 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-grained Attention in Hierarchical Transformers for Tabular Time-series
Jun 21, 2024



Tabular data is ubiquitous in many real-life systems. In particular, time-dependent tabular data, where rows are chronologically related, is typically used for recording historical events, e.g., financial transactions, healthcare records, or stock history. Recently, hierarchical variants of the attention mechanism of transformer architectures have been used to model tabular time-series data. At first, rows (or columns) are encoded separately by computing attention between their fields. Subsequently, encoded rows (or columns) are attended to one another to model the entire tabular time-series. While efficient, this approach constrains the attention granularity and limits its ability to learn patterns at the field-level across separate rows, or columns. We take a first step to address this gap by proposing Fieldy, a fine-grained hierarchical model that contextualizes fields at both the row and column levels. We compare our proposal against state of the art models on regression and classification tasks using public tabular time-series datasets. Our results show that combining row-wise and column-wise attention improves performance without increasing model size. Code and data are available at https://github.com/raphaaal/fieldy.
Information Theoretic Text-to-Image Alignment
May 31, 2024Diffusion models for Text-to-Image (T2I) conditional generation have seen tremendous success recently. Despite their success, accurately capturing user intentions with these models still requires a laborious trial and error process. This challenge is commonly identified as a model alignment problem, an issue that has attracted considerable attention by the research community. Instead of relying on fine-grained linguistic analyses of prompts, human annotation, or auxiliary vision-language models to steer image generation, in this work we present a novel method that relies on an information-theoretic alignment measure. In a nutshell, our method uses self-supervised fine-tuning and relies on point-wise mutual information between prompts and images to define a synthetic training set to induce model alignment. Our comparative analysis shows that our method is on-par or superior to the state-of-the-art, yet requires nothing but a pre-trained denoising network to estimate MI and a lightweight fine-tuning strategy.
Data Augmentation for Traffic Classification
Jan 23, 2024



Data Augmentation (DA) -- enriching training data by adding synthetic samples -- is a technique widely adopted in Computer Vision (CV) and Natural Language Processing (NLP) tasks to improve models performance. Yet, DA has struggled to gain traction in networking contexts, particularly in Traffic Classification (TC) tasks. In this work, we fulfill this gap by benchmarking 18 augmentation functions applied to 3 TC datasets using packet time series as input representation and considering a variety of training conditions. Our results show that (i) DA can reap benefits previously unexplored, (ii) augmentations acting on time series sequence order and masking are better suited for TC than amplitude augmentations and (iii) basic models latent space analysis can help understanding the positive/negative effects of augmentations on classification performance.
Toward Generative Data Augmentation for Traffic Classification
Oct 21, 2023
Data Augmentation (DA)-augmenting training data with synthetic samples-is wildly adopted in Computer Vision (CV) to improve models performance. Conversely, DA has not been yet popularized in networking use cases, including Traffic Classification (TC). In this work, we present a preliminary study of 14 hand-crafted DAs applied on the MIRAGE19 dataset. Our results (i) show that DA can reap benefits previously unexplored in TC and (ii) foster a research agenda on the use of generative models to automate DA design.
"It's a Match!" -- A Benchmark of Task Affinity Scores for Joint Learning
Jan 07, 2023



While the promises of Multi-Task Learning (MTL) are attractive, characterizing the conditions of its success is still an open problem in Deep Learning. Some tasks may benefit from being learned together while others may be detrimental to one another. From a task perspective, grouping cooperative tasks while separating competing tasks is paramount to reap the benefits of MTL, i.e., reducing training and inference costs. Therefore, estimating task affinity for joint learning is a key endeavor. Recent work suggests that the training conditions themselves have a significant impact on the outcomes of MTL. Yet, the literature is lacking of a benchmark to assess the effectiveness of tasks affinity estimation techniques and their relation with actual MTL performance. In this paper, we take a first step in recovering this gap by (i) defining a set of affinity scores by both revisiting contributions from previous literature as well presenting new ones and (ii) benchmarking them on the Taskonomy dataset. Our empirical campaign reveals how, even in a small-scale scenario, task affinity scoring does not correlate well with actual MTL performance. Yet, some metrics can be more indicative than others.
Accelerating Deep Learning Classification with Error-controlled Approximate-key Caching
Jan 11, 2022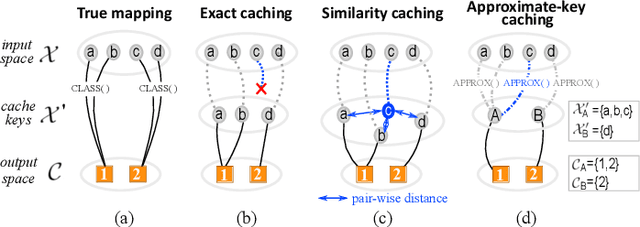
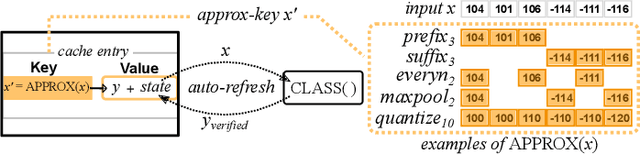


While Deep Learning (DL) technologies are a promising tool to solve networking problems that map to classification tasks, their computational complexity is still too high with respect to real-time traffic measurements requirements. To reduce the DL inference cost, we propose a novel caching paradigm, that we named approximate-key caching, which returns approximate results for lookups of selected input based on cached DL inference results. While approximate cache hits alleviate DL inference workload and increase the system throughput, they however introduce an approximation error. As such, we couple approximate-key caching with an error-correction principled algorithm, that we named auto-refresh. We analytically model our caching system performance for classic LRU and ideal caches, we perform a trace-driven evaluation of the expected performance, and we compare the benefits of our proposed approach with the state-of-the-art similarity caching -- testifying the practical interest of our proposal.
FENXI: Deep-learning Traffic Analytics at the Edge
May 25, 2021



Live traffic analysis at the first aggregation point in the ISP network enables the implementation of complex traffic engineering policies but is limited by the scarce processing capabilities, especially for Deep Learning (DL) based analytics. The introduction of specialized hardware accelerators i.e., Tensor Processing Unit (TPU), offers the opportunity to enhance the processing capabilities of network devices at the edge. Yet, to date, no packet processing pipeline is capable of offering DL-based analysis capabilities in the data-plane, without interfering with network operations. In this paper, we present FENXI, a system to run complex analytics by leveraging TPU. The design of FENXI decouples forwarding operations and traffic analytics which operates at different granularities i.e., packet and flow levels. We conceive two independent modules that asynchronously communicate to exchange network data and analytics results, and design data structures to extract flow level statistics without impacting per-packet processing. We prototyped and evaluated FENXI on general-purpose servers considering both adversarial and realistic network conditions. Our analysis shows that FENXI can sustain 100 Gbps line rate traffic processing requiring only limited resources, while also dynamically adapting to variable network conditions.