 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Motion Transfer from Poses in the Wild
Apr 07, 2020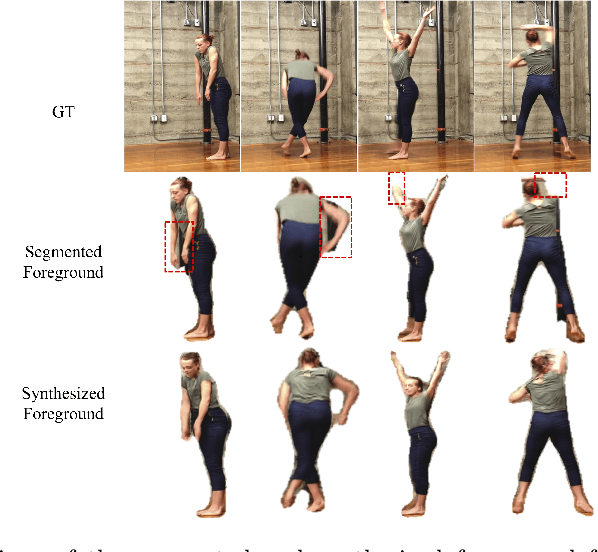
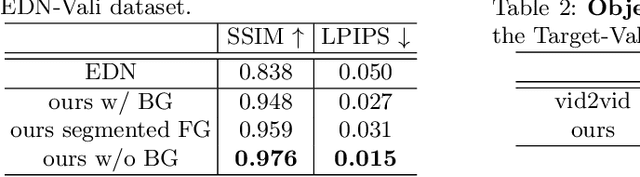
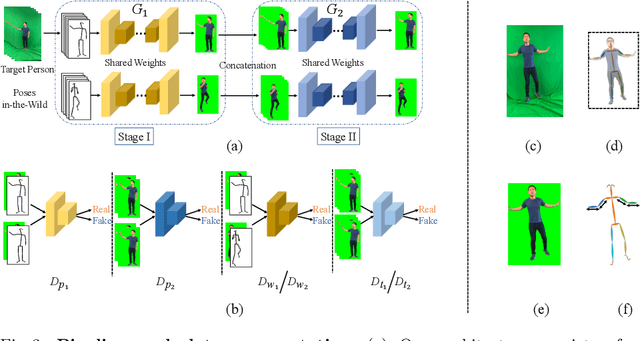

In this paper, we tackle the problem of human motion transfer, where we synthesize novel motion video for a target person that imitates the movement from a reference video. It is a video-to-video translation task in which the estimated poses are used to bridge two domains. Despite substantial progress on the topic, there exist several problems with the previous methods. First, there is a domain gap between training and testing pose sequences--the model is tested on poses it has not seen during training, such as difficult dancing moves. Furthermore, pose detection errors are inevitable, making the job of the generator harder. Finally, generating realistic pixels from sparse poses is challenging in a single step. To address these challenges, we introduce a novel pose-to-video translation framework for generating high-quality videos that are temporally coherent even for in-the-wild pose sequences unseen during training. We propose a pose augmentation method to minimize the training-test gap, a unified paired and unpaired learning strategy to improve the robustness to detection errors, and two-stage network architecture to achieve superior texture quality. To further boost research on the topic, we build two human motion datasets. Finally, we show the superiority of our approach over the state-of-the-art studies through extensive experiments and evaluations on different datasets.
Anatomy-aware 3D Human Pose Estimation in Videos
Mar 17, 2020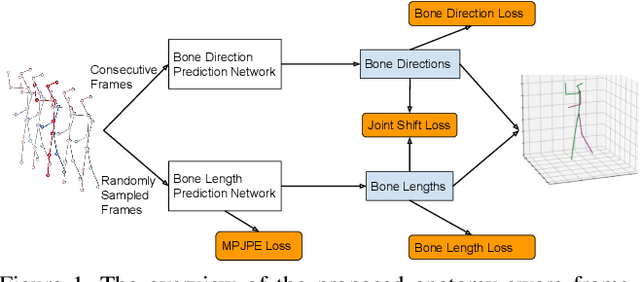
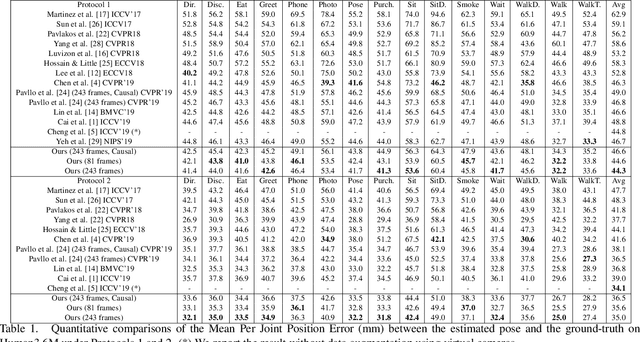
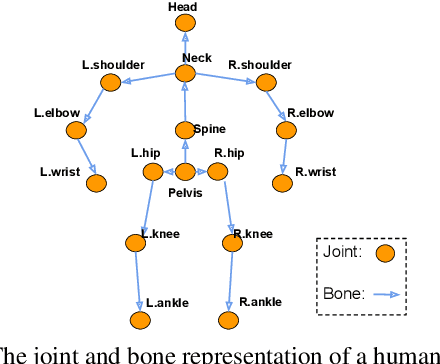
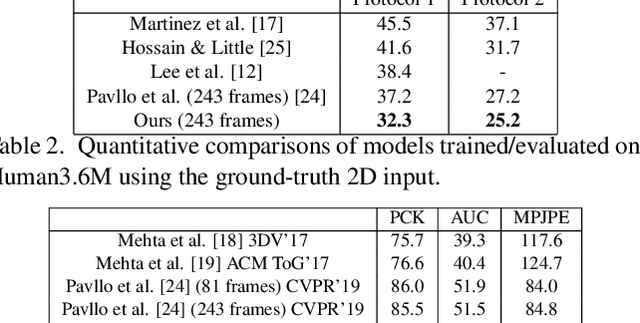
In this work, we propose a new solution for 3D human pose estimation in videos. Instead of directly regressing the 3D joint locations, we draw inspiration from the human skeleton anatomy and decompose the task into bone direction prediction and bone length prediction, from which the 3D joint locations can be completely derived. Our motivation is the fact that the bone lengths of a human skeleton remain consistent across time. This promotes us to develop effective techniques to utilize global information across {\it all} the frames in a video for high-accuracy bone length prediction. Moreover, for the bone direction prediction network, we propose a fully-convolutional propagating architecture with long skip connections. Essentially, it predicts the directions of different bones hierarchically without using any time-consuming memory units (e.g. LSTM). A novel joint shift loss is further introduced to bridge the training of the bone length and bone direction prediction networks. Finally, we employ an implicit attention mechanism to feed the 2D keypoint visibility scores into the model as extra guidance, which significantly mitigates the depth ambiguity in many challenging poses. Our full model outperforms the previous best results on Human3.6M and MPI-INF-3DHP datasets, where comprehensive evaluation validates the effectiveness of our model.
EnlightenGAN: Deep Light Enhancement without Paired Supervision
Jun 17, 2019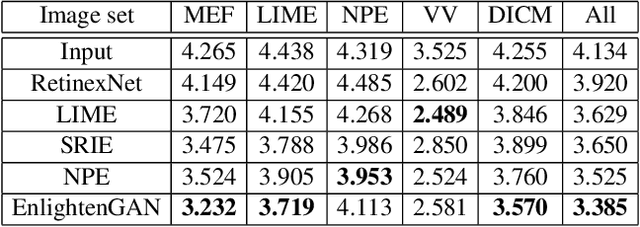
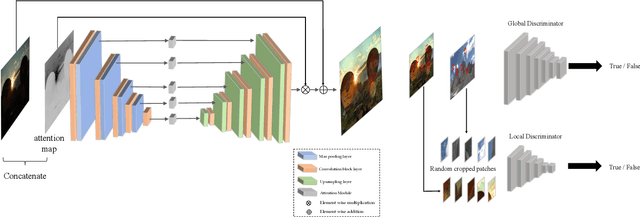


Deep learning-based methods have achieved remarkable success in image restoration and enhancement, but are they still competitive when there is a lack of paired training data? As one such example, this paper explores the low-light image enhancement problem, where in practice it is extremely challenging to simultaneously take a low-light and a normal-light photo of the same visual scene. We propose a highly effective unsupervised generative adversarial network, dubbed EnlightenGAN, that can be trained without low/normal-light image pairs, yet proves to generalize very well on various real-world test images. Instead of supervising the learning using ground truth data, we propose to regularize the unpaired training using the information extracted from the input itself, and benchmark a series of innovations for the low-light image enhancement problem, including a global-local discriminator structure, a self-regularized perceptual loss fusion, and attention mechanism. Through extensive experiments, our proposed approach outperforms recent methods under a variety of metrics in terms of visual quality and subjective user study. Thanks to the great flexibility brought by unpaired training, EnlightenGAN is demonstrated to be easily adaptable to enhancing real-world images from various domains. The code is available at \url{https://github.com/yueruchen/EnlightenGAN}
Multimodal Style Transfer via Graph Cuts
May 17, 2019
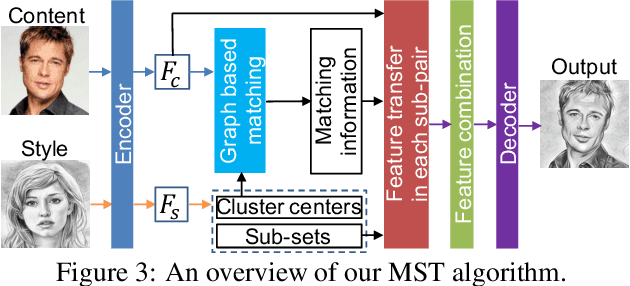

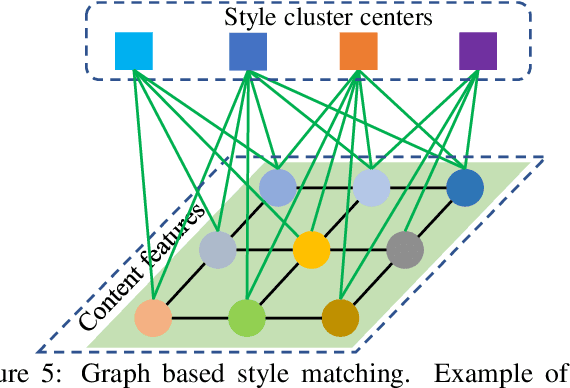
An assumption widely used in recent neural style transfer methods is that image styles can be described by global statics of deep features like Gram or covariance matrices. Alternative approaches have represented styles by decomposing them into local pixel or neural patches. Despite the recent progress, most existing methods treat the semantic patterns of style image uniformly, resulting unpleasing results on complex styles. In this paper, we introduce a more flexible and general universal style transfer technique: multimodal style transfer (MST). MST explicitly considers the matching of semantic patterns in content and style images. Specifically, the style image features are clustered into sub-style components, which are matched with local content features under a graph cut formulation. A reconstruction network is trained to transfer each sub-style and render the final stylized result. Extensive experiments demonstrate the superior effectiveness, robustness and flexibility of MST.
Creative Procedural-Knowledge Extraction From Web Design Tutorials
Apr 18, 2019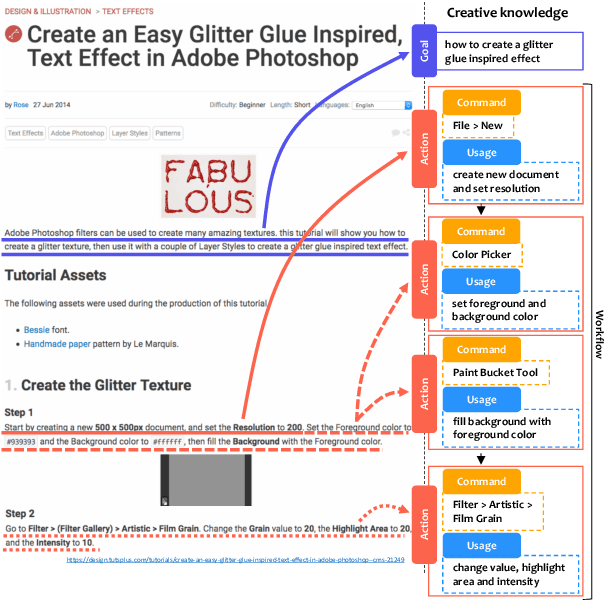

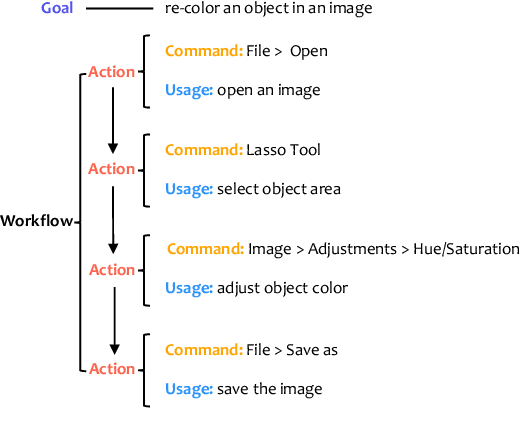
Complex design tasks often require performing diverse actions in a specific order. To (semi-)autonomously accomplish these tasks, applications need to understand and learn a wide range of design procedures, i.e., Creative Procedural-Knowledge (CPK). Prior knowledge base construction and mining have not typically addressed the creative fields, such as design and arts. In this paper, we formalize an ontology of CPK using five components: goal, workflow, action, command and usage; and extract components' values from online design tutorials. We scraped 19.6K tutorial-related webpages and built a web application for professional designers to identify and summarize CPK components. The annotated dataset consists of 819 unique commands, 47,491 actions, and 2,022 workflows and goals. Based on this dataset, we propose a general CPK extraction pipeline and demonstrate that existing text classification and sequence-to-sequence models are limited in identifying, predicting and summarizing complex operations described in heterogeneous styles. Through quantitative and qualitative error analysis, we discuss CPK extraction challenges that need to be addressed by future research.
PaintBot: A Reinforcement Learning Approach for Natural Media Painting
Apr 03, 2019

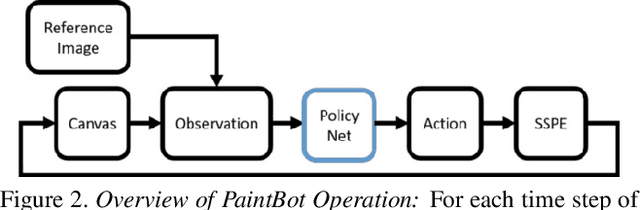
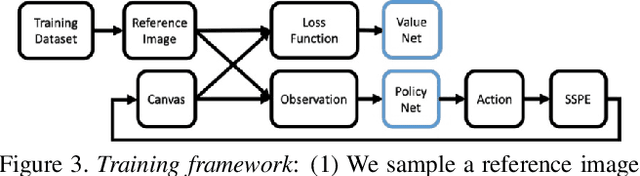
We propose a new automated digital painting framework, based on a painting agent trained through reinforcement learning. To synthesize an image, the agent selects a sequence of continuous-valued actions representing primitive painting strokes, which are accumulated on a digital canvas. Action selection is guided by a given reference image, which the agent attempts to replicate subject to the limitations of the action space and the agent's learned policy. The painting agent policy is determined using a variant of proximal policy optimization reinforcement learning. During training, our agent is presented with patches sampled from an ensemble of reference images. To accelerate training convergence, we adopt a curriculum learning strategy, whereby reference patches are sampled according to how challenging they are using the current policy. We experiment with differing loss functions, including pixel-wise and perceptual loss, which have consequent differing effects on the learned policy. We demonstrate that our painting agent can learn an effective policy with a high dimensional continuous action space comprising pen pressure, width, tilt, and color, for a variety of painting styles. Through a coarse-to-fine refinement process our agent can paint arbitrarily complex images in the desired style.
Dance Dance Generation: Motion Transfer for Internet Videos
Mar 30, 2019
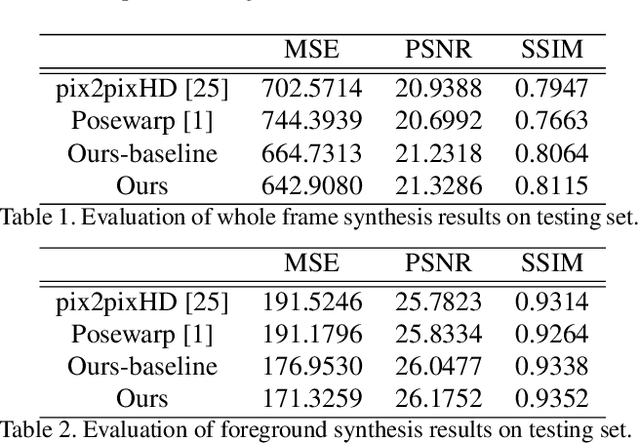

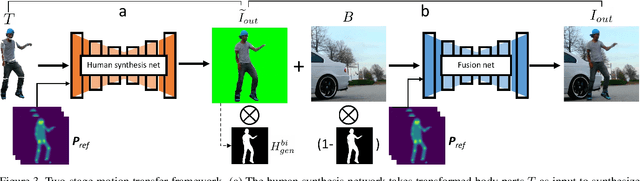
This work presents computational methods for transferring body movements from one person to another with videos collected in the wild. Specifically, we train a personalized model on a single video from the Internet which can generate videos of this target person driven by the motions of other people. Our model is built on two generative networks: a human (foreground) synthesis net which generates photo-realistic imagery of the target person in a novel pose, and a fusion net which combines the generated foreground with the scene (background), adding shadows or reflections as needed to enhance realism. We validate the the efficacy of our proposed models over baselines with qualitative and quantitative evaluations as well as a subjective test.
Im2Pencil: Controllable Pencil Illustration from Photographs
Mar 20, 2019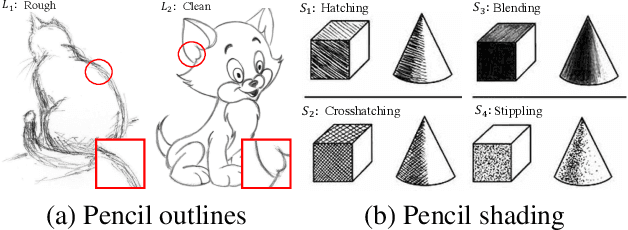


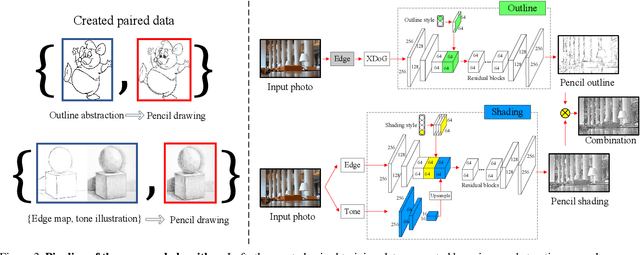
We propose a high-quality photo-to-pencil translation method with fine-grained control over the drawing style. This is a challenging task due to multiple stroke types (e.g., outline and shading), structural complexity of pencil shading (e.g., hatching), and the lack of aligned training data pairs. To address these challenges, we develop a two-branch model that learns separate filters for generating sketchy outlines and tonal shading from a collection of pencil drawings. We create training data pairs by extracting clean outlines and tonal illustrations from original pencil drawings using image filtering techniques, and we manually label the drawing styles. In addition, our model creates different pencil styles (e.g., line sketchiness and shading style) in a user-controllable manner. Experimental results on different types of pencil drawings show that the proposed algorithm performs favorably against existing methods in terms of quality, diversity and user evaluations.
Learning to Sketch with Deep Q Networks and Demonstrated Strokes
Oct 14, 2018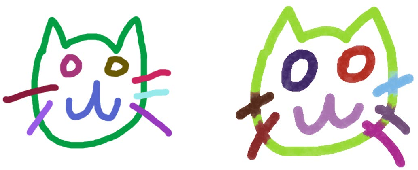


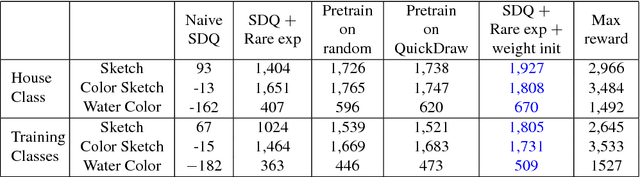
Doodling is a useful and common intelligent skill that people can learn and master. In this work, we propose a two-stage learning framework to teach a machine to doodle in a simulated painting environment via Stroke Demonstration and deep Q-learning (SDQ). The developed system, Doodle-SDQ, generates a sequence of pen actions to reproduce a reference drawing and mimics the behavior of human painters. In the first stage, it learns to draw simple strokes by imitating in supervised fashion from a set of strokeaction pairs collected from artist paintings. In the second stage, it is challenged to draw real and more complex doodles without ground truth actions; thus, it is trained with Qlearning. Our experiments confirm that (1) doodling can be learned without direct stepby- step action supervision and (2) pretraining with stroke demonstration via supervised learning is important to improve performance. We further show that Doodle-SDQ is effective at producing plausible drawings in different media types, including sketch and watercolor.
Flow-Grounded Spatial-Temporal Video Prediction from Still Images
Aug 26, 2018

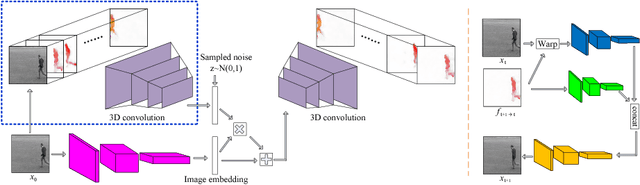

Existing video prediction methods mainly rely on observing multiple historical frames or focus on predicting the next one-frame. In this work, we study the problem of generating consecutive multiple future frames by observing one single still image only. We formulate the multi-frame prediction task as a multiple time step flow (multi-flow) prediction phase followed by a flow-to-frame synthesis phase. The multi-flow prediction is modeled in a variational probabilistic manner with spatial-temporal relationships learned through 3D convolutions. The flow-to-frame synthesis is modeled as a generative process in order to keep the predicted results lying closer to the manifold shape of real video sequence. Such a two-phase design prevents the model from directly looking at the high-dimensional pixel space of the frame sequence and is demonstrated to be more effective in predicting better and diverse results. Extensive experimental results on videos with different types of motion show that the proposed algorithm performs favorably against existing methods in terms of quality, diversity and human perceptual evaluation.