 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming External Knowledge into Triplets for Enhanced Retrieval in RAG of LLMs
Apr 14, 2026Retrieval-Augmented Generation (RAG) mitigates hallucination in large language models (LLMs) by incorporating external knowledge during generation. However, the effectiveness of RAG depends not only on the design of the retriever and the capacity of the underlying model, but also on how retrieved evidence is structured and aligned with the query. Existing RAG approaches typically retrieve and concatenate unstructured text fragments as context, which often introduces redundant or weakly relevant information. This practice leads to excessive context accumulation, reduced semantic alignment, and fragmented reasoning chains, thereby degrading generation quality while increasing token consumption. To address these challenges, we propose Tri-RAG, a structured triplet-based retrieval framework that improves retrieval efficiency through reasoning-aligned context construction. Tri-RAG automatically transforms external knowledge from natural language into standardized structured triplets consisting of Condition, Proof, and Conclusion, explicitly capturing logical relations among knowledge fragments using lightweight prompt-based adaptation with frozen model parameters. Building on this representation, the triplet head Condition is treated as an explicit semantic anchor for retrieval and matching, enabling precise identification of query-relevant knowledge units without directly concatenating lengthy raw texts. As a result, Tri-RAG achieves a favorable balance between retrieval accuracy and context token efficiency. Experimental results across multiple benchmark datasets demonstrate that Tri-RAG significantly improves retrieval quality and reasoning efficiency, while producing more stable generation behavior and more efficient resource utilization in complex reasoning scenarios.
Exploring Accurate and Transparent Domain Adaptation in Predictive Healthcare via Concept-Grounded Orthogonal Inference
Feb 13, 2026Deep learning models for clinical event prediction on electronic health records (EHR) often suffer performance degradation when deployed under different data distributions. While domain adaptation (DA) methods can mitigate such shifts, its "black-box" nature prevents widespread adoption in clinical practice where transparency is essential for trust and safety. We propose ExtraCare to decompose patient representations into invariant and covariant components. By supervising these two components and enforcing their orthogonality during training, our model preserves label information while exposing domain-specific variation at the same time for more accurate predictions than most feature alignment models. More importantly, it offers human-understandable explanations by mapping sparse latent dimensions to medical concepts and quantifying their contributions via targeted ablations. ExtraCare is evaluated on two real-world EHR datasets across multiple domain partition settings, demonstrating superior performance along with enhanced transparency, as evidenced by its accurate predictions and explanations from extensive case studies.
Adaptive Graph Learning with Transformer for Multi-Reservoir Inflow Prediction
Nov 10, 2025Reservoir inflow prediction is crucial for water resource management, yet existing approaches mainly focus on single-reservoir models that ignore spatial dependencies among interconnected reservoirs. We introduce AdaTrip as an adaptive, time-varying graph learning framework for multi-reservoir inflow forecasting. AdaTrip constructs dynamic graphs where reservoirs are nodes with directed edges reflecting hydrological connections, employing attention mechanisms to automatically identify crucial spatial and temporal dependencies. Evaluation on thirty reservoirs in the Upper Colorado River Basin demonstrates superiority over existing baselines, with improved performance for reservoirs with limited records through parameter sharing. Additionally, AdaTrip provides interpretable attention maps at edge and time-step levels, offering insights into hydrological controls to support operational decision-making. Our code is available at https://github.com/humphreyhuu/AdaTrip.
No Black Boxes: Interpretable and Interactable Predictive Healthcare with Knowledge-Enhanced Agentic Causal Discovery
May 22, 2025Deep learning models trained on extensive Electronic Health Records (EHR) data have achieved high accuracy in diagnosis prediction, offering the potential to assist clinicians in decision-making and treatment planning. However, these models lack two crucial features that clinicians highly value: interpretability and interactivity. The ``black-box'' nature of these models makes it difficult for clinicians to understand the reasoning behind predictions, limiting their ability to make informed decisions. Additionally, the absence of interactive mechanisms prevents clinicians from incorporating their own knowledge and experience into the decision-making process. To address these limitations, we propose II-KEA, a knowledge-enhanced agent-driven causal discovery framework that integrates personalized knowledge databases and agentic LLMs. II-KEA enhances interpretability through explicit reasoning and causal analysis, while also improving interactivity by allowing clinicians to inject their knowledge and experience through customized knowledge bases and prompts. II-KEA is evaluated on both MIMIC-III and MIMIC-IV, demonstrating superior performance along with enhanced interpretability and interactivity, as evidenced by its strong results from extensive case studies.
Reflection of Episodes: Learning to Play Game from Expert and Self Experiences
Feb 19, 2025



StarCraft II is a complex and dynamic real-time strategy (RTS) game environment, which is very suitable for artificial intelligence and reinforcement learning research. To address the problem of Large Language Model(LLM) learning in complex environments through self-reflection, we propose a Reflection of Episodes(ROE) framework based on expert experience and self-experience. This framework first obtains key information in the game through a keyframe selection method, then makes decisions based on expert experience and self-experience. After a game is completed, it reflects on the previous experience to obtain new self-experience. Finally, in the experiment, our method beat the robot under the Very Hard difficulty in TextStarCraft II. We analyze the data of the LLM in the process of the game in detail, verified its effectiveness.
LLM-PySC2: Starcraft II learning environment for Large Language Models
Nov 08, 2024



This paper introduces a new environment LLM-PySC2 (the Large Language Model StarCraft II Learning Environment), a platform derived from DeepMind's StarCraft II Learning Environment that serves to develop Large Language Models (LLMs) based decision-making methodologies. This environment is the first to offer the complete StarCraft II action space, multi-modal observation interfaces, and a structured game knowledge database, which are seamlessly connected with various LLMs to facilitate the research of LLMs-based decision-making. To further support multi-agent research, we developed an LLM collaborative framework that supports multi-agent concurrent queries and multi-agent communication. In our experiments, the LLM-PySC2 environment is adapted to be compatible with the StarCraft Multi-Agent Challenge (SMAC) task group and provided eight new scenarios focused on macro-decision abilities. We evaluated nine mainstream LLMs in the experiments, and results show that sufficient parameters are necessary for LLMs to make decisions, but improving reasoning ability does not directly lead to better decision-making outcomes. Our findings further indicate the importance of enabling large models to learn autonomously in the deployment environment through parameter training or train-free learning techniques. Ultimately, we expect that the LLM-PySC2 environment can promote research on learning methods for LLMs, helping LLM-based methods better adapt to task scenarios.
DualMAR: Medical-Augmented Representation from Dual-Expertise Perspectives
Oct 25, 2024



Electronic Health Records (EHR) has revolutionized healthcare data management and prediction in the field of AI and machine learning. Accurate predictions of diagnosis and medications significantly mitigate health risks and provide guidance for preventive care. However, EHR driven models often have limited scope on understanding medical-domain knowledge and mostly rely on simple-and-sole ontologies. In addition, due to the missing features and incomplete disease coverage of EHR, most studies only focus on basic analysis on conditions and medication. We propose DualMAR, a framework that enhances EHR prediction tasks through both individual observation data and public knowledge bases. First, we construct a bi-hierarchical Diagnosis Knowledge Graph (KG) using verified public clinical ontologies and augment this KG via Large Language Models (LLMs); Second, we design a new proxy-task learning on lab results in EHR for pretraining, which further enhance KG representation and patient embeddings. By retrieving radial and angular coordinates upon polar space, DualMAR enables accurate predictions based on rich hierarchical and semantic embeddings from KG. Experiments also demonstrate that DualMAR outperforms state-of-the-art models, validating its effectiveness in EHR prediction and KG integration in medical domains.
Bi-Mamba4TS: Bidirectional Mamba for Time Series Forecasting
Apr 24, 2024



Long-term time series forecasting (LTSF) provides longer insights into future trends and patterns. In recent years, deep learning models especially Transformers have achieved advanced performance in LTSF tasks. However, the quadratic complexity of Transformers rises the challenge of balancing computaional efficiency and predicting performance. Recently, a new state space model (SSM) named Mamba is proposed. With the selective capability on input data and the hardware-aware parallel computing algorithm, Mamba can well capture long-term dependencies while maintaining linear computational complexity. Mamba has shown great ability for long sequence modeling and is a potential competitor to Transformer-based models in LTSF. In this paper, we propose Bi-Mamba4TS, a bidirectional Mamba for time series forecasting. To address the sparsity of time series semantics, we adopt the patching technique to enrich the local information while capturing the evolutionary patterns of time series in a finer granularity. To select more appropriate modeling method based on the characteristics of the dataset, our model unifies the channel-independent and channel-mixing tokenization strategies and uses a series-relation-aware decider to control the strategy choosing process. Extensive experiments on seven real-world datasets show that our model achieves more accurate predictions compared with state-of-the-art methods.
Towards Semi-Structured Automatic ICD Coding via Tree-based Contrastive Learning
Oct 14, 2023Automatic coding of International Classification of Diseases (ICD) is a multi-label text categorization task that involves extracting disease or procedure codes from clinical notes. Despite the application of state-of-the-art natural language processing (NLP) techniques, there are still challenges including limited availability of data due to privacy constraints and the high variability of clinical notes caused by different writing habits of medical professionals and various pathological features of patients. In this work, we investigate the semi-structured nature of clinical notes and propose an automatic algorithm to segment them into sections. To address the variability issues in existing ICD coding models with limited data, we introduce a contrastive pre-training approach on sections using a soft multi-label similarity metric based on tree edit distance. Additionally, we design a masked section training strategy to enable ICD coding models to locate sections related to ICD codes. Extensive experimental results demonstrate that our proposed training strategies effectively enhance the performance of existing ICD coding methods.
KinD-LCE Curve Estimation And Retinex Fusion On Low-Light Image
Jul 19, 2022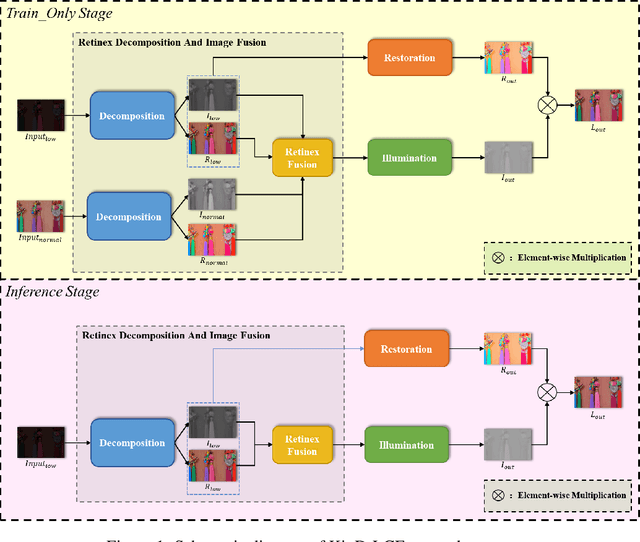

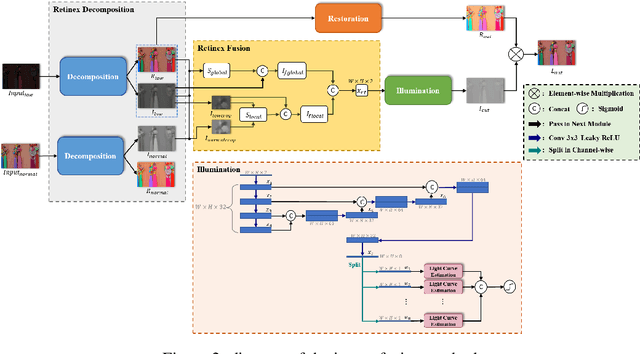

The problems of low light image noise and chromatic aberration is a challenging problem for tasks such as object detection, semantic segmentation, instance segmentation, etc. In this paper, we propose the algorithm for low illumination enhancement. KinD-LCE uses the light curve estimation module in the network structure to enhance the illumination map in the Retinex decomposed image, which improves the image brightness; we proposed the illumination map and reflection map fusion module to restore the restored image details and reduce the detail loss. Finally, we included a total variation loss function to eliminate noise. Our method uses the GladNet dataset as the training set, and the LOL dataset as the test set and is validated using ExDark as the dataset for downstream tasks. Extensive Experiments on the benchmarks demonstrate the advantages of our method and are close to the state-of-the-art results, which achieve a PSNR of 19.7216 and SSIM of 0.8213 in terms of metrics.