 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-Judge in Education: A Curriculum-Grounded Marking Pipeline
Jun 16, 2026Generative AI and large language models (LLMs) are increasingly applied to question generation and automated assessment. However, deploying LLMs in preparation for high-stakes exams requires more than prompt engineering; it demands software pipelines that systematically ground model outputs in authorised curriculum artefacts and marking guidelines issued by education authorities. This paper presents a curriculum-grounded, configurable LLM-as-Judge pipeline for question-level marking, co-developed with an industrial partner, to support exam preparation for university admission. The pipeline identifies the relevant topics, subtopics, and cognitive demand of a question, and assembles verifiable and authorised context to support LLM judgement. Curriculum intent is operationalised through concrete syllabus artefacts, including prescribed verbs and outcomes, performance band descriptors, glossary definitions, and marking-guideline principles. A staged LLM workflow is employed to first generate question-specific rubrics, capturing structured expectations of performance, and then derive and evaluate marking criteria used to allocate marks to student responses. This design improves consistency, transparency, and alignment with official marking practices. Preliminary evaluation shows that the proposed LLM-as-Judge pipeline delivers marking outcomes comparable to human tutors, while yielding justifications that are more traceable to authorised curriculum artefacts and marking standards. The pipeline has also been integrated into an online study platform, where early deployment data provide initial insights into operational usage and manual overrides.
Text to Query Plans for Question Answering on Large Tables
Aug 26, 2025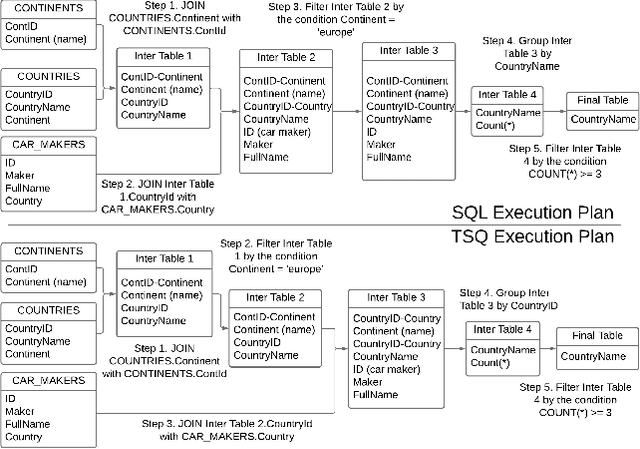

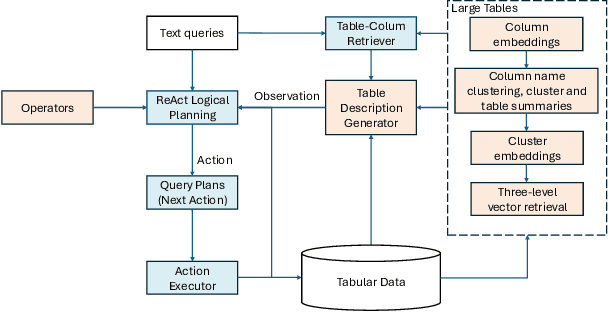

Efficient querying and analysis of large tabular datasets remain significant challenges, especially for users without expertise in programming languages like SQL. Text-to-SQL approaches have shown promising performance on benchmark data; however, they inherit SQL's drawbacks, including inefficiency with large datasets and limited support for complex data analyses beyond basic querying. We propose a novel framework that transforms natural language queries into query plans. Our solution is implemented outside traditional databases, allowing us to support classical SQL commands while avoiding SQL's inherent limitations. Additionally, we enable complex analytical functions, such as principal component analysis and anomaly detection, providing greater flexibility and extensibility than traditional SQL capabilities. We leverage LLMs to iteratively interpret queries and construct operation sequences, addressing computational complexity by incrementally building solutions. By executing operations directly on the data, we overcome context length limitations without requiring the entire dataset to be processed by the model. We validate our framework through experiments on both standard databases and large scientific tables, demonstrating its effectiveness in handling extensive datasets and performing sophisticated data analyses.