 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurg-3M: A Dataset and Foundation Model for Perception in Surgical Settings
Mar 25, 2025Advancements in computer-assisted surgical procedures heavily rely on accurate visual data interpretation from camera systems used during surgeries. Traditional open-access datasets focusing on surgical procedures are often limited by their small size, typically consisting of fewer than 100 videos with less than 100K images. To address these constraints, a new dataset called Surg-3M has been compiled using a novel aggregation pipeline that collects high-resolution videos from online sources. Featuring an extensive collection of over 4K surgical videos and more than 3 million high-quality images from multiple procedure types, Surg-3M offers a comprehensive resource surpassing existing alternatives in size and scope, including two novel tasks. To demonstrate the effectiveness of this dataset, we present SurgFM, a self-supervised foundation model pretrained on Surg-3M that achieves impressive results in downstream tasks such as surgical phase recognition, action recognition, and tool presence detection. Combining key components from ConvNeXt, DINO, and an innovative augmented distillation method, SurgFM exhibits exceptional performance compared to specialist architectures across various benchmarks. Our experimental results show that SurgFM outperforms state-of-the-art models in multiple downstream tasks, including significant gains in surgical phase recognition (+8.9pp, +4.7pp, and +3.9pp of Jaccard in AutoLaparo, M2CAI16, and Cholec80), action recognition (+3.1pp of mAP in CholecT50) and tool presence detection (+4.6pp of mAP in Cholec80). Moreover, even when using only half of the data, SurgFM outperforms state-of-the-art models in AutoLaparo and achieves state-of-the-art performance in Cholec80. Both Surg-3M and SurgFM have significant potential to accelerate progress towards developing autonomous robotic surgery systems.
RFMI: Estimating Mutual Information on Rectified Flow for Text-to-Image Alignment
Mar 18, 2025Rectified Flow (RF) models trained with a Flow matching framework have achieved state-of-the-art performance on Text-to-Image (T2I) conditional generation. Yet, multiple benchmarks show that synthetic images can still suffer from poor alignment with the prompt, i.e., images show wrong attribute binding, subject positioning, numeracy, etc. While the literature offers many methods to improve T2I alignment, they all consider only Diffusion Models, and require auxiliary datasets, scoring models, and linguistic analysis of the prompt. In this paper we aim to address these gaps. First, we introduce RFMI, a novel Mutual Information (MI) estimator for RF models that uses the pre-trained model itself for the MI estimation. Then, we investigate a self-supervised fine-tuning approach for T2I alignment based on RFMI that does not require auxiliary information other than the pre-trained model itself. Specifically, a fine-tuning set is constructed by selecting synthetic images generated from the pre-trained RF model and having high point-wise MI between images and prompts. Our experiments on MI estimation benchmarks demonstrate the validity of RFMI, and empirical fine-tuning on SD3.5-Medium confirms the effectiveness of RFMI for improving T2I alignment while maintaining image quality.
DPC: Dual-Prompt Collaboration for Tuning Vision-Language Models
Mar 17, 2025



The Base-New Trade-off (BNT) problem universally exists during the optimization of CLIP-based prompt tuning, where continuous fine-tuning on base (target) classes leads to a simultaneous decrease of generalization ability on new (unseen) classes. Existing approaches attempt to regulate the prompt tuning process to balance BNT by appending constraints. However, imposed on the same target prompt, these constraints fail to fully avert the mutual exclusivity between the optimization directions for base and new. As a novel solution to this challenge, we propose the plug-and-play Dual-Prompt Collaboration (DPC) framework, the first that decoupling the optimization processes of base and new tasks at the prompt level. Specifically, we clone a learnable parallel prompt based on the backbone prompt, and introduce a variable Weighting-Decoupling framework to independently control the optimization directions of dual prompts specific to base or new tasks, thus avoiding the conflict in generalization. Meanwhile, we propose a Dynamic Hard Negative Optimizer, utilizing dual prompts to construct a more challenging optimization task on base classes for enhancement. For interpretability, we prove the feature channel invariance of the prompt vector during the optimization process, providing theoretical support for the Weighting-Decoupling of DPC. Extensive experiments on multiple backbones demonstrate that DPC can significantly improve base performance without introducing any external knowledge beyond the base classes, while maintaining generalization to new classes. Code is available at: https://github.com/JREion/DPC.
Can LLMs Formally Reason as Abstract Interpreters for Program Analysis?
Mar 16, 2025LLMs have demonstrated impressive capabilities in code generation and comprehension, but their potential in being able to perform program analysis in a formal, automatic manner remains under-explored. To that end, we systematically investigate whether LLMs can reason about programs using a program analysis framework called abstract interpretation. We prompt LLMs to follow two different strategies, denoted as Compositional and Fixed Point Equation, to formally reason in the style of abstract interpretation, which has never been done before to the best of our knowledge. We validate our approach using state-of-the-art LLMs on 22 challenging benchmark programs from the Software Verification Competition (SV-COMP) 2019 dataset, widely used in program analysis. Our results show that our strategies are able to elicit abstract interpretation-based reasoning in the tested models, but LLMs are susceptible to logical errors, especially while interpreting complex program structures, as well as general hallucinations. This highlights key areas for improvement in the formal reasoning capabilities of LLMs.
FinTMMBench: Benchmarking Temporal-Aware Multi-Modal RAG in Finance
Mar 07, 2025



Finance decision-making often relies on in-depth data analysis across various data sources, including financial tables, news articles, stock prices, etc. In this work, we introduce FinTMMBench, the first comprehensive benchmark for evaluating temporal-aware multi-modal Retrieval-Augmented Generation (RAG) systems in finance. Built from heterologous data of NASDAQ 100 companies, FinTMMBench offers three significant advantages. 1) Multi-modal Corpus: It encompasses a hybrid of financial tables, news articles, daily stock prices, and visual technical charts as the corpus. 2) Temporal-aware Questions: Each question requires the retrieval and interpretation of its relevant data over a specific time period, including daily, weekly, monthly, quarterly, and annual periods. 3) Diverse Financial Analysis Tasks: The questions involve 10 different tasks, including information extraction, trend analysis, sentiment analysis and event detection, etc. We further propose a novel TMMHybridRAG method, which first leverages LLMs to convert data from other modalities (e.g., tabular, visual and time-series data) into textual format and then incorporates temporal information in each node when constructing graphs and dense indexes. Its effectiveness has been validated in extensive experiments, but notable gaps remain, highlighting the challenges presented by our FinTMMBench.
TPC: Cross-Temporal Prediction Connection for Vision-Language Model Hallucination Reduction
Mar 06, 2025Vision-language models (VLMs) have achieved remarkable advancements, capitalizing on the impressive capabilities of large language models (LLMs) across diverse tasks. Despite this, a critical challenge known as hallucination occurs when models overconfidently describe objects or attributes absent from the image, a problem exacerbated by the tendency of VLMs to rely on linguistic priors. This limitation reduces model reliability in high-stakes applications. In this work, we have observed the characteristic of logits' continuity consistency enhancement and introduced a straightforward and efficient method, Cross-Temporal Prediction Connection (TPC), designed to enhance the semantic consistency of logits by connecting them temporally across timesteps. TPC amplifies information flow and improves coherence, effectively reducing hallucination. Extensive experiments show that TPC surpasses existing representatives, delivering superior performance in both accuracy and efficiency while maintaining robustness in open-ended text generation tasks.
Advancing vision-language models in front-end development via data synthesis
Mar 03, 2025Modern front-end (FE) development, especially when leveraging the unique features of frameworks like React and Vue, presents distinctive challenges. These include managing modular architectures, ensuring synchronization between data and visual outputs for declarative rendering, and adapting reusable components to various scenarios. Such complexities make it particularly difficult for state-of-the-art large vision-language models (VLMs) to generate accurate and functional code directly from design images. To address these challenges, we propose a reflective agentic workflow that synthesizes high-quality image-text data to capture the diverse characteristics of FE development. This workflow automates the extraction of self-contained\footnote{A \textbf{self-contained} code snippet is one that encapsulates all necessary logic, styling, and dependencies, ensuring it functions independently without requiring external imports or context.} code snippets from real-world projects, renders the corresponding visual outputs, and generates detailed descriptions that link design elements to functional code. To further expand the scope and utility of the synthesis, we introduce three data synthesis strategies: Evolution-based synthesis, which enables scalable and diverse dataset expansion; Waterfall-Model-based synthesis, which generates logically coherent code derived from system requirements; and Additive Development synthesis, which iteratively increases the complexity of human-authored components. We build a large vision-language model, Flame, trained on the synthesized datasets and demonstrate its effectiveness in generating React code via the $\text{pass}@k$ metric. Our results suggest that a code VLM trained to interpret images before code generation may achieve better performance.
Can Large Language Models Unveil the Mysteries? An Exploration of Their Ability to Unlock Information in Complex Scenarios
Feb 27, 2025Combining multiple perceptual inputs and performing combinatorial reasoning in complex scenarios is a sophisticated cognitive function in humans. With advancements in multi-modal large language models, recent benchmarks tend to evaluate visual understanding across multiple images. However, they often overlook the necessity of combinatorial reasoning across multiple perceptual information. To explore the ability of advanced models to integrate multiple perceptual inputs for combinatorial reasoning in complex scenarios, we introduce two benchmarks: Clue-Visual Question Answering (CVQA), with three task types to assess visual comprehension and synthesis, and Clue of Password-Visual Question Answering (CPVQA), with two task types focused on accurate interpretation and application of visual data. For our benchmarks, we present three plug-and-play approaches: utilizing model input for reasoning, enhancing reasoning through minimum margin decoding with randomness generation, and retrieving semantically relevant visual information for effective data integration. The combined results reveal current models' poor performance on combinatorial reasoning benchmarks, even the state-of-the-art (SOTA) closed-source model achieves only 33.04% accuracy on CVQA, and drops to 7.38% on CPVQA. Notably, our approach improves the performance of models on combinatorial reasoning, with a 22.17% boost on CVQA and 9.40% on CPVQA over the SOTA closed-source model, demonstrating its effectiveness in enhancing combinatorial reasoning with multiple perceptual inputs in complex scenarios. The code will be publicly available.
X-Dancer: Expressive Music to Human Dance Video Generation
Feb 24, 2025We present X-Dancer, a novel zero-shot music-driven image animation pipeline that creates diverse and long-range lifelike human dance videos from a single static image. As its core, we introduce a unified transformer-diffusion framework, featuring an autoregressive transformer model that synthesize extended and music-synchronized token sequences for 2D body, head and hands poses, which then guide a diffusion model to produce coherent and realistic dance video frames. Unlike traditional methods that primarily generate human motion in 3D, X-Dancer addresses data limitations and enhances scalability by modeling a wide spectrum of 2D dance motions, capturing their nuanced alignment with musical beats through readily available monocular videos. To achieve this, we first build a spatially compositional token representation from 2D human pose labels associated with keypoint confidences, encoding both large articulated body movements (e.g., upper and lower body) and fine-grained motions (e.g., head and hands). We then design a music-to-motion transformer model that autoregressively generates music-aligned dance pose token sequences, incorporating global attention to both musical style and prior motion context. Finally we leverage a diffusion backbone to animate the reference image with these synthesized pose tokens through AdaIN, forming a fully differentiable end-to-end framework. Experimental results demonstrate that X-Dancer is able to produce both diverse and characterized dance videos, substantially outperforming state-of-the-art methods in term of diversity, expressiveness and realism. Code and model will be available for research purposes.
Event Stream-based Visual Object Tracking: HDETrack V2 and A High-Definition Benchmark
Feb 08, 2025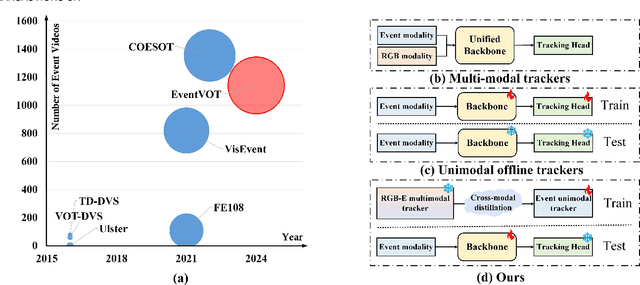

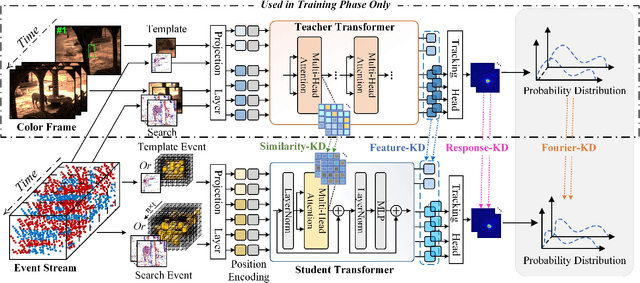

We then introduce a novel hierarchical knowledge distillation strategy that incorporates the similarity matrix, feature representation, and response map-based distillation to guide the learning of the student Transformer network. We also enhance the model's ability to capture temporal dependencies by applying the temporal Fourier transform to establish temporal relationships between video frames. We adapt the network model to specific target objects during testing via a newly proposed test-time tuning strategy to achieve high performance and flexibility in target tracking. Recognizing the limitations of existing event-based tracking datasets, which are predominantly low-resolution, we propose EventVOT, the first large-scale high-resolution event-based tracking dataset. It comprises 1141 videos spanning diverse categories such as pedestrians, vehicles, UAVs, ping pong, etc. Extensive experiments on both low-resolution (FE240hz, VisEvent, FELT), and our newly proposed high-resolution EventVOT dataset fully validated the effectiveness of our proposed method. Both the benchmark dataset and source code have been released on https://github.com/Event-AHU/EventVOT_Benchmark