 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-800: An 800 Hz Data Glove for Precise Hand Gesture Tracking
Mar 27, 2026Human dexterity relies on rapid, sub-second motor adjustments, yet capturing these high-frequency dynamics remains an enduring challenge in biomechanics and robotics. Existing motion capture paradigms are compromised by a trade-off between temporal resolution and visual occlusion, failing to record the fine-grained hand motion of fast, contact-rich manipulation. Here we introduce T-800, a high-bandwidth data glove system that achieves synchronized, full-hand motion tracking at 800 Hz. By integrating a novel broadcast-based synchronization mechanism with a mechanical stress isolation architecture, our system maintains sub-frame temporal alignment across 18 distributed inertial measurement units (IMUs) during extended, vigorous movements. We demonstrate that T-800 recovers fine-grained manipulation details previously lost to temporal undersampling. Our analysis reveals that human dexterity exhibits significantly high-frequency motion energy (>100 Hz) that was fundamentally inaccessible due to the Nyquist sampling limit imposed by previous hardware constraints. To validate the system's utility for robotic manipulation, we implement a kinematic retargeting algorithm that maps T-800's high-fidelity human gestures onto dexterous robotic hand models. This demonstrates that the high-frequency motion data can be accurately translated while respecting the kinematic constraints of robotic hands, providing the rich behavioral data necessary for training robust control policies in the future.
Confidence Calibration under Ambiguous Ground Truth
Mar 24, 2026Confidence calibration assumes a unique ground-truth label per input, yet this assumption fails wherever annotators genuinely disagree. Post-hoc calibrators fitted on majority-voted labels, the standard single-label targets used in practice, can appear well-calibrated under conventional evaluation yet remain substantially miscalibrated against the underlying annotator distribution. We show that this failure is structural: under simplifying assumptions, Temperature Scaling is biased toward temperatures that underestimate annotator uncertainty, with true-label miscalibration increasing monotonically with annotation entropy. To address this, we develop a family of ambiguity-aware post-hoc calibrators that optimise proper scoring rules against the full label distribution and require no model retraining. Our methods span progressively weaker annotation requirements: Dirichlet-Soft leverages the full annotator distribution and achieves the best overall calibration quality across settings; Monte Carlo Temperature Scaling with a single annotation per example (MCTS S=1) matches full-distribution calibration across all benchmarks, demonstrating that pre-aggregated label distributions are unnecessary; and Label-Smooth Temperature Scaling (LS-TS) operates with voted labels alone by constructing data-driven pseudo-soft targets from the model's own confidence. Experiments on four benchmarks with real multi-annotator distributions (CIFAR-10H, ChaosNLI) and clinically-informed synthetic annotations (ISIC~2019, DermaMNIST) show that Dirichlet-Soft reduces true-label ECE by 55-87% relative to Temperature Scaling, while LS-TS reduces ECE by 9-77% without any annotator data.
GenPO: Generative Diffusion Models Meet On-Policy Reinforcement Learning
May 24, 2025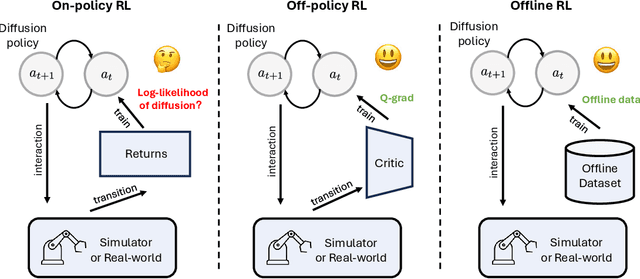

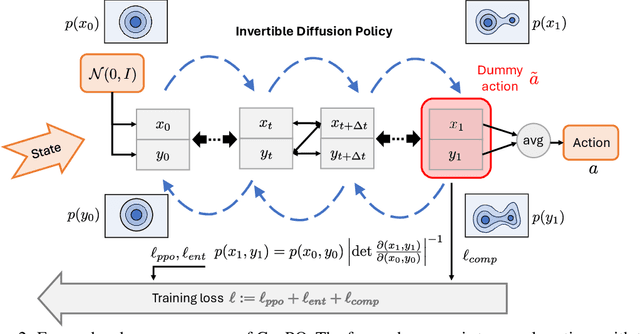
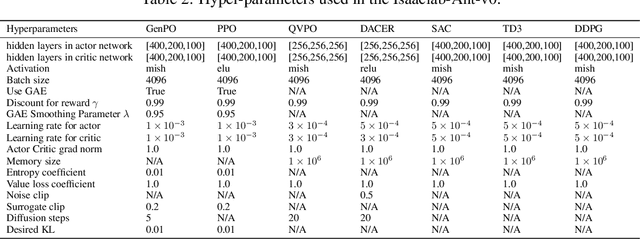
Recent advances in reinforcement learning (RL) have demonstrated the powerful exploration capabilities and multimodality of generative diffusion-based policies. While substantial progress has been made in offline RL and off-policy RL settings, integrating diffusion policies into on-policy frameworks like PPO remains underexplored. This gap is particularly significant given the widespread use of large-scale parallel GPU-accelerated simulators, such as IsaacLab, which are optimized for on-policy RL algorithms and enable rapid training of complex robotic tasks. A key challenge lies in computing state-action log-likelihoods under diffusion policies, which is straightforward for Gaussian policies but intractable for flow-based models due to irreversible forward-reverse processes and discretization errors (e.g., Euler-Maruyama approximations). To bridge this gap, we propose GenPO, a generative policy optimization framework that leverages exact diffusion inversion to construct invertible action mappings. GenPO introduces a novel doubled dummy action mechanism that enables invertibility via alternating updates, resolving log-likelihood computation barriers. Furthermore, we also use the action log-likelihood for unbiased entropy and KL divergence estimation, enabling KL-adaptive learning rates and entropy regularization in on-policy updates. Extensive experiments on eight IsaacLab benchmarks, including legged locomotion (Ant, Humanoid, Anymal-D, Unitree H1, Go2), dexterous manipulation (Shadow Hand), aerial control (Quadcopter), and robotic arm tasks (Franka), demonstrate GenPO's superiority over existing RL baselines. Notably, GenPO is the first method to successfully integrate diffusion policies into on-policy RL, unlocking their potential for large-scale parallelized training and real-world robotic deployment.
Beyond One-Hot Labels: Semantic Mixing for Model Calibration
Apr 18, 2025



Model calibration seeks to ensure that models produce confidence scores that accurately reflect the true likelihood of their predictions being correct. However, existing calibration approaches are fundamentally tied to datasets of one-hot labels implicitly assuming full certainty in all the annotations. Such datasets are effective for classification but provides insufficient knowledge of uncertainty for model calibration, necessitating the curation of datasets with numerically rich ground-truth confidence values. However, due to the scarcity of uncertain visual examples, such samples are not easily available as real datasets. In this paper, we introduce calibration-aware data augmentation to create synthetic datasets of diverse samples and their ground-truth uncertainty. Specifically, we present Calibration-aware Semantic Mixing (CSM), a novel framework that generates training samples with mixed class characteristics and annotates them with distinct confidence scores via diffusion models. Based on this framework, we propose calibrated reannotation to tackle the misalignment between the annotated confidence score and the mixing ratio during the diffusion reverse process. Besides, we explore the loss functions that better fit the new data representation paradigm. Experimental results demonstrate that CSM achieves superior calibration compared to the state-of-the-art calibration approaches. Code is available at github.com/E-Galois/CSM.
SeqAfford: Sequential 3D Affordance Reasoning via Multimodal Large Language Model
Dec 02, 2024



3D affordance segmentation aims to link human instructions to touchable regions of 3D objects for embodied manipulations. Existing efforts typically adhere to single-object, single-affordance paradigms, where each affordance type or explicit instruction strictly corresponds to a specific affordance region and are unable to handle long-horizon tasks. Such a paradigm cannot actively reason about complex user intentions that often imply sequential affordances. In this paper, we introduce the Sequential 3D Affordance Reasoning task, which extends the traditional paradigm by reasoning from cumbersome user intentions and then decomposing them into a series of segmentation maps. Toward this, we construct the first instruction-based affordance segmentation benchmark that includes reasoning over both single and sequential affordances, comprising 180K instruction-point cloud pairs. Based on the benchmark, we propose our model, SeqAfford, to unlock the 3D multi-modal large language model with additional affordance segmentation abilities, which ensures reasoning with world knowledge and fine-grained affordance grounding in a cohesive framework. We further introduce a multi-granular language-point integration module to endow 3D dense prediction. Extensive experimental evaluations show that our model excels over well-established methods and exhibits open-world generalization with sequential reasoning abilities.
SHREC'22 Track: Sketch-Based 3D Shape Retrieval in the Wild
Jul 11, 2022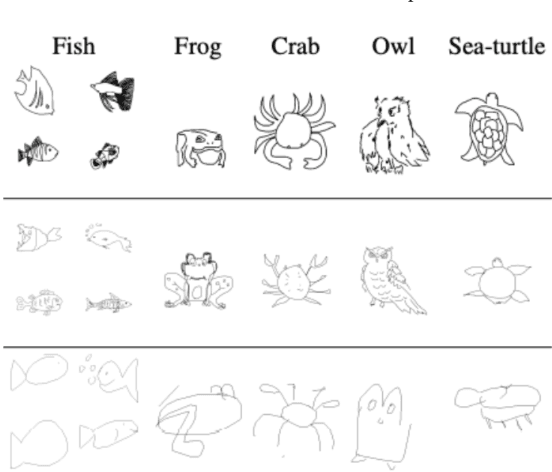
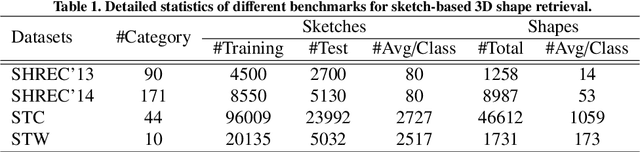
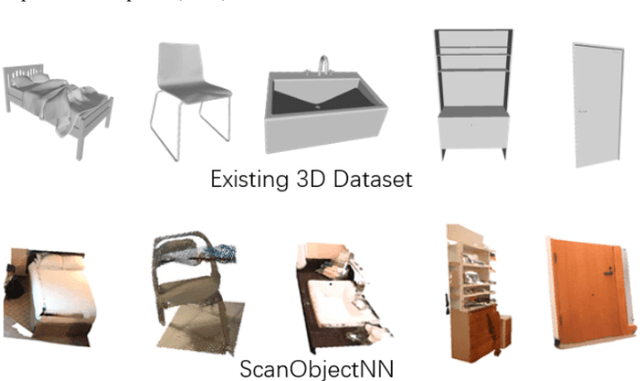
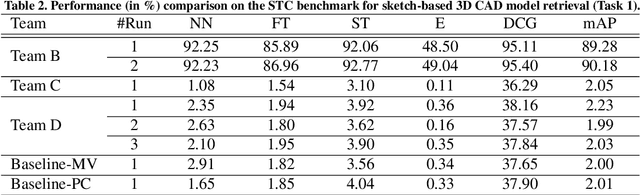
Sketch-based 3D shape retrieval (SBSR) is an important yet challenging task, which has drawn more and more attention in recent years. Existing approaches address the problem in a restricted setting, without appropriately simulating real application scenarios. To mimic the realistic setting, in this track, we adopt large-scale sketches drawn by amateurs of different levels of drawing skills, as well as a variety of 3D shapes including not only CAD models but also models scanned from real objects. We define two SBSR tasks and construct two benchmarks consisting of more than 46,000 CAD models, 1,700 realistic models, and 145,000 sketches in total. Four teams participated in this track and submitted 15 runs for the two tasks, evaluated by 7 commonly-adopted metrics. We hope that, the benchmarks, the comparative results, and the open-sourced evaluation code will foster future research in this direction among the 3D object retrieval community.