 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal ASR: Unify and Improve Streaming ASR with Full-context Modeling
Oct 12, 2020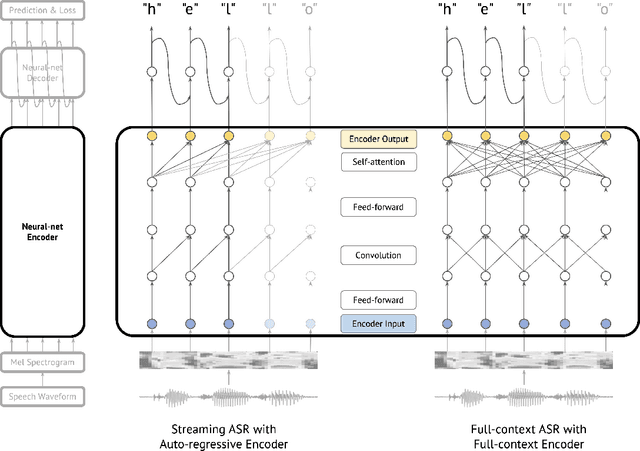
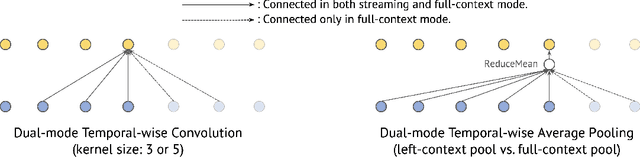
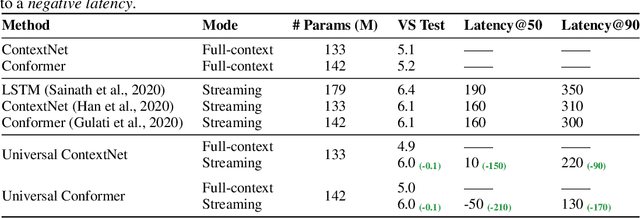
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible, while full-context ASR waits for the completion of a full speech utterance before emitting completed hypotheses. In this work, we propose a unified framework, Universal ASR, to train a single end-to-end ASR model with shared weights for both streaming and full-context speech recognition. We show that the latency and accuracy of streaming ASR significantly benefit from weight sharing and joint training of full-context ASR, especially with inplace knowledge distillation. The Universal ASR framework can be applied to recent state-of-the-art convolution-based and transformer-based ASR networks. We present extensive experiments with two state-of-the-art ASR networks, ContextNet and Conformer, on two datasets, a widely used public dataset LibriSpeech and an internal large-scale dataset MultiDomain. Experiments and ablation studies demonstrate that Universal ASR not only simplifies the workflow of training and deploying streaming and full-context ASR models, but also significantly improves both emission latency and recognition accuracy of streaming ASR. With Universal ASR, we achieve new state-of-the-art streaming ASR results on both LibriSpeech and MultiDomain in terms of accuracy and latency.
Parallel Rescoring with Transformer for Streaming On-Device Speech Recognition
Sep 02, 2020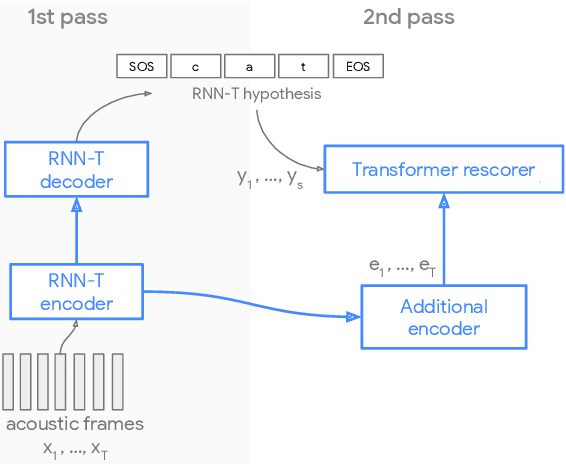
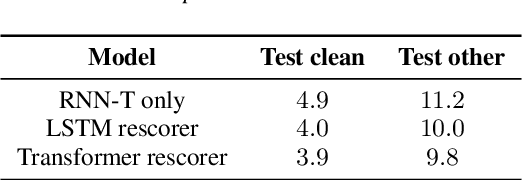
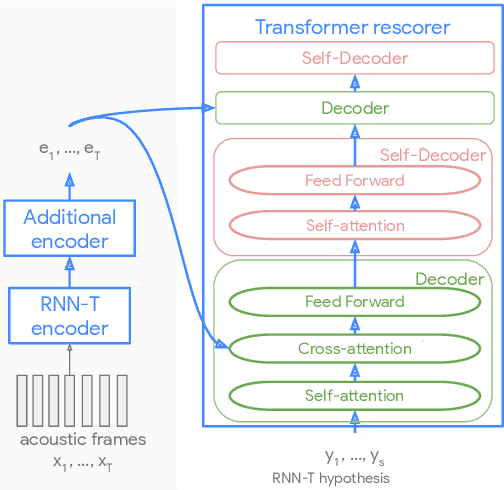
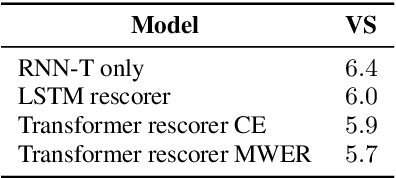
Recent advances of end-to-end models have outperformed conventional models through employing a two-pass model. The two-pass model provides better speed-quality trade-offs for on-device speech recognition, where a 1st-pass model generates hypotheses in a streaming fashion, and a 2nd-pass model re-scores the hypotheses with full audio sequence context. The 2nd-pass model plays a key role in the quality improvement of the end-to-end model to surpass the conventional model. One main challenge of the two-pass model is the computation latency introduced by the 2nd-pass model. Specifically, the original design of the two-pass model uses LSTMs for the 2nd-pass model, which are subject to long latency as they are constrained by the recurrent nature and have to run inference sequentially. In this work we explore replacing the LSTM layers in the 2nd-pass rescorer with Transformer layers, which can process the entire hypothesis sequences in parallel and can therefore utilize the on-device computation resources more efficiently. Compared with an LSTM-based baseline, our proposed Transformer rescorer achieves more than 50% latency reduction with quality improvement.
Improved Noisy Student Training for Automatic Speech Recognition
May 19, 2020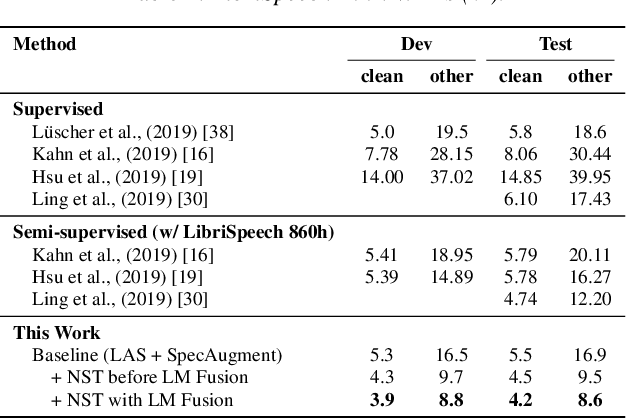
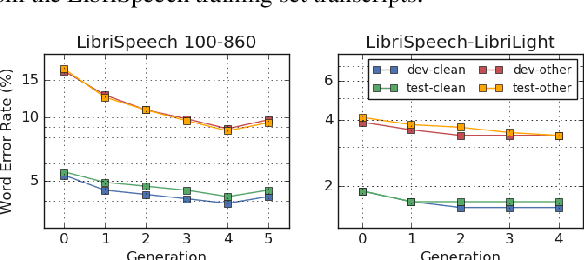
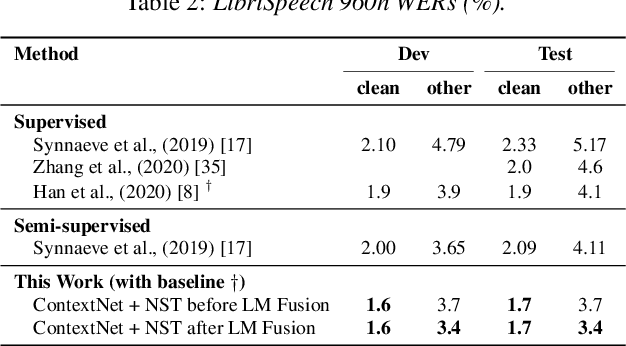
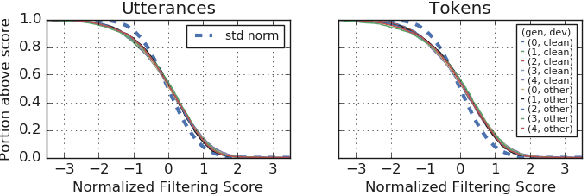
Recently, a semi-supervised learning method known as "noisy student training" has been shown to improve image classification performance of deep networks significantly. Noisy student training is an iterative self-training method that leverages augmentation to improve network performance. In this work, we adapt and improve noisy student training for automatic speech recognition, employing (adaptive) SpecAugment as the augmentation method. We find effective methods to filter, balance and augment the data generated in between self-training iterations. By doing so, we are able to obtain word error rates (WERs) 4.2%/8.6% on the clean/noisy LibriSpeech test sets by only using the clean 100h subset of LibriSpeech as the supervised set and the rest (860h) as the unlabeled set. Furthermore, we are able to achieve WERs 1.7%/3.4% on the clean/noisy LibriSpeech test sets by using the unlab-60k subset of LibriLight as the unlabeled set for LibriSpeech 960h. We are thus able to improve upon the previous state-of-the-art clean/noisy test WERs achieved on LibriSpeech 100h (4.74%/12.20%) and LibriSpeech (1.9%/4.1%).
RNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
May 17, 2020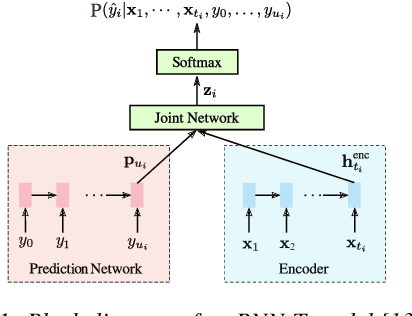
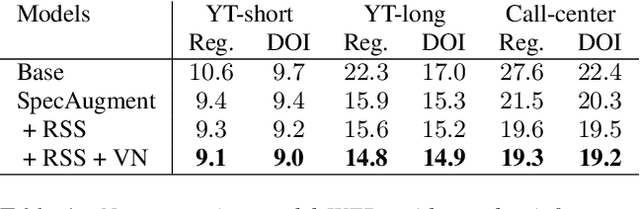
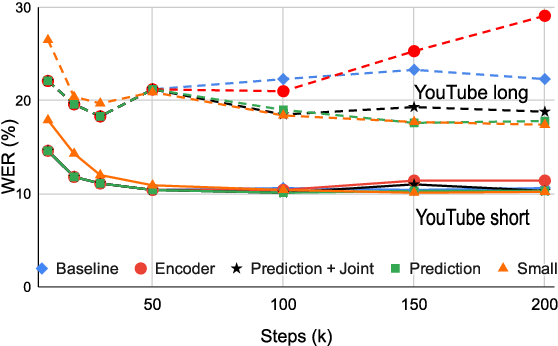
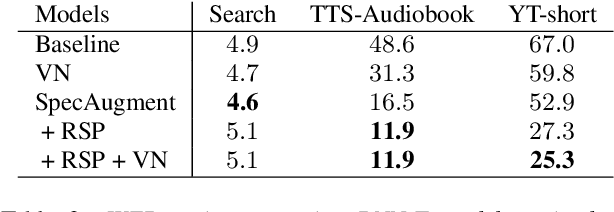
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.
Conformer: Convolution-augmented Transformer for Speech Recognition
May 16, 2020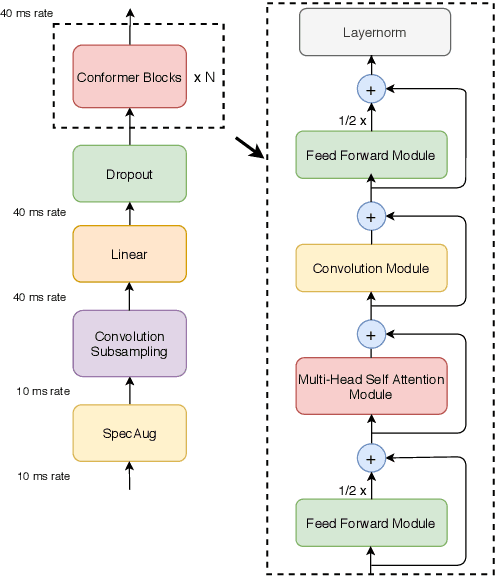
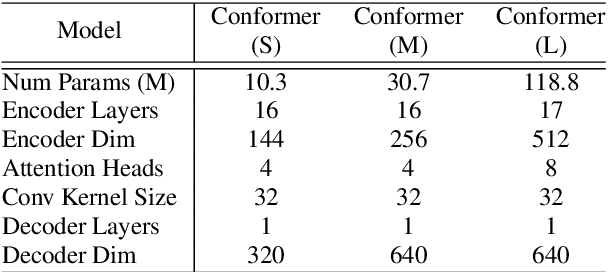

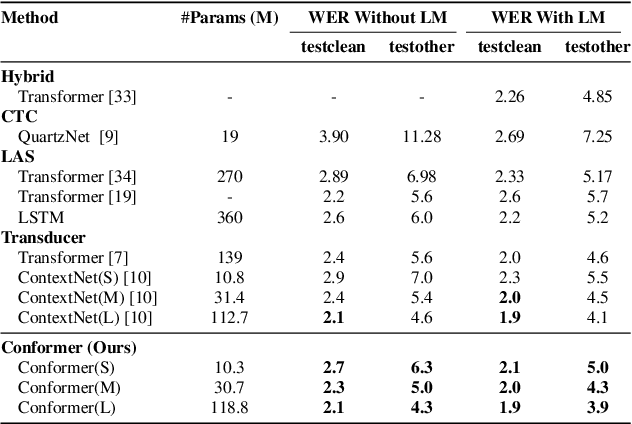
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
May 16, 2020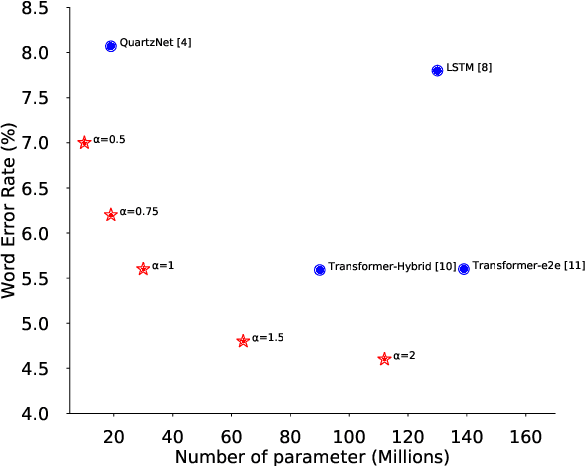
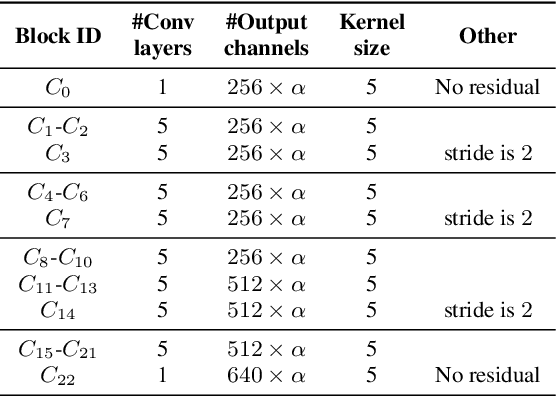
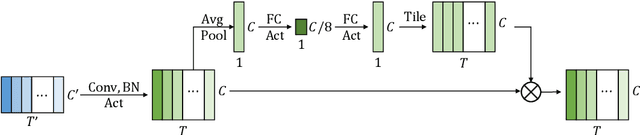
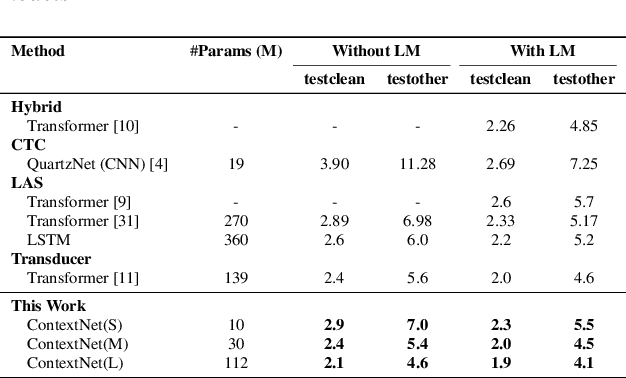
Convolutional neural networks (CNN) have shown promising results for end-to-end speech recognition, albeit still behind other state-of-the-art methods in performance. In this paper, we study how to bridge this gap and go beyond with a novel CNN-RNN-transducer architecture, which we call ContextNet. ContextNet features a fully convolutional encoder that incorporates global context information into convolution layers by adding squeeze-and-excitation modules. In addition, we propose a simple scaling method that scales the widths of ContextNet that achieves good trade-off between computation and accuracy. We demonstrate that on the widely used LibriSpeech benchmark, ContextNet achieves a word error rate (WER) of 2.1%/4.6% without external language model (LM), 1.9%/4.1% with LM and 2.9%/7.0% with only 10M parameters on the clean/noisy LibriSpeech test sets. This compares to the previous best published system of 2.0%/4.6% with LM and 3.9%/11.3% with 20M parameters. The superiority of the proposed ContextNet model is also verified on a much larger internal dataset.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020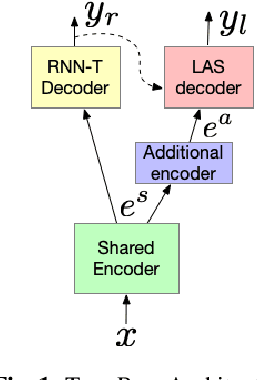
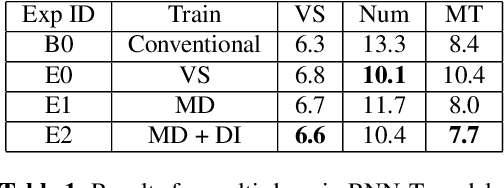
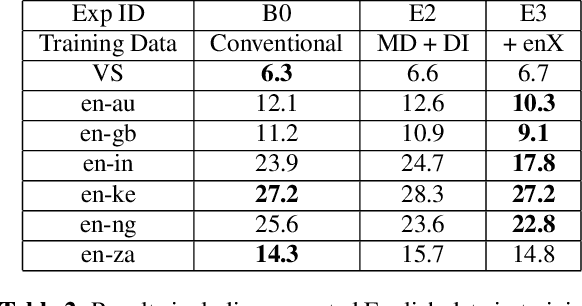
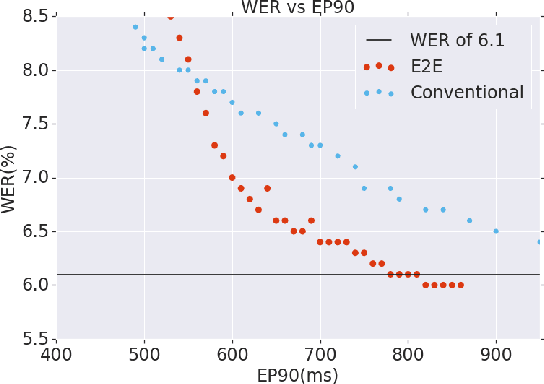
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
SpecAugment on Large Scale Datasets
Dec 11, 2019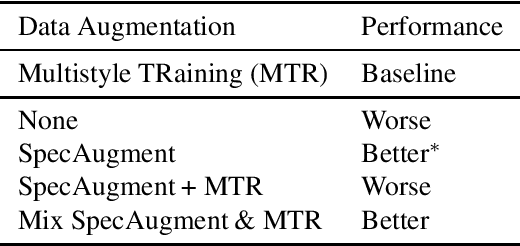
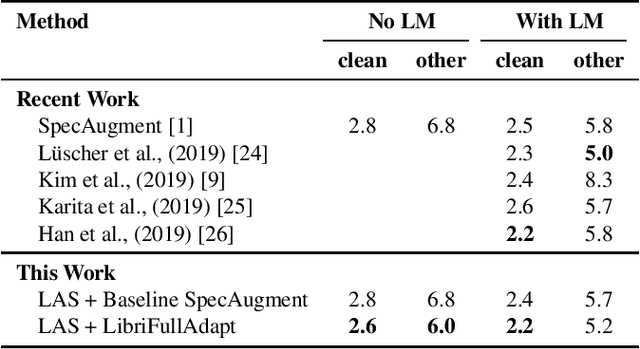
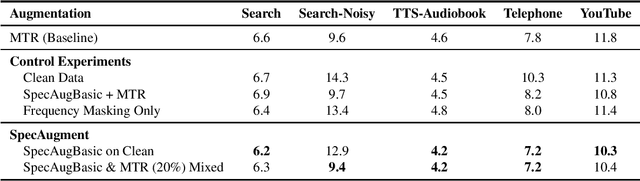
Recently, SpecAugment, an augmentation scheme for automatic speech recognition that acts directly on the spectrogram of input utterances, has shown to be highly effective in enhancing the performance of end-to-end networks on public datasets. In this paper, we demonstrate its effectiveness on tasks with large scale datasets by investigating its application to the Google Multidomain Dataset (Narayanan et al., 2018). We achieve improvement across all test domains by mixing raw training data augmented with SpecAugment and noise-perturbed training data when training the acoustic model. We also introduce a modification of SpecAugment that adapts the time mask size and/or multiplicity depending on the length of the utterance, which can potentially benefit large scale tasks. By using adaptive masking, we are able to further improve the performance of the Listen, Attend and Spell model on LibriSpeech to 2.2% WER on test-clean and 5.2% WER on test-other.
Speech Sentiment Analysis via Pre-trained Features from End-to-end ASR Models
Nov 21, 2019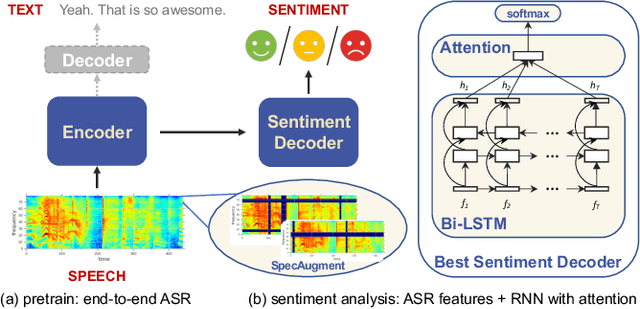

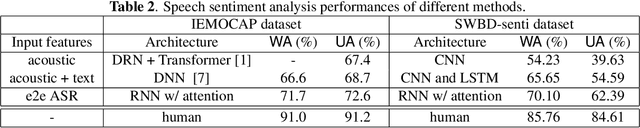

In this paper, we propose to use pre-trained features from end-to-end ASR models to solve the speech sentiment analysis problem as a down-stream task. We show that end-to-end ASR features, which integrate both acoustic and text information from speech, achieve promising results. We use RNN with self-attention as the sentiment classifier, which also provides an easy visualization through attention weights to help interpret model predictions. We use well benchmarked IEMOCAP dataset and a new large-scale sentiment analysis dataset SWBD-senti for evaluation. Our approach improves the-state-of-the-art accuracy on IEMOCAP from 66.6% to 71.7%, and achieves an accuracy of 70.10% on SWBD-senti with more than 49,500 utterances.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019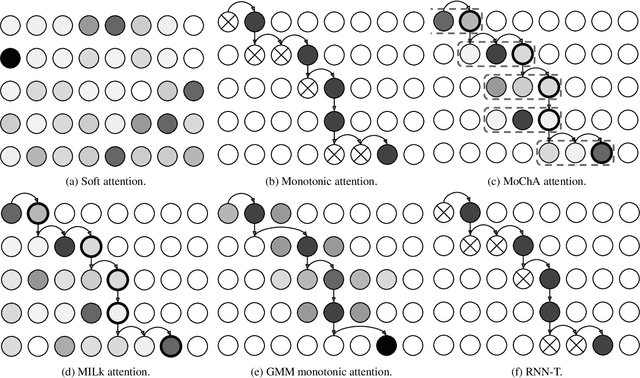

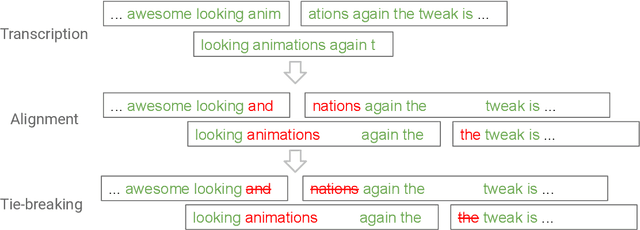
End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.