 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Universal and Robust Framework for Multiple Gas Recognition Based-on Spherical Normalization-Coupled Mahalanobis Algorithm
Jan 05, 2026Electronic nose (E-nose) systems face two interconnected challenges in open-set gas recognition: feature distribution shift caused by signal drift and decision boundary failure induced by unknown gas interference. Existing methods predominantly rely on Euclidean distance or conventional classifiers, failing to account for anisotropic feature distributions and dynamic signal intensity variations. To address these issues, this study proposes the Spherical Normalization coupled Mahalanobis (SNM) module, a universal post-processing module for open-set gas recognition. First, it achieves geometric decoupling through cascaded batch and L2 normalization, projecting features onto a unit hypersphere to eliminate signal intensity fluctuations. Second, it utilizes Mahalanobis distance to construct adaptive ellipsoidal decision boundaries that conform to the anisotropic feature geometry. The architecture-agnostic SNM-Module seamlessly integrates with mainstream backbones including Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Transformer. Experiments on the public Vergara dataset demonstrate that the Transformer+SNM configuration achieves near-theoretical-limit performance in discriminating among multiple target gases, with an AUROC of 0.9977 and an unknown gas detection rate of 99.57% at 5% false positive rate, significantly outperforming state-of-the-art methods with a 3.0% AUROC improvement and 91.0% standard deviation reduction compared to Class Anchor Clustering (CAC). The module maintains exceptional robustness across five sensor positions, with standard deviations below 0.0028. This work effectively addresses the critical challenge of simultaneously achieving high accuracy and high stability in open-set gas recognition, providing solid support for industrial E-nose deployment.
SNM-Net: A Universal Framework for Robust Open-Set Gas Recognition via Spherical Normalization and Mahalanobis Distance
Dec 28, 2025Electronic nose (E-nose) systems face dual challenges in open-set gas recognition: feature distribution shifts caused by signal drift and decision failures induced by unknown interference. Existing methods predominantly rely on Euclidean distance, failing to adequately account for anisotropic gas feature distributions and dynamic signal intensity variations. To address these issues, this study proposes SNM-Net, a universal deep learning framework for open-set gas recognition. The core innovation lies in a geometric decoupling mechanism achieved through cascaded batch normalization and L2 normalization, which projects high-dimensional features onto a unit hypersphere to eliminate signal intensity fluctuations. Additionally, Mahalanobis distance is introduced as the scoring mechanism, utilizing class-wise statistics to construct adaptive ellipsoidal decision boundaries. SNM-Net is architecture-agnostic and seamlessly integrates with CNN, RNN, and Transformer backbones. Systematic experiments on the Vergara dataset demonstrate that the Transformer+SNM configuration attains near-theoretical performance, achieving an AUROC of 0.9977 and an unknown gas detection rate of 99.57% (TPR at 5% FPR). This performance significantly outperforms state-of-the-art methods, showing a 3.0% improvement in AUROC and a 91.0% reduction in standard deviation compared to Class Anchor Clustering. The framework exhibits exceptional robustness across sensor positions with standard deviations below 0.0028. This work effectively resolves the trade-off between accuracy and stability, providing a solid technical foundation for industrial E-nose deployment.
Inferring Operator Emotions from a Motion-Controlled Robotic Arm
Dec 09, 2025A remote robot operator's affective state can significantly impact the resulting robot's motions leading to unexpected consequences, even when the user follows protocol and performs permitted tasks. The recognition of a user operator's affective states in remote robot control scenarios is, however, underexplored. Current emotion recognition methods rely on reading the user's vital signs or body language, but the devices and user participation these measures require would add limitations to remote robot control. We demonstrate that the functional movements of a remote-controlled robotic avatar, which was not designed for emotional expression, can be used to infer the emotional state of the human operator via a machine-learning system. Specifically, our system achieved 83.3$\%$ accuracy in recognizing the user's emotional state expressed by robot movements, as a result of their hand motions. We discuss the implications of this system on prominent current and future remote robot operation and affective robotic contexts.
PAVE: An End-to-End Dataset for Production Autonomous Vehicle Evaluation
Nov 19, 2025Most existing autonomous-driving datasets (e.g., KITTI, nuScenes, and the Waymo Perception Dataset), collected by human-driving mode or unidentified driving mode, can only serve as early training for the perception and prediction of autonomous vehicles (AVs). To evaluate the real behavioral safety of AVs controlled in the black box, we present the first end-to-end benchmark dataset collected entirely by autonomous-driving mode in the real world. This dataset contains over 100 hours of naturalistic data from multiple production autonomous-driving vehicle models in the market. We segment the original data into 32,727 key frames, each consisting of four synchronized camera images and high-precision GNSS/IMU data (0.8 cm localization accuracy). For each key frame, 20 Hz vehicle trajectories spanning the past 6 s and future 5 s are provided, along with detailed 2D annotations of surrounding vehicles, pedestrians, traffic lights, and traffic signs. These key frames have rich scenario-level attributes, including driver intent, area type (covering highways, urban roads, and residential areas), lighting (day, night, or dusk), weather (clear or rain), road surface (paved or unpaved), traffic and vulnerable road users (VRU) density, traffic lights, and traffic signs (warning, prohibition, and indication). To evaluate the safety of AVs, we employ an end-to-end motion planning model that predicts vehicle trajectories with an Average Displacement Error (ADE) of 1.4 m on autonomous-driving frames. The dataset continues to expand by over 10 hours of new data weekly, thereby providing a sustainable foundation for research on AV driving behavior analysis and safety evaluation. The PAVE dataset is publicly available at https://hkustgz-my.sharepoint.com/:f:/g/personal/kema_hkust-gz_edu_cn/IgDXyoHKfdGnSZ3JbbidjduMAXxs-Z3NXzm005A_Ix9tr0Q?e=9HReCu.
Unified Multimodal Vessel Trajectory Prediction with Explainable Navigation Intention
Nov 18, 2025Vessel trajectory prediction is fundamental to intelligent maritime systems. Within this domain, short-term prediction of rapid behavioral changes in complex maritime environments has established multimodal trajectory prediction (MTP) as a promising research area. However, existing vessel MTP methods suffer from limited scenario applicability and insufficient explainability. To address these challenges, we propose a unified MTP framework incorporating explainable navigation intentions, which we classify into sustained and transient categories. Our method constructs sustained intention trees from historical trajectories and models dynamic transient intentions using a Conditional Variational Autoencoder (CVAE), while using a non-local attention mechanism to maintain global scenario consistency. Experiments on real Automatic Identification System (AIS) datasets demonstrates our method's broad applicability across diverse scenarios, achieving significant improvements in both ADE and FDE. Furthermore, our method improves explainability by explicitly revealing the navigational intentions underlying each predicted trajectory.
DIMO: Diverse 3D Motion Generation for Arbitrary Objects
Nov 10, 2025



We present DIMO, a generative approach capable of generating diverse 3D motions for arbitrary objects from a single image. The core idea of our work is to leverage the rich priors in well-trained video models to extract the common motion patterns and then embed them into a shared low-dimensional latent space. Specifically, we first generate multiple videos of the same object with diverse motions. We then embed each motion into a latent vector and train a shared motion decoder to learn the distribution of motions represented by a structured and compact motion representation, i.e., neural key point trajectories. The canonical 3D Gaussians are then driven by these key points and fused to model the geometry and appearance. During inference time with learned latent space, we can instantly sample diverse 3D motions in a single-forward pass and support several interesting applications including 3D motion interpolation and language-guided motion generation. Our project page is available at https://linzhanm.github.io/dimo.
Global Feature Enhancing and Fusion Framework for Strain Gauge Time Series Classification
Nov 07, 2025



Strain Gauge Status (SGS) recognition is crucial in the field of intelligent manufacturing based on the Internet of Things, as accurate identification helps timely detection of failed mechanical components, avoiding accidents. The loading and unloading sequences generated by strain gauges can be identified through time series classification (TSC) algorithms. Recently, deep learning models, e.g., convolutional neural networks (CNNs) have shown remarkable success in the TSC task, as they can extract discriminative local features from the subsequences to identify the time series. However, we observe that only the local features may not be sufficient for expressing the time series, especially when the local sub-sequences between different time series are very similar, e.g., SGS data of aircraft wings in static strength experiments. Nevertheless, CNNs suffer from the limitation in extracting global features due to the nature of convolution operations. For extracting global features to more comprehensively represent the SGS time series, we propose two insights: (i) Constructing global features through feature engineering. (ii) Learning high-order relationships between local features to capture global features. To realize and utilize them, we propose a hypergraph-based global feature learning and fusion framework, which learns and fuses global features for semantic consistency to enhance the representation of SGS time series, thereby improving recognition accuracy. Our method designs are validated on industrial SGS and public UCR datasets, showing better generalization for unseen data in SGS recognition.
Instance Generation for Meta-Black-Box Optimization through Latent Space Reverse Engineering
Sep 19, 2025To relieve intensive human-expertise required to design optimization algorithms, recent Meta-Black-Box Optimization (MetaBBO) researches leverage generalization strength of meta-learning to train neural network-based algorithm design policies over a predefined training problem set, which automates the adaptability of the low-level optimizers on unseen problem instances. Currently, a common training problem set choice in existing MetaBBOs is well-known benchmark suites CoCo-BBOB. Although such choice facilitates the MetaBBO's development, problem instances in CoCo-BBOB are more or less limited in diversity, raising the risk of overfitting of MetaBBOs, which might further results in poor generalization. In this paper, we propose an instance generation approach, termed as \textbf{LSRE}, which could generate diverse training problem instances for MetaBBOs to learn more generalizable policies. LSRE first trains an autoencoder which maps high-dimensional problem features into a 2-dimensional latent space. Uniform-grid sampling in this latent space leads to hidden representations of problem instances with sufficient diversity. By leveraging a genetic-programming approach to search function formulas with minimal L2-distance to these hidden representations, LSRE reverse engineers a diversified problem set, termed as \textbf{Diverse-BBO}. We validate the effectiveness of LSRE by training various MetaBBOs on Diverse-BBO and observe their generalization performances on either synthetic or realistic scenarios. Extensive experimental results underscore the superiority of Diverse-BBO to existing training set choices in MetaBBOs. Further ablation studies not only demonstrate the effectiveness of design choices in LSRE, but also reveal interesting insights on instance diversity and MetaBBO's generalization.
BagIt! An Adaptive Dual-Arm Manipulation of Fabric Bags for Object Bagging
Sep 11, 2025



Bagging tasks, commonly found in industrial scenarios, are challenging considering deformable bags' complicated and unpredictable nature. This paper presents an automated bagging system from the proposed adaptive Structure-of-Interest (SOI) manipulation strategy for dual robot arms. The system dynamically adjusts its actions based on real-time visual feedback, removing the need for pre-existing knowledge of bag properties. Our framework incorporates Gaussian Mixture Models (GMM) for estimating SOI states, optimization techniques for SOI generation, motion planning via Constrained Bidirectional Rapidly-exploring Random Tree (CBiRRT), and dual-arm coordination using Model Predictive Control (MPC). Extensive experiments validate the capability of our system to perform precise and robust bagging across various objects, showcasing its adaptability. This work offers a new solution for robotic deformable object manipulation (DOM), particularly in automated bagging tasks. Video of this work is available at https://youtu.be/6JWjCOeTGiQ.
Text to Query Plans for Question Answering on Large Tables
Aug 26, 2025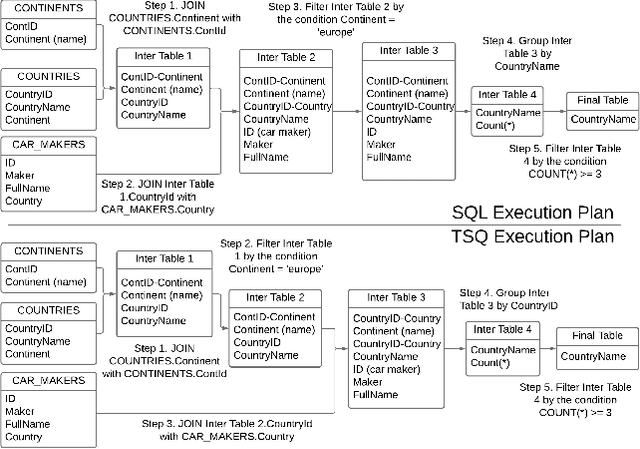

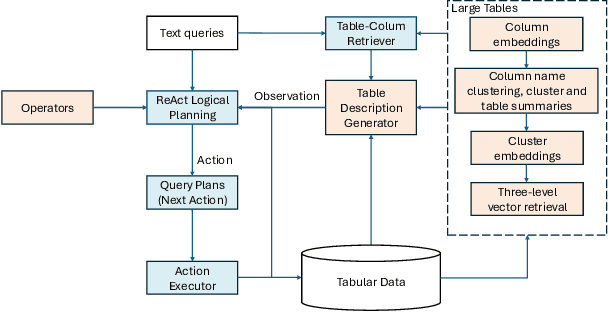

Efficient querying and analysis of large tabular datasets remain significant challenges, especially for users without expertise in programming languages like SQL. Text-to-SQL approaches have shown promising performance on benchmark data; however, they inherit SQL's drawbacks, including inefficiency with large datasets and limited support for complex data analyses beyond basic querying. We propose a novel framework that transforms natural language queries into query plans. Our solution is implemented outside traditional databases, allowing us to support classical SQL commands while avoiding SQL's inherent limitations. Additionally, we enable complex analytical functions, such as principal component analysis and anomaly detection, providing greater flexibility and extensibility than traditional SQL capabilities. We leverage LLMs to iteratively interpret queries and construct operation sequences, addressing computational complexity by incrementally building solutions. By executing operations directly on the data, we overcome context length limitations without requiring the entire dataset to be processed by the model. We validate our framework through experiments on both standard databases and large scientific tables, demonstrating its effectiveness in handling extensive datasets and performing sophisticated data analyses.