an attention-based recognizer and a generative adversarial architecture. Furthermore, to tackle the lack of paired training samples, we design an interactive joint training scheme, which shares attention masks from the recognizer to the discriminator, and enables the discriminator to extract the features of every character for further adversarial training. Benefiting from the character-level adversarial training, our framework requires only unpaired simple data for style supervision. Every target style sample containing only one randomly chosen character can be simply synthesized online during the training. This is significant as the training does not require costly paired samples or character-level annotations. Thus, only the input images and corresponding text labels are needed. In addition to the style transfer of the backgrounds, we refine character patterns to ease the recognition task. A feedback mechanism is proposed to bridge the gap between the discriminator and the recognizer. Therefore, the discriminator can guide the generator according to the confusion of the recognizer. The generated patterns are thus clearer for recognition. Experiments on various benchmarks, including both regular and irregular text, demonstrate that our method significantly reduces the difficulty of recognition. Our framework can be integrated with recent recognition methods to achieve new state-of-the-art performance.