 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Oct 15, 2021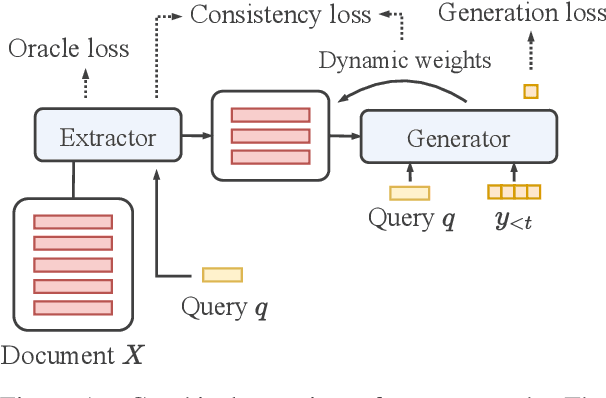
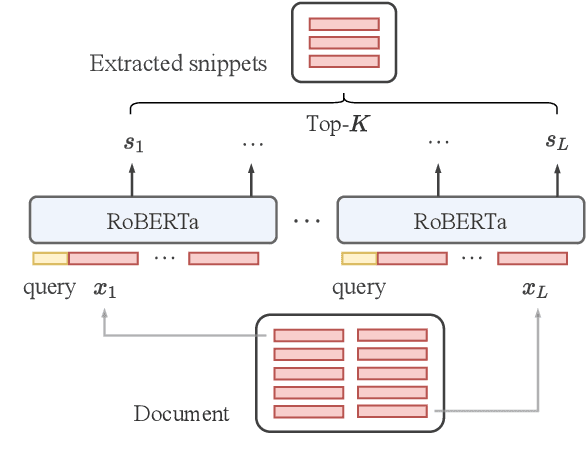
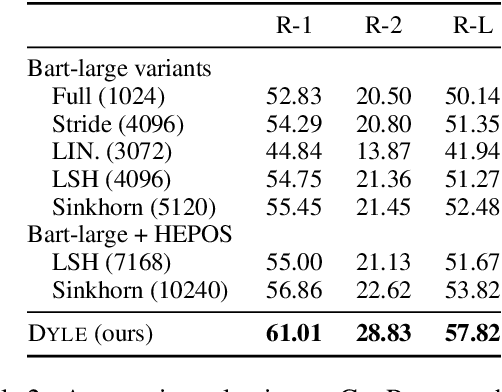
Transformer-based models have achieved state-of-the-art performance on short text summarization. However, they still struggle with long-input summarization. In this paper, we present a new approach for long-input summarization: Dynamic Latent Extraction for Abstractive Summarization. We jointly train an extractor with an abstractor and treat the extracted text snippets as the latent variable. We propose extractive oracles to provide the extractor with a strong learning signal. We introduce consistency loss, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We conduct extensive tests on two long-input summarization datasets, GovReport (document) and QMSum (dialogue). Our model significantly outperforms the current state-of-the-art, including a 6.21 ROUGE-2 improvement on GovReport and a 2.13 ROUGE-1 improvement on QMSum. Further analysis shows that the dynamic weights make our generation process highly interpretable. Our code will be publicly available upon publication.
End-to-End Segmentation-based News Summarization
Oct 15, 2021

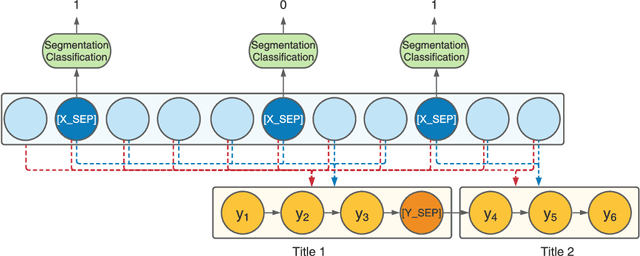
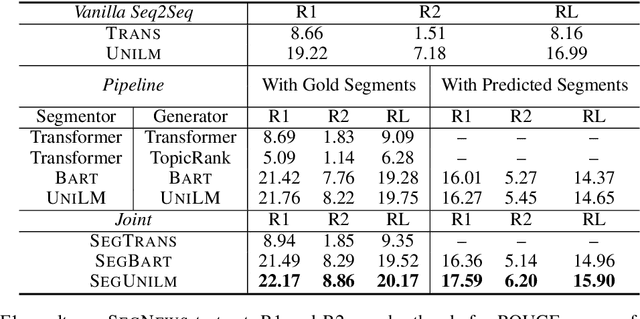
In this paper, we bring a new way of digesting news content by introducing the task of segmenting a news article into multiple sections and generating the corresponding summary to each section. We make two contributions towards this new task. First, we create and make available a dataset, SegNews, consisting of 27k news articles with sections and aligned heading-style section summaries. Second, we propose a novel segmentation-based language generation model adapted from pre-trained language models that can jointly segment a document and produce the summary for each section. Experimental results on SegNews demonstrate that our model can outperform several state-of-the-art sequence-to-sequence generation models for this new task.
Dict-BERT: Enhancing Language Model Pre-training with Dictionary
Oct 13, 2021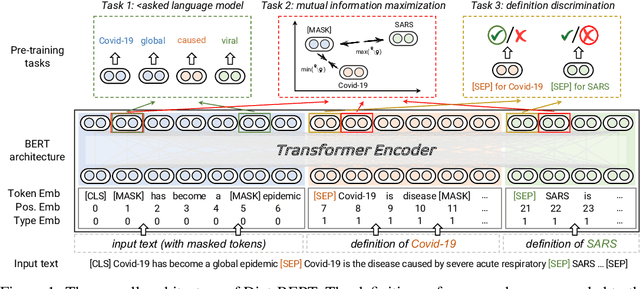
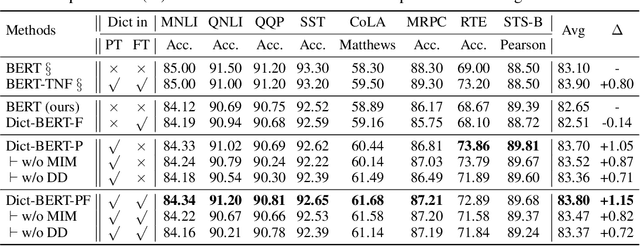
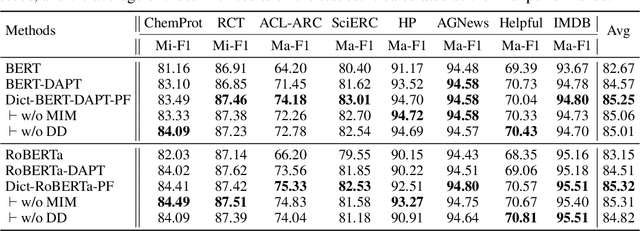
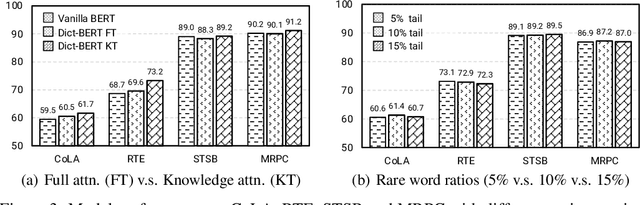
Pre-trained language models (PLMs) aim to learn universal language representations by conducting self-supervised training tasks on large-scale corpora. Since PLMs capture word semantics in different contexts, the quality of word representations highly depends on word frequency, which usually follows a heavy-tailed distributions in the pre-training corpus. Therefore, the embeddings of rare words on the tail are usually poorly optimized. In this work, we focus on enhancing language model pre-training by leveraging definitions of the rare words in dictionaries (e.g., Wiktionary). To incorporate a rare word definition as a part of input, we fetch its definition from the dictionary and append it to the end of the input text sequence. In addition to training with the masked language modeling objective, we propose two novel self-supervised pre-training tasks on word and sentence-level alignment between input text sequence and rare word definitions to enhance language modeling representation with dictionary. We evaluate the proposed Dict-BERT model on the language understanding benchmark GLUE and eight specialized domain benchmark datasets. Extensive experiments demonstrate that Dict-BERT can significantly improve the understanding of rare words and boost model performance on various NLP downstream tasks.
KG-FiD: Infusing Knowledge Graph in Fusion-in-Decoder for Open-Domain Question Answering
Oct 08, 2021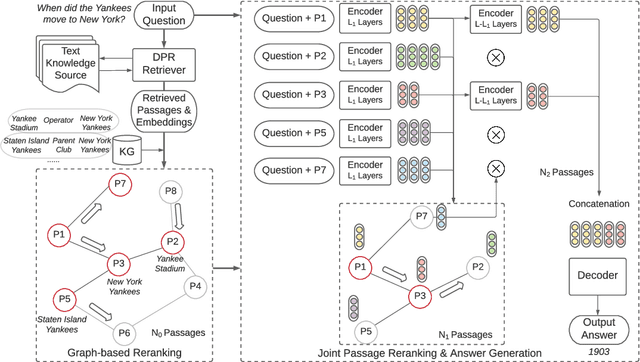
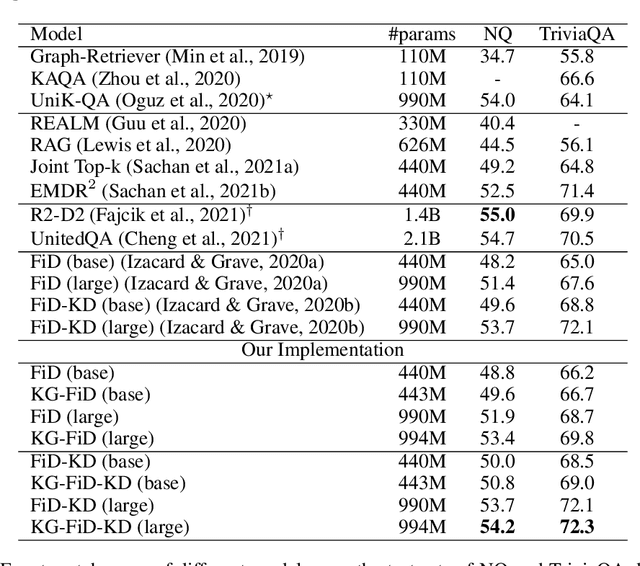
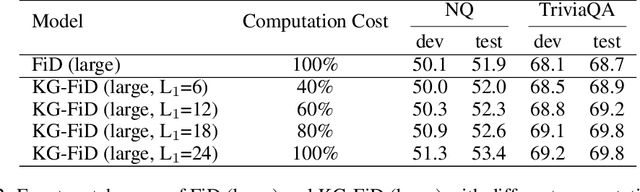
Current Open-Domain Question Answering (ODQA) model paradigm often contains a retrieving module and a reading module. Given an input question, the reading module predicts the answer from the relevant passages which are retrieved by the retriever. The recent proposed Fusion-in-Decoder (FiD), which is built on top of the pretrained generative model T5, achieves the state-of-the-art performance in the reading module. Although being effective, it remains constrained by inefficient attention on all retrieved passages which contain a lot of noise. In this work, we propose a novel method KG-FiD, which filters noisy passages by leveraging the structural relationship among the retrieved passages with a knowledge graph. We initiate the passage node embedding from the FiD encoder and then use graph neural network (GNN) to update the representation for reranking. To improve the efficiency, we build the GNN on top of the intermediate layer output of the FiD encoder and only pass a few top reranked passages into the higher layers of encoder and decoder for answer generation. We also apply the proposed GNN based reranking method to enhance the passage retrieval results in the retrieving module. Extensive experiments on common ODQA benchmark datasets (Natural Question and TriviaQA) demonstrate that KG-FiD can improve vanilla FiD by up to 1.5% on answer exact match score and achieve comparable performance with FiD with only 40% of computation cost.
An Exploratory Study on Long Dialogue Summarization: What Works and What's Next
Sep 10, 2021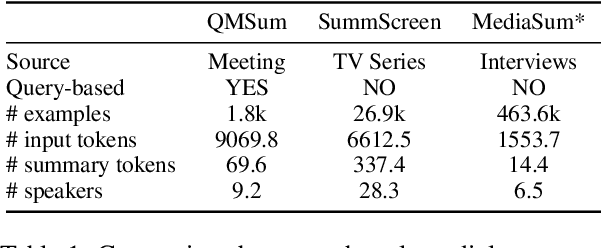
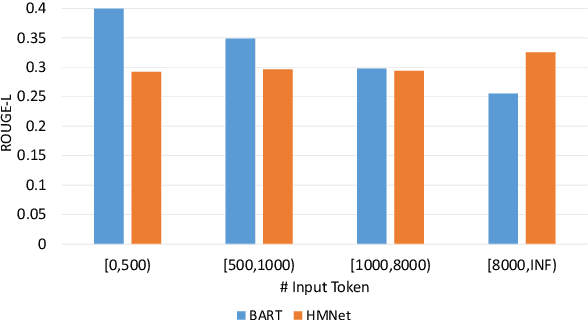
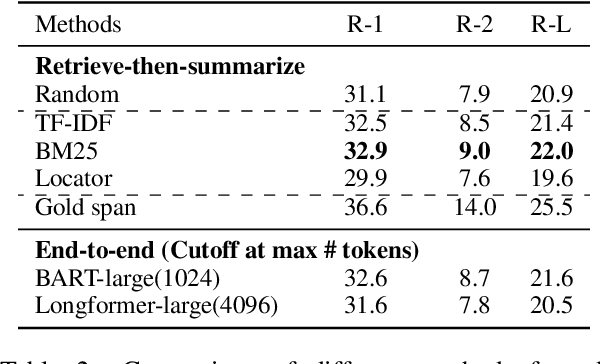
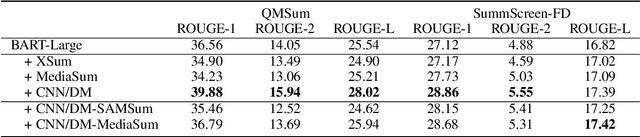
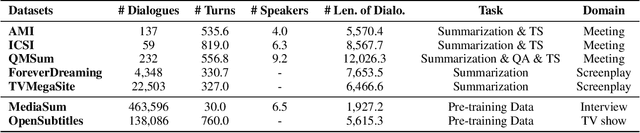
Dialogue summarization helps readers capture salient information from long conversations in meetings, interviews, and TV series. However, real-world dialogues pose a great challenge to current summarization models, as the dialogue length typically exceeds the input limits imposed by recent transformer-based pre-trained models, and the interactive nature of dialogues makes relevant information more context-dependent and sparsely distributed than news articles. In this work, we perform a comprehensive study on long dialogue summarization by investigating three strategies to deal with the lengthy input problem and locate relevant information: (1) extended transformer models such as Longformer, (2) retrieve-then-summarize pipeline models with several dialogue utterance retrieval methods, and (3) hierarchical dialogue encoding models such as HMNet. Our experimental results on three long dialogue datasets (QMSum, MediaSum, SummScreen) show that the retrieve-then-summarize pipeline models yield the best performance. We also demonstrate that the summary quality can be further improved with a stronger retrieval model and pretraining on proper external summarization datasets.
DialogLM: Pre-trained Model for Long Dialogue Understanding and Summarization
Sep 06, 2021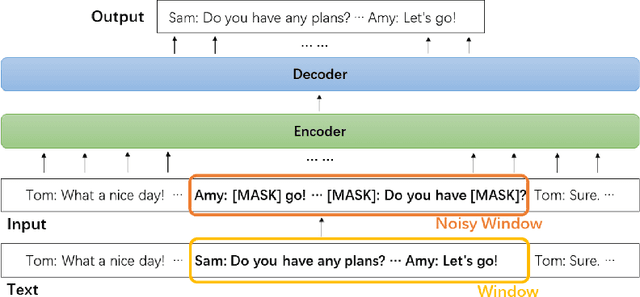

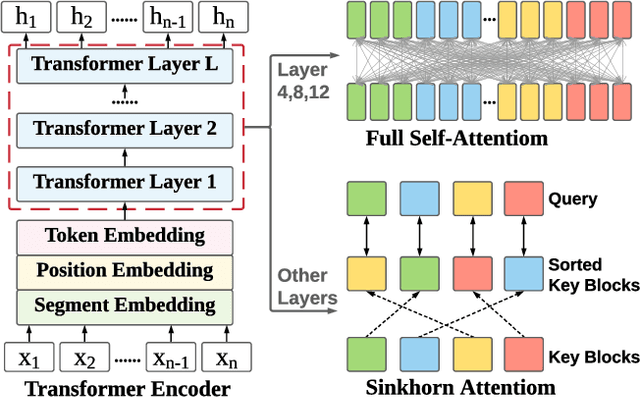
Dialogue is an essential part of human communication and cooperation. Existing research mainly focuses on short dialogue scenarios in a one-on-one fashion. However, multi-person interactions in the real world, such as meetings or interviews, are frequently over a few thousand words. There is still a lack of corresponding research and powerful tools to understand and process such long dialogues. Therefore, in this work, we present a pre-training framework for long dialogue understanding and summarization. Considering the nature of long conversations, we propose a window-based denoising approach for generative pre-training. For a dialogue, it corrupts a window of text with dialogue-inspired noise, and guides the model to reconstruct this window based on the content of the remaining conversation. Furthermore, to process longer input, we augment the model with sparse attention which is combined with conventional attention in a hybrid manner. We conduct extensive experiments on five datasets of long dialogues, covering tasks of dialogue summarization, abstractive question answering and topic segmentation. Experimentally, we show that our pre-trained model DialogLM significantly surpasses the state-of-the-art models across datasets and tasks.
Does Knowledge Help General NLU? An Empirical Study
Sep 01, 2021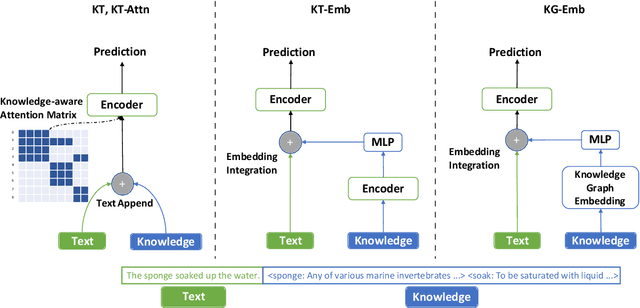

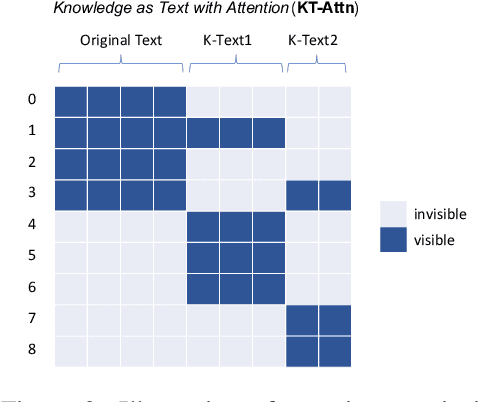
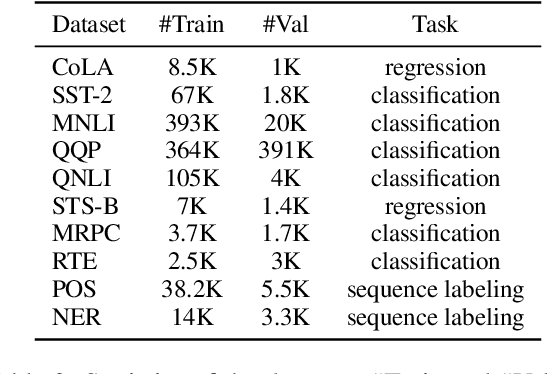
It is often observed in knowledge-centric tasks (e.g., common sense question and answering, relation classification) that the integration of external knowledge such as entity representation into language models can help provide useful information to boost the performance. However, it is still unclear whether this benefit can extend to general natural language understanding (NLU) tasks. In this work, we empirically investigated the contribution of external knowledge by measuring the end-to-end performance of language models with various knowledge integration methods. We find that the introduction of knowledge can significantly improve the results on certain tasks while having no adverse effects on other tasks. We then employ mutual information to reflect the difference brought by knowledge and a neural interpretation model to reveal how a language model utilizes external knowledge. Our study provides valuable insights and guidance for practitioners to equip NLP models with knowledge.
Want To Reduce Labeling Cost? GPT-3 Can Help
Aug 30, 2021
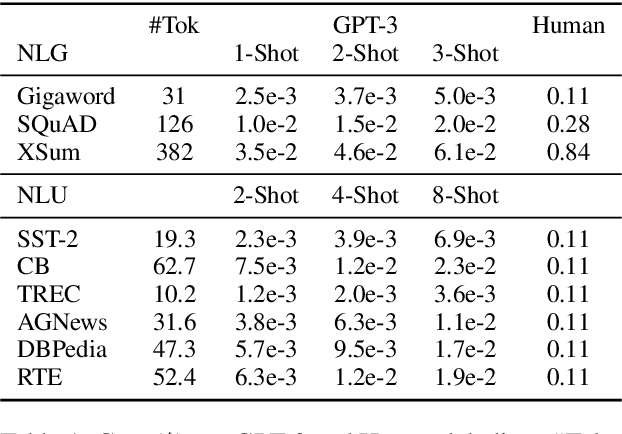
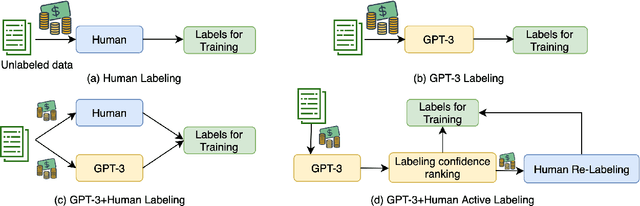
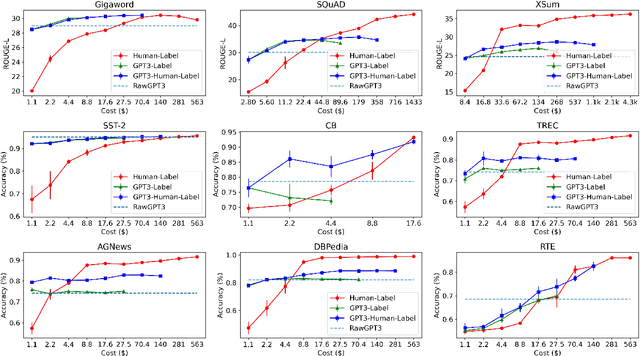
Data annotation is a time-consuming and labor-intensive process for many NLP tasks. Although there exist various methods to produce pseudo data labels, they are often task-specific and require a decent amount of labeled data to start with. Recently, the immense language model GPT-3 with 175 billion parameters has achieved tremendous improvement across many few-shot learning tasks. In this paper, we explore ways to leverage GPT-3 as a low-cost data labeler to train other models. We find that, to make the downstream model achieve the same performance on a variety of NLU and NLG tasks, it costs 50% to 96% less to use labels from GPT-3 than using labels from humans. Furthermore, we propose a novel framework of combining pseudo labels from GPT-3 with human labels, which leads to even better performance with limited labeling budget. These results present a cost-effective data labeling methodology that is generalizable to many practical applications.
Retrieval Enhanced Model for Commonsense Generation
May 24, 2021
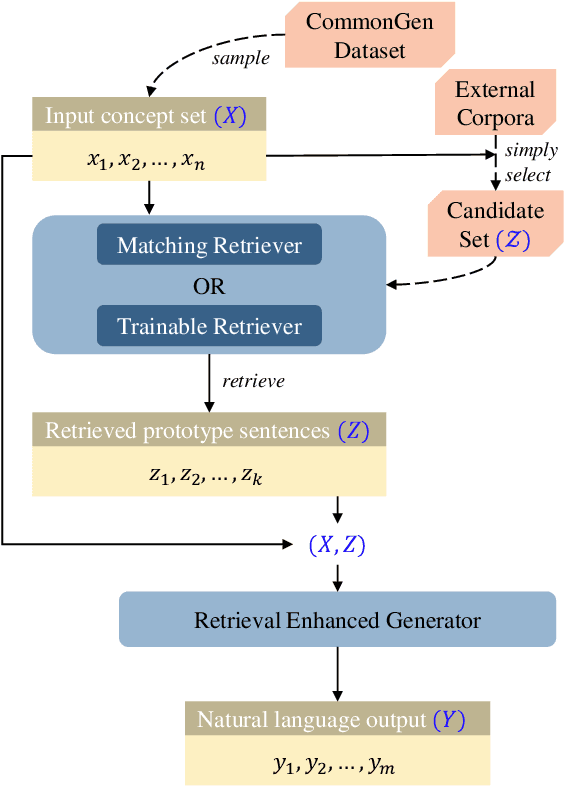
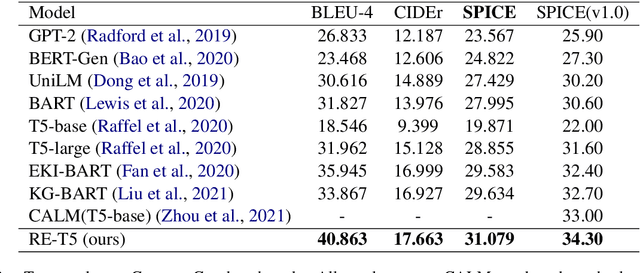

Commonsense generation is a challenging task of generating a plausible sentence describing an everyday scenario using provided concepts. Its requirement of reasoning over commonsense knowledge and compositional generalization ability even puzzles strong pre-trained language generation models. We propose a novel framework using retrieval methods to enhance both the pre-training and fine-tuning for commonsense generation. We retrieve prototype sentence candidates by concept matching and use them as auxiliary input. For fine-tuning, we further boost its performance with a trainable sentence retriever. We demonstrate experimentally on the large-scale CommonGen benchmark that our approach achieves new state-of-the-art results.
Sentence-Permuted Paragraph Generation
Apr 15, 2021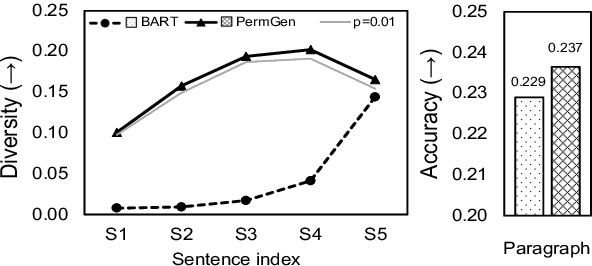
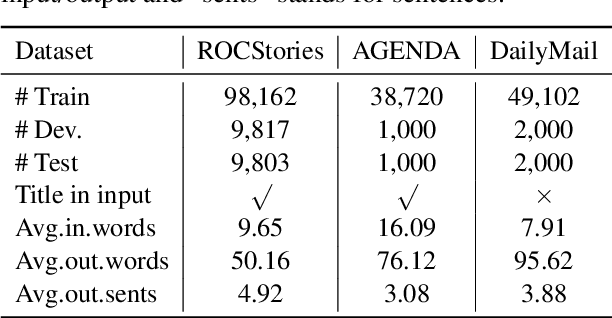
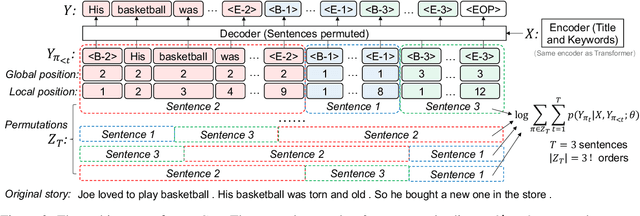
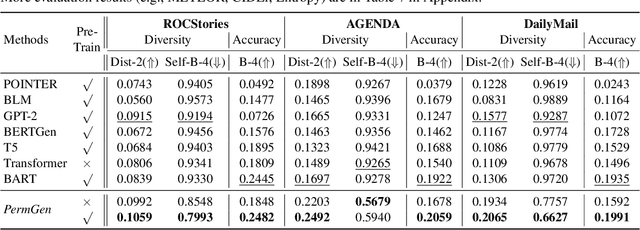
Generating paragraphs of diverse contents is important in many applications. Existing generation models produce similar contents from homogenized contexts due to the fixed left-to-right sentence order. Our idea is permuting the sentence orders to improve the content diversity of multi-sentence paragraph. We propose a novel framework PermGen whose objective is to maximize the expected log-likelihood of output paragraph distributions with respect to all possible sentence orders. PermGen uses hierarchical positional embedding and designs new procedures for training, decoding, and candidate ranking in the sentence-permuted generation. Experiments on three paragraph generation benchmarks demonstrate PermGen generates more diverse outputs with a higher quality than existing models.