 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEAttack: Downstream-agnostic Vision Encoder Attack against Large Vision Language Models
May 23, 2025Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in multimodal understanding and generation, yet their vulnerability to adversarial attacks raises significant robustness concerns. While existing effective attacks always focus on task-specific white-box settings, these approaches are limited in the context of LVLMs, which are designed for diverse downstream tasks and require expensive full-model gradient computations. Motivated by the pivotal role and wide adoption of the vision encoder in LVLMs, we propose a simple yet effective Vision Encoder Attack (VEAttack), which targets the vision encoder of LVLMs only. Specifically, we propose to generate adversarial examples by minimizing the cosine similarity between the clean and perturbed visual features, without accessing the following large language models, task information, and labels. It significantly reduces the computational overhead while eliminating the task and label dependence of traditional white-box attacks in LVLMs. To make this simple attack effective, we propose to perturb images by optimizing image tokens instead of the classification token. We provide both empirical and theoretical evidence that VEAttack can easily generalize to various tasks. VEAttack has achieved a performance degradation of 94.5% on image caption task and 75.7% on visual question answering task. We also reveal some key observations to provide insights into LVLM attack/defense: 1) hidden layer variations of LLM, 2) token attention differential, 3) M\"obius band in transfer attack, 4) low sensitivity to attack steps. The code is available at https://github.com/hfmei/VEAttack-LVLM
Circle-RoPE: Cone-like Decoupled Rotary Positional Embedding for Large Vision-Language Models
May 22, 2025Rotary Position Embedding (RoPE) is a widely adopted technique for encoding relative positional information in large language models (LLMs). However, when extended to large vision-language models (LVLMs), its variants introduce unintended cross-modal positional biases. Specifically, they enforce relative positional dependencies between text token indices and image tokens, causing spurious alignments. This issue arises because image tokens representing the same content but located at different spatial positions are assigned distinct positional biases, leading to inconsistent cross-modal associations. To address this, we propose Per-Token Distance (PTD) - a simple yet effective metric for quantifying the independence of positional encodings across modalities. Informed by this analysis, we introduce Circle-RoPE, a novel encoding scheme that maps image token indices onto a circular trajectory orthogonal to the linear path of text token indices, forming a cone-like structure. This configuration ensures that each text token maintains an equal distance to all image tokens, reducing artificial cross-modal biases while preserving intra-image spatial information. To further enhance performance, we propose a staggered layer strategy that applies different RoPE variants across layers. This design leverages the complementary strengths of each RoPE variant, thereby enhancing the model's overall performance. Our experimental results demonstrate that our method effectively preserves spatial information from images while reducing relative positional bias, offering a more robust and flexible positional encoding framework for LVLMs. The code is available at [https://github.com/lose4578/CircleRoPE](https://github.com/lose4578/CircleRoPE).
Enhancing Privacy-Utility Trade-offs to Mitigate Memorization in Diffusion Models
Apr 25, 2025



Text-to-image diffusion models have demonstrated remarkable capabilities in creating images highly aligned with user prompts, yet their proclivity for memorizing training set images has sparked concerns about the originality of the generated images and privacy issues, potentially leading to legal complications for both model owners and users, particularly when the memorized images contain proprietary content. Although methods to mitigate these issues have been suggested, enhancing privacy often results in a significant decrease in the utility of the outputs, as indicated by text-alignment scores. To bridge the research gap, we introduce a novel method, PRSS, which refines the classifier-free guidance approach in diffusion models by integrating prompt re-anchoring (PR) to improve privacy and incorporating semantic prompt search (SS) to enhance utility. Extensive experiments across various privacy levels demonstrate that our approach consistently improves the privacy-utility trade-off, establishing a new state-of-the-art.
TarDiff: Target-Oriented Diffusion Guidance for Synthetic Electronic Health Record Time Series Generation
Apr 24, 2025Synthetic Electronic Health Record (EHR) time-series generation is crucial for advancing clinical machine learning models, as it helps address data scarcity by providing more training data. However, most existing approaches focus primarily on replicating statistical distributions and temporal dependencies of real-world data. We argue that fidelity to observed data alone does not guarantee better model performance, as common patterns may dominate, limiting the representation of rare but important conditions. This highlights the need for generate synthetic samples to improve performance of specific clinical models to fulfill their target outcomes. To address this, we propose TarDiff, a novel target-oriented diffusion framework that integrates task-specific influence guidance into the synthetic data generation process. Unlike conventional approaches that mimic training data distributions, TarDiff optimizes synthetic samples by quantifying their expected contribution to improving downstream model performance through influence functions. Specifically, we measure the reduction in task-specific loss induced by synthetic samples and embed this influence gradient into the reverse diffusion process, thereby steering the generation towards utility-optimized data. Evaluated on six publicly available EHR datasets, TarDiff achieves state-of-the-art performance, outperforming existing methods by up to 20.4% in AUPRC and 18.4% in AUROC. Our results demonstrate that TarDiff not only preserves temporal fidelity but also enhances downstream model performance, offering a robust solution to data scarcity and class imbalance in healthcare analytics.
Functional Abstraction of Knowledge Recall in Large Language Models
Apr 20, 2025Pre-trained transformer large language models (LLMs) demonstrate strong knowledge recall capabilities. This paper investigates the knowledge recall mechanism in LLMs by abstracting it into a functional structure. We propose that during knowledge recall, the model's hidden activation space implicitly entails a function execution process where specific activation vectors align with functional components (Input argument, Function body, and Return values). Specifically, activation vectors of relation-related tokens define a mapping function from subjects to objects, with subject-related token activations serving as input arguments and object-related token activations as return values. For experimental verification, we first design a patching-based knowledge-scoring algorithm to identify knowledge-aware activation vectors as independent functional components. Then, we conduct counter-knowledge testing to examine the independent functional effects of each component on knowledge recall outcomes. From this functional perspective, we improve the contextual knowledge editing approach augmented by activation patching. By rewriting incoherent activations in context, we enable improved short-term memory retention for new knowledge prompting.
Beyond One-Hot Labels: Semantic Mixing for Model Calibration
Apr 18, 2025



Model calibration seeks to ensure that models produce confidence scores that accurately reflect the true likelihood of their predictions being correct. However, existing calibration approaches are fundamentally tied to datasets of one-hot labels implicitly assuming full certainty in all the annotations. Such datasets are effective for classification but provides insufficient knowledge of uncertainty for model calibration, necessitating the curation of datasets with numerically rich ground-truth confidence values. However, due to the scarcity of uncertain visual examples, such samples are not easily available as real datasets. In this paper, we introduce calibration-aware data augmentation to create synthetic datasets of diverse samples and their ground-truth uncertainty. Specifically, we present Calibration-aware Semantic Mixing (CSM), a novel framework that generates training samples with mixed class characteristics and annotates them with distinct confidence scores via diffusion models. Based on this framework, we propose calibrated reannotation to tackle the misalignment between the annotated confidence score and the mixing ratio during the diffusion reverse process. Besides, we explore the loss functions that better fit the new data representation paradigm. Experimental results demonstrate that CSM achieves superior calibration compared to the state-of-the-art calibration approaches. Code is available at github.com/E-Galois/CSM.
ThoughtProbe: Classifier-Guided Thought Space Exploration Leveraging LLM Intrinsic Reasoning
Apr 09, 2025



Pre-trained large language models (LLMs) have been demonstrated to possess intrinsic reasoning capabilities that can emerge naturally when expanding the response space. However, the neural representation mechanisms underlying these intrinsic capabilities and approaches for their optimal utilization remain inadequately understood. In this work, we make the key discovery that a simple linear classifier can effectively detect intrinsic reasoning capabilities in LLMs' activation space, particularly within specific representation types and network layers. Based on this finding, we propose a classifier-guided search framework that strategically explore a tree-structured response space. In each node expansion, the classifier serves as a scoring and ranking mechanism that efficiently allocates computational resources by identifying and prioritizing more thoughtful reasoning directions for continuation. After completing the tree expansion, we collect answers from all branches to form a candidate answer pool. We propose a branch-aggregation selection method that marginalizes over all supporting branches by aggregating their thoughtfulness scores, thereby identifying the optimal answer from the pool. Experimental results show that our framework's comprehensive exploration not only covers valid reasoning chains but also effectively identifies them, achieving significant improvements across multiple arithmetic reasoning benchmarks.
Marine Saliency Segmenter: Object-Focused Conditional Diffusion with Region-Level Semantic Knowledge Distillation
Apr 03, 2025Marine Saliency Segmentation (MSS) plays a pivotal role in various vision-based marine exploration tasks. However, existing marine segmentation techniques face the dilemma of object mislocalization and imprecise boundaries due to the complex underwater environment. Meanwhile, despite the impressive performance of diffusion models in visual segmentation, there remains potential to further leverage contextual semantics to enhance feature learning of region-level salient objects, thereby improving segmentation outcomes. Building on this insight, we propose DiffMSS, a novel marine saliency segmenter based on the diffusion model, which utilizes semantic knowledge distillation to guide the segmentation of marine salient objects. Specifically, we design a region-word similarity matching mechanism to identify salient terms at the word level from the text descriptions. These high-level semantic features guide the conditional feature learning network in generating salient and accurate diffusion conditions with semantic knowledge distillation. To further refine the segmentation of fine-grained structures in unique marine organisms, we develop the dedicated consensus deterministic sampling to suppress overconfident missegmentations. Comprehensive experiments demonstrate the superior performance of DiffMSS over state-of-the-art methods in both quantitative and qualitative evaluations.
Lumina-Image 2.0: A Unified and Efficient Image Generative Framework
Mar 27, 2025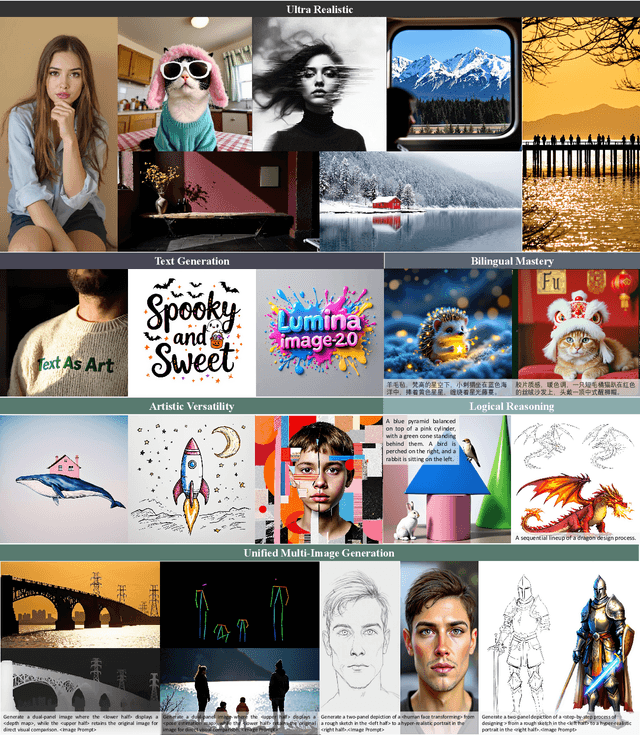
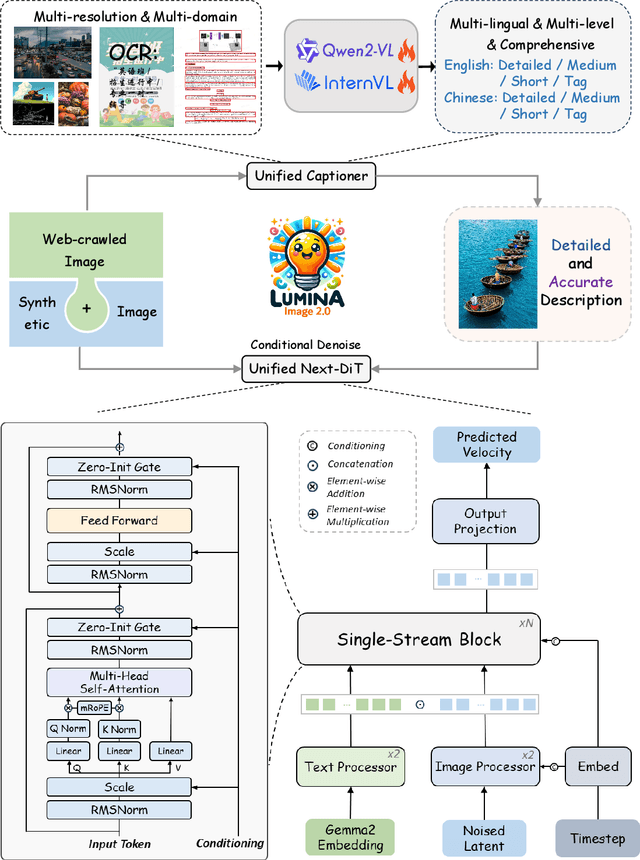

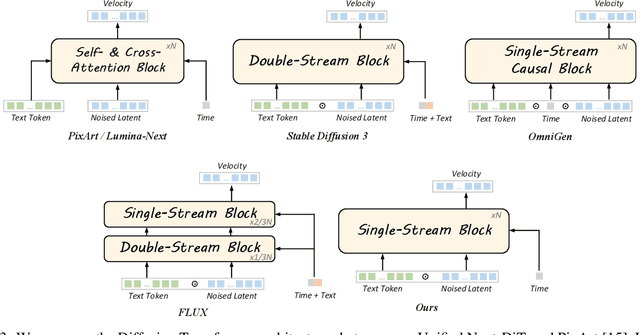
We introduce Lumina-Image 2.0, an advanced text-to-image generation framework that achieves significant progress compared to previous work, Lumina-Next. Lumina-Image 2.0 is built upon two key principles: (1) Unification - it adopts a unified architecture (Unified Next-DiT) that treats text and image tokens as a joint sequence, enabling natural cross-modal interactions and allowing seamless task expansion. Besides, since high-quality captioners can provide semantically well-aligned text-image training pairs, we introduce a unified captioning system, Unified Captioner (UniCap), specifically designed for T2I generation tasks. UniCap excels at generating comprehensive and accurate captions, accelerating convergence and enhancing prompt adherence. (2) Efficiency - to improve the efficiency of our proposed model, we develop multi-stage progressive training strategies and introduce inference acceleration techniques without compromising image quality. Extensive evaluations on academic benchmarks and public text-to-image arenas show that Lumina-Image 2.0 delivers strong performances even with only 2.6B parameters, highlighting its scalability and design efficiency. We have released our training details, code, and models at https://github.com/Alpha-VLLM/Lumina-Image-2.0.
Silent Hazards of Token Reduction in Vision-Language Models: The Hidden Impact on Consistency
Mar 11, 2025Vision language models (VLMs) have excelled in visual reasoning but often incur high computational costs. One key reason is the redundancy of visual tokens. Although recent token reduction methods claim to achieve minimal performance loss, our extensive experiments reveal that token reduction can substantially alter a model's output distribution, leading to changes in prediction patterns that standard metrics such as accuracy loss do not fully capture. Such inconsistencies are especially concerning for practical applications where system stability is critical. To investigate this phenomenon, we analyze how token reduction influences the energy distribution of a VLM's internal representations using a lower-rank approximation via Singular Value Decomposition (SVD). Our results show that changes in the Inverse Participation Ratio of the singular value spectrum are strongly correlated with the model's consistency after token reduction. Based on these insights, we propose LoFi--a training-free visual token reduction method that utilizes the leverage score from SVD for token pruning. Experimental evaluations demonstrate that LoFi not only reduces computational costs with minimal performance degradation but also significantly outperforms state-of-the-art methods in terms of output consistency.