 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-signed neural fitting for surface reconstruction from unoriented point clouds
Jun 14, 2022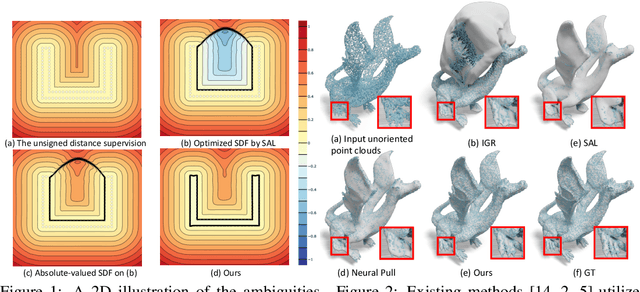
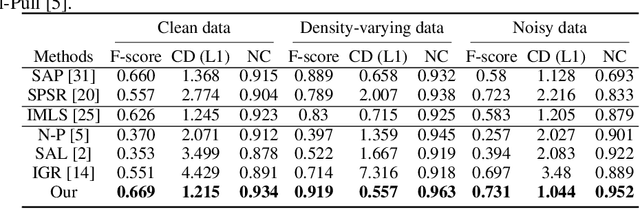
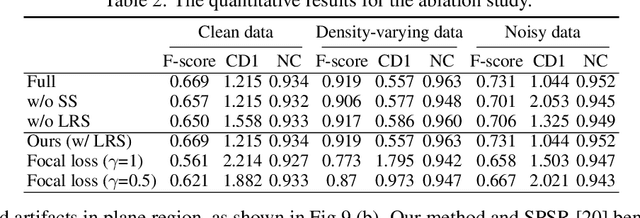
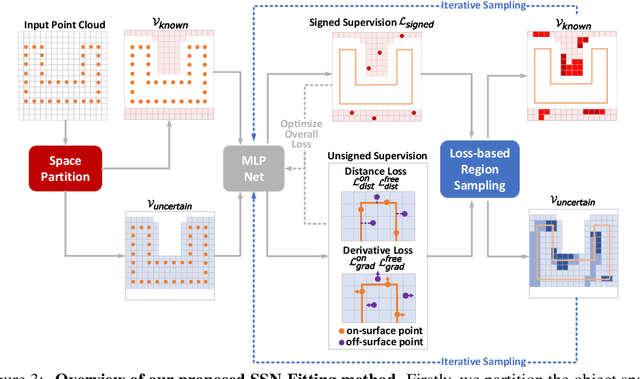
Reconstructing 3D geometry from \emph{unoriented} point clouds can benefit many downstream tasks. Recent methods mostly adopt a neural shape representation with a neural network to represent a signed distance field and fit the point cloud with an unsigned supervision. However, we observe that using unsigned supervision may cause severe ambiguities and often leads to \emph{unexpected} failures such as generating undesired surfaces in free space when reconstructing complex structures and struggle with reconstructing accurate surfaces. To reconstruct a better signed distance field, we propose semi-signed neural fitting (SSN-Fitting), which consists of a semi-signed supervision and a loss-based region sampling strategy. Our key insight is that signed supervision is more informative and regions that are obviously outside the object can be easily determined. Meanwhile, a novel importance sampling is proposed to accelerate the optimization and better reconstruct the fine details. Specifically, we voxelize and partition the object space into \emph{sign-known} and \emph{sign-uncertain} regions, in which different supervisions are applied. Also, we adaptively adjust the sampling rate of each voxel according to the tracked reconstruction loss, so that the network can focus more on the complex under-fitting regions. We conduct extensive experiments to demonstrate that SSN-Fitting achieves state-of-the-art performance under different settings on multiple datasets, including clean, density-varying, and noisy data.
Neural Template: Topology-aware Reconstruction and Disentangled Generation of 3D Meshes
Jun 10, 2022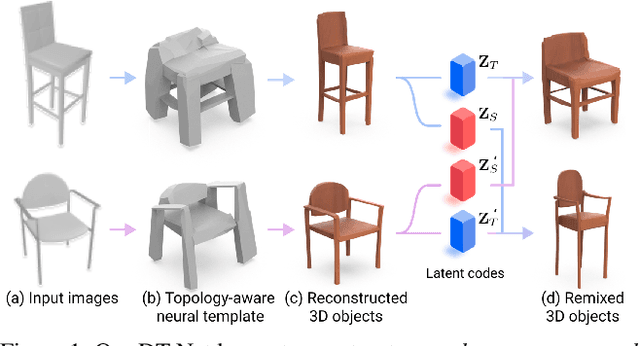
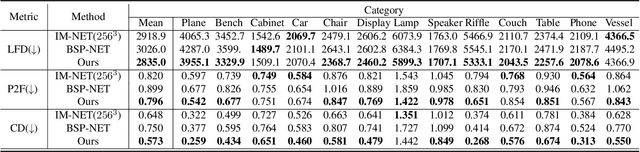
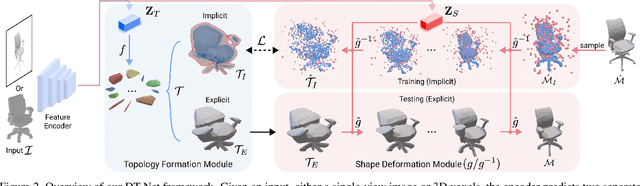
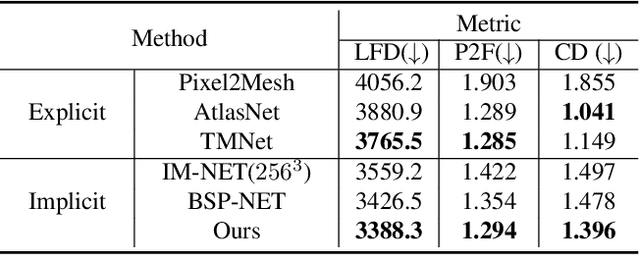
This paper introduces a novel framework called DTNet for 3D mesh reconstruction and generation via Disentangled Topology. Beyond previous works, we learn a topology-aware neural template specific to each input then deform the template to reconstruct a detailed mesh while preserving the learned topology. One key insight is to decouple the complex mesh reconstruction into two sub-tasks: topology formulation and shape deformation. Thanks to the decoupling, DT-Net implicitly learns a disentangled representation for the topology and shape in the latent space. Hence, it can enable novel disentangled controls for supporting various shape generation applications, e.g., remix the topologies of 3D objects, that are not achievable by previous reconstruction works. Extensive experimental results demonstrate that our method is able to produce high-quality meshes, particularly with diverse topologies, as compared with the state-of-the-art methods.
Towards Implicit Text-Guided 3D Shape Generation
Mar 28, 2022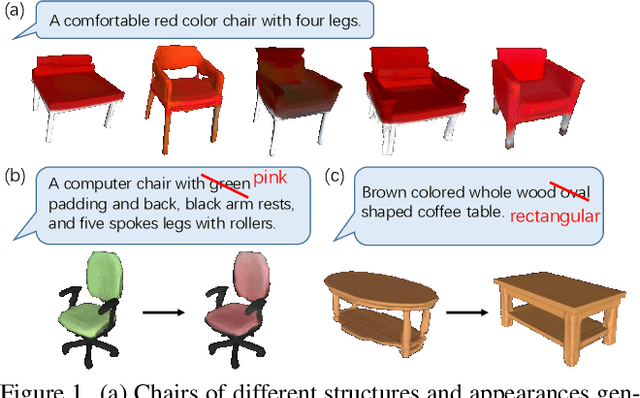
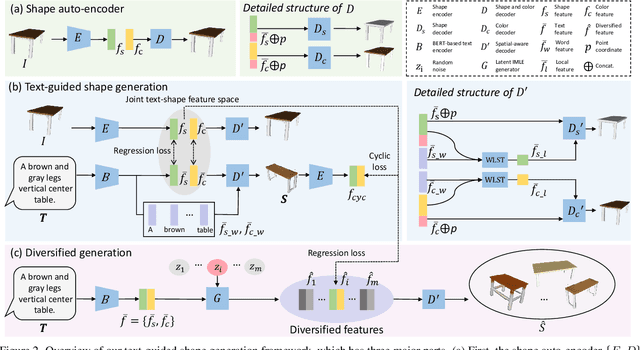
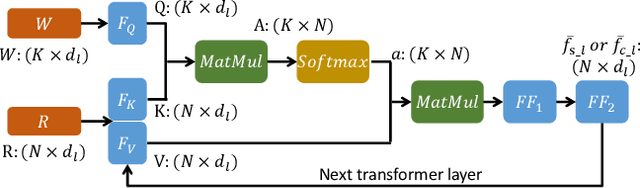
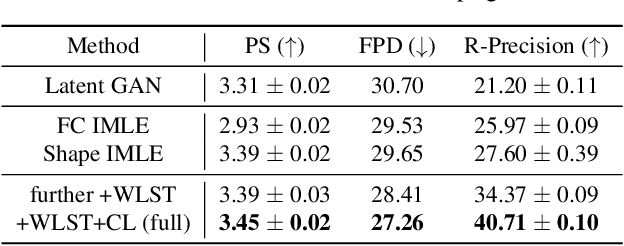
In this work, we explore the challenging task of generating 3D shapes from text. Beyond the existing works, we propose a new approach for text-guided 3D shape generation, capable of producing high-fidelity shapes with colors that match the given text description. This work has several technical contributions. First, we decouple the shape and color predictions for learning features in both texts and shapes, and propose the word-level spatial transformer to correlate word features from text with spatial features from shape. Also, we design a cyclic loss to encourage consistency between text and shape, and introduce the shape IMLE to diversify the generated shapes. Further, we extend the framework to enable text-guided shape manipulation. Extensive experiments on the largest existing text-shape benchmark manifest the superiority of this work. The code and the models are available at https://github.com/liuzhengzhe/Towards-Implicit Text-Guided-Shape-Generation.
Towards Robust Part-aware Instance Segmentation for Industrial Bin Picking
Mar 05, 2022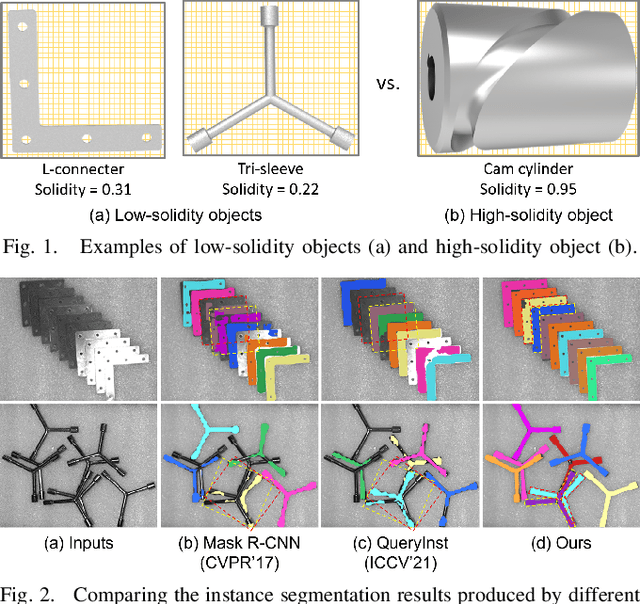

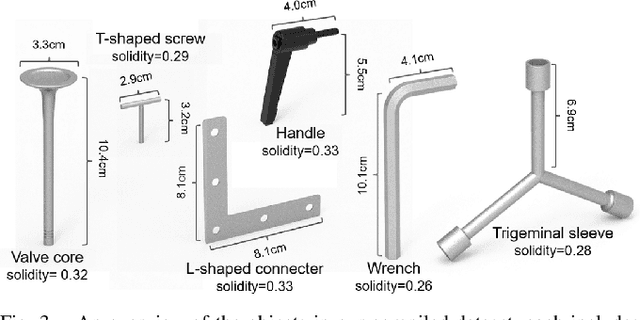
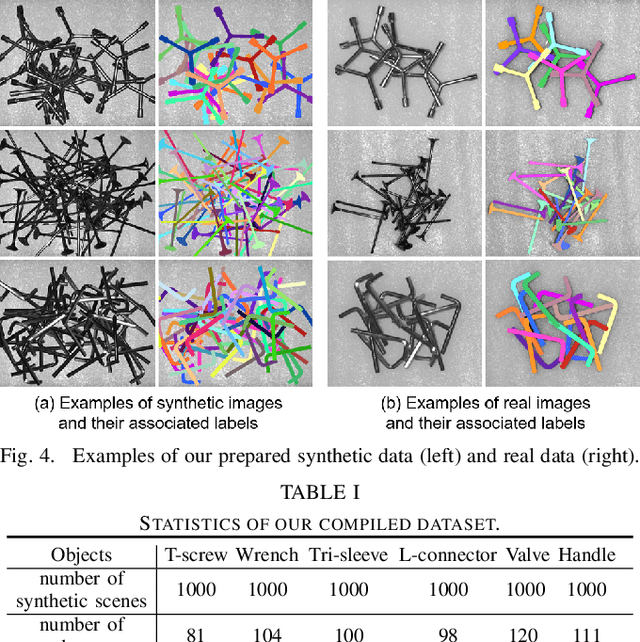
Industrial bin picking is a challenging task that requires accurate and robust segmentation of individual object instances. Particularly, industrial objects can have irregular shapes, that is, thin and concave, whereas in bin-picking scenarios, objects are often closely packed with strong occlusion. To address these challenges, we formulate a novel part-aware instance segmentation pipeline. The key idea is to decompose industrial objects into correlated approximate convex parts and enhance the object-level segmentation with part-level segmentation. We design a part-aware network to predict part masks and part-to-part offsets, followed by a part aggregation module to assemble the recognized parts into instances. To guide the network learning, we also propose an automatic label decoupling scheme to generate ground-truth part-level labels from instance-level labels. Finally, we contribute the first instance segmentation dataset, which contains a variety of industrial objects that are thin and have non-trivial shapes. Extensive experimental results on various industrial objects demonstrate that our method can achieve the best segmentation results compared with the state-of-the-art approaches.
Point Set Self-Embedding
Feb 28, 2022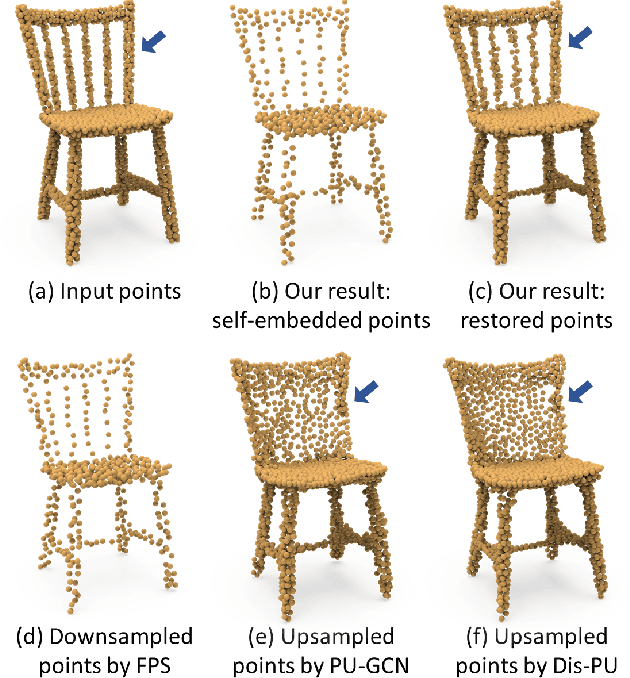
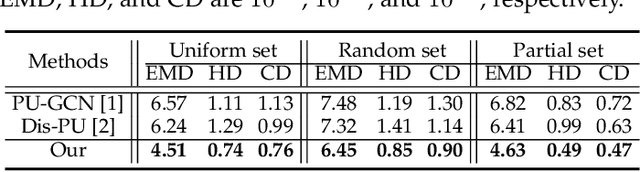


This work presents an innovative method for point set self-embedding, that encodes the structural information of a dense point set into its sparser version in a visual but imperceptible form. The self-embedded point set can function as the ordinary downsampled one and be visualized efficiently on mobile devices. Particularly, we can leverage the self-embedded information to fully restore the original point set for detailed analysis on remote servers. This task is challenging since both the self-embedded point set and the restored point set should resemble the original one. To achieve a learnable self-embedding scheme, we design a novel framework with two jointly-trained networks: one to encode the input point set into its self-embedded sparse point set and the other to leverage the embedded information for inverting the original point set back. Further, we develop a pair of up-shuffle and down-shuffle units in the two networks, and formulate loss terms to encourage the shape similarity and point distribution in the results. Extensive qualitative and quantitative results demonstrate the effectiveness of our method on both synthetic and real-scanned datasets.
Guided Point Contrastive Learning for Semi-supervised Point Cloud Semantic Segmentation
Oct 15, 2021
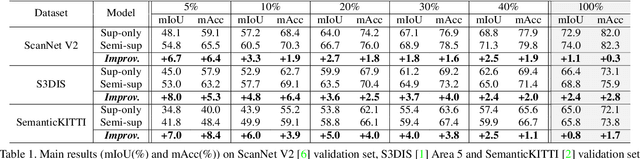
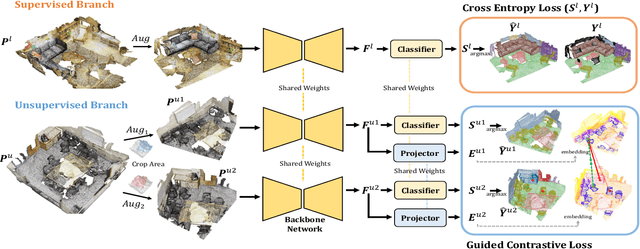
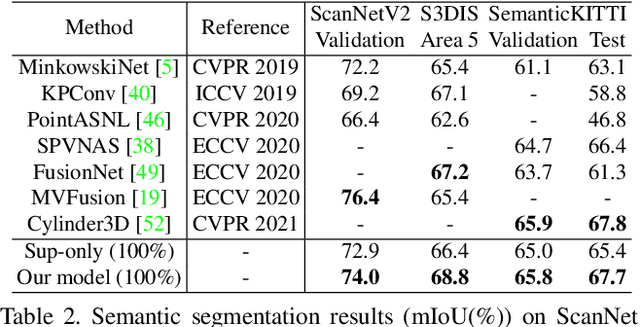
Rapid progress in 3D semantic segmentation is inseparable from the advances of deep network models, which highly rely on large-scale annotated data for training. To address the high cost and challenges of 3D point-level labeling, we present a method for semi-supervised point cloud semantic segmentation to adopt unlabeled point clouds in training to boost the model performance. Inspired by the recent contrastive loss in self-supervised tasks, we propose the guided point contrastive loss to enhance the feature representation and model generalization ability in semi-supervised setting. Semantic predictions on unlabeled point clouds serve as pseudo-label guidance in our loss to avoid negative pairs in the same category. Also, we design the confidence guidance to ensure high-quality feature learning. Besides, a category-balanced sampling strategy is proposed to collect positive and negative samples to mitigate the class imbalance problem. Extensive experiments on three datasets (ScanNet V2, S3DIS, and SemanticKITTI) show the effectiveness of our semi-supervised method to improve the prediction quality with unlabeled data.
Towards Accurate Alignment in Real-time 3D Hand-Mesh Reconstruction
Sep 03, 2021
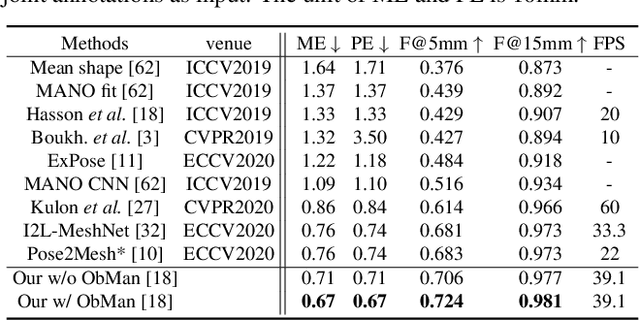
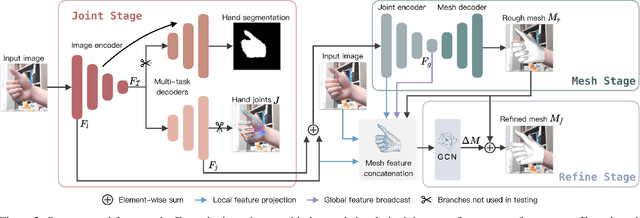
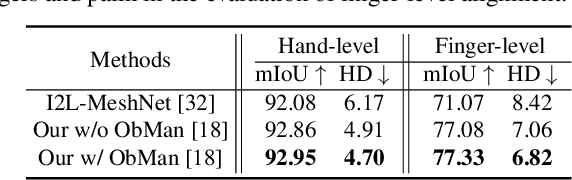
3D hand-mesh reconstruction from RGB images facilitates many applications, including augmented reality (AR). However, this requires not only real-time speed and accurate hand pose and shape but also plausible mesh-image alignment. While existing works already achieve promising results, meeting all three requirements is very challenging. This paper presents a novel pipeline by decoupling the hand-mesh reconstruction task into three stages: a joint stage to predict hand joints and segmentation; a mesh stage to predict a rough hand mesh; and a refine stage to fine-tune it with an offset mesh for mesh-image alignment. With careful design in the network structure and in the loss functions, we can promote high-quality finger-level mesh-image alignment and drive the models together to deliver real-time predictions. Extensive quantitative and qualitative results on benchmark datasets demonstrate that the quality of our results outperforms the state-of-the-art methods on hand-mesh/pose precision and hand-image alignment. In the end, we also showcase several real-time AR scenarios.
SP-GAN: Sphere-Guided 3D Shape Generation and Manipulation
Aug 10, 2021
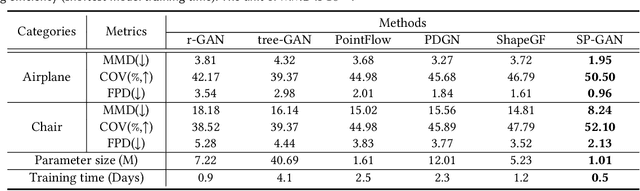
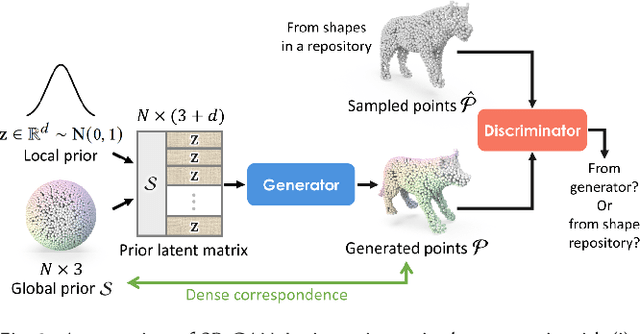
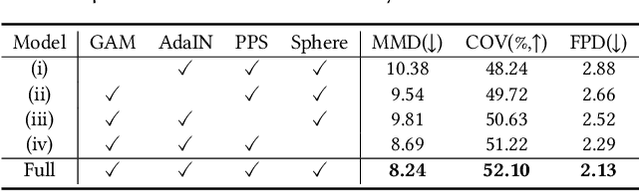
We present SP-GAN, a new unsupervised sphere-guided generative model for direct synthesis of 3D shapes in the form of point clouds. Compared with existing models, SP-GAN is able to synthesize diverse and high-quality shapes with fine details and promote controllability for part-aware shape generation and manipulation, yet trainable without any parts annotations. In SP-GAN, we incorporate a global prior (uniform points on a sphere) to spatially guide the generative process and attach a local prior (a random latent code) to each sphere point to provide local details. The key insight in our design is to disentangle the complex 3D shape generation task into a global shape modeling and a local structure adjustment, to ease the learning process and enhance the shape generation quality. Also, our model forms an implicit dense correspondence between the sphere points and points in every generated shape, enabling various forms of structure-aware shape manipulations such as part editing, part-wise shape interpolation, and multi-shape part composition, etc., beyond the existing generative models. Experimental results, which include both visual and quantitative evaluations, demonstrate that our model is able to synthesize diverse point clouds with fine details and less noise, as compared with the state-of-the-art models.
* SIGGRAPH 2021, website https://liruihui.github.io/publication/SP-GAN/
Accurate Grid Keypoint Learning for Efficient Video Prediction
Jul 28, 2021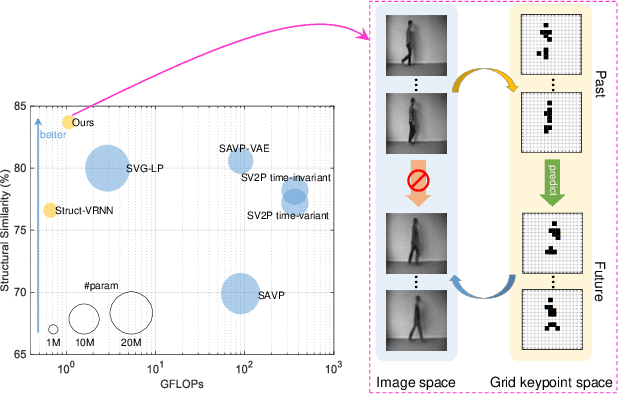
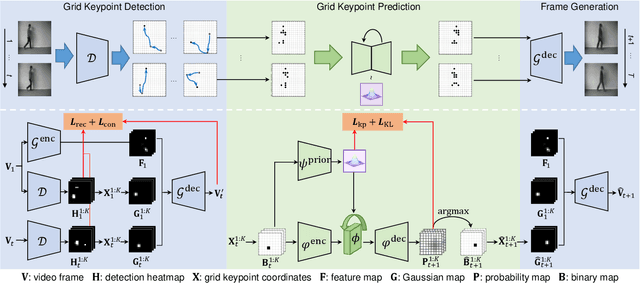
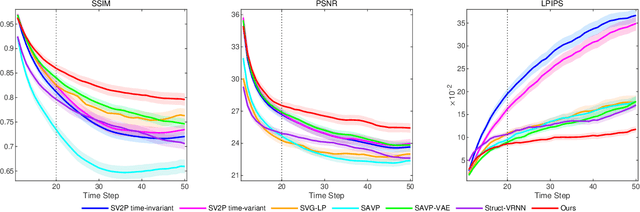

Video prediction methods generally consume substantial computing resources in training and deployment, among which keypoint-based approaches show promising improvement in efficiency by simplifying dense image prediction to light keypoint prediction. However, keypoint locations are often modeled only as continuous coordinates, so noise from semantically insignificant deviations in videos easily disrupt learning stability, leading to inaccurate keypoint modeling. In this paper, we design a new grid keypoint learning framework, aiming at a robust and explainable intermediate keypoint representation for long-term efficient video prediction. We have two major technical contributions. First, we detect keypoints by jumping among candidate locations in our raised grid space and formulate a condensation loss to encourage meaningful keypoints with strong representative capability. Second, we introduce a 2D binary map to represent the detected grid keypoints and then suggest propagating keypoint locations with stochasticity by selecting entries in the discrete grid space, thus preserving the spatial structure of keypoints in the longterm horizon for better future frame generation. Extensive experiments verify that our method outperforms the state-ofthe-art stochastic video prediction methods while saves more than 98% of computing resources. We also demonstrate our method on a robotic-assisted surgery dataset with promising results. Our code is available at https://github.com/xjgaocs/Grid-Keypoint-Learning.
FloorLevel-Net: Recognizing Floor-Level Lines with Height-Attention-Guided Multi-task Learning
Jul 06, 2021
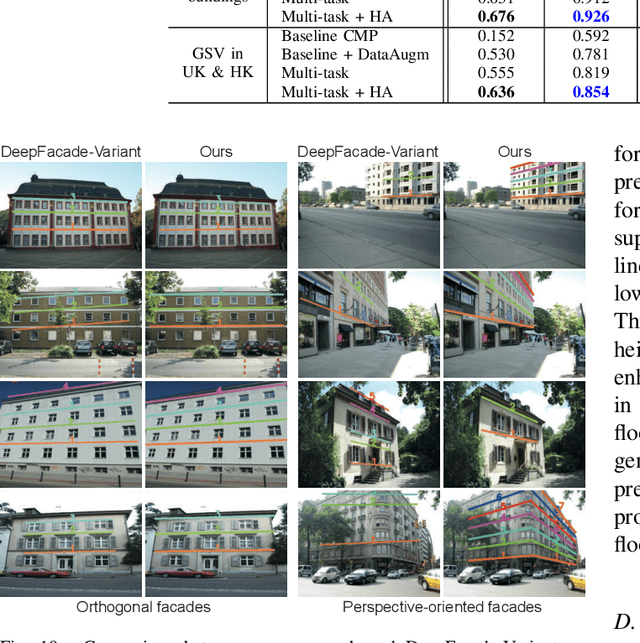


The ability to recognize the position and order of the floor-level lines that divide adjacent building floors can benefit many applications, for example, urban augmented reality (AR). This work tackles the problem of locating floor-level lines in street-view images, using a supervised deep learning approach. Unfortunately, very little data is available for training such a network $-$ current street-view datasets contain either semantic annotations that lack geometric attributes, or rectified facades without perspective priors. To address this issue, we first compile a new dataset and develop a new data augmentation scheme to synthesize training samples by harassing (i) the rich semantics of existing rectified facades and (ii) perspective priors of buildings in diverse street views. Next, we design FloorLevel-Net, a multi-task learning network that associates explicit features of building facades and implicit floor-level lines, along with a height-attention mechanism to help enforce a vertical ordering of floor-level lines. The generated segmentations are then passed to a second-stage geometry post-processing to exploit self-constrained geometric priors for plausible and consistent reconstruction of floor-level lines. Quantitative and qualitative evaluations conducted on assorted facades in existing datasets and street views from Google demonstrate the effectiveness of our approach. Also, we present context-aware image overlay results and show the potentials of our approach in enriching AR-related applications.